亚马逊AWS官方博客
使用 Amazon Textract 与 Amazon Comprehend,通过 AWS Finance and Global Business Services 构建一套自动化合约处理平台
原文链接:
处理合约及协议等文档资料是一项费时费力的任务。在传统意义上,对典型的合约签订工作流进行审计往往涉及合约条款的加载、阅读及提取等多个步骤,这往往需要耗费大量人工与劳力。
以往,AWS Finance and Global Business Services (AWS FGBS)每月也曾投入150多个人工处理这方面工作。在此期间,众多分析师需要将上百份合约一次性手动输入至Excel表格当中。
最近,专门负责分析合约协议的AWS FGBS团队开发建立一条自动化工作流,借此高效处理传入文档。其目标非常简单——把专业财会资源从繁琐的日常劳作中解放出来,将更多精力投入到增值性财务分析当中。
最终,该团队构建了一套解决方案,能够在1分钟之内以高保真度与可靠的安全性持续解析并存储整个合同中的重要数据。现在,整个自动化流程每月只需要1位分析师工作30小时即可完成平台的维护与运行。处理时长缩短至之前的五分之一,生产效率得到显著提高。
整个应用由两项AWS支持的机器学习(ML)托管服务实现,分别为Amazon Textract(可高效实现文档内容提取)以及Amazon Comprehend(可提供下游文本处理,负责提取关键术语)。
本文将介绍整套解决方案的基本架构,深入研究架构设计并简要探讨其中的设计取舍。
合约工作流
下图所示,为这套解决方案的基本架构:

AWS FGBS团队在AWS机器学习(ML)专业服务(ProServe)团队的帮助下,构建起一套自动化、持久且可扩展的合约处理平台。传入的合约数据被存储在Amazon Simple Storage Service (Amazon S3)数据湖当中。此解决方案使用Amazon Textract将合约转换为文本形式,而后使用Amazon Comprehend进行文本分析与术语提取。从合约中提取到的关键条款及其他元数据,将被存储在Amazon DyanmoDB(一套可接收键-值与文档类型数据的数据库)当中。财会用户可以通过由Amazon CloudFront托管的自定义Web用户界面访问数据内容,并执行关键用户操作,例如错误检查、数据验证以及自定义术语输入等。此外,他们还可以由完全托管应用程序流服务Amazon Appstream管理的Tableau服务器生成结果报告。您还可以使用AWS CloudFormation模板在AWS生产环境中启动并托管这套端到端合约处理平台。
构建高效且可扩展的文档输入引擎
AWS FGBS团队负责处理的合约往往相当复杂,因此以往只能通过人工审查以解析并提取相关信息。这些合约的格式随时间推移而不断变化,且具体篇幅及复杂性各不相同。除此之外,文档中不仅包含自由文本,同时也有着大量涉及重要上下文信息的表格与表单。
为了满足这些需求,这套解决方案使用Amazon Textract作为文档输入引擎。Amazon Textract是一项功能强大的服务,以一组经过预先训练的机器学习计算机视觉模型为基础,这些模型通过复杂的调优对来自文档(例如图像或PDF)的文本及数字执行光学字符识别(OCR)。Amazon Textract能够识别出文档中的表格与表单,保留每个单词的上下文信息。该团队希望从每一份合约中提取出重要的核心条款,但也有一些合约中并不包含任何条款集。例如,可能有多份合约共同同一主表,此表左侧列出术语名称,右侧列出该术语的值。我们的解决方案可以使用Amazon Textract的表单提取功能将其转化为一个键-值对,其链接至合约条款中的名称与值。
下图所示,为Amazon Textract中的批处理架构:
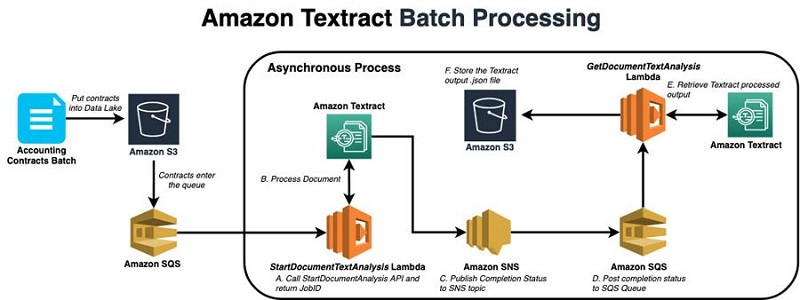
