亚马逊AWS官方博客
用自己的数据在 AWS DeepComposer 中创建音乐流派模型
Original URL: https://aws.amazon.com/cn/blogs/machine-learning/creating-a-music-genre-model-with-your-own-data-in-aws-deepcomposer/
AWS DeepComposer是一项教育型的AWS服务,可以训练出生成式的人工智能并利用GAN (Generative Adversarial Network) 转换输入的旋律,创作出完整的原创乐曲。借助AWS DeepComposer,你可以使用预先训练好的音乐流派模型(例如爵士、摇滚、流行、交响乐等),或者自行训练出你自己的流派选项。在训练自定义音乐流派模型时,你需要将音乐数据文件存储在NumPy对象当中。结合GitHub上的Lab 2——训练一套自定义GAN模型中的训练步骤,本文将向大家展示如何将MIDI文件转换为适用于AWS Deepomposer的格式从而用于训练。
在这种应用场景中,你可以使用自己的MIDI文件训练出雷鬼音乐流派模型。雷鬼音乐诞生于牙买加岛,常用乐器包括低音吉他、鼓以及各类打击乐器。但别担心,本文介绍的方法是通用的,大家完全可以借此训练任何其他音乐流派。
数据处理:生成训练数据
MIDI(.mid)文件是训练数据的最初始状态。MIDI文件由软件生成(并读取),文件中包括关于音符及声音回放的数据。在数据处理过程中,我们需要将MIDI文件转换为NumPy数组,并将其持久化保存成磁盘上的一个单独的.npy文件。下图展示了数据的转换过程。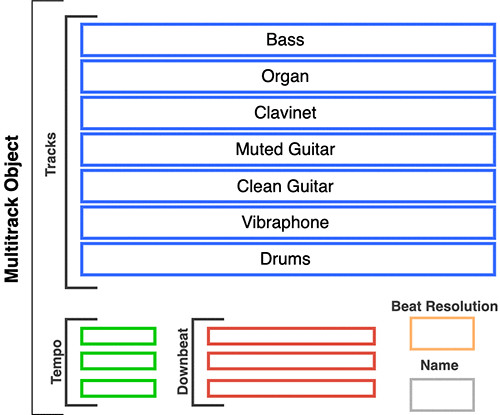
尽管机器学习普遍使用.csv文件存储数据,但.npy文件是为加速训练过程中的读取速度高度优化的。.npy文件的最终形态应为(x, 32, 128, 4),其含义分别为 (样本数量,每个样本的时间步数, 音高范围, 乐器)。
将MIDI文件转换为适当的格式,我们需要完成以下步骤:
- 读取MIDI文件以生成一个
Multitrack对象。 - 确定要使用的四条乐器音轨。
- 检索各音轨中的
pianoroll矩阵,并将其调整为正确的格式。 - 将Pianoroll对象与给定的乐器相匹配,并将其存储在.npy文件中。
读取MIDI文件以生成一个Multitrack对象
数据处理的第一步,是解析各MIDI文件并生成一个Multitrack对象。下图即为Multitrack对象的基本结构。
这个过程用需要用到Pypianoroll库,它以Python代码实现读取及写入MIDI文件的功能。具体参见以下代码:
music_tracks是一个Mulitrack对象,包含一个从MIDI文件中读取到的Track对象列表。每个Mulitrack对象都包含速度(tempo)、节拍(downbeat)、节拍分辨率(beat resolution)以及名称(name),具体如以下代码所示:
确定要使用的四条乐器音轨
如果您要解析的Mulitrack对象中恰好包含四种乐器,则可以直接跳过此步骤。
我们之前解析的Mulitrack对象共包含7条乐器音轨(fretless电贝司、风琴、竖笛、静音电吉他、清音电吉他、颤音琴和鼓)。模型需要学习的乐器种类越多,训练时间就越长,成本自然也越高。有鉴于此,这里我们选择的GAN只支持最多4种乐器。如果MIDI文件中的音轨包含4种以上的乐器,请直接从所选择的音乐流派中选择最重要的4种乐器进行模型训练。相应的,如果乐器数量不足4种,则需要扩充MIDI文件。乐器数量错误会导致NumPy的形制出现错误。
给定音轨上的每一种乐器都拥有自己的编号。编号由通用MIDI规范规定,相当于乐器的唯一标识符。以下代码示例就用相关编号提取到钢琴、风琴、贝司以及吉他四种乐器:
检索每条音轨中的pianoroll矩阵,并将其调整为正确的格式
Multitrack对象为每种乐器提供一个Track对象。每个Track对象中都包含一个pianoroll矩阵、一个编号、人个表示音轨是否为鼓的布尔值以及一个名称。
以下代码,为单一Track的具体示例:
在训练当中,单一pianoroll对象应具有32个离散的时间步长,代表一首歌曲的片段与128个音高。所选乐器音轨的pianoroll对象的起始形态为(512,128),我们需要将其调整为正确的格式。每个pianoroll对象将重新调整为2个小节(32个时间步长)、音高为128。输入以下代码后,单一pianoroll对象的最终形制为(16, 32, 128):
