引言
PCB印刷电路板(PCB)的质量是电子产品可靠性的关键。然而,随着PCB设计日益复杂,传统的人工目检或基础AOI(自动化光学检测)在效率、精度和成本控制上面临严峻挑战,难以满足现代制造业的需求。检测速度慢、易出错、漏检误报率高成为了生产中的常见痛点。人工智能(AI)视觉技术为此提供了强大的解决方案。利用深度学习,我们可以训练模型自动、快速且准确地识别PCB上的各种缺陷,大幅提升质检效率和一致性。
本篇博客将向你展示如何在AWS利用一套高效的云技术栈,轻松构建PCB智能视觉质检系统。我们将重点介绍:
- YOLO (You Only Look Once): 一种领先的实时目标检测算法,擅长快速定位和分类PCB上的缺陷。
- Amazon SageMaker: AWS提供的一站式机器学习平台,它极大地简化了YOLO模型的训练、调优过程。
- AWS Lambda: 一种无服务器计算服务,用于经济高效地部署训练好的模型,实现弹性伸缩的在线推理。
接下来,我们将带你一步步实践,从数据准备到模型训练,最终将智能检测模型部署上线。
关键步骤
数据准备
在AI视觉项目中,数据质量就是生命线。“Garbage In, Garbage Out” —— 模型的性能上限完全取决于训练数据的质量和代表性。因此,为PCB缺陷检测精心准备数据至关重要。
核心要点:
- 高质量数据:高质量、多样化的数据是训练出强大泛化能力模型的基础。在此投入时间是值得的。数据最好是源于生产线的真实缺陷数据
- 精确标注:对于YOLO模型,我们需要为每个缺陷绘制边界框 (Bounding Box) 并指定类别标签 (Class Label)。标注必须精确且标准一致。
- 数据集划分与格式:将数据分为训练集、验证集(用于调优)和测试集(用于最终评估),常见比例为70/20/10或80/10/10。确保标注文件符合YOLO要求的格式
在本文中,为了便于测试验证,采用网上公开数据集来进行验证。
模型训练与调优
对于YOLO这种模型的训练较为简单,我们使用Sagemaker笔记本直接进行训练。先创建一个Sagemaker笔记本实例,我这里使用的实例型号是ml.g4dn.xlarge,然后创建训练脚本,训练脚本示例如下:
%pip install sagemaker
%pip install ultralytics
%pip install datasets
from datasets import Dataset
from ultralytics import YOLO
!pip install roboflow
from roboflow import Roboflow
rf = Roboflow(api_key="xxx")
project = rf.workspace("xxx").project("xxxxx")
version = project.version(1)
dataset = version.download("yolov11")
from IPython.display import display, Image
!yolo task=detect mode=train model=/home/ec2-user/SageMaker/yolo11m.pt data=/home/ec2-user/SageMaker/PCB_defect-1/data.yaml epochs=150 imgsz=800 plots=True
这里的训练数据使用的是roboflow平台上的pcb公开的数据集格式用于测试和验证,生产中需要使用实际生产的图片和标注数据。此外这里模型路径使用的是绝对路径,也可以忽略路径自动下载基础模型。训练结束后,会在笔记本目录里生成新的模型文件,可以下载下来或者上传到S3以便后续部署。
无服务器部署:将YOLO模型部署至AWS Lambda (对应Lambda部署)
在上一个步骤最后训练得到了最终的权重模型后,使用这个模型来部署在lambda进行推理,这里选用python镜像部署的方式
Python依赖如下
opencv-python-headless
ultralytics
Pillow
Lambda示例代码如下:
import base64
import os
