引言:规模化内容创作的挑战
从数据到富有洞察力的内容
在数字经济时代,企业面临“海量数据、匮乏洞察”的悖论。核心需求已从单纯的数据处理,升级为自动化生成高质量、可执行的内容,例如高管财务报告、市场情报、合规文档及定制化客户沟通材料。企业不再满足于原始数据,而是需要能够揭示趋势、辅助决策的叙事性洞察。
以电商成本优化平台为例,其目标是为海量商家提供定制化的诊断报告。传统人工方式不仅效率低下,且难以保证分析深度与一致性。这折射出企业的共性挑战:如何将分散的结构化数据,如销售额、库存、广告费与非结构化信息,如政策、研报进行有效整合,转化为规模化、个性化且具商业价值的内容产出。
范式转移:迈向多智能体系统
为突破单一模型瓶颈,Multi-Agent系统成为新范式。其核心是用专业化协作的智能体集群取代单体模型,复刻了人类团队的高效分工:由项目经理拆解任务,分析师、研究员及撰稿人各司其职。各Agent凭借专属工具在统一框架下协同,不仅提升了系统的模块化与可维护性,更为实现复杂的类人推理与规划循环奠定了基础。
LangGraph 与 Bedrock AgentCore 的强强联合
本文提出一套生产就绪的企业级内容生成架构蓝图。该方案融合了 LangGraph 的动态有状态编排能力与 Amazon Bedrock AgentCore 的全托管安全环境。前者作为“大脑”实现复杂循环推理,后者提供“躯体”保障生产级的扩展性与稳定性。二者结合,为企业构建解决复杂业务痛点的下一代 GenAI 应用提供了明确路径。
高阶解决方案架构
架构总览
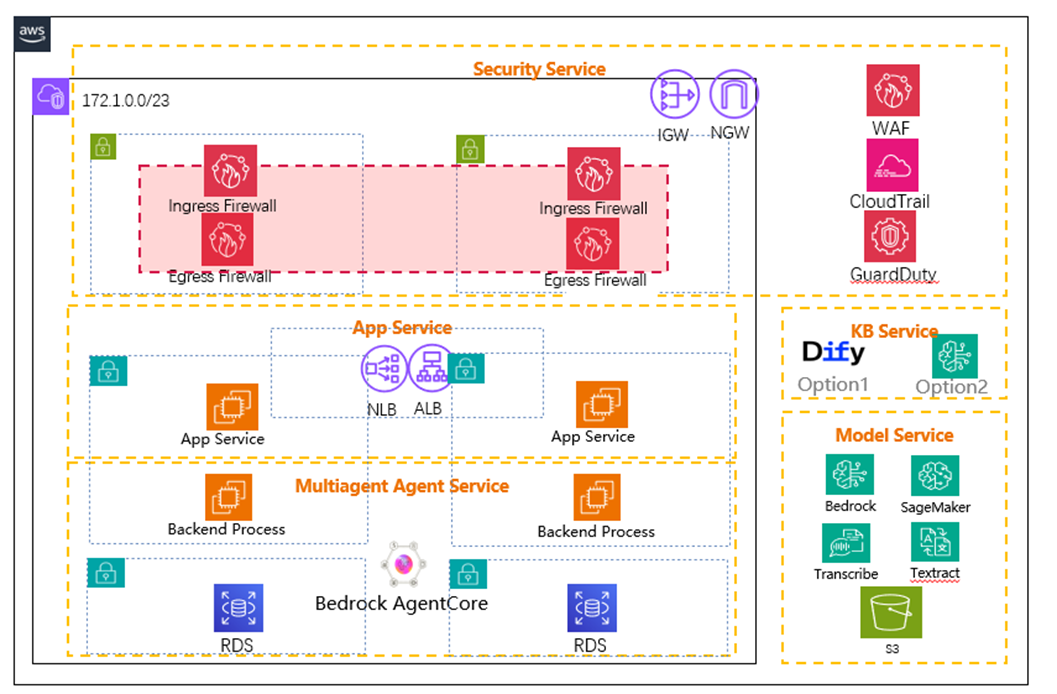
构建企业级端到端内容生成方案,需遵循分层设计与纵深防御原则。系统不仅聚焦核心 AI 逻辑,更必须全面覆盖安全性、扩展性、可靠性及可观测性等生产级指标。下图展示了该通用高阶架构,它将具体业务场景抽象为可复用的设计模式:通过特定 AWS 服务构建逻辑分层,实现严格的关注点分离与模块化。
图: 内容生成平台高可用部署架构
架构层次深度解析
多智能体服务与托管运行时
这里是整个解决方案的核心和智能中枢,所有复杂的推理和生成任务都在此完成。
- Backend Process (LangGraph Application): 封装多智能体协作逻辑的容器化应用。全权负责任务拆解、工具调用、状态机流转及循环推理等核心“思考”过程。
- Amazon Bedrock AgentCore: 提供全托管、无服务器的运行环境。自动接管基础设施的部署、扩缩容及安全隔离,大幅降低运维成本,使团队聚焦业务逻辑。
数据与模型服务层
这一层为上层的智能引擎提供所需的数据、知识和基础模型能力,是系统智能的源泉。
- Amazon RDS for PostgreSQL: 兼具业务数据存储与状态持久化双重职能。既管理销售、成本等结构化数据,又作为 LangGraph 的 Checkpoints(工作流快照)与 Stores(跨会话记忆)存储层,保障系统容错性与长期记忆能力。
- Amazon Bedrock & Amazon SageMaker: 提供模型服务接口,支持按场景择优:利用 Anthropic Claude 生成高质量文本,Amazon Nova 处理复杂推理,Cohere 优化 RAG 检索排序。