为了简洁起见,以下代码示例仅显示钢琴音轨的制作示例:
将Pianoroll对象与给定乐器相匹配,并将其存储在.npy文件中。
下一步是按乐器将所有音轨连结起来,并将其存储在.npy训练文件当中。我们可以将这个过程理解为各pianoroll对象间的彼此堆叠。我们需要为4种所选乐器分别重复这个过程,具体请参见以下代码:
现在,我们将合并后的pianoroll存储在.npy文件当中,详见以下代码:
结果
以上代码将一组存储在your_midi_file_directory中的MIDI文件生成reggae-train.npy 。相应Jupyter notebook与完整代码可通过 GitHub repo获取。
现在,我们已经拥有了训练数据文件,接下来就可以根据AWS DeepComposer示例notebook中Lab 2——训练自定义GAN模型提出的步骤训练自定义音乐流派模型。
本文在SoundCloud上提供两个由AI生成的雷鬼风格音轨:Summer Breeze 与 Mellow Vibe。
技巧与秘诀
你可以使用以下技巧与秘诀理解你的数据内容,并生成更悦耳的AI乐曲。
在GarageBand中查看及收听MIDI文件
如果您使用Mac设备,可以使用GarageBand收听MIDI文件并查看其中使用的乐器。如果您没有Mac设备,则可使用任何其他支持MIDI文件的Digital Audio Workstation(DAW)。在通过GarageBand收听AI生成的乐曲时,音质要明显更好。大家甚至可以连接专业级扬声器以获得极好的听觉效果。
使用乐器编号更改伴奏的乐器
在运行Lab 2——训练自定义GAN模型提供的推理代码时,大家可能会注意到,所有由AI生成的音轨都会在GarageBand中显示为“Steinway Grand Piano”。如果大家熟悉AWS DeepComposer控制台,则可随时调整乐器种类。要在训练自定义模型时更改伴奏的乐器种类,请在调用midi_utils中的 save_pianoroll_as_midi函数时使用programs参数,具体请见以下代码:
使用GarageBand添加其他伴奏
在使用AI生成一首乐曲(带伴奏)之后,我们可以使用GarageBand(或者其他类似的工具)进一步添加更多伴奏。我们可以调整音轨的速度,甚至让某些乐器静音。我们也可以添加任意数量的其他伴奏乐器以创造出独特的声音表现。
在AWS DeepComposer控制台上创建推理旋律
在运行推理时,我们需要一段MIDI格式的自定义旋律。我们还可以添加伴奏乐器配合该自定义旋律生成一首独特的乐曲。在训练自定义模型时,最简单的旋律创建方法就是使用AWS DeepComposer控制台。我们可以使用虚拟键盘或者AWS DeepComposer键盘记录下旋律,而后选择“Download”将其下载为MIDI文件。
使用matplotlib绘制pianoroll
大家可以使用Track上的plot函数绘制pianoroll对象,这样我们就能直观查看pianoroll对象了。具体请参见以下代码:
下图所示,为pianoroll对象的基本观感。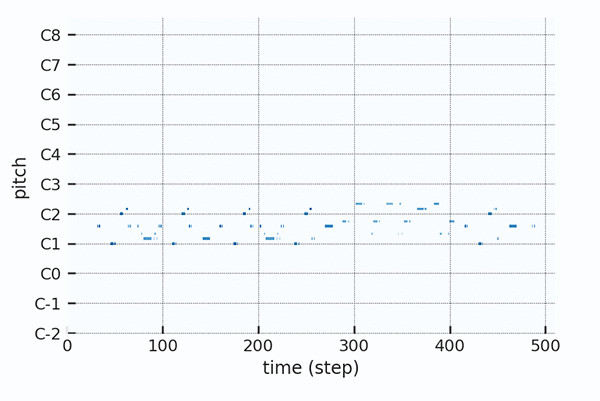
数据二值化
代码包含了一段对数据进行二进制化的部分。这项更新非常重要,因为在处理二进制化输入时,该模型实际处理的是-1与1(而非0与1)。track_list 中包含最终训练数据,在继续使用reggae-train.npy之前,应将其设置为-1或者1。具体请参见以下代码:
总结
AWS DeepComposer不只是一款普通的键盘,同时也是一种有趣的互动方式,了解生成式的AI与GAN的复杂性。您可以在它的帮助下学习演奏简单的旋律,甚至可能激发出创作全新乐曲的灵感、训练出自己的自定义音乐流派模型、最终创造出前所未有的声音。我们也可以将两种流派融合起来以创造出新的音乐类型!
我还将在A Cloud Guru上发布免费的系列文章《AWS Deep Composer: Train it Again Maestro》。这个系列共含六篇文章,将向大家介绍关于机器学习与音乐术语的知识,并讲解如何使用生成式AI及AWS DeepComposer生成乐曲。该系列将与《Battle of the DeepComposers》系列文章同步发表,这里由AI创作的两首歌曲将正面对抗,欢迎大家投票支持您喜爱的一首。
大家也可以在SoundCLoud上关注我,及时收听我受各位艺术大家启发创作出的AI生成乐曲,或者在LinkedIn上与我联系。