AWS Big Data Blog
Up to 15 times improvement in Hive write performance with the Amazon EMR Hive zero-rename feature
Our customers use Apache Hive on Amazon EMR for large-scale data analytics and extract, transform, and load (ETL) jobs. Amazon EMR Hive uses Apache Tez as the default job execution engine, which creates Directed Acyclic Graphs (DAGs) to process data. Each DAG can contain multiple vertices from which tasks are created to run the application in parallel. Their final output is written to Amazon Simple Storage Service (Amazon S3).
Hive initially writes data to staging directories and then move it to the final location after a series of rename operations. This design of Hive renames supports task failure recovery, such as rescheduling the failed task with another attempt, running speculative execution, and recovering from a failed job attempt. These move and rename operations don’t have a significant performance impact in HDFS because it’s only a metadata operation when compared to Amazon S3 where the performance can degrade significantly based on the number of files written.
This post discusses the new optimized committer for Hive in Amazon EMR and also highlights its impressive performance by running a TPCx-BB performance benchmark and comparing it with the Hive default commit logic.
How Hive commit logic works
By default, Apache Hive manages the task and job commit phase and doesn’t have support for pluggable Hadoop output committers, which you can use to customize Hive’s file commit behavior.
In its current state, the rename operation with Hive-managed and external tables happens in three places:
- Task commit – The output of task attempts is stored in its own staging directory. In the task commit phase, they’re renamed and moved to a task-specific staging directory.
- Job commit – In this phase, the final output is generated from the output of all committed tasks of a job attempt. Task-specific staging directories are renamed and moved to the job commit staging directory.
- Move task – The job commit staging directory is renamed or moved to the final table directory.
The impact of these rename operations is more significant on Hive jobs writing a large number of files.
Hive EMRFS S3-optimized committer
To mitigate the slowdown in write performance due to renames, we added support for output committers in Hive. We developed a new output committer, the Hive EMRFS S3-optimized committer, to avoid Hive rename operations. This committer directly writes the data to the output location, and the file commit happens only at the end of the job to ensure that it is resilient to job failures.
It modifies the default Hive file naming convention from <task_id>_<attempt_id>_<copy_n> to <task_id>_<attempt_id>_<copy_n>-<query_id>. For example, after an insert query in a Hive table, the output file is generated as 000000_0-hadoop_20210714130459_ba7c23ec-5695-4947-9d98-8a40ef759222-1 instead of 000000_0, where the suffix is the combination of user_name, timestamp, and UUID, which forms the query ID.
Performance evaluation
We ran the TPCx-BB Express Benchmark tests with and without the new committer and evaluated the write performance improvement.
The following graph shows performance improvement measured as total runtime of the queries. With the new committer, the runtime is better(lower).