- Amazon S3, AWS Lambda, Amazon Textract: 构成非结构化数据湖与动态工具链。S3 存储政策/研报等文档;Lambda 封装 Textract 能力作为原子化工具,实现对 PDF 或图片的实时 OCR 提取与分析。
端到端示例:生成季度业务回顾(QBR)报告
为了让这个抽象的架构变得具体,让我们以一个常见的企业场景——生成季度业务回顾报告(QBR)为例,追踪一个完整的请求流程:
- 请求链路与鉴权 业务经理发起请求,经 ALB 转发至 App Service 完成身份验证后,唤起部署于 Bedrock AgentCore Runtime 的多智能体服务。
- 工作流初始化(Orchestrator) 编排智能体(Orchestrator Agent) 接管请求,生成会话 ID(thread_id),并通过 RDS for PostgreSQL 的 Store Checkpointer 持久化初始状态,确保会话上下文可追溯。
- 任务并行分解 编排智能体将目标拆解为并行子任务:
- Data Analysis Agent: 连接业务系统或解析上传文件,提取核心指标(GMS, GV, Units, SKUs, ASP, CR)。
- Knowledge Retrieval Agent: 调用 Amazon Bedrock Knowledge Base,检索市场趋势、竞品分析及相关政策文档。
- 迭代式推理与归因(Looping & Reasoning) 系统进入动态推理循环。若发现数据异常(如某 SKU GMS 下滑),编排智能体将触发**下钻分析(Drill-down)**指令:
- 根因排查: 指示分析智能体关联 GV、CR、ASP 等维度,验证是否因广告缩减或促销力度不足导致。
- 外部归因: 指示检索智能体查询同期外部事件。
- 注:每一步状态变更均实时写入 RDS,保障故障恢复能力。
- 结构化内容合成 所有洞察收敛至 Report Generation Agent。智能体基于预定义的 JSON 模板,调用 Anthropic Claude 4 模型,将图表数据(结构化)与市场摘要(非结构化)融合,生成逻辑严密的 QBR 报告。
- 交付与反馈 最终报告经由 App Service 返回前端界面。
为了清晰地总结每个服务在架构中的定位和价值,下表提供了一个概览。
| AWS 服务 |
所属架构层 |
主要角色 |
次要角色 |
| AWS WAF |
安全服务层 |
在网络边缘防护常见的 Web 攻击和 DDoS 攻击。 |
提供基于规则的流量过滤和速率限制,增强应用安全性。 |
| Amazon GuardDuty |
安全服务层 |
持续监控 AWS 账户中的恶意活动和异常行为。 |
基于机器学习的智能威胁检测,简化安全运维。 |
| Application Load Balancer (ALB) |
应用服务层 |
分发入站应用流量,实现负载均衡和高可用性。 |
支持基于内容的路由,SSL/TLS 终端,与 WAF 集成。 |
| Amazon Bedrock AgentCore Runtime |
