亚马逊AWS官方博客
亚马逊云科技Flink计算引擎使用指南
一、前言
亚马逊云科技对Flink计算引擎在产品形态上提供了全面的支持。Amazon EMR on EC2,Amazon EMR on EKS,Amazon Managed Service for Apache Flink这三个产品都支持Flink计算引擎,客户可以根据自己的场景选择最适合的服务来运行Flink任务。本文内容会着重介绍Amazon EMR on EC2和Amazon Managed Service for Apache Flink的使用指南,包括作业的提交、监控方案、Autoscaler、Iceberg集成。目的是帮助客户快速上手使用这两个服务。对于Amazon EMR on EKS Flink我们提供了详细的Workshop,可以点击这里访问Flink on EKS动手实验
二、EMR on EC2 Flink使用指南
2.1 AutoScaler说明
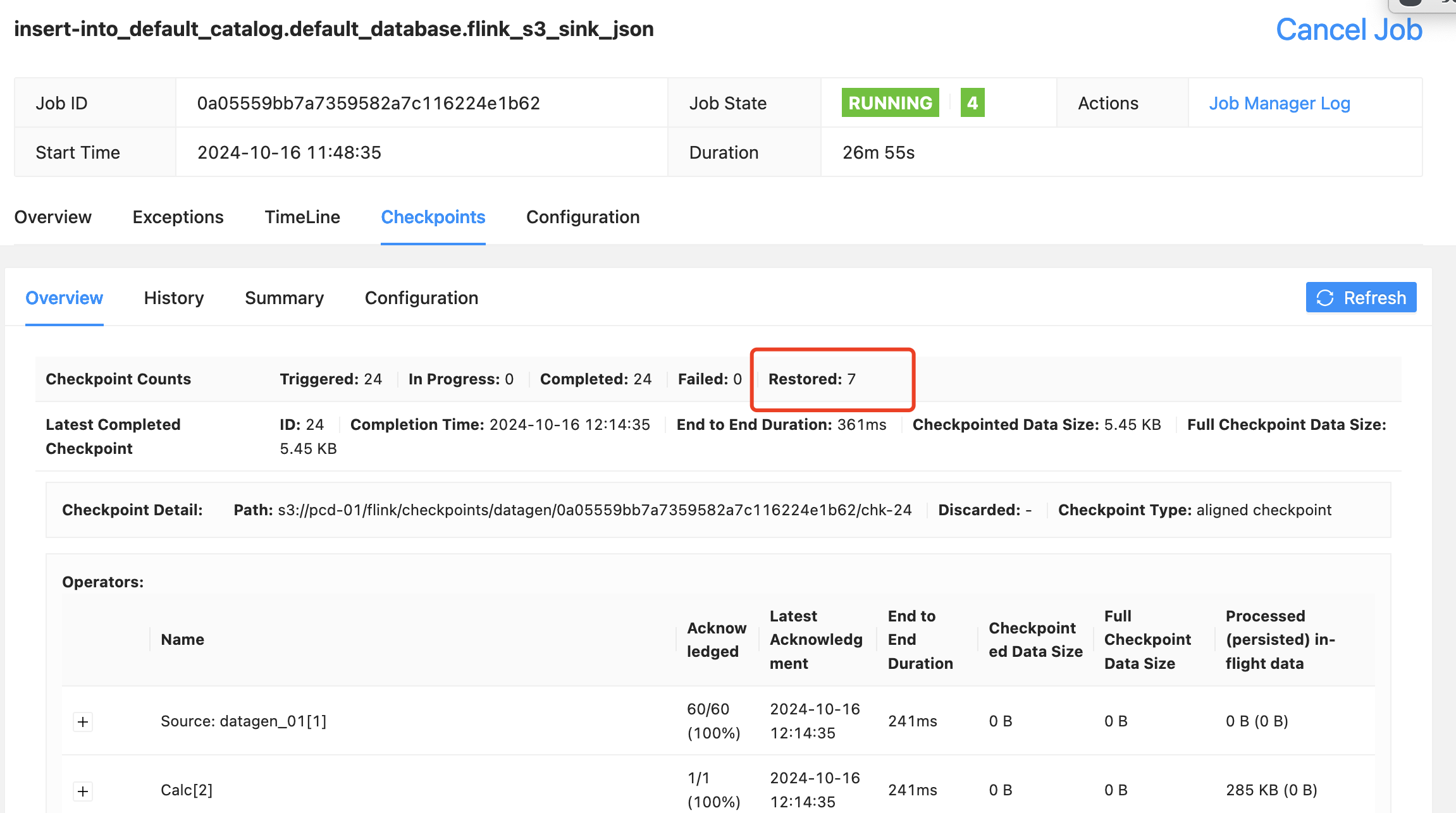
Apache Flink在1.18版本之后对AutoScaler做了增强支持in-place scaling support, 在EKS上可以直接集成使用,但在ON YARN上只提供了一个Standalone的包,并不能满足生产要求。EMR on EC2的Flink对AutoScaler做了产品级别的集成,方便客户直接配置使用。对于使用AutoScaler这里做几点说明:
