亚马逊AWS官方博客
基于NOVA MME多模态能力构建游戏资产库
背景
在游戏行业中,如何有效地管理音频/美术资产是一个很有挑战的话题。通常工程师们会通过xls表格,关键字命名方式,或者开发一些插件工具来管理海量的资产库。不过受限于对于资产本身内容理解的限制,往往止步于名字或者标签搜索,是否结果是真的符合使用者使用需求,其实并不能有效验证。
最近,AWS推出了NOVA多模态embedding模型(NOVA MME),它的技术能力:将任意资产(文字,文档,图片,视屏,音频等)转换成存储在向量数据库中统一纬度的数据,然后将用户任意输入(文字,文档,图片,视屏,音频等)也转换成同维度的向量,利用余铉近似(cosine similarity)或者欧氏距离(Euclidean distance)的方式,选择出来相似度最高的资产。这种不依赖关键词匹配的新型检索方式,可以大大方便游戏资产库的构建工作。
注意:本案例主要是以音频构建为主,其他形式资产可以用类似的方式处理
技术架构
案例的整体技术架构如下:
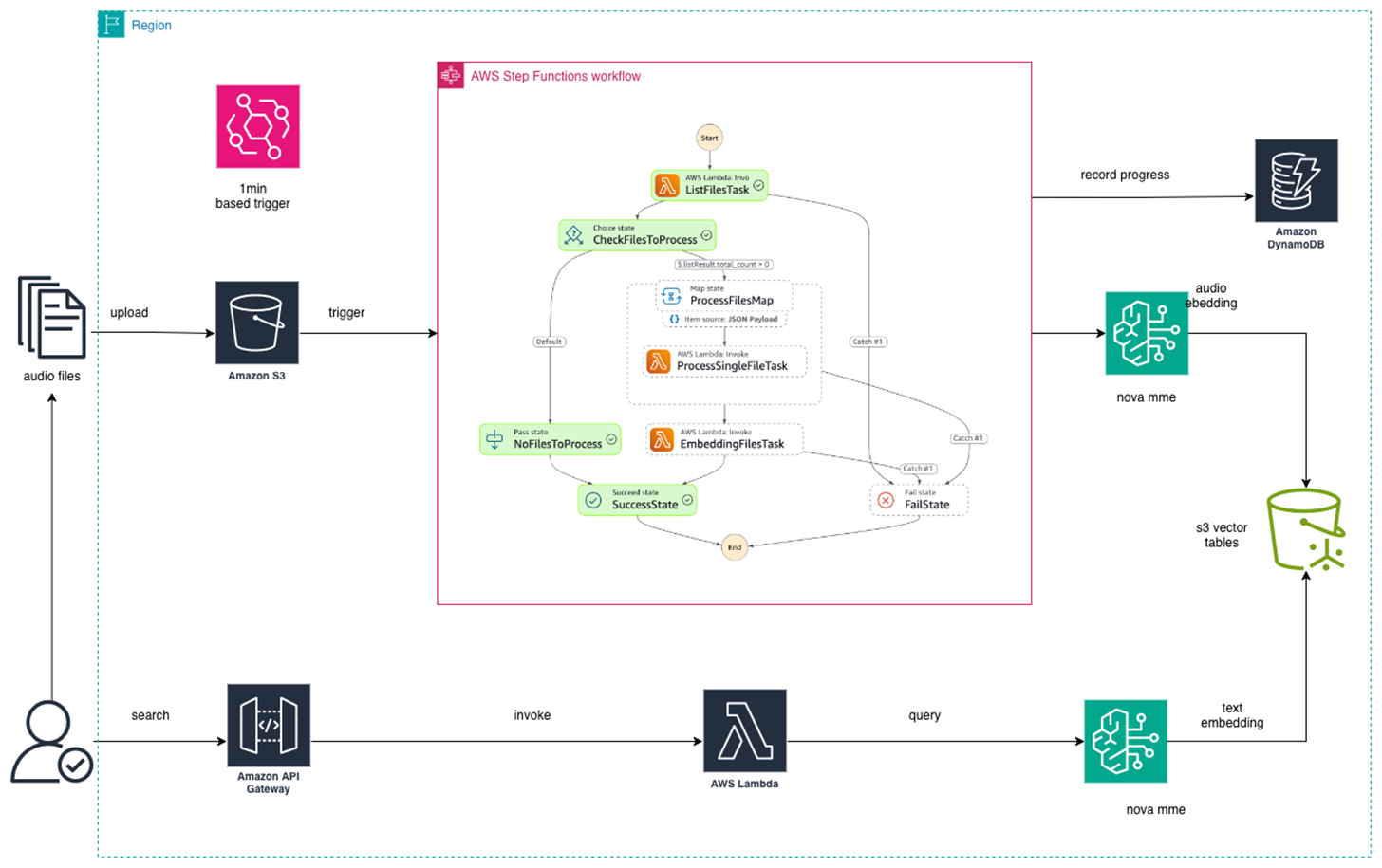 |
可以将架构分成两个部分
- 上半部分:批量处理音频文件
- 同步本地音频文件到指定s3桶
- 利用eventbridge来每分钟扫描s3桶的音频,它会触发一个stepfunctions