多智能体服务层 |
为容器化的 LangGraph 应用提供无服务器、可扩展且安全的执行环境。 |
极大地简化 DevOps 负担,自动处理扩缩容和会话隔离。 |
| Amazon RDS for PostgreSQL |
数据与模型层 |
存储结构化业务数据,并为智能体记忆提供持久化后端。 |
支持 Multi-AZ 部署以实现高可用性,提供读副本以扩展读取性能。 |
| Amazon Bedrock |
数据与模型层 |
提供对多种领先基础模型的 API 访问,赋能智能体的推理和生成能力。 |
简化模型集成,提供模型选择的灵活性,统一计费和管理。 |
| Amazon S3 |
数据与模型层 |
作为数据湖,存储非结构化数据如文档、图片,并作为产物的存储桶。 |
高持久性、高可用性、低成本的对象存储,易于扩展。 |
| AWS IAM |
(跨层) |
控制对所有 AWS 资源的访问,实施最小权限原则。 |
为每个组件提供精细化的权限管理,是云安全的核心。 |
多智能体生成引擎:基于 LangGraph 构建协作式 AI
选择 LangGraph源于对循环式、有状态工作流的需求
选择 LangGraph 并非单纯的技术升级,而是对 AI 开发范式的重构。传统基于 DAG(有向无环图)的框架仅支持单向线性流,无法适配企业级任务中本质上的循环逻辑。 LangGraph 的核心价值在于原生支持循环图,赋予系统“反思”、“重试”与“自我修正”的能力。这种架构复刻了人类专家“建立假设-验证证据-迭代修正”的认知闭环,使 AI 从简单的指令执行者进化为具备复杂推理能力的合作伙伴。这意味着开发重心已从单一的 Prompt 调优转向了更系统的工作流工程。
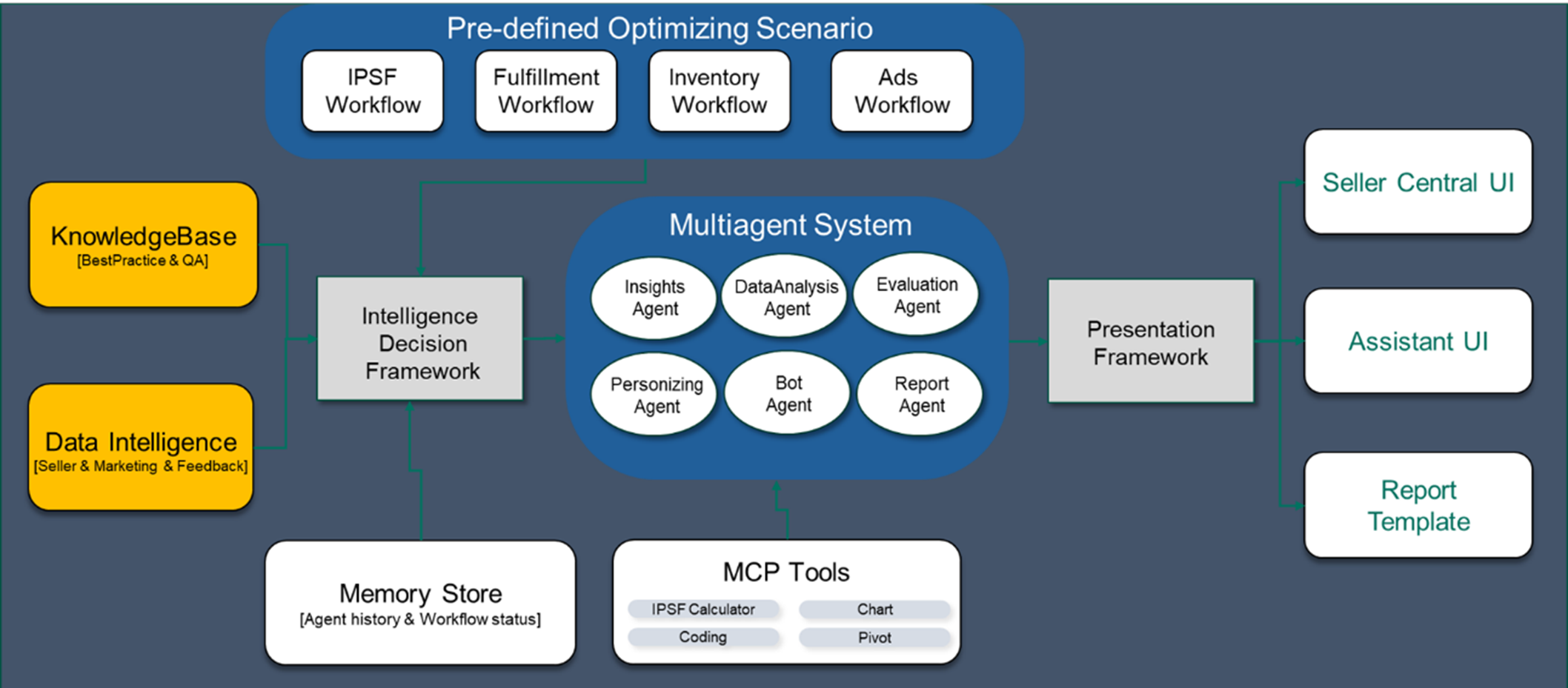
设计协作式智能体团队
针对内容生成场景,构建由以下原型智能体组成的专业团队:
- Orchestrator Agent (编排智能体/项目经理): 工作流的流量入口与总指挥。负责全局状态管理,解析初始意图,将复杂目标拆解为子任务,并依据上下文动态分发给下游 Agent。
- Data Analysis Agent (数据分析智能体/量化分析师): 精通结构化数据处理。具备 SQL 查询与复杂业务逻辑计算能力(如物流成本演算),并能产出可视化图表以辅助决策。
- Knowledge Retrieval Agent (知识检索智能体/研究员): 基于 RAG(检索增强生成) 技术。通过与 Amazon Bedrock Knowledge Base 交互,从非结构化文档(政策、FAQ、研报)中精准提取高相关度信息。
- Report Generation Agent (报告生成智能体/内容架构师): 负责最终内容的合成与标准化。汇聚结构化数据与非结构化洞察,基于可配置的 JSON/XML 模板调用大模型,生成逻辑严密、格式合规的专业报告。
图: 智能体应用程序架构
LangGraph 中状态与记忆的力量
如果说循环图提供了逻辑骨架,那么状态与记忆则是系统的神经中枢。LangGraph 通过显式状态管理与持久化机制,解决了 AI 应用从原型迈向生产级稳定性的关键难题。
