亚马逊AWS官方博客
敦煌网集团大数据上云实践
公司介绍
敦煌网成立于 2004 年,是领先的 B2B 跨境电子商务交易平台,敦煌网在品牌优势、技术优势、运营优势、用户优势四大维度上,已建立起竞争优势。截至 2022 年 12 月 31 日,DHgate 为来自 225 个国家和地区的 5960 万名注册买家提供服务,将他们与中国和其他国家的 254 万卖家联系起来,平台每年有超过 3400 万个在线商品,拥有 100 多条物流线路和 10 多个海外仓,71 个币种支付能力,在北美、拉美、欧洲等地设有全球业务办事机构。
挑战与目标
面临的挑战
- 随着跨境电商的日趋成熟,经营范围持续扩大、品类和渠道的增加,以及 AIGC 等行业新技术在运营提效场景下的广泛应用,对沉淀近 20 年的大数据进行深度挖掘、洞察和使用,给我们带来成本、算力、效率、安全的挑战。
- 之前传统 IDC 大数据集群,维护成本高、无法实现弹性伸缩、计算存储耦合、算力瓶颈扩容周期长等问题越发严重,无法响应业务快速发展,具体表现在以下几个方面:
- 1) 硬件设备、软件许可及运行维护成本高:自建大数据集群需要大量的硬件设备,包括服务器、存储设备、网络设备、机柜等等,CDH 有 100 个节点数免费上限,软件许可费用高昂,需要持续不断投入大量人力和物力来进行系统维护和升级以确保正常运行。
- 2) 弹性伸缩:IDC 资源从采购到部署上线周期漫长,通常以月为单位,无法及时应对突发的业务高峰资源需求。受软件许可限制,无法横向扩容算力和存储。
- 3) 计算存储耦合:由于计算节点和存储节点共享同一物理节点的资源,如 CPU、内存、磁盘等,可能会出现资源竞争的问题。如果一个计算任务占用了大量的资源,可能会影响其他任务的执行效率。数据的读写和计算都需要通过网络进行传输,随着集群规模的扩大,网络带宽可能会成为瓶颈,影响计算性能。
- 4) 算力瓶颈:主要计算引擎使用 Hive On Spark(2.4 版本)和 Hive on MR,计算效率比最新的 Spark/Tez 引擎有明显差距,通过横向扩容集群或纵向升级节点配置无法很好提升计算效率。
预期上云实现目标
- 智能湖仓架构
建设智能湖仓架构,将数据的采集、传输、存储、分析、应用全流程各环节无缝衔接,实现数据的集中存储和管理,提高数据的流转效率、数据质量、可靠性和安全性。对数据进行深度挖掘、智能分层和热力分析,提高数据的价值和利用率。
- 精细化运营成本管控
建立云资源的精细化运营和成本管控制度,提高资源利用率并降低成本。实现资源随业务灵活扩缩,提高业务的灵活性和响应速度。利用云原生的智能分层、自动化管理和运维能力,提高运维效率和质量。
- 一站式数据平台底座
打造集数据集成、数据开发、数据资产管理、数据服务等一站式大数据平台,实现“快、准、全、稳”的数仓体系,达到数据驱动决策,算法增长业务的目标。平台提供数据可视化和报表分析工具,帮助业务人员更好地理解和利用数据,提高业务决策的准确性和效率。
数据架构及技术方案
敦煌大数据的技术组件及架构(IDC)

IDC 大数据环境基于 CDH、大数据开源生态组件、商业及自研工具构建。
数据源:包含上百个 MySQL、Oracle 以及 NoSQL 数据库实例,数万张源表(分库分表),数十 TB 数据。
数据缓冲区:每天数十亿条数据库增量数据,用户行为日志数据实时发送到 Kafka 集群,保证了数据高可用的同时,满足了离线和实时大规模数据分析处理的需求。
离线计算和实时计算集群:使用 CDH 6.x 搭建大数据集群,借助于 Cloudera Manager 可方便地管理和部署 Hadoop 集群,并进行可视化监控和故障诊断。提供稳定可靠的离线、实时的计算引擎服务。
OLAP 引擎:按不同应用场景需求配置了 ElasticSearch、ClickHouse、StarRocks 查询引擎提供买卖家、业务运营的在线查询服务。
业务应用:常用的报表及可视化工具:Hue、Tableau、BO,自研的 EOS 系统和对接服务化接口等业务应用。
数据安全:集成了 Kerberos+Sentry+Ldap 提供统一用户认证与鉴权,保障了数据安全。其中,Kerberos 提供了身份验证协议的基础,Sentry 提供了细粒度的授权控制,LDAP 则提供了用户和组信息的管理功能。这些技术的结合极大提高大数据集群的安全性和管理效率。
数据开发平台:我们的数据开发平台采用了开源和自研技术相结合的方案。其中,任务调度部分采用 DolphinScheduler 实现,数据集成部分在 DataX 基础上进行二次开发,实现了可视化配置。此外,我们还注重数据血缘、元数据以及生命周期管理等方面,专门进行了针对性的研发。
敦煌大数据集群负载(IDC)
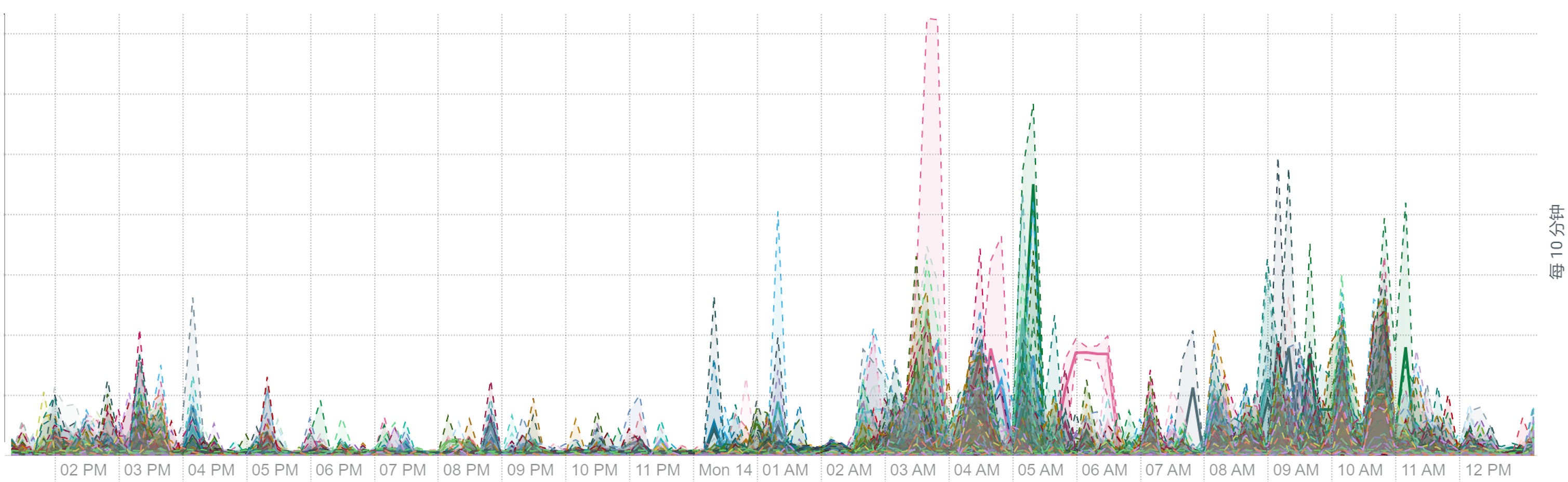
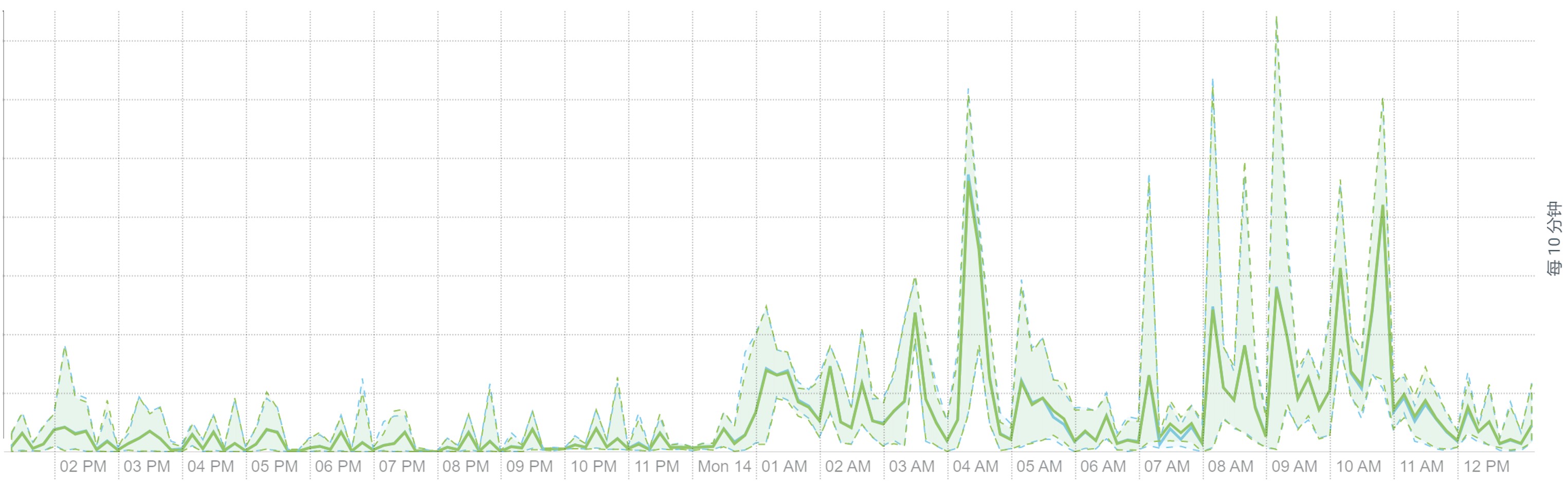
离线大集群计算的资源利用率包括 CPU、内存、磁盘与网络 IO 等均可看到明显的潮汐效应。每天波峰集中在三个时间段:2-5(每天定时离线计算任务)、9-11(工作时段业务常规报表查询),14-16(工作时段业务常规报表查询),平均资源利用率 30%。