- stepfunctions的listFiles: 记录扫描进度到DynamoDB, 同时获取到新的音频文件
- stepfunctions的processFiles: 利用可控高并发的lambda方法,同时预处理海量音频文件
- stepfunctions的embeddingFiles: 将预处理好的音频文件通过NOVA MME进行embedding并存储到S3 Vectors
- 下半部分:查询流程
- 通过apigateway暴露固定端点url
- lambda方法主要是将用户输入的查询语句进行embedding,然后开始匹配返回结果
方案步骤
准备工作
创建s3 vector table
我们需要手动在aws console中创建一个s3 vector table,具体操作方法如下:
关键参数说明:
--index-name: 索引名称--data-type: 数据类型(如float32)--dimension: 向量维度数--distance-metric: 距离度量方式(cosine、euclidean等)
获取项目
项目地址:https://gitee.com/benxiwan/novamme-audio-assets-management.git
接下来我们通过获取项目,然后修改配置文件,填入上一步对应的bucket_name和index_name即可
schedule_interval_minutes:这个参数它决定触发s3桶扫描的频率, 以下是参考:
调度间隔选项
- 1 分钟 – 最频繁,适合开发环境
- 5 分钟 – 平衡,适合生产环境
- 15 分钟 – 较少,适合批处理
- 60 分钟 – 最少,适合低频场景
成本影响: 调度间隔直接影响 Step Functions 执行次数:
- 1 分钟 ≈ 43,800 次/月
- 5 分钟 ≈ 8,760 次/月
- 15 分钟 ≈ 2,920 次/月
- 60 分钟 ≈ 730 次/月
部署项目
整个项目是由aws cdk快速构建,它能够用代码的方式管理你的云上服务,省去了繁琐的配置过程。当我们前面的配置都检查无误了,就可以直接开始部署了
常规部署
当然也支持按需部署
关于ffmpeg
FFmpeg是一个开源的多媒体处理工具,广泛用于音视频的编码、解码、转码、流媒体处理等任务。主要功能
- 音视频转码: 支持几乎所有主流的音视频格式之间的转换
- 编解码: 支持264、H.265、AAC等多种编解码器
- 流媒体处理: 可以处理RTMP、RTMPS等流媒体协议
- 视频编辑: 支持剪辑、合并、添加滤镜效果等操作
- 格式转换: 在不同容器格式之间转换(如MP4、AVI、MKV等)
在这个项目中,由于nova mme单次只能操作1-30s的音频片段,需要将超过30s的音频文件进行切分。
