亚马逊AWS官方博客
在 AWS 上构建云原生机器学习流水线
前言
近两年,机器学习已经渗透到各行各业,各种人工智能和机器学习的应用蓬勃发展,在其背后实际上会有一个完善的机器学习平台和流水线来支撑模型的开发、测试和迭代。但是这样一个系统性的平台,往往需要通过整合基础架构层和平台层来完成,这样的工程是非常消耗人力和物力的。
而AWS作为云计算的领导者,在基础架构层可以提供丰富的、充足的算力,在平台层提供全家桶式的机器学习平台服务,那么最后一步就是需要使用一条流水线将这些机器学习中各个环节串联在一起。
在本篇Blog中,我们将展现如果通过AWS的服务构建云原生的机器学习流水线。本文中所有的代码您都可以从这个Github Repo中获取
机器学习工作流

在一个完整的机器学习工作流中,通常都包括以上几个环节:
- 数据标注,对于监督学习来说,我们的训练数据不仅仅需要特征数据,还需要对每一条数据的标注(label或者target),这一步往往通过大数据处理的方式得到,在AWS上有丰富的工具和服务可以帮助客户完成此类任务。
- 数据预处理和特征工程,数据预处理是指对数据进行一些处理,比如处理缺失值和去除异常值数据等等,使数据处理一个合理分布中;而特征工程,是指将非实数的特征,转换成模型可以理解的数据,比如one-hot和feature hashing等特征处理方法。这一步往往也是通过大数据的处理方式可以得到。
- 算法构建,这一步很好理解,就是针对不同的应用场景开发最适合的算法。
- 模型训练,有了训练数据和算法,那么我们需要进行机器学习的迭代训练。
- 评估,在训练过程中,我们需要定期的进行评估,以确定我们的算法在向最优值进行收敛。
- 调参,如果评估的结果达不到我们的业务目标,那么我就需要不断调整算法超参数,从而得到一个最优的模型,这个过程是一个耗时耗算力的过程。
- 模型部署和推理,将模型部署到一个终端节点上,使其可以对外提供相应的推理服务,通常对外暴露出一个http或者grpc的API,让客户端进行调用。
- 推理数据监控,持续的监控推理请求的数据,检查数据和训练数据相比是否发生偏移,如果发生数据偏移,及时更新模型。
AWS云原生机器学习流水线

在第2章节我们描述很多机器学习中的环节,这么多的环节我如何一一去实现并将他们打包成一个流水线呢?在AWS上,您可以通过丰富的服务和工具快速的构建一个自动化的机器学习平台,如上图所示,在这个方案中我们通过使用 AWS Glue(简称Glue) + Amazon SageMaker(简称SageMaker) + Step Functions的方式,完成一个serverless机器学习流水线,在这个方案中您不需要配置和维护任何一台EC2,所有的资源都是按需开启和按需付费;在这个方案中,Glue对训练数据进行预处理,SageMaker完成机器学习的其他环节,包括训练、评估、模型部署等工作,而这些环节通过Step Functions串联成一个工作流。使用这样的方案可以实现模型的整体工程化部署,或者让数据科学家也具有编排自己机器学习工作流的能力,提高模型开发和迭代过程。
Glue
AWS Glue 是完全托管的提取、转换和加载 (ETL) 服务,您可以轻松地准备并加载数据以进行分析。您只需在 AWS Glue 可视化编辑器中单击几次,即可创建并运行 ETL 作业。此外您也可以自己编写Python或者Scalar的Spark应用程序,并定义ETL job所需的计算资源,之后您便可以手动或者自动的触发ETL job,Glue会以Serverless的方式运行您的job,您可以将处理过的数据存储到多种数据源,比如S3,RDS或者Redshift等等。
SageMaker