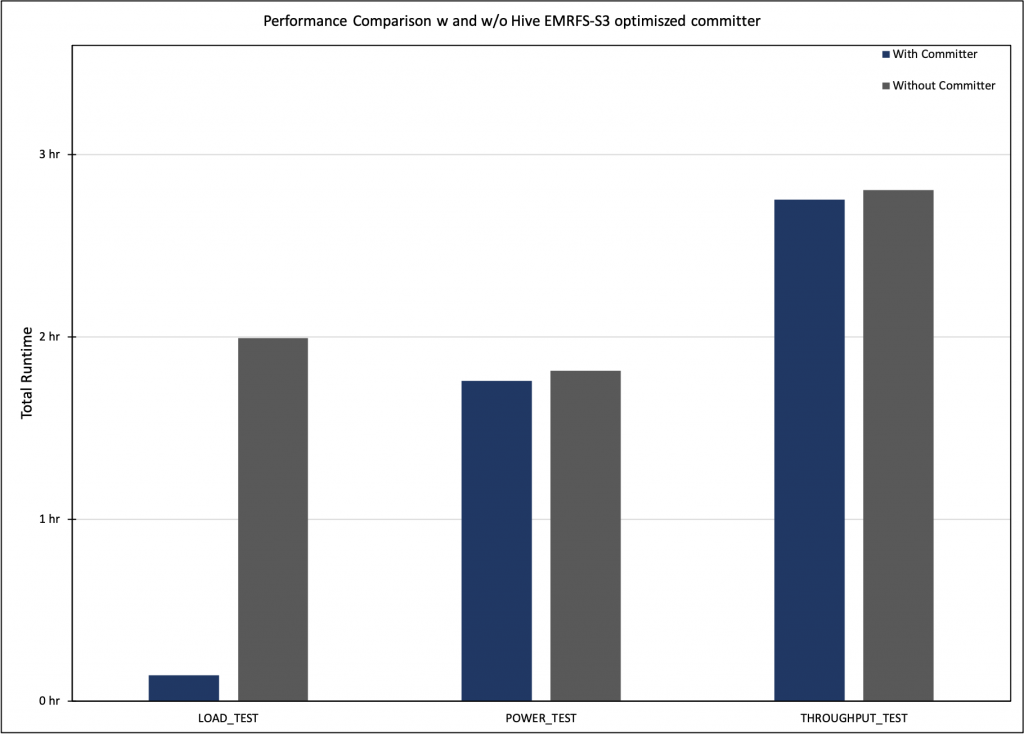
This optimization is for Hive writes and hence the majority of improvement occurred in the load test, which is the writing phase of the benchmark. We observed an approximate 15-times reduction in runtime. However, we didn’t see much improvement in the power test and throughput test because each query is just writing a single file to the final table.
The benchmark used in this post is derived from the industry-standard TPCx-BB benchmark, and has the following characteristics:
- The schema and data are used unmodified from TPCx-BB.
- The scale factor used is 1000.
- The queries are used unmodified from TPCx-BB.
- The suite has three tests: the load test is the process of building of test database and is write heavy; the power test determines the maximum speed the system takes to run all the queries; and the Throughput test runs the queries in concurrent streams. The run elapsed times are used as the primary metric.
- The power tests and throughput tests include 25 out of 30 queries. The five queries for machine learning workloads were excluded.
Note that this is derived from the TPCx-BB benchmark, and as such is not comparable to published TPCx-BB results, as the results of our tests do not comply with the specification.
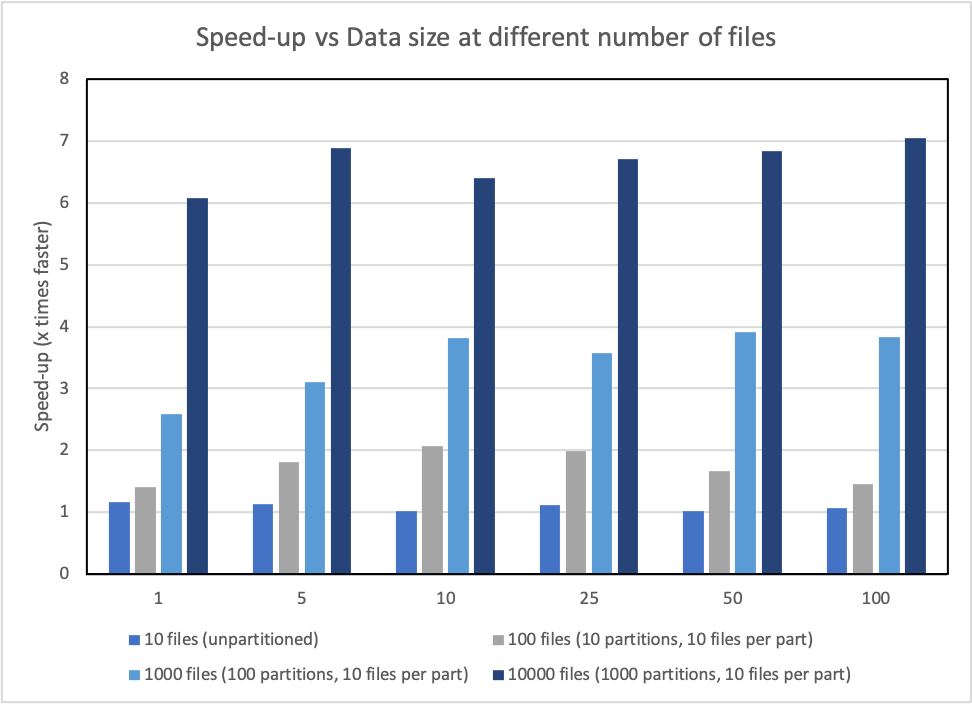
Understanding performance impact with different data sizes and number of files
To benchmark the performance impact with variable data sizes and number of files, we also evaluated the following INSERT OVERWRITE query over the store_sales table from the TPC-DS dataset with additional variations, such as size of data (1 GB, 5 GB, 10 GB, 25 GB, 50 GB, 100 GB), number of files, and number of partitions:
The results show that the number of files written is the critical factor for performance improvement when using this new committer in comparison to the default Hive commit logic.
In the following graph, the y-axis denotes the speedup (total time taken with rename / total time taken by query with committer), and the x-axis denotes the data size.
Enabling the feature
To enable Amazon EMR Hive to use HiveEMRFSOptimizedCommitter to commit data as the default for all Hive-managed and external tables, use the following hive-site configuration starting with EMR 6.5.0 or EMR 5.34.0 clusters:
The new committer is not compatible with the hive.exec.parallel=true setting. Be sure to not enable both settings at the same time in Amazon EMR 6.5.0. In future EMR releases, parallel execution will automatically be disabled when the new Hive committer is used.