下面是某个集群的工作负载截图:
CPU 负载:
Yarn 内存使用:
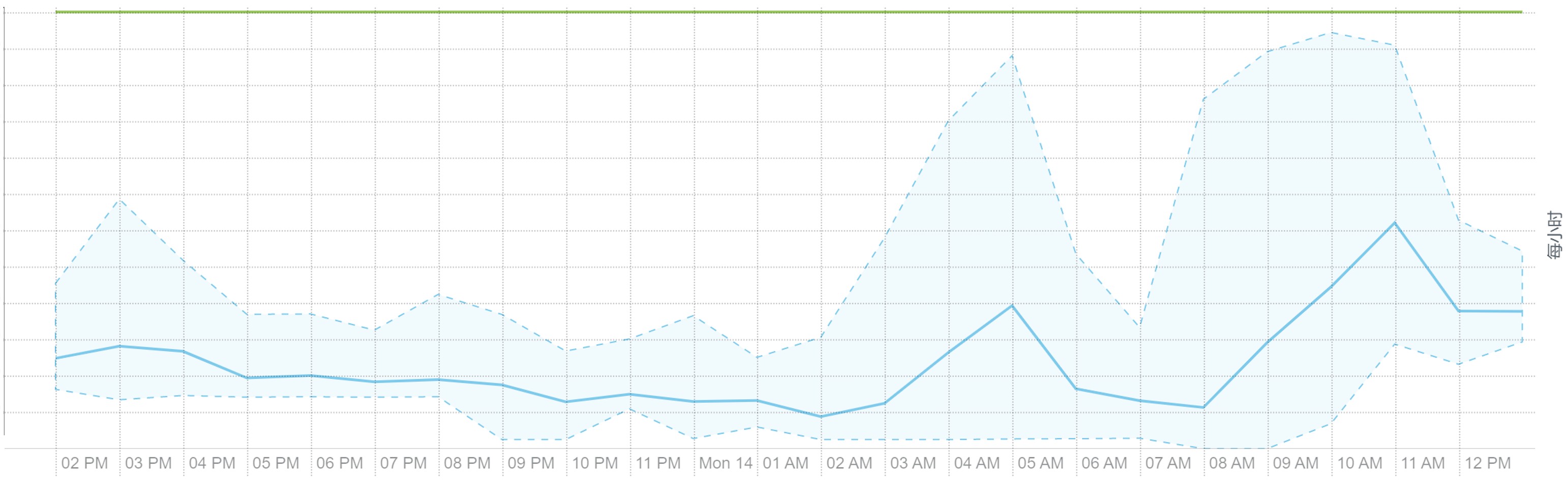
HDFS IO:

Network IO:
前期技术方案调研
前期调研阶段,我们花了大量时间和精力对 Amazon EMR、Redshift、S3 等进行多个维度深入评估测试并得到了超过预期的结果,最终选择亚马逊云科技作为大数据云底座。调研最终结论如下:
| 架构兼容性 | 技术先进性 | 算力 | 维护难易成本 | 开发平台 | 扩展性 | 成本 |
| 适配现有公司架构 | 技术先进且开放,更新迭代快 | 高-EMR Spark 效率是 CDH 的 2 倍 | EMR-中
数仓-低 |
可集成第三方开发平台 | 组件全面
可自定义扩展全球节点资源丰富 |
中 |
在调研过程中,我们主要对比亚马逊云科技和 IDC 自建的离线 Hadoop 集群和数据仓库服务,以下是核心组件版本和硬件资源配置和关键项目项对比结果:
| 项目 | 亚马逊云科技 | DHgate | ||
| 离线集群 | 数据分析服务 | EMR | CDH | |
| 主版本 | 6.3/5.34 | CDH6.x | ||
| Hadoop | 3.2.1/2.10.1 | 3.x | ||
| Hive | 3.1.2/2.3.8 | 2.x | ||
| Spark | 3.1.2/2.4.8 | 2.4.0 | ||
| Master节点 | m6g.2xlarge | – | ||
| Core节点 | m6g.8xlarge
EBS:600GB |
– | ||
| Task节点 | m6g.8xlarge
EBS:600GB |
– | ||
| 创建集群 | 15min | – | ||
| 弹性扩容 | 3min,服务无需重启 | – | ||
| 弹性收缩 | 2min,服务无需重启 | – | ||
| Spot竞价实例 | 预计可节约成本60% | – | ||
| 一次性集群 | 有 | – | ||
| 风险点 | 版本升级Spark3兼容 | 100节点限制不能扩容 | ||
| 数据仓库 | 数仓服务 | Redshift | Spark-SQL | |
| 协议兼容 | redshift-jdbc,兼容postgresql | spark-jdbc | ||
| 服务器资源配置 | ra3.4xlarge
12vCPUs | 96GB | 128TB |
spark.dynamicAllocation.enabled=true
spark.dynamicAllocation.maxExecutors=60 spark.executor.cores=4 spark.executor.memory=12GB |
||
| 节点数 | 4 | 动态调整 | ||
| 总计算资源 | 48vCPUs | 768GB | 最小1vCPUs | 12GB | ||
| 最大60vCPUs | 720GB | ||||
| 存储资源 | 1PB | ulimited | ||
| 数据存储 | 列式
占用空间约为parquet的1.2-2倍 |
列式Parquet | ||
| 性能 | 高,随节点数线性增长 | 低,资源充分情况下执行时间基本不变,平均76s | ||
| 稳定性 | 高
测试过程中无SQL执行失败 |
中高
稳定性和数据格式、SQL优化及资源分配相关 |
||
| 缓存 | 结果集缓存加速
数据缓存 |
数据缓存 | ||
| 弹性扩缩 | 最小节点数2
可扩容、收缩约5分钟,期间只读 |
动态调整 | ||
| 维护优化 | 极简
机器学习自动提供优化SQL 数据表需持续Vacuum和分析 |
开发人员自助优化 | ||
| 权限管理 | 列级权限 | 列级权限 | ||
| 风险点 | 无分区,自动优化大表性能一般 | 数据倾斜内存溢出失败
少部分Hive on Spark SQL执行效率低 |
||
调研过程中我们进行了严格的 Benchmark 对比测试,从生产业务数百个查询场景中随机挑选了 42 个 sql 并分别对比了 EMR SparkSQL、CDH Hive on Spark、CDH SparkSQL 三个计算引擎的执行时间,执行过程采用单线程并排除了 Spark 环境启动时间和缓存的影响,得出如下的测试结果:即 EMR 的 SparkSQL 执行效率是 CDH SparkSQL 的 2 倍以上。这得益于 EMR 5.24 版本以后 SparkSQL Runtime 优化的结果,关于 EMR Runtime for Apache Spark 的介绍见官方博客地址:https://aws.amazon.com/cn/blogs/big-data/amazon-emr-introduces-emr-runtime-for-apache-spark/。
 |
我们对同样的查询 SQL 针对 Redshift 兼容性调整后,再次进行数仓业务查询并发测试,测试过程使用了 Redshift RA3 类型(存算分离)4-8 节点,关闭了结果集缓存,并进行了全自动排序优化和手工调优的对比测试,测试结果如预期,查询性能随节点数增加线性增长,随查询并发数增加线性降低,手工调优后查询响应时间降低了 60%。下面是并发测试 8 节点优化前后查询响应时间(秒)趋势图:

云上的架构规划
新的大数据架构是基于亚马逊云科技的 EMR、Redshift、S3 等组件和 IDC 自建服务混合云模式搭建的。

数据源和数据缓冲区:新架构增加了 EFS 网络文件系统和多账号的 S3 用于文件分享和传输,其他同 IDC。
离线计算集群:使用 EMR 搭建大数据集群,采用 3 Master 节点,固定基线的 Core、Task 节点,加 Spot 弹缩资源提供离线计算服务。
OLAP 引擎:增加了 Redshift 提供数仓查询服务,保留 IDC 现有提供生产服务组件。
业务应用:报表可视化工具由 Tableau、BO、Davinci 等迁移至 FineBI,统一了数据门户。
数据安全:调整为 Ranger+Ldap 提供统一用户认证与鉴权,保障了数据安全。由 Ranger 替代 Sentry 提供细粒度的授权控制,S3 数据访问权限则由 IAM 策略进行管控。
数据开发平台:敦煌网大数据团队与合作伙伴共同打造集数据集成、数据开发、数据资产管理、数据服务等一站式大数据平台。
云上新架构能够带来的价值
- 弹性伸缩:基于亚马逊云科技的 EMR 存算分离架构,在计算层可以根据数据分析任务去灵活调度不同的算力,支持分钟级别的计算实例弹缩,解决了 IDC 资源从采购到部署上线需要的漫长时间和提前预制算力可能产生的资源浪费。
- 性能提升:Amazon EMR 上 Spark Runtime 性能相比开源 Spark 提升 1.7~2 倍左右,相同的资源使用下,可以更快的完成作业的执行。Presto 也做了 Runtime 的优化,性能相比 OSS 快 2.7 倍左右,接入 OLAP 的引擎做交互式查询分析,也会从中受益。
- 成本节省:Amazon EMR 可以根据计算需求变化灵活扩缩集群调整集群,在工作负载高峰时增加实例,在工作负载高峰过后移除实例。Amazon EMR 还提供了运行多个实例组的选项,可以在一个组中使用按需实例来保障处理能力,同时在另一个组中使用竞价型实例来加快任务完成速度并降低成本,可以利用混合多种实例类型以充分利用某种竞价型实例类型的定价优势。应用 S3 的智能分层去自动化管理数据生命周期,在不影响数据读写性能的同时相比 IDC 大幅降低存储成本。
- 开发效率:Amazon EMR 是全托管的云端数据平台,支持常驻、瞬态集群模式去分别适配每天的常规离线任务、临时数据分析和 Ad-Hoc 的任务,支持通过控制台界面或者 API 快速构建集群的能力,可以很方便和现有的大数据平台做集成,避免了传统自建集群日常维护的工作量,让大数据团队可以把更多的时间投入到技术探索中。
- 平台化数据底座:应用亚马逊云科技的智能湖仓架构,提供一个统一的、可共享的数据底座,避免传统的数据湖、数据仓库之间的数据移动,将原始数据、加工清洗数据、模型化数据,共同存储于一体化的“湖仓”中,既能面向业务实现高并发、精准化、高性能的历史数据、实时数据的查询服务,又能承载分析报表、批处理、数据挖掘等分析型业务。
核心技术架构
部署架构图

存算分离
- S3 EMRFS 的智能分层
大数据场景下存算分离的架构已经成为业界的共识,存储从之前的 HDFS 三副本磁盘存储到 S3 对象存储,S3 提供了 99.999999999% 的数据持久性保证,S3 的标准存储每 GB 相比 EBS(GP3)成本能节省 70% 以上,同时数据在 S3 上只需为一份数据付费,存储成本带来极大的节省。存算分离之后,架构会更加灵活,计算可以做到按需弹性扩展,通过 Amazon EMR 的 Auto Scaling/Managed Scaling 功能可以让计算资源的扩缩变得更简单高效。
EMRFS 文件系统是亚马逊云科技自研的 HDFS 文件系统的实现,EMRFS S3-optimized Committer 深度优化大数据场景下数据写 S3 的性能,不仅仅对于 Spark 写 S3 实现了 Multipart Upload 方式,避免 Rename 带来的性能损失,对于 Hive 也实现了类似的机制避免 Hive 写对象存储的三次 Rename 操作,在测试场景中最高有 15 倍的性能提升(https://aws.amazon.com/blogs/big-data/up-to-15-times-improvement-in-hive-write-performance-with-the-amazon-emr-hive-zero-rename-feature/),在 EMR 6.5.0 及以上版本可用。

S3 的智能分层可以根据文件访问模式自动将数据移动到最具成本效益的访问层,以优化存储成本。支持三个快速读写的数据访问层:Frequent Access Tier(FA)、Infrequent Access Tier(IA)和 Archive Instant Access Tier(AIA)。EMRFS 可以无缝地集成 S3 的智能分层,只需在 EMRFS 配置中指定 S3 的存储类为智能分层存储类即可。