Amazon SageMaker是一个机器学习平台服务,它就像一个全家桶囊括了机器学习各个环节,主要包括以下组件:
- Ground Truth – 数据标注服务
- SageMaker Studio – 一个针对机器学习领域的IDE
- Training and Tuning – 支持Tensorflow、MXNet和Pytorch主流框架和以及分布式训练任务,提供自动化超参调优的能力
- Deployment and Hosting – 部署模型到Sagemaker托管的endpoint上,支持在线和离线的推理,支持Auto Scaling
除此之外,SageMaker是一个对开发者友好的服务,提供非常完善的SageMaker SDK,您可以使用这个SDK方便的调用SageMaker中的组件
Step Functions
AWS Step Functions 是一个无服务器服务编排工具,可轻松将多个 AWS 服务按顺序安排到业务关键型应用程序中。通过其可视界面,您可以创建并运行一系列检查点和事件驱动的工作流,以维护应用程序状态。 每一步的输出作为下一步的输入。应用程序中的各个步骤根据业务逻辑定义的顺序执行。
目前Step Functions已经全面的支持SageMaker及其各个组件,如果编排一个Step Functions工作流,需要掌握Amazon States Language JSON文件的书写方法,这对于一个初学者来说是非常难以入手的,为了简化这方面的学习成本,提高数据科学家的工作效率,AWS提供了Step Functions Data Scientist SDK,通过简单的API接口就可以快速构建出一个套机器学习工作流
实验步骤
下面我们将一步步给大家演示,如何在AWS上构建上述的解决方案,在此实验中您将使用以下几个AWS服务:
- AWS S3 :AWS对象存储服务,用于存放训练数据集以及机器学习模型
- Amazon SageMaker:AWS机器学习托管服务,在实验中主要的操作我们将在Notebook Instance中完成
- AWS Glue:无服务器化的ETL服务,Glue的数据处理脚本已经为您准备好,对Glue的操作都会在Notebook中通过AWS SDK的方式调用
- AWS Step Functions:无服务器服务编排工具,对AWS Step Functions的操作都会在Notebook中通过AWS Step Functions Data Science SDK的方式调用
下面我们正式开始实验步骤
在Sagemaker中创建并配置Notebook Instance
Notebook Instance是使用Amazon SageMaker的入口,在Notebook Instance部署完成后您可以进入到熟悉的Jupyter Notebook或者Jupyter Lab的UI中,完成算法开发、交互式验证,SageMaker服务调用等工作;在AWS配置好的Jupyter Notebook环境中,已经安装好了常用的Tensorflow、MXNet、Pytorch、Spark和Python等Kernel,并且AWS SDK和CLI也已经配置好,用户可以快速的开始机器学习的算法研发和验证。
创建Notebook Instance需要进入SageMaker的Console,然后点击“Create notebook instance”

然后选择这个Notebook Instance的配置,根据自己的需求进行选择

此外还需要配置Notebook Instance的Role,在Jupyter中调用AWS CLI和AWS SDK的都将使用这个Role的权限,这里选择“Create a new role”然后按照默认的权限配置就好


然后其他配置保持默认,点击“Create notebook instance”,然后等待新的Notebook Instance的状态变为“InService”,然后点击“Open jupyterLab”进入Jupyter Lab

进入Jupyter Lab之后,打开一个Terminal,然后运行以下命令,将Github repo下载到Jupyter Lab本地:
cd SageMaker/ && git clone https://Github.com/xzy0223/SageMaker-example.git
然后导航到对应的目录,找到SageMaker Pipeline的notebook并打开,之后的大部分操作将在这里完成。
安装Step Functions Data Scientist SDK和初始化
在Notebook中运行此cell,这将在环境中安装Step Functions Data Scientist SDK,用于后面调用

然后进行一些全局参数的初始化
- session,接下来调用SageMaker组件的session
- bucket,用于存放训练数据的S3存储桶,需要提前创建好
- source_prefix,用于存放原始训练数据的S3 prefix

- output_prefix,用于存放通过Glue转换过的最终训练数据的prefix

分配相应的权限
在这个实验中,涉及到AWS之间服务的调用,所以需要给这些服务配置正确的权限才能顺利完成。这些操作可以根据notebook中的描述在AWS Console中完成。
- 为Notebook Instance的Role分配“AWSStepFunctionsFullAccess”,以便在Jupyter notebook中Step Functions Data Scientist SDK可以有权限操作。
- 为Notebook Instance的Role分配可以创建Glue Job的权限,因为后边在Jupyter notebook中会通过AWS SDK创建Glue Job。
- 为Step Functions创建一个Role,并赋予这个Role操作SageMaker和Glue的权限,因为Step Functions要和这个Role绑定去启动Glue job和SageMaker的training job等组件
- 为Glue Job创建一个Role,Glue ETL job需要使用这个Role的权限从S3读取和写入训练数据
准备原始训练数据
从Internet下载MNIST数据集

将数据分割成Train、Validation和Test数据集并存储到S3上

创建Glue ETL Job
我们需要创建一个Glue ETL Job用于后边Step Functions的调用,实验目录中包含了一个名为“train_val_norm.py”的ETL脚本,您可以打开进行查看,这个脚本的主要作用是从S3中读取原始训练数据,对特征进行归一化,最后再存储回S3。
在notebook中通过AWS SDK创建Glue ETL Job