Limitations
This committer will not be used and default Hive commit logic will be applied in the following scenarios:
- When merge small files (
hive.merge.tezfiles) is enabled - When using Hive ACID tables
- When partitions are distributed across file systems such as HDFS and Amazon S3
Summary
The Hive EMRFS S3-optimized committer improves write performance compared to the default Hive commit logic, eliminating Amazon S3 renames. You can use this feature starting with Amazon EMR 6.5.0 and Amazon EMR 5.34.0.
Stay tuned for additional updates on new features and further improvements in Apache Hive on Amazon EMR.
About the Authors
 Suthan Phillips works with customers to provide them architectural guidance and helps them achieve performance enhancements for complex applications on Amazon EMR. In his spare time, he enjoys hiking and exploring the Pacific Northwest.
Suthan Phillips works with customers to provide them architectural guidance and helps them achieve performance enhancements for complex applications on Amazon EMR. In his spare time, he enjoys hiking and exploring the Pacific Northwest.
 Aditya Shah is a Software Development Engineer at AWS. He is interested in Databases and Data warehouse engines and has worked on distributed filesystem, ACID compliance and metadata management of Apache Hive. When not thinking about data, he is browsing pages of internet to sate his appetite for random trivia and is a movie geek at heart.
Aditya Shah is a Software Development Engineer at AWS. He is interested in Databases and Data warehouse engines and has worked on distributed filesystem, ACID compliance and metadata management of Apache Hive. When not thinking about data, he is browsing pages of internet to sate his appetite for random trivia and is a movie geek at heart.
 Syed Shameerur Rahman is a software development engineer at Amazon EMR. He is interested in highly scalable, distributed computing. He is an active contributor of open source projects like Apache Hive, Apache Tez, Apache ORC and has contributed important features and optimizations. During his free time, he enjoys exploring new places and food.
Syed Shameerur Rahman is a software development engineer at Amazon EMR. He is interested in highly scalable, distributed computing. He is an active contributor of open source projects like Apache Hive, Apache Tez, Apache ORC and has contributed important features and optimizations. During his free time, he enjoys exploring new places and food.