我们大部分数据场景需要频繁访问最近三个月的数据,并且会不频繁访问三个月前的数据。当我们访问三个月前的数据时,也需要和访问 S3 标准存储的数据一样快。S3 智能分层支持 IA 和 AIA,它们与标准层具有相同的低延迟和高性能,但每 GB 单价比标准存储最高低 85%。在 EMRFS 配置智能分层后,我们既能保证高性能,又能进一步压缩存储成本。

Hive on Spark 到 SparkSQL 的升级
在从 CDH 6.x 到 EMR 6.x 的迁移过程中,同时也是在从 Hive On Spark(Spark 2.4)升级到 SparkSQL(Spark3.2)过程中碰到以下需要进行改造适配的问题:
| 问题类型 | 问题详细描述 | 解决方案 |
| sql 语法兼容性 | spark-sql 执行代码关联条件nvl(t.item_code,rand()) = p.item_code 报错,Error in query: nondeterministic expressions are only allowed in | spark sql 不支持在 on 条件中带有 rand(),需要去掉,或者改写成 t.item_code = p.item_code and t.item_code is not null |
| sql 语法兼容性 | spark-sql 执行代码中row_number() over()报错 | 修改成 row_number() over(order by 1) |
| sql 语法兼容性 | count(distinct rfx_id) over(partition by buyer_id) rfx_num 报错 | spark-sql 不支持开窗中count(distinct ),使用size(collect_set() over(partition by order by))写法 |
| sql 语法兼容性 | spark-sql 执行 hive parse_url_tuple 函数报错 | 使用 regexp_extract(link_url,’http[s]://[^/]+([^?^&^#]+).*’,1)截取 |
| sql 语法兼容性 | hive on tez 执行,代码中带有 time 字段,报错 | time 进行转义,在 hive sql 中写成`time`形式,在 shell 中写成\`time\`形式 |
| 函数兼容性 | timestamp 函数报错,Function timestamp accepts only one argument | 去掉第二个参数:yyyy-MM-dd hh:mm:ss |
| 函数兼容性 | split(visit_src_type,’\\|’)[3] 切出和原来数据不一致 | 增加转义符, 由 split(visit_src_type,’\\|’)[3] 变换成 split(visit_src_type,’\\\\|’)[3] |
| 函数兼容性 | confirm_date > add_months(‘${etl_date}’,-12) 判断条件,cdh 包含 12 月前的一天,emr spark-sql 执行不包含 | 改成 confirm_date >= add_months(‘${etl_date}’,-12)
验证 sql : select case when ‘2021-08-03 15:57:53’ = add_months(‘2022-08-03’,-12) then ‘等于’ else ‘不等于’ end as com1 |
| 数据类型兼容 | sql 字符串数值比较问题,rfx_gmv > 0 作为过滤条件 | rfx_gmv > 0 应变为 rfx_gmv > 0.0;修改 rfx_gvm 字段类型,alter table mds_rfx_info change column rfx_gmv rfx_gmv decimal(18,4) |
| 数据类型兼容 | spark 数据类型转换:Cannot safely cast ‘xxx’ :string to int | 1、添加参数 set spark.sql.storeAssignmentPolicy=LEGACY
2、字段做类型转换 cast(xxx as int) as xxx |
| spark 运行时 | spark-sql-e 执行,报错 Error in query: Cannot modify the value of a Spark config: spark.executor.cores | 去掉 sql 中 set spark.xxx.xxx=xxx;类似的参数 |
| spark 运行时 | spark submit 方式提交任务,中文字段乱码 | spark 配置参数 spark.driver.extraJavaOptions -Dfile.encoding=UTF-8 -Dsun.jnu.encoding=UTF-8 spark.executor.extraJavaOptions -Dfile.encoding=UTF-8 -Dsun.jnu.encoding=UTF-8 |
| 空值处理 | null 判断不一样 is not null and <>” | is not null |