- 应该使用EMR 7.x+, Flink 1.18+版本,因为1.18可以做in-place作业重启升级不用执行完整的升级流程(不用先savepoint再启动,直接从checkpoint restore),缩短作业调整并行度后的重启时间。
- EMR的AutoScaler是专门优化过的,且集成到flink的runtime中
(flink-dist,org/apache/flink/runtime/scheduler/autoscaler/),这是开源Flink不具备的. - 如果要尽快在缩容底层EC2资源,将
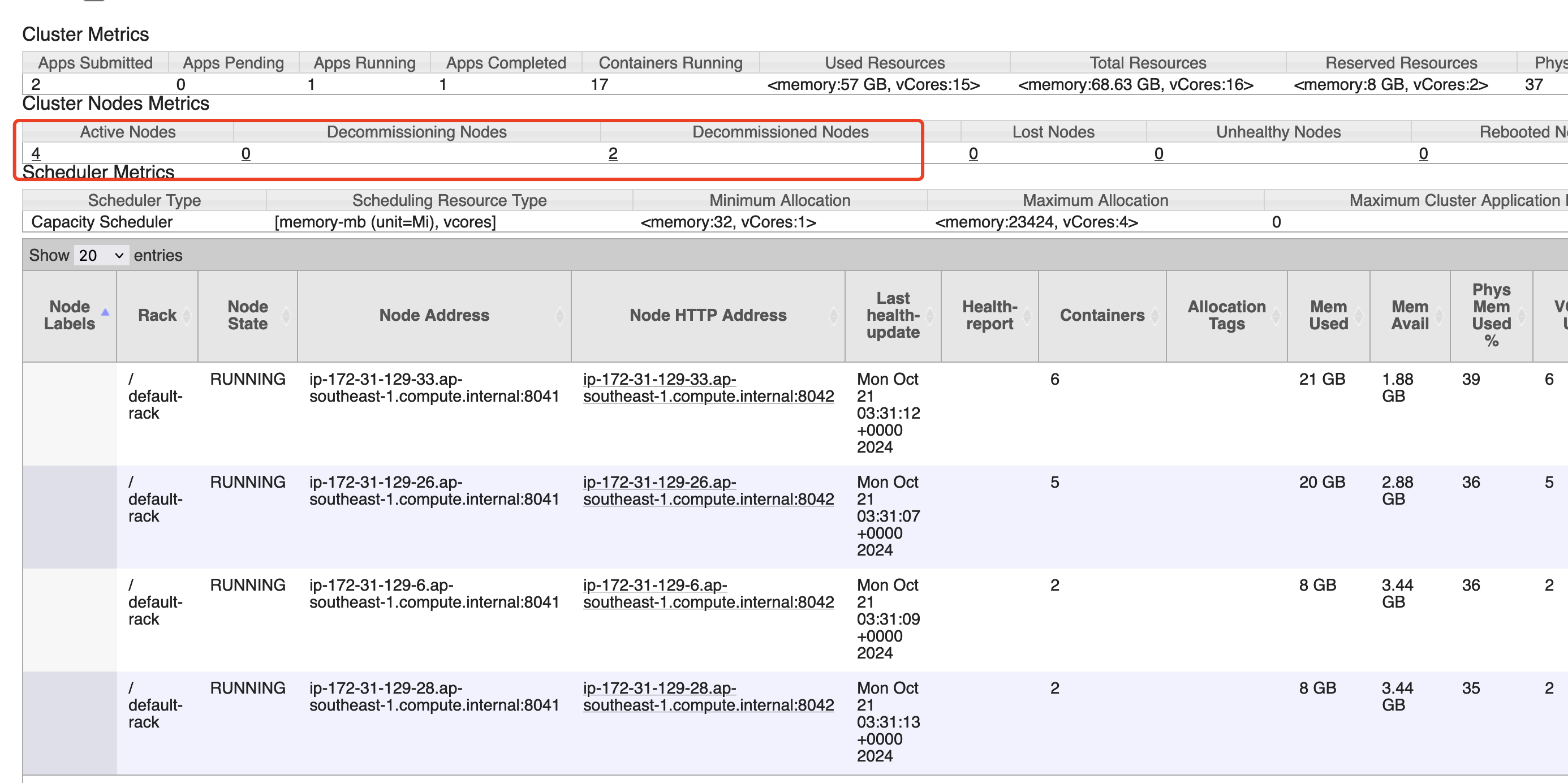
yarn.resourcemanager.nodemanager-graceful-decommission-timeout-secs减少,默认是3600秒,如果节点进入decommission状态但是有container在EC2上运行,3600秒后才强制终止。注意调整这个值对作业稳定性有影响,请在在快速缩减资源和作业SLA之间做权衡。
2.2 创建Session
- 下面以Flink session+Flink-CLI模式为列做使用说明,注意Flink生产使用模式建议使用application模式提交作业,session和per-job模式已经不再是推荐的使用模式。 这里使用flink cli只是为了方便说明,使用其它模式时下面的配置AutoScaler参数是一致的。EMR AutoScaler支持的参数配置在这里AutoScaler Configurations