管道使用由分布式消息队列服务Amazon Simple Queue Service (Amazon SQS)启用的异步Amazon Textract API处理传入的合约。AWS Lambda函数StartDocumentTextAnalysis 负责启动Amazon Textract处理作业,而此函数会在有新文件被存放至Amazon S3的合约数据湖时触发。由于合约以分批形式加载,而且异步API能够在不预先将合约转换为图像文件格式的情况下直接处理PDF文件,因此设计人员决定构建异步流程以提高方案的可扩展性。此解决方案使用DocumentAnalysis API(而非DocumentDetection API),用以实现对表格及表单的识别。
在DocumentAnalysis作业完成之后,解决方案会返回JobID并将其输入至另一个队列当中,此队列负责以JSON对象的形式从Amazon Textract中检测已经完成的输出。响应结果将以大型嵌套数据结构,同时容纳提取到的文本以及文档元数据。GetDocumentTextAnalysis 函数将JSON输出的检索与存储放置在S3存储桶内,以待后续处理及术语提取。
使用Amazon Comprehend提取标准与非标准条款
下图所示,为关键词提取功能的基本架构:
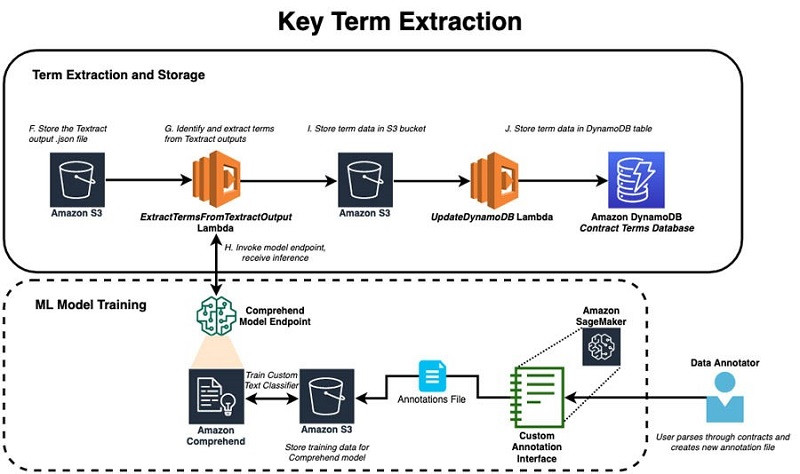
本解决方案将Amazon Textract处理后的合约输出结果存放在S3存储桶内,而后启动术语提取管道。此管道的主要工作程序为ExtractTermsFromTextractOutput函数,此函数对术语提取所得到的情报进行编码。
此步骤包含以下关键操作:
- 合约被拆分为多个部分,提取其中的基础属性,例如合约标题与合约ID编号。
- 标准合约条款将被标识为键-值对。使用Amazon Textract输出结果中发现的表关系,本解决方案可以从包含关键术语的表中找到正确的术语与对应值,同时采取其他操作将术语值转换为正确的数据格式,例如解析日期。
- 可以将一组非标准术语添加至表内,或者嵌入至合约特定部分的自由文本当中。该团队使用Amazon Comprehend自定义分类模型识别这些需要关注的重要部分。
为了为这套模型生成适当的训练数据,AWS FGBS团队的主题专家对大量历史合约进行了标记,借此识别出合约中的标准部分(不包含任何特殊术语)与非标准部分(包含特殊术语及用语)。这套托管在Amazon SageMaker实例之上的标记平台能够显示单一合约中的各个部分,各部分由之前使用的ExtractTermsFromTextractOutput函数拆分而来,以便用户能够相应标记这些内容。
经过训练的最终自定义文本分类模型将负责对各段落进行分类,识别出F1得分超过85%的内容,并由Amazon Comprehend管理非标准部分。使用Amazon Comprehend进行文本分类的核心优势,在于其对训练数据格式的要求非常宽松,该服务能够自主完成文本预处理步骤,例如特征工程并解决类别不平衡问题。这些都属于需要在自定义文本模型中需要解决的典型问题。
在将合约划分成多个部分之后,这些部分的一个子集将由ExtractTermsFromTextractOutput 函数传递至自定义分类模型端点处,检测其中是否包含非标准术语。DynamoDB表中记录了已检查完成的合约部分与被标记为非标部分的最终列表。接下来,系统会通知会计师们检查需要人工核查以进行解释的非标合约语言,并挑选出有必要明确记录的条款。
在完成这三个阶段(合约拆分、提取标准条款、以及使用自定义模型对非标部分进行分类)之后,解决方案使用条款的键-值对创建一份嵌套字典。针对每份合约,系统还会生成一个错误文件,确切指定提取到的哪个术语引发了错误以及相应的错误类型。这个错误文件被存放在存储合约条款的S3存储桶当中,以便用户可以将单一合约中的任何失败提取追溯至相应的单一条款。错误日志中还包含一个特殊的错误警报短语,用以简化对Amazon CloudWatch日志的搜索,借此查找发生提取错误的具体点。最终,系统会为每个合约生成一个包含多达100个或者更多条款的JSON文件,并将其推送至中间S3存储桶当中。
从每份合约中提取的数据将被发送至DynamoDB数据库进行存储与检索。之所以选择DynamoDB作为持久数据存储载体,主要出于以下两个理由:
- 此键-值与文档数据库相较于关系数据库具有更大的灵活性,因为其能够接受大字符串值及嵌套键-值对等数据结构,而且无需依赖预定义schema,因此用户可以随合约发展随时向数据库内添加新的术语。
- 这套完全托管数据库能够以规模化方式提供个位数毫秒级性能,因此可以将自定义前端与报告功能集成在这项服务之上。
此外,DynamoDB能够支持连续备份与时间点恢复,借此将表内数据恢复至过去35天周期内的任意一秒钟。这项功能,也让我们的解决方案赢得了整个团队的信任。它能够保护关键数据免遭意外删除或编辑,并为重要的下游任务(例如财务报告)提供业务连续性支持。数据上传期间,系统需要执行一项重要检查——检查DynamoDB条目的大小限制。解决方案将其上限设置为400 KB。对于体量较大的合约与提取条款列表,某些合约的输出结果会超过此限制,因此我们需要在条目提取功能中执行检查,及时将较大条目拆分为多个JSON对象。
通过自定义Web UI保护数据访问与验证
下图所示,为自定义Web用户界面(UI)与报告架构:

为了与提取到的合约数据进行有效交互,团队构建了一套自定义Web UI。使用Angular v8框架构建的Web应用程序通过Amazon S3托管在云内容交付网络Amazon CloudFront上。当访问Amazon CloudFront URL时,我们首无使用具有严格权限约束的用户池对用户进行授权及身份验证,借此判断其是否有权查看此UI并与之交互。在完成验证之后,会话信息将被保存下来,确保用户仅在设定的时段之内保持登录状态。
在登陆页面上,用户可以通过链接导航至面板上显示的三套关键用户方案处:
- Search for Records – 查看并编辑合约记录
- View Record History – 查看合约记录的历史编辑记录
- Appstream Reports – 打开Appstream托管的报告仪表板

要查看特定记录,系统会提示用户使用特定的客户名称或文件名称进行文件搜索。在使用前一种方式时,搜索将返回具有相同客户名称的各份合约的最新记录。对于后一种方式,搜索将仅返回具有 该文件名的特定合约的最新记录。
在用户找到需要检查或编辑的正确合约之后,即可选定其文件名称并跳转至Edit Record页面。系统将显示合约条款的完整列表,并允许用户编辑、添加或删除这些提取自合约的信息。您可以使用不同的术语从表单字段中检索最新记录,选择不同的值为验证数据;如果发现错误,则及时编辑数据。用户还可以选择Add New Field并为自定义术语输入键-值对来添加新的字段。
使用编辑或新的字段更新条目之后,用户可以选择Update Item按钮。这项操作将触发使用POST方法把新记录的数据从前端通过Amazon API Gateway传递至PostFromDynamoDB函数的过程,生成一个JSON文件,此文件将被推送至保存全部已提取到的术语数据的S3存储桶内。该文件触发相同的UpdateDynamoDB 函数,此函数会在第一次Amazon Textract处理运行之后将原始术语数据推送至DynamoDB表。
验证完成之后,用户可以选择Delete Record,借此通过统一删除DynamoDB以及存储到S3存储桶内所有已提取到的各合约版本中的数据。这项操作由DELETE方法所启动,将触发用于删除数据的DeleteFromDynamoDB函数。在合约数据验证及编辑期间,对于推送字段的每一次更新都会创建一条新的数据记录。此记录将根据登录配置文件自动记录时间戳与用户身份,借此确保对历史编辑记录进行细粒度跟踪。

要发挥编辑跟踪的作用,用户可以搜索合约并查看合约中全部记录的集合(按时间戳排序)。以此为基础,用户可以快速比较跨时间段进行的编辑操作,包括添加任何自定义字段,并将这些编辑链接回编辑器标记。
为了确保团队能够从这套解决方案中实现业务价值,他们还向架构当中添加了报告仪表板管道。报告应用程序实例由完全托管应用程序流服务Amazon AppStream 2.0负责托管。AWS Glue爬取器则为Amazon S3中的数据建立schema,并由Amazon Athena查询并将数据加载至Amazon AppStream实例与报告应用程序当中。