| 空值处理 | cdh 中空值为‘’,idc 空值为‘\N’,筛选 columnname <> ” ,和 emr结果集不一样 | 重建表,新增 ROW FORMAT SERDE ‘org.apache.hadoop.hive.serde2.columnar.ColumnarSerDe’
textfile格式,建表语句新增 TBLPROPERTIES (‘serialization.null.format’=”) |
在更早的 CDH5 到 CDH6 的集群升级过程中,我们把计算引擎从 Hive 升级到 Hive On Spark,获得了数倍的性能提升,也解决了更多在 SQL 语法、UDF、数据文件格式、运行参数等方面的兼容性问题,在这里不一一列举。
Kudu+Impala 到数据湖(Hudi)的改造
我们需要将 900 多张数据库表同步到大数据平台以进行数据统计分析。在 IDC 中,我们使用 Canal 解析 Binlog Sink 数据并将其发送到 Kafka,以实现上下游的解耦,并且能够更好地进行数据回溯,例如从特定时间点的 Kafka Offset 消费数据。接下来,我们利用 Kudu 的 Upsert 功能将 Kafka 数据写入 Kudu,以确保数据的最终一致性。每天,我们会通过 Impala 将 Kudu 数据导出到 HDFS,作为处理原始数据层(ODS)的基础数据。
虽然该方案具有优势,但我们还有三个痛点。首先,Kudu 本身依赖于磁盘存储引擎,存储成本和运维成本比较高;其次,Impala 可能存在高并发稳定性差的问题,影响数据导出和查询;第三,由于原始数据需要进行大量加工处理才能为业务报表提供支持,因此我们无法直接使用 Impala 查询 Kudu 原始表为业务提供查询服务。由于考虑到成本、性能和扩展性等方面的原因,使用 Kudu 建立仓库也不是一个理想的方案。因此,Kudu 只是作为数据的一个中间层,其性价比不高,并且不能满足某些业务场景对实时数据分析的要求。
在云上,我们要实现智能湖仓架构,S3 作为中心数据湖,根据不同场景选择最具性价比的计算引擎。这样,数据可以在湖仓和计算引擎之间无缝流转。对于 900 张表 CDC 的场景,我们选择了 Hudi 作为解决方案。Hudi 对 Upsert 有很好的支持,支持准实时分钟级别延迟写入,并具备灵活的 Payload 机制,例如乱序入湖(DefaultHoodieRecordPayload)、部分字段更新(PartialUpdateAvroPayload)以及自定义 Payload 等。我们非常看重这些功能,因为我们的场景主要涉及更新和 JOIN 操作。使用乱序入湖可以让我们在计算过程中更加灵活地定义并行度,从而提高计算性能。只要保证 ts 字段顺序,我们就不需要考虑 CDC 数据的乱序问题。而 PartialUpdate 则可以将流式 Join 操作下沉到 Hudi 层来处理。例如,在 Flink 中通过状态进行多表 Join 时,我们可以使用 PartialUpdate 来实现,这样 Flink 就不需要关心状态的过期和 Watermark 的乱序处理。Spark 也可以利用 PartialUpdate 实现多表关联操作。
我们使用的是 Spark Structured Streaming 消费 Kafka 中多个 Topic(源端安装实例和库组合划分 Topic,不同的库会写到相同的Topic)CDC 数据 Sink 到 900 张 Hudi 表。在实现过程中我们有如下几点可以分享:
1. 我们使用 Spark 作业来处理 900 张表的写入操作,启动多个线程并行地写入多张表。每个程序管理 30~100 张表,并根据表的数据量大小划分不同的程序进行管理。例如,数据量较小的表可以由一个程序管理 100 张表,而数据量较大的表则由一个程序管理 30 张表。理论上,只要资源足够,一个程序就可以管理所有的 900 张表。但实际情况下,我们需要考虑失败快速恢复和业务优先级等问题,因此单个作业多线程的并行写入多张表不能达到多个作业写入多张表同样的性能。在 Structured Streaming 的 foreachBatch 中,我们使用多线程来进行写入操作。首先,我们将每个批次的 DataFrame 进行缓存,然后将 DataFrame 发送到多个线程中。每个线程按照表名过滤出属于自己的数据,并将其写入到 Hudi 中。最后,我们使用 unpersist 方法完成该批次的处理。
我们也尝试过使用多个 Streaming Query 方式来进行写入操作,但是这种方式存在问题。每个 Query 都会独立消费 Kafka 的数据,导致 Kafka 的消费流量激增。此外,想要通过 Kafka 监控工具直接监控 offset 也比较繁琐。因为每个 Streaming Query 都有对应的 consumer group 的 offset,如果使用同一个 consumer group,则会导致 offset 记录错误,被其他表的 offset 覆盖。