我们在构建step functions中的时候,需要依赖ffmpeg。项目中已经将相关的bin文件放置进去,部署时候自动会添加layer的依赖
 |
场景测试
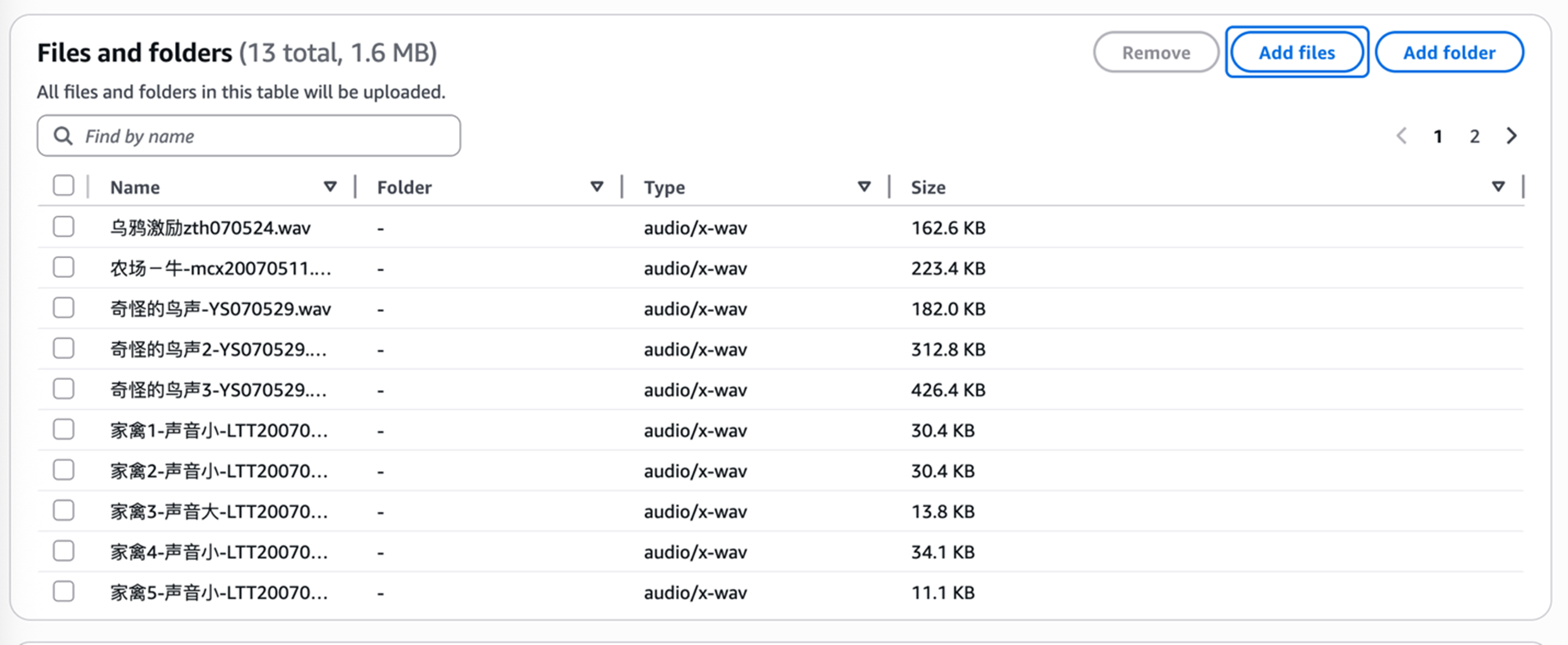
音频批处理测试:
首先我们上传一批音频片段:
 |
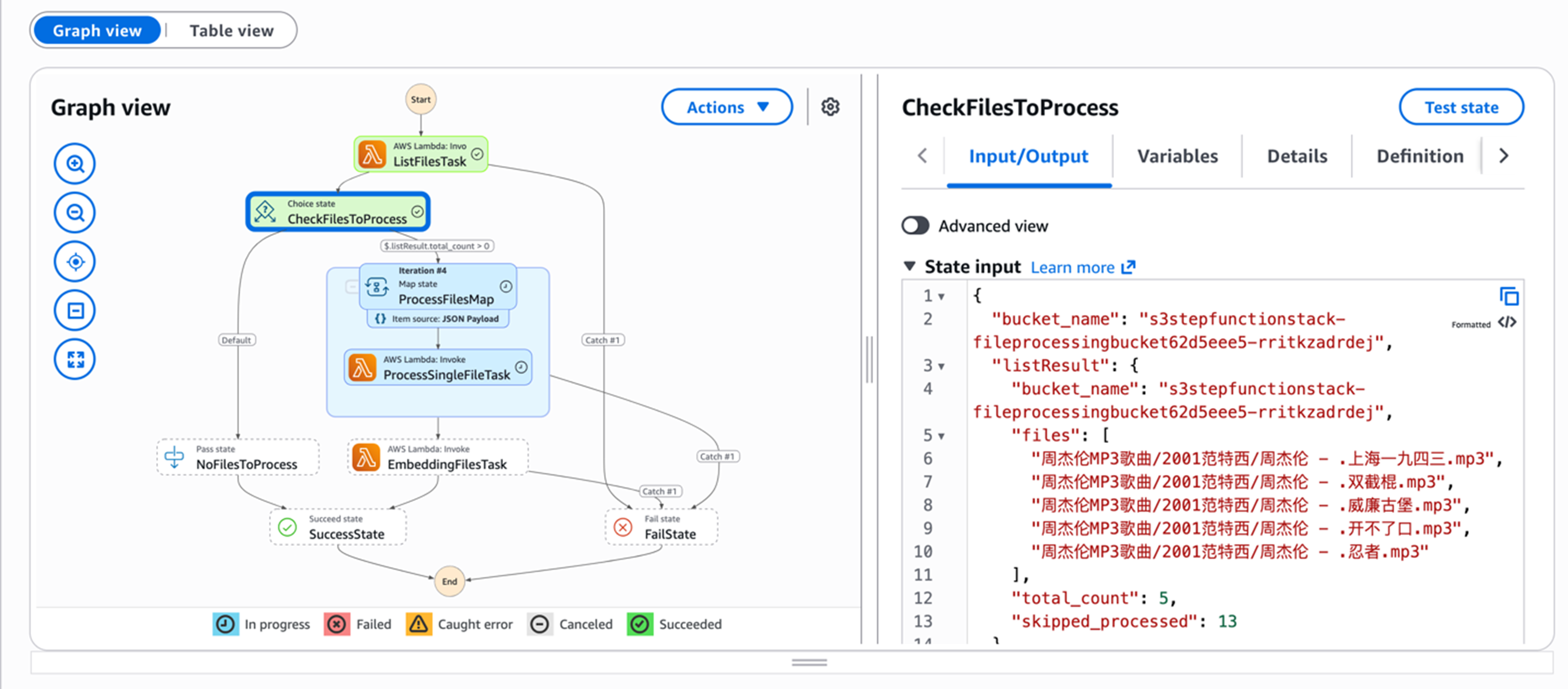
可以看到Step functions会定时触发处理这些音频的流程,整个进度记录在DynamoDB中,如果我们测试一些歌曲的话,也可以看到它们会自动按照30s一段的方式进行裁切。需要注意的是,尽管配置了可以同时并发10个lambda来处理这些音频,更多更长的歌曲仍旧会拉长整体的处理时间。
 |
文字搜索测试:
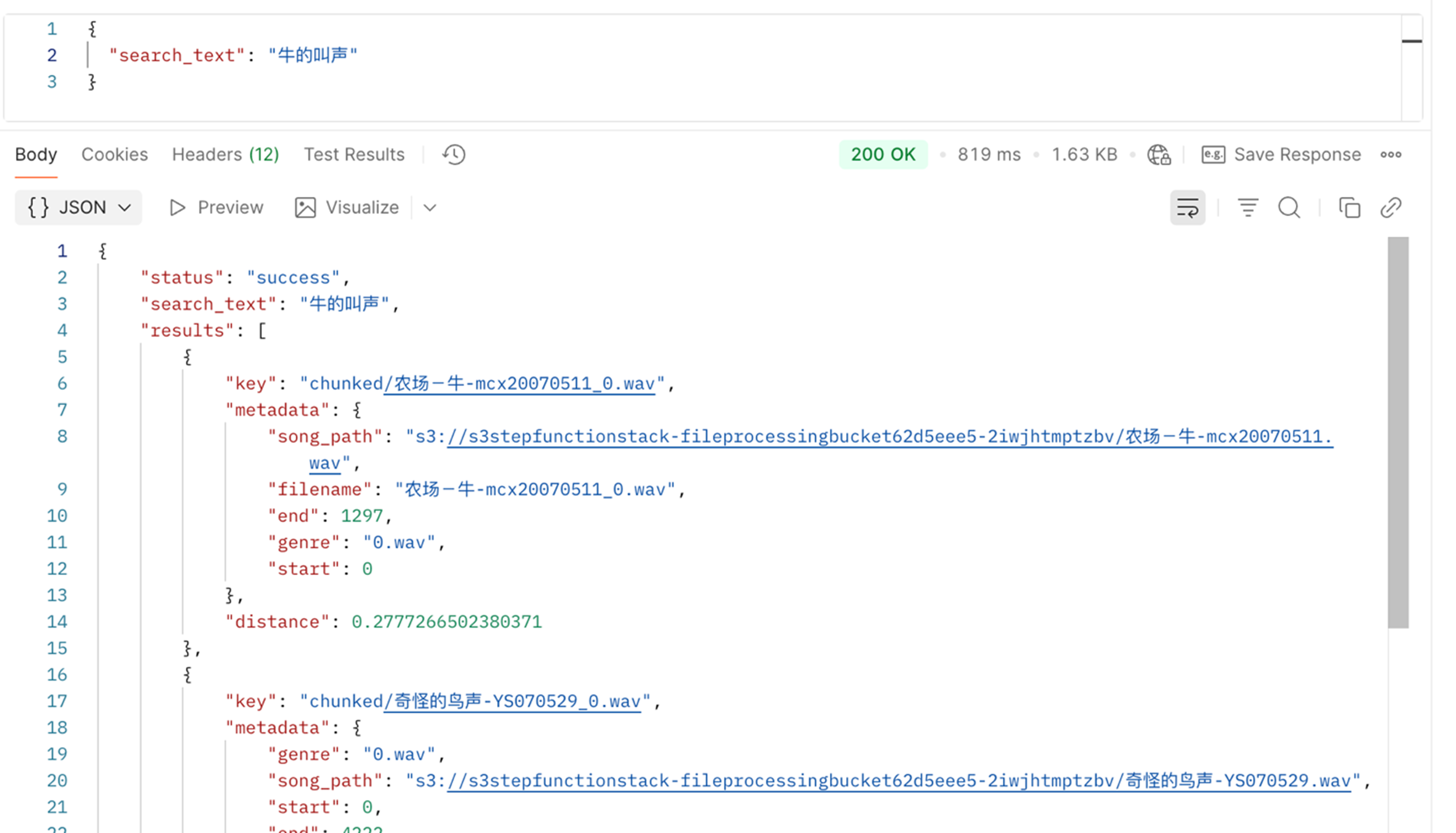
当我获取到APIGateway的对外endpoint之后,就可以开始测试了,这里假设,我们需要搜索一个“牛的叫声”,可以看到返回的结果中,”chunked/农场-牛-mcx20070511_0.wav” 出现在了第一个位置,并且也告知了其桶的位置,方便我们进行后续操作。
 |
音频搜索测试:
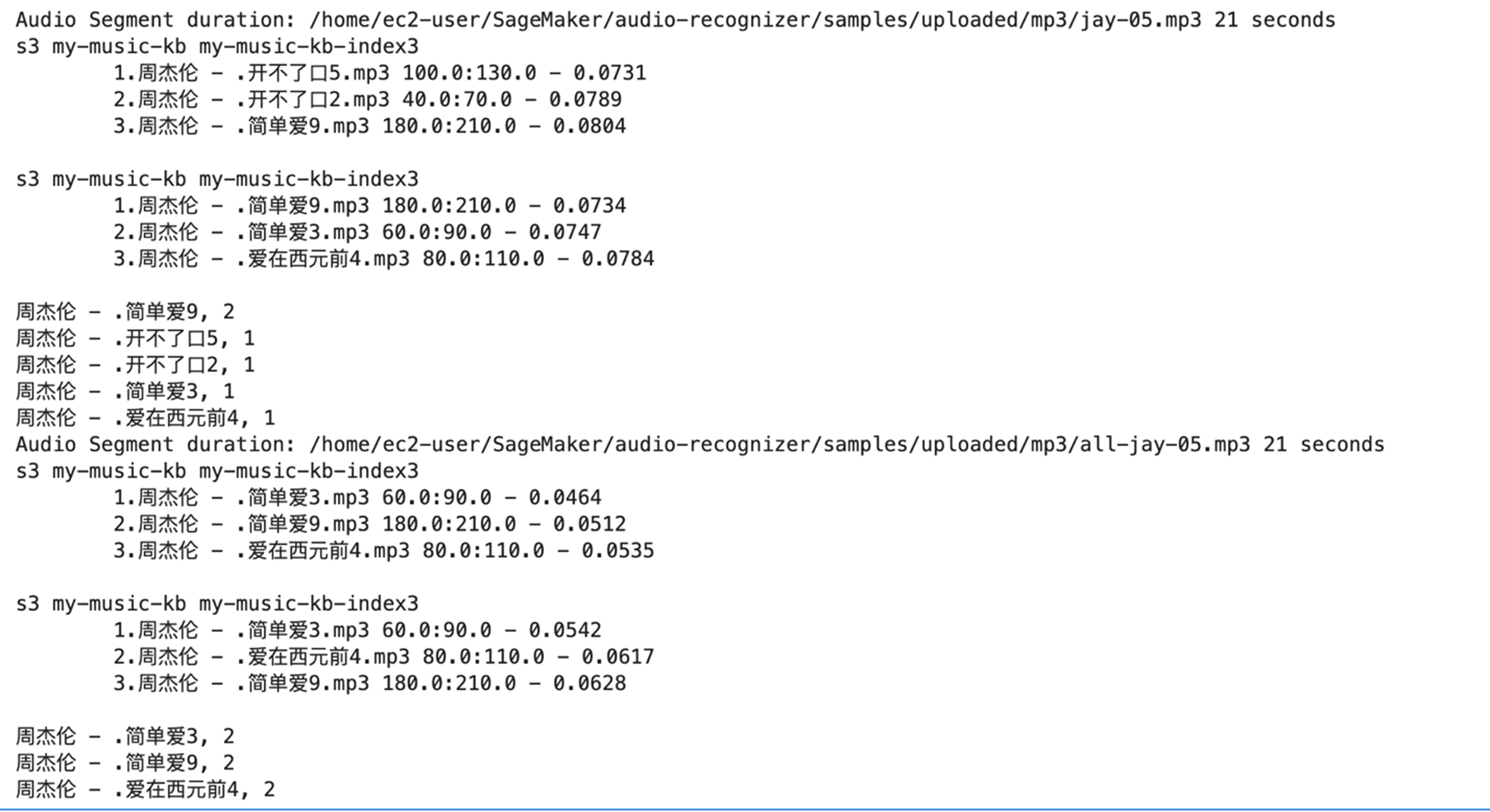