- 显式状态管理 (Explicit State Management)
LangGraph 基于 StateGraph 架构,利用中心化的状态对象(通常定义为 Python TypedDict)在节点间流转。
- 全链路可观测性: 状态对象在每一步都被显式传递与更新。这意味着系统当前的假设、已获信息及后续计划对开发者完全透明,为复杂 Agent 行为的调试与控制流治理提供了确定性基础。
- 基于 Checkpointers 的持久化执行 (Durable Execution)
利用 PostgreSQL 等可靠后端作为 Checkpointers,实现企业级的高可用与连续性。
- 短期记忆(容错与人机协同): 基于 thread_id 标识会话,系统自动将每一次状态变更保存为快照(Checkpoint)。
- 故障恢复: 若因网络或工具故障中断,工作流可直接从最新快照无缝恢复,避免重复计算。
- Human-in-the-Loop: 天然支持“暂停-审查-继续”模式,无需复杂编码即可在关键决策点引入人工干预,随后携带完整上下文继续运行。
- 长期记忆(持续学习): 通过将跨会话的关键数据(用户偏好、历史方案)持久化至专用存储(Store),构建系统的“长期记忆”。这使 Agent 能够基于历史经验进行自我优化,实现真正个性化与具备学习能力的长期服务。
以下是一个定义状态和初始化带持久化后端的图的代码示例:
from typing import List, TypedDict, Annotated
from langgraph.graph import StateGraph
from langgraph.checkpoint.aiopostgres import PostgresSaver
import operator
# 1. 定义中心状态对象
# 这个 TypedDict 定义了在整个工作流中传递的数据结构。
class AgentState(TypedDict):
# 初始用户请求
initial_request: str
# 数据分析结果
analysis_result: dict
# 知识检索的上下文
retrieved_knowledge: List[str]
# 最终报告内容
final_report: str
# 用于记录中间步骤的消息列表
intermediate_steps: Annotated[List[str], operator.add]
# 2. 初始化数据库支持的 Checkpointer
# 这使得工作流的每一步状态都能被持久化到 PostgreSQL 数据库中
db_conn_info = "postgresql+psycopg://user:password@host:port/dbname"
memory = PostgresSaver.from_conn_string(db_conn_info)
# 3. 创建 StateGraph 实例
# 将状态定义和 Checkpointer 传入,构建一个有状态、可持久化的工作流图
workflow = StateGraph(AgentState)
#... 在这里添加节点 (nodes) 和边 (edges)...