2. 我们使用的 EMR 版本是 6.6.0,这是一个比较新的版本。我们使用的 Hudi 版本是 0.10.1。虽然 Hudi 只是一个 package,计算引擎是解耦的,但我们不建议直接从开源社区下载 Hudi 并在 EMR 上运行。这是因为 Amazon EMR 对 Spark 做了性能优化,在源代码上进行了一定的修改,但 API 层和开源保持一致。EMR 上自带的 Hudi 包是基于自己的 Spark 编译的,并且已经过适配。直接使用开源的 Hudi 包可能会导致在某些特定场景下的兼容性问题。
目前,EMR 的版本已经更新到了 6.10.0,而 Hudi 的版本也升级到了 0.12.2。我们建议大家选择最新版本,因为 Hudi 高版本的稳定性和性能有了进一步提升,并且重要的功能也都得到了更新。例如,并发写支持基于 FileSystem 的锁,当在正在运行写入操作的表上进行 Compaction 或 Clustering 时,基于文件锁的配置会更加便捷。在 Schema 变更方面,可以通过设置 hoodie.datasource.write.schema.allow.auto.evolution.column.drop 来实现删除列,而不需要使用 Alter 语句。当作为动态 Schema 变更时,删除列的处理逻辑也会更加简单。
3. 对于 COW 和 MOR 表模式及 Index 的选择,可参考以下指标:
- 写入延迟 COW>MOR,写放大 COW>MOR,100MB,更新 10%,5 批次写,(100+500)MB。MOR 未 compaction 之前(100+50)MB
- MOR 更新代价低,因为写 deltafile,只有 merge
- 查询性能看情况 MOR<COW,COW 要比 MOR 简单易维护,没有 deltafile,没有 compaction 的逻辑
- bucket index 在频繁更新和大数据量级下有更好的表现,避免了 BLoom index 的假阳问题。通过 recordkey hash 直接定位 FileGroup•之前 buckets num 确定后不能修改 hudi-0. 12.0 实现了一致性 hash,可以动态调整桶个数 index.bucket.engine=CONSISTENT_ HASHING
- Hudi 的 PartialUpdateAvroPayload,实现了部分字段更新,解决了多表实时 JOIN 打宽在引擎侧无法很好处理的场景。这个 PayLoad 在此场景下非常好用,无需考虑多流 JOIN 之问的数据延迟
- MOR 表 inline compaction 在性能满足时是首选,单独程序做 compaction 需要锁,hudi>0. 12 基于文件的锁会更方便。只有在性能不满足时在考虑单独程序做,因为多了维护成本
- 一般的经验 2w/s 写入,30% update,Cow 表做没有问题;超过 2w/s,更新 50%+选择 MOR 表
- Flink Hudi 使用 Streaming Read 将整个数仓的链路做成实时,Flink 管理聚合状态计算。理论上可以做,但目前还没有看到有大规模的生产实践。基本还是数仓的 ODS,DIWD 层用的多,其它层的构建使用 Hudi 的相对较少,增量查询没有问题,但是下一层数仓写要有的聚合操作的,增量查无法实现聚合写入。还有一种就是 Hudi 宽表,实时摄入,直接接 API 引擎查询,满足分钟级别端到端延迟的需求
4. Spark 写入 Hudi 过程中的参数配置调整如下做参考:
我们使用 Spark Structured Streaming 写入 Hudi。目前我们使用 Trigger.Once 方式并非一直 Streaming 写入。主要考虑到成本因素,我们每天定时运行两个作业,总运行时间约 1.5 小时,占用了 50% 的离线集群资源。这种批处理方式有助于节省资源和控制成本。
对于那些对实时性要求较高的表,我们会使用 Streaming 写入以保证分钟级别的摄入延迟。
- 我们使用 COW 表,虽然有写放大,但逻辑相对 MOR 简单,没有 compaction 过程
- hoodie.datasource.write. table.type=COPY_ON_WRITE
- spark sql 的并行度默认 200,我们会调小该值,因为是多线程并行写多表,单表的数据量可控对单个表的写入不需要太多的 task,造成空跑的浪费,为了更好利用资源,会将 Spark sql 的默认并行度也调整为 10-20
- hoodie.upsert.shuffle.parallelism=20
- hoodie.insert.shuffle.parallelism=20
- 小文件的控制,为了防止更严重的写放大,文件不会设置太大,当使用 CON 表,同时又对摄入实时性要求高的,可以將该值调小,但带来的问题是小文件会多,需要定期做 clustering
- hoodie.parquet. small. file. limit=52428800
- index 选择的是 BLOOM,因为当时 Hudi 0.10 还不支持一致性 Hash 桶的个数一旦确定无法修改,后边会考虑 Bucket Index
- hoodie.index. type=GLOBAL_BLOOM
- DefaultHoodieRecordPayload 因为要乱序入湖