在类似“听歌识曲”的场景中,如果想通过录音的方式来进行搜索,需要借助ffmpeg对于原来声音进行降噪和提高人声处理, 比如下面的这条命令会:
- 增强低音: 提升100Hz附近的低频部分(+6dB)
- 削减高频: 降低8000Hz附近的高频部分(-3dB)
我们上传了两段音频,时常都在15s,一个是直接录制未经过处理的jay-05,另一个是通过ffepeg的降噪提人声处理过的all-jay-05.mp3。可以明显看到,处理过的准确率会明显提高。
 |
总结
本文通过cdk的方式快速部署了一个基于NOVA MME的音频搜索demo,可以看到nova mme通过向量搜索的方式大大简化了多模态场景下各种游戏资产的查询和搜索方式。是一个真正意义上的“Game Changer”。同时,本文中所有的服务都是“serverless”j架构,无需提前预制任何服务器,真正做到了“按需使用”。
当然, 由于转换成了向量,会导致信息的丢失,所以关于内容的细节并不能很好支持。这里的一些关于多模态模型这种向量搜索的方式也会有一定局限性:
- 在寻找类似的音乐,或者“节奏紧凑/舒缓”这类感官型的任务时候,它能够很好的完成任务
- 如果要查询音频中是否出现某个关键字,它的匹配正确率并不高,是因为MME压缩信息,造成的不准确。
- 在“听音识曲”的场景中,输入的音频一定要经过ffmpeg来进行降噪提人声这类的处理。
- 受限于录音设备的不同于采样率(1hz或者48hz),虽然人耳无法识别区别,这个对于输出的结果也有较大影响。
- 音频的长度同样是一个问题,经验值来看,通常低于15s以下的音频更难获得一个准确的结果。
我们也深知,作为开源项目肯定会有各种不尽如意的问题,欢迎大家的留言!
参考
- 如何创建s3 vector和index: https://docs.amazonaws.cn/AmazonS3/latest/userguide/s3-vectors.html
- Amazon Nova 多模态嵌入模型实战指南:https://aws.amazon.com/cn/blogs/china/amazon-nova-multimodal-embedding-model-practical-guide/
- Processing user-generated content using AWS Lambda and FFmpeg: https://aws.amazon.com/blogs/media/processing-user-generated-content-using-aws-lambda-and-ffmpeg/
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