# 4. 编译图
# 编译后的 app 对象就是一个可执行的、具备持久化能力的应用
app = workflow.compile(checkpointer=memory)
编排复杂的业务逻辑
LangGraph 通过图论抽象,将复杂的业务规则(如决策树)直接映射为可执行的系统架构。
- 节点 (Nodes) —— 原子化业务动作 将每个业务步骤(如“查询销量”、“计算 ROI”)封装为独立的 Python 函数。遵循严格的接口规范:接收当前 AgentState 作为输入,仅返回包含更新信息的状态增量(State Update)。这种设计实现了业务逻辑的高度解耦与模块化。
- 条件边 (Conditional Edges) —— 动态决策路由 承载控制流逻辑。不同于静态的顺序连接,条件边通过路由函数实时评估当前状态(例如检测 state[‘analysis_result’] 中的异常标记),动态决定下一个执行节点。这使得系统能够完美复刻包含复杂分支(Branching)的非线性业务流程。
这种“节点+边”的模式,实现了从业务流程图到代码实现的同构映射。以下代码片段展示了基于分析结果动态选择路径(生成报告 vs 用户澄清)的实现逻辑:
from typing import Literal
# 假设 data_analysis_node 节点执行后,会更新 state['analysis_result']
# analysis_result 可能包含一个 'status' 字段
def route_after_analysis(state: AgentState) -> Literal["generate_report", "clarify_with_user", "__end__"]:
"""
这是一个路由函数,用于实现条件边。
它检查数据分析节点的结果,并决定下一步的走向。
"""
print("---DECISION: ROUTING AFTER DATA ANALYSIS---")
analysis_status = state.get("analysis_result", {}).get("status")
if analysis_status == "success":
# 数据完整且分析成功,进入报告生成环节
print("Decision: Analysis successful. Proceeding to report generation.")
return "generate_report"
elif analysis_status == "insufficient_data":
# 数据不足,需要与用户交互以获取更多信息
print("Decision: Insufficient data. Routing to user clarification.")
return "clarify_with_user"
else:
# 出现无法处理的错误,结束工作流
print("Decision: Analysis failed with an unrecoverable error. Ending workflow.")