- hoodie.datasource.write.payload. class=org.apache.hudi.common. model. DefaultHoodieRecordPayload
- 表不设置分区,目的是为了简单,因为我们不开放业务直接查询 Hudi 表,所以性能可以接受
- hoodie.datasource.write.keygenerator.class=org.apache.hudi.keygen.NonpartitionedKeyGenerator hoodie.metadata.enable=true
- 我们暂时不需要增量读取太长时间数据 commits 保留设置的比较少,retained 保留 5 次提交 active timline 引用的对应版本的数据文件
- hoodie.cleaner.commits.retained=5
- 每 2 次提交检查一次 retained 的是否满足设置的条件
- hoodie.clean.max.commits=2
- 超过 6 次就 archive,最小值要大于 retained 的值
- hoodie.keep.min.commits=6
- hoodie.keep.max.commits=7
- type 我们设定为了 DIRECT,没有使用 Timeline-server-based marker,当时写 S3 遇到 Markers 找不到的错误,跟社区沟通后,暂时采用了 DIRECT 的方式
- hoodie.write.markers. type=DIRECT
乱序入湖,Hudi ts 字段生成逻辑
为了保证多次变更的同一记录从 binlog 生成,写入 Kafka 到最终消费 kafka 写入 Hudi 的数据一致性,我们对一个表的同一个 key 数据自定义了如下 ts 的三段式的生成逻辑:<CanalJsonTS>-<KafkaOffset>-<CanalJsonArrayIndex>,每段的详细含义:
CanalJsonTS:Canal 解析 Binlog 写入 Hudi 的时间戳(毫秒)
KafkaOffset:当前记录所在 Kafka Partition 的 offset 值
CanalJsonArrayIndex:当消费到的一条 Kafka 消息中的 CanalJson 的 Data 数组包含多条数据时,按数组 index 排序拼接
Kudu+Impala 成本节省
在 IDC 应用场景中,我们使用了 16 台服务器部署 Kudu 服务,承接了公司 95% 以上的业务数据库全量和增量数据,实现了业务数据秒级延迟入库,一些实时计算业务也可基于 Impala+Kudu 实现,但数据存储和使用成本高,后期维护成本高,在稳定性、扩展性、并发查询性能方面不足。在切换到 Hudi 方案后,我们和 EMR 集群公用计算资源,相比之前的硬件成本降低超过 75%,实现了准实时分钟级别延迟写入,借助 S3 作为数据湖,数据可在各计算引擎自由流转。
Spark 交互式查询 Kyuubi
为了给业务方提供统一的 JDBC 服务接口,我们部署了 SparkThriftServer 和 Kyuubi 服务,下面是我们使用过程中的一些经验。由于 SparkThriftServer 不支持多租户,我们未来会优先选择 Kyuubi 方案。
SparkThriftServer
在实际使用过程中,SparkThriftServer 的稳定性不足,不能满足多租户数据安全和资源隔离。时不时出现 Driver 端内存 OOM 进而查询服务崩溃的问题,引发 OOM 主要原因是为定时任务、即席查询数据量大并且并发集中,导致 Driver 端数据缓存不足。我们从以下三方面进行优化,OOM 问题有所改善,但并未完全避免出现:
1. 适当增加 driver-memory、spark.driver.maxResultSize 参数设置,并设置 spark.sql.thriftServer.incrementalCollect 为 true(该参数对结果集取回效率影响较大);
2. 通过 NLB 部署三个 SparkThriftServer 服务进行流量负载均衡,单节点异常时自动切换至仍可提供正常服务节点;
3. 定时报表任务分散执行;
4. 定期分析日志,优化查询结果集数据量大和引发 OOM 的 TopSQL。
Kyuubi 配置使用经验,权限,资源隔离,配置优化总结
Apache 开源项目 Kyuubi 提供了一个标准化的 JDBC 接口,基于 Spark 引擎提供高性能的多租户数据查询能力,通过水平扩展、负载均衡、引擎缓存等方式增强并发性和响应能力,同时提供鉴权服务保证数据安全,可以满足 ETL、BI 报表和 Ad-Hoc 查询等大数据应用场景,具有较高的稳定性、可靠性和安全性。
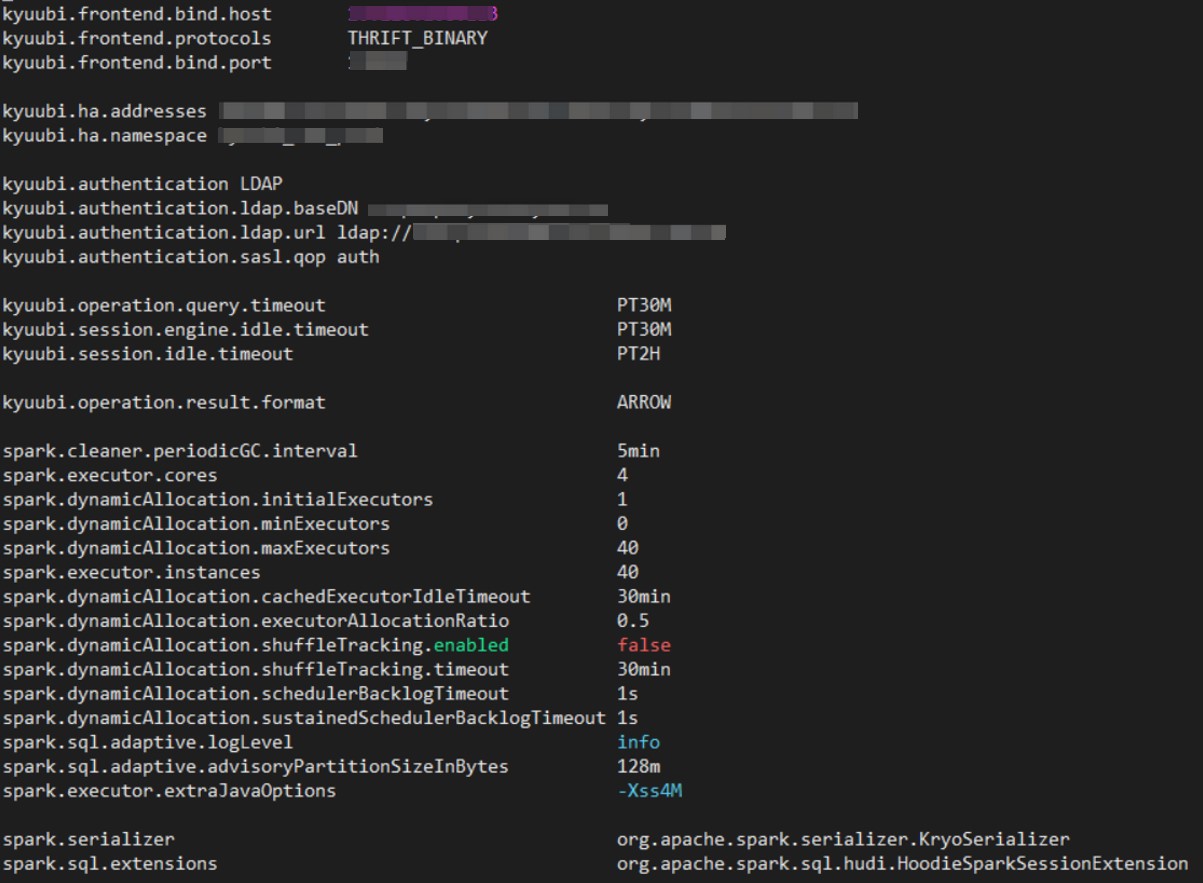
一个 Kyuubi 服务节点典型的参数配置参考下图:
随着新版本更多新特性的推出,我们还在持续跟进优化以改进服务稳定性、引擎执行效率和安全性。
OLAP 引擎之 Redshift