考虑到这部分数据对于Amazon而言相当敏感,我们的团队还纳入了不少安全考量,确保能够安全地与数据进行交互,同时严格阻断未授权第三方的访问。Amazon Cognito授权程序负责保护API Gateway的安全。在用户登录期间,将由采用双因素身份验证的Amazon内部单点登录机制对申请访问Amazon Cognito用户池的团队成员进行验证。
要查看历史记录,用户可以搜索合约并检查单一合约的完整记录集合,快速查看一切错误或可疑的编辑结果,并准确追溯编辑时间与编辑者身份。
该团队还采用其他应用程序强化步骤,用以保护架构及前端。请确保根据最低权限原则缩小AWS角色与策略的应用范围。对于Amazon S3与DynamoDB等存储位置,一切访问将默认被阻断,通过启用服务器端加密以实现静态加密,同时提供版本控制与日志记录功能。对于传输数据加密,AWS PrivateLink支持的VPC接口端点将各AWS服务连接起来,确保数据只通过AWS私有端点(而非公共互联网)进行往来传输。在一切Lambda函数中,全面使用Python临时文件库以应对时间攻击(TOCTOU),由此遵循临时数据处理方面的最佳实践。顺带一提,所谓时间攻击,是指攻击者抢先将文件放置在指定位置,以时间差的方式完成入侵目标。由于Lambda属于无服务器服务,因此在调用Lambda函数之后,存储在临时目录中的所有数据都将被删除,除非用户明确要求将数据推送至另一存储位置(例如Amazon S3)。
客户数据隐私一直是AWS FGBS团队乃至整个AWS服务团队的头等大事。虽然在Amazon Textract及Amazon Comprehend等AWS服务中合并其他训练数据,能够显著提高机器学习模型的最终性能,但大家请务必保持严格的数据保留限制。为了防止将Amazon Textract与Amazon Comprehend生成的合约数据存储下来供后续模型训练,AWS FGBS团队建立起客户数据清退机制以及时清理客户数据。
为了在处理特定敏感数据时验证应用程序的完整性,团队还执行了内部安全检查与来自外部供应商的渗透测试。其中包含动态代码审查、动态模糊测试、表单验证、脚本注入与跨站点脚本(XSS),并针对OWASP十大Web应用程序安全风险做出响应。为了解决分布式拒绝服务(DDoS)攻击,团队在API Gateway上设置了限制,并使用CloudWatch警报对调用阈值限值加以监控。
将安全要求整合至应用程序当中,整个解决方案即可被编入AWS CloudFormation模板,而后将解决方案交付至团队的实际生产流程内。CloudFormation模板将多个嵌套栈组成,其中描述了应用程序基础设施中的各关键组件(前端服务与后端服务)。使用AWS CodeBUIld设置的持续部署管道,帮助团队及时构建并部署指向应用程序代码或基础设施的一切更改。开发及生产环境在两个相互独立的AWS账户当中创建,并通过在相应账户中设置的环境变量来管理两套环境的具体部署。
总结
这款应用程序现已上线,而且每月通过成百上千份合约进行测试。最重要的是,该团队已经切实体会到业务流程自动化所带来的时间节约与价值提升效益。
AWS ProServe团队目前正与AWS FGBS团队合作推进项目的第二阶段,旨在进一步增强这套解决方案。为了提高术语提取的准确性,他们尝试使用经过预训练及定制化设计的Amazon Comprehend NER模型。他们将建立起重新训练管道,确保平台智能可以随着时间推移与新数据的供给实现改进。他们还考虑引入Amazon Augmented AI(Amazon A2I)这一新服务,利用其中的AI代码审查功能发现低置信度Amazon Textract输出结果,并生成新的训练数据以持续改进模型。
随着AWS不断推出更多激动人心的全新机器学习服务,AWS FGBS团队也期待不断增强这套解决方案,运用现代化、自动化成果逐步取代传统财会工作用例。
立即体验!欢迎大家在AWS管理控制台上使用本文中提到的服务及更多其他服务支持您的用例。