return "__end__"
# 在构建图时,将这个路由函数与一个条件边关联起来
# workflow.add_node("data_analyzer", data_analysis_node)
# workflow.add_conditional_edges(
# "data_analyzer",
# route_after_analysis,
# {
# "generate_report": "report_generator",
# "clarify_with_user": "user_interaction_node",
# "__end__": END
# }
# )
通过这种方式,LangGraph 提供了一个强大而灵活的框架,用于构建能够模拟复杂人类专家工作流程的、真正智能的企业级内容生成引擎。
构建安全、可扩展、高可靠的企业级应用
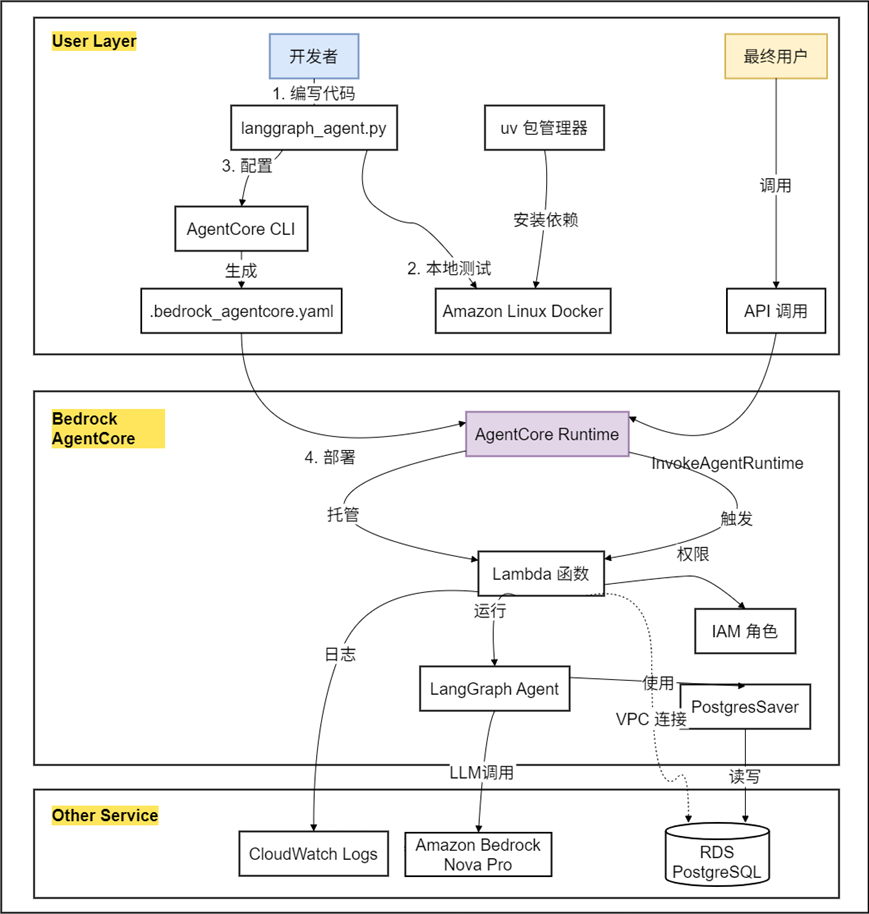
从原型到生产: Agent部署设计
将本地运行的 LangGraph 原型转化为生产级服务,必须跨越基础设施的“最后一公里”:如何实现算力的无服务器自动伸缩?如何安全暴露内部 API?如何保障状态存储的高可用与持久性? 解决这些“非差异化繁重工作”正是 Amazon Bedrock AgentCore 的核心价值。它作为专为智能体工作负载设计的 PaaS,全托管了底层执行、工具集成与记忆管理,使开发团队能专注于核心业务逻辑的实现。
- Amazon Bedrock AgentCore Runtime: 专为长运行、有状态工作流优化的无服务器(Serverless)容器环境。
- 弹性伸缩: 支持自动扩缩容,精准适配负载波动。
- 安全隔离: 强制执行会话级隔离,确保多租户环境下的数据边界。
- 身份管控: 原生集成 AWS IAM,为智能体运行提供细粒度的身份鉴权与资源访问控制。
整体架构图
Langraph BAC部署示例
步骤 1: 准备环境(使用 uv + Amazon Linux)
启动开发环境
推荐使用 Amazon Linux进行开发和测试,因为它与 Lambda 运行时环境一致。
安装 uv(快速 Python 包管理器)
curl -LsSf https://astral.sh/uv/install.sh | sh
export PATH="$HOME/.cargo/bin:$PATH"
uv --version
创建项目
mkdir langgraph-agentcore-postgres
cd langgraph-agentcore-postgres
uv venv
source .venv/bin/activate
安装依赖
uv pip install bedrock-agentcore bedrock-agentcore-starter-toolkit langgraph langchain-aws psycopg2-binary sqlalchemy
agentcore --help
python -c "import langgraph; print('LangGraph version:', langgraph.version)"
安装系统依赖(Amazon Linux)
sudo dnf install -y postgresql15
sudo dnf install -y git vim
步骤 2: 准备 RDS PostgreSQL
创建 RDS 实例并记录 RDS 信息
aws rds create-db-instance
--db-instance-identifier langgraph-memory-db
--db-instance-class db.t3.micro
--engine postgres
--engine-version 15.4
--master-username postgres
--master-user-password YourSecurePassword123
--allocated-storage 20
--vpc-security-group-ids sg-xxxxx
--db-subnet-group-name your-subnet-group
--publicly-accessible false
连接到 RDS:
psql -h langgraph-memory-db.xxxxx.us-east-1.rds.amazonaws.com -U postgres -d postgres
创建数据库:
CREATE DATABASE langgraph_memory;
步骤 3: 创建 Agent 代码
# ============================================================================
# 定义 State
# ============================================================================
class AgentState(TypedDict):
"""Agent 状态定义"""
messages: Annotated[list, operator.add] # 消息历史
user_input: str # 用户输入
response: str # AI 响应
# ============================================================================
# 定义 Agent 节点
# ============================================================================
def process_message(state: AgentState) -> AgentState:
"""
处理用户消息的节点
这里可以添加你的 AI 逻辑,比如调用 LLM
"""
user_input = state["user_input"]
# 简单的响应逻辑(替换为你的 AI 模型调用)
response = f"收到您的消息: {user_input}"
# 更新状态
return {
"messages": [
HumanMessage(content=user_input),
AIMessage(content=response)
],
"response": response
}
# ============================================================================
# 创建 LangGraph
# ============================================================================
def create_agent_graph():
"""创建 Agent Graph"""
# 创建 Graph
workflow = StateGraph(AgentState)
# 添加节点
workflow.add_node("process", process_message)
# 定义流程
workflow.add_edge(START, "process")
workflow.add_edge("process", END)
# 编译 Graph(使用内存 Checkpointer)
checkpointer = MemorySaver()
graph = workflow.compile(checkpointer=checkpointer)
return graph
# ============================================================================
# BedrockAgentCore 应用
# ============================================================================
app = BedrockAgentCoreApp()
# 创建 Graph(全局单例)
agent_graph = create_agent_graph()
@app.entrypoint
def invoke(payload):
"""
AI Agent 入口函数
Args:
payload: 包含 prompt 的字典
Returns:
包含 result 的字典
"""
# 获取用户消息
user_message = payload.get("prompt", "Hello! How can I help you today?")
# 获取或生成 thread_id(用于会话管理)
thread_id = payload.get("thread_id", "default_thread")
# 调用 Graph
result = agent_graph.invoke(
{
"messages": [],
"user_input": user_message,
"response": ""
},
config={
"configurable": {
"thread_id": thread_id
}
}
)
# 返回响应
return {
"result": result["response"]
}
# ============================================================================
# 运行
# ============================================================================
if __name__ == "__main__":
app.run()
创建 requirements.txt
bedrock-agentcore
langgraph>=0.2.0
langchain-aws>=0.1.0
psycopg2-binary>=2.9.9
sqlalchemy>=2.0.0
步骤 4: 启动 Agent 测试
设置环境变量:
export DATABASE_URL="postgresql://postgres:password@host.docker.internal:5432/langgraph_memory"
export AWS_REGION="us-east-1"
启动 agent:
python my_agent.py
在另一个终端测试:
curl -X POST http://localhost:8080/invocations -H "Content-Type: application/json" -d '{"prompt": "你好!"}'
验证输出
成功的输出应该类似:
{
"result": "你好!我是一个友好的 AI 助手...",
"thread_id": "default"
}
步骤 5: 配置 AgentCore
基础配置
agentcore configure -e my_agent.py
在配置过程中:
Region: 选择你的 RDS 所在区域(如 us-east-1)