- Redshift 作为亚马逊云科技完全托管的云原生数仓产品,可以根据业务需要在几分钟内建立几个到几十个节点的数据仓库集群,支持数据分析的业务场景。支持复杂的数据查询语句做高性能的并行查询,通过 COPY/UNLOAD 命令很方便的和 S3 做数据交互,如果需要对 S3 上的数据做临时查询,不需要做数据加载,利用 Redshift Spectrum 直接支持做外表查询。
- 低运维成本和基于 ML 的自动优化
- 生产环境环境查询响应时间分布
- 50% <10s
- 70% <20s
- 80% <30s
- 90% <60s
- 95% <80s
- 98% <180s
- 99% <360s
- Concurrency Scaling 功能支持突发的高并发查询,并可提供始终如一的快速查询性能。对于写入(如 COPY、INSERT、UPDATE 和 DELETE)可以在排队时在瞬态 Concurrency Scaling 集群上运行,Concurrent Scaling 在算力不足时,快速弹出原有集群数倍的算力提升数据处理速度。
以下是工作日生产环境并发扩展集群使用情况:

- 扩容的故障问题
在半年的使用时间里,我们也遇到了 Redshift 的几个服务故障,例如:天级别定时扩容调度任务失败和集群扩容超时导致失败回退,经过亚马逊云科技的后台技术支持团队排查是服务版本升级引发的 Bug,并且已经完成了修复。
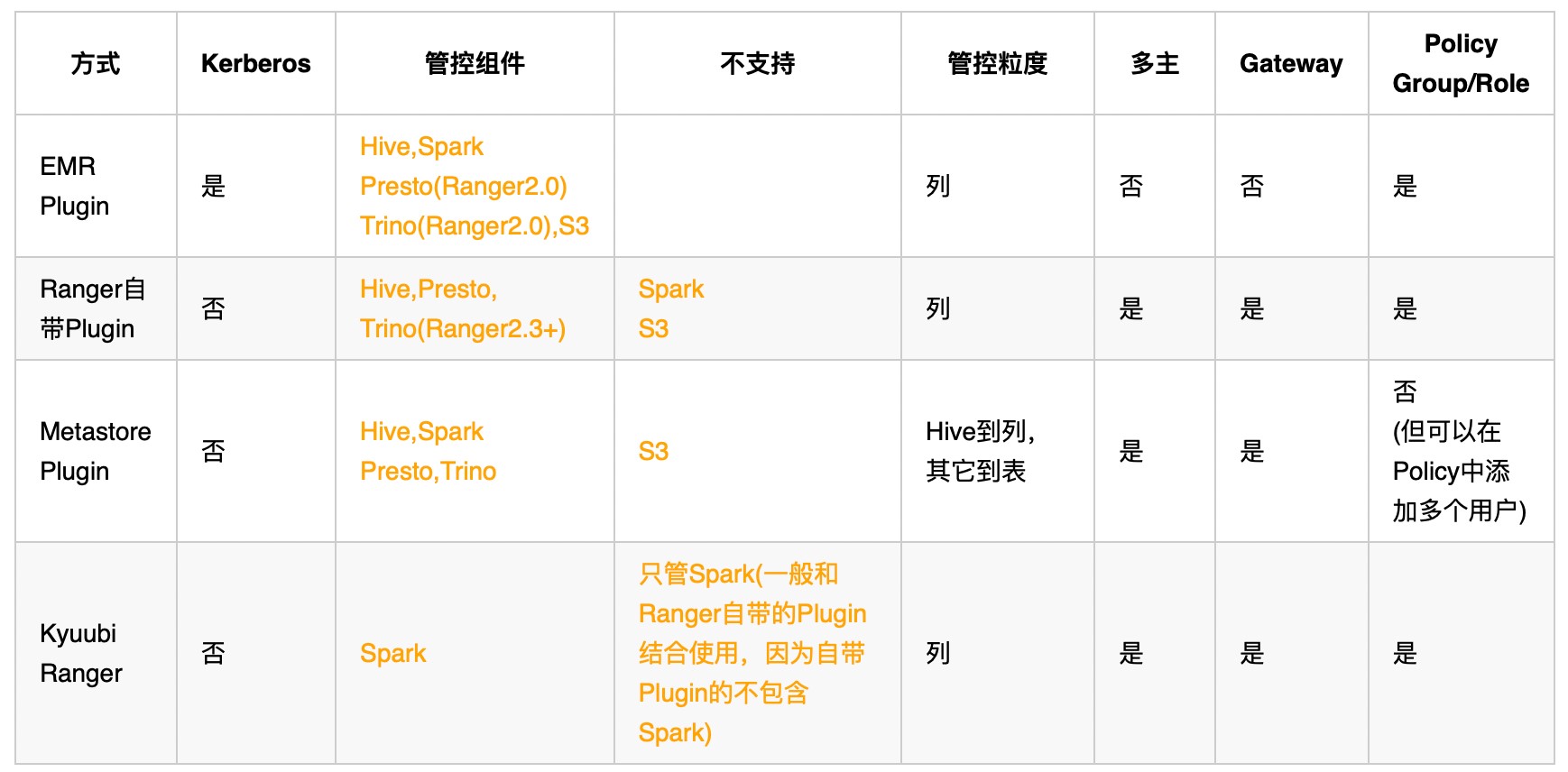
Ranger 的权限控制
Ranger 提供了四种权限控制方案,包括 EMR Plugin、Ranger Metastore Plugin 等。我们最初尝试了 EMR Plugin,但由于必须启用 Kerberos,且不支持多主,最终放弃了这个方案。目前我们采用的是 Ranger Metastore Plugin,它的部署简单、维护方便,一个 Plugin 就可以管 Hive、Spark、Trino 和 Presto。不过,该方案对于视图权限的支持不太好,如果给了用户视图权限,视图中包含的表的权限也需要开放。因此,我们将考虑使用 Kyuubi Ranger Plugin。在选择 Plugin 方案时,我们的经验是:
1. 非必要,不选择 EMR Ranger Kerberos。维护成本高,管理复杂,出问题不易定位。适合本身对 Kerberos 有一定经验,且接受非多主;
2. 如果 Spark,Presto,Trino 只需管表级别权限,选 Metastore Plugin,只需要部署一个 Plugin 即可。不支持 Group/Role 设置 Policy,但可以在 Policy 中添加多个用户;
3. 如果要管到列级别权限,Ranger 自带 Plugin + Kyuubi Ranger Plugin。Kyuubi Ranger Plugin 并不是要安装 Kyuubi,而只是使用 Spark 的 Ranger 插件,该插件最早命名为 Spark-Ranger,后续作者将其合并到了 Kyuubi 项目中,支持 Spark3.x,可单独部署。
最终的成果
经过前期深入的技术调研,我们制定了详细的迁移方案。最终,在三个多月的数据作业迁移后,项目如期上线并稳定运行,达到了预期目标:
1. 大数据集群的运行硬件和维护成本降低了 30%;
2. 解决了 IDC 集群无法通过扩展节点来增加算力、存储和网络流量的瓶颈问题;
3. 实现了 EMR 和 Redshift 集群、定时、分钟级多种动态弹性扩缩容方式,以满足业务潮汐效应的资源需求,提高数据查询效率达到 100%;
4. 数据架构完成了云原生的改造和升级,实现了数据实时入湖、存算分离架构,支撑未来更多实时和离线业务场景需求,例如 AIGC、智能湖仓、实时用户画像搜索推荐等;
5. 大数据中台的上线使数据开发、测试、发布、运维流程规范化,提高了开发效率 40%,数据资产管理的数据地图、数据血缘等功能提高了数据探查效率,有效降低了数据使用沟通成本。
未来的展望和规划
实时计算 & 准实时湖仓一体
随着 AIGC 技术爆发式发展和应用,未来的数据增长趋势将会是实时的、高质量的、大规模的。为了应对这一趋势,需要建立准实时的数据湖仓,以便实时收集数据,并在数据到达几秒钟或几分钟内完成处理和存储,快速提取有价值的信息以便响应实时的业务需求和决策。
Serverless 做为现有架构未来演进方向
Amazon EMR 和 Redshift 的 Serverless 可以为用户提供更加灵活、高效、低成本和可靠的数据处理解决方案,无服务意味着可以按需使用资源付费,避免长期运行的服务器和运维成本,更简单、快速的部署时间,根据工作负载自动伸缩计算资源。随着 Serverless 在国内亚马逊云科技落地,目前常驻+弹缩节点的模式也逐渐转向 Serverless,以更好的平衡成本和满足业务资源需求。
尝试 Amazon EMR Auto Scaling
目前生产上的弹缩策略是基于经验的定时任务,往往不够灵活和及时,在某些突发时间的业务高峰需人工频繁介入调节资源,在保证稳定性的前提下尝试启用 EMR Auto Scaling 以确保集群始终能够满足业务需求,避免过度或不足分配资源造成的浪费,并降低集群管理的人力和时间成本。