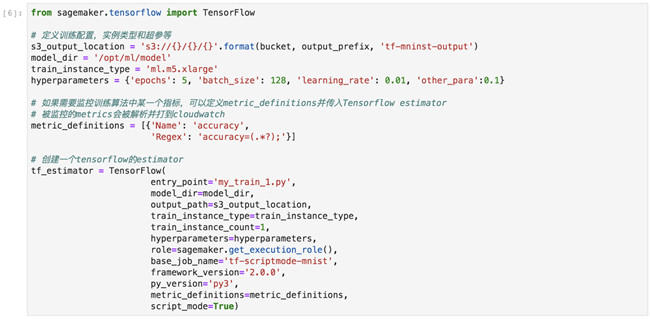
创建Tensorflow Estimatior
SageMaker可以支持Tensorflow、Pytorch和MXNet等常见的框架,并且在SageMaker SDK中也为大家封装了对应的类,可以通过这个类创建出一个对应框架的estimator,通过这个estimator对象可以完成从训练、部署到推理的整个机器学习流程。在本实验中,我们的算法基于Tensorflow开发,并且使用了脚本模式进行训练,脚本模式允许算法工程是编写自己的训练脚本,而无需构建一个训练容器镜像,简化了开发和验证算法的难度。
我们需要创建一个Tensorflow Estimator,在后边Step Funtions会使用这个Estimator完成训练、部署模型的步骤,在创建时需要传入一些必要的参数:
- entry_point:训练脚本的路径
- output_path:模型文件存放的S3路径
- train_instance_type:训练模型的实例类型,机型配置
- train_instance_count:训练实例的数量
- hyperparameters:训练脚本需要使用的超参数
- framework_version:训练脚本使用的Tensorflow的版本
- py_version:训练脚本使用的python版本
- metric_definitions:训练任务要监控的模型性能指标
- script_mode:打开脚本模式

创建并运行Step Functions流水线
Step Functions是AWS的任务编排服务,在其中最核心的概念就是Step,也就是工作流中每一步要执行的任务;另外Step Functions中每个step都会有input和output;并且可以在Step Functions中编排复杂的任务逻辑,比如并行、判断、分支等等,在这个实验中我们使用最简单的串行逻辑,按照数据处理、模型训练、模型创建到模型部署的流程顺序执行。
首先import相关类库

Step Functions的工作流是通过事件触发的机制被启动的,并且由于每个step都要有input,所以我们要定义一个触发工作流的input schema,这个input会在各个step中传递,在其中我们定义了一些参数变量,对应的step会使用这些参数,完成对应的任务

定义Glue Job Step,定义一些Glue ETL Job需要使用的参数

定义Training Step,这里使用了我们刚才创建的Tensorflow Estimator,还有需要传入训练数据的S3路径,并等待训练任务完成再进入下一个Step

当训练结束后,需要创建一个SageMaker的Model

下一个Step就是要生成一个部署模型的配置信息,比如托管模型的实例的配置和数量等

最后一个Step就是基于上一个Step创建的配置,部署托管模型的Endpoint,这个Endpoint就可以被client进行调用,完成在线推理的工作
各个Step已经创建完成,那么就需要创建一个工作流将它们串联起来
创建这个工作流

此时,来到Step Functions的console中,应该可以看到对应的工作流已经创建,并可以看到整个pipeline的图形化展现。您可以看到左侧是这个工作流的定义,在没有Step Functions Data Scientist SDK的情况下,您需要自己编写这个JSON文档完成配置,如果使用了Step Functions Data Scientist SDK极大的简化了创建机器学习工作流的难度和过程。

最后回到notebook,完成对工作流的触发,传入我们定义好的input参数

当工作流开始运行后,您可以在Step Functions的console中看到每个Step的执行情况和input/output

总结
在本文中,我主要讲述了如何通过Step Functions编排整个机器学习工作流,使用Glue可以帮助我们完成训练数据的ETL和特征工程等数据相关的操作,SageMaker可以完成从模型训练、超参调优、模型生成和模型部署等机器学习流程,最后通过服务器化的任务编排服务Step Functions将整个流程串联,并且AWS提供了完善的UI和SDK工具,帮助算法工程师快速的构建、管理和监控机器学习工作流,大大提高了模型开发和模型验证的效率,更好的满足越来越多的业务需求。