Memory: 选择 "No" (我们使用自己的 PostgreSQL)
Deployment mode: 选择 direct_code_deploy(推荐)或 container
配置 VPC
重要:根据 AWS 官方文档,AgentCore Runtime 必须使用私有子网。
编辑生成的 .bedrock_agentcore.yaml 文件,添加 VPC 配置:
bedrock_agentcore:
agent_name: my_agent
region: us-east-1
deployment_mode: direct_code_deploy
VPC 配置(使用私有子网)
vpc_config:
subnet_ids:
- subnet-private-1a # 必须是私有子网(无直接 Internet 访问)
- subnet-private-1b # 建议多 AZ 部署
security_group_ids:
- sg-lambda-langgraph # Lambda 安全组
环境变量
environment_variables:
DATABASE_URL: "postgresql://postgres:YourSecurePassword123@langgraph-memory-db.xxxxx.us-east-1.rds.amazonaws.com:5432/langgraph_memory"
AWS_REGION: "us-east-1"
MODEL_ID: "us.amazon.nova-pro-v1:0"
Lambda 配置
timeout: 60
memory_size: 512
步骤 6: 部署到 AgentCore Runtime
agentcore launch
打包你的代码和依赖
上传到 S3(direct_code_deploy)或 ECR(container)
创建 Lambda 函数
配置 VPC 和安全组
设置环境变量
配置 IAM 角色和权限
记录输出中的:
Agent ARN: arn:aws:bedrock-agentcore:us-east-1:xxxxx:agent-runtime/my-agent/DEFAULT
CloudWatch Logs: /aws/bedrock-agentcore/runtimes/my-agent-DEFAULT
步骤 7: 验证部署
检查状态
agentcore status
测试调用
测试基础对话:
agentcore invoke '{"prompt": "你好!"}'
测试多轮对话(使用 thread_id):
agentcore invoke '{"prompt": "我叫张三", "thread_id": "user_001"}'
agentcore invoke '{"prompt": "你还记得我的名字吗?", "thread_id": "user_001"}'
测试会话隔离:
agentcore invoke '{"prompt": "你知道张三是谁吗?", "thread_id": "user_002"}'
面向可扩展性与高可靠性的设计
一个企业级系统必须能够在业务高峰期稳定运行,并能从各种故障中快速恢复。
- 计算资源的可扩展性: Application Load Balancer (ALB) 与 Bedrock AgentCore Runtime 的无服务器特性相结合,构成了强大的弹性伸缩能力。当用户请求增多时,ALB 会将流量分发到更多的后端实例,而 AgentCore Runtime 会自动拉起更多的智能体容器实例来处理这些请求。当流量回落时,资源又会自动缩减,实现了成本和性能的最佳平衡。
- 数据库的可靠性: 作为存储关键业务数据和智能体记忆的核心,数据库的可靠性至关重要。将 Amazon RDS for PostgreSQL 部署为多可用区配置,是确保高可用性的标准实践。在这种配置下,数据库会有一个主实例和一个在不同可用区的备用实例,数据会同步复制。一旦主实例发生故障,系统会自动、透明地切换到备用实例,通常能在分钟级别内恢复服务,对上层应用的影响降到最低。
结论与核心价值
架构蓝图回顾
本方案通过融合 LangGraph 的动态编排能力与 Amazon Bedrock AgentCore 的企业级托管优势,确立了一套可复用的 GenAI 实践。它不仅是技术的堆栈,更是连接开源创新与云端稳健性的桥梁,为构建具备复杂推理与持久记忆的下一代应用提供了标准化路径。
核心价值三要素
- 认知升级:从“指令执行”到“复杂推理” 打破简单问答的局限,利用 LangGraph 的有状态、循环式工作流,实现多步推理与动态规划。这标志着从“指令式 AI”向“认知式 AI”**的跨越,赋予系统解决核心业务难题的能力。
- 生产基石:全托管与卓越运营 基于 AWS 的纵深防御体系与弹性伸缩架构,确保系统满足企业对安全性、可靠性(及可观测性的严苛 SLA。Bedrock AgentCore 的引入大幅降低了运维复杂度,使企业能安全、快速地将 AI 创新落地生产。
- 架构韧性:开源生态与云原生融合 拒绝厂商锁定,采用“开源内核 + 云端底座”的双模架构。企业既能利用 LangGraph 掌控核心逻辑,又能灵活接入 AWS 多样化的基础模型(FM)与云服务组合,确保方案在技术上的先进性与商业上的长期适应性。
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心: 云端创新的引领者
探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用

|
 |