import cv2
from ultralytics import YOLO
from PIL import Image
import io
# 模型路径
MODEL_LOCAL_PATH = os.path.join(os.environ['LAMBDA_TASK_ROOT'], 'models/best.pt')
model = YOLO(MODEL_LOCAL_PATH)
# 缺陷名称映射
defect_names_map = {
0: "Missing hole",
1: "Mouse bite",
2: "Open circuit",
3: "Short",
4: "Spur",
5: "Supurious copper"
}
def lambda_handler(event, context):
image_data = event.get('file_data')
"""处理图像并进行缺陷检测"""
image_bytes = base64.b64decode(image_data)
# 转换为PIL图像
img = Image.open(io.BytesIO(image_bytes))
# 预测
results = model.predict(img)
# 处理结果
boxes = results[0].boxes
# 将图像转换为OpenCV格式以便绘制
plotted_img = results[0].plot()
# 将绘制后的图像编码为base64
_, buffer = cv2.imencode('.jpg', plotted_img)
plotted_base64 = base64.b64encode(buffer).decode('utf-8')
# 提取缺陷信息
defects = []
if len(boxes) > 0:
defect_indices = boxes.cls.cpu().numpy()
confidences = boxes.conf.cpu().numpy()
for i, cls_idx in enumerate(defect_indices):
cls_idx = int(cls_idx)
if cls_idx in defect_names_map:
defects.append({
"type": defect_names_map[cls_idx],
"confidence": float(confidences[i])
})
# 计算缺陷摘要
defect_summary = {}
for defect in defects:
defect_type = defect["type"]
if defect_type in defect_summary:
defect_summary[defect_type] += 1
else:
defect_summary[defect_type] = 1
return {
"processed_image": plotted_base64,
"defects": defects,
"defect_count": len(defects),
"defect_summary": defect_summary
}
实战演示:端到端的智能质检流程
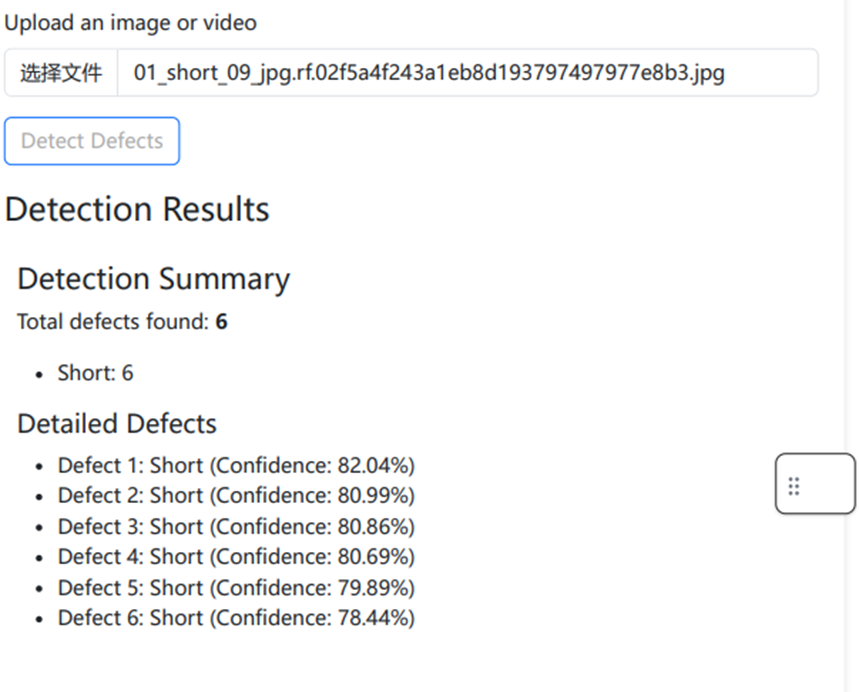
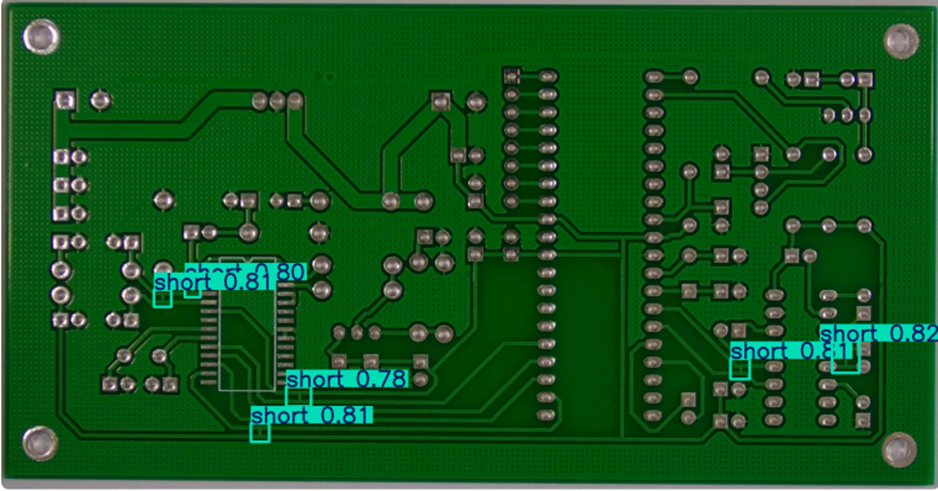
通过容器部署lambda后,就可以使用这个函数来进行缺陷检测了,输入为图片的base64格式,输出检测的结果和图片的缺陷标注
图片的缺陷标注如下图,图中通过标注框指出了可能是短路缺陷的部分
总结与展望
本文介绍了一套高效的方案来构建PCB缺陷检测程序,通过Sagemaker笔记本高效训练模型,然后通过AWS Lambda无服务器快速部署推理。使用这套方案可以快速进行业务上的验证和演示,以及一些低负载的生产场景。对于一些高并发场景的缺陷检测或者视频场景的缺陷检测,部署到AWS的GPU实例会是更具性能优势的选择。同时数据的质量也决定了最终模型的效果,在生产中,最推荐的是使用实际生产的数据来进行数据标注然后训练模型,这样准确度会更高。
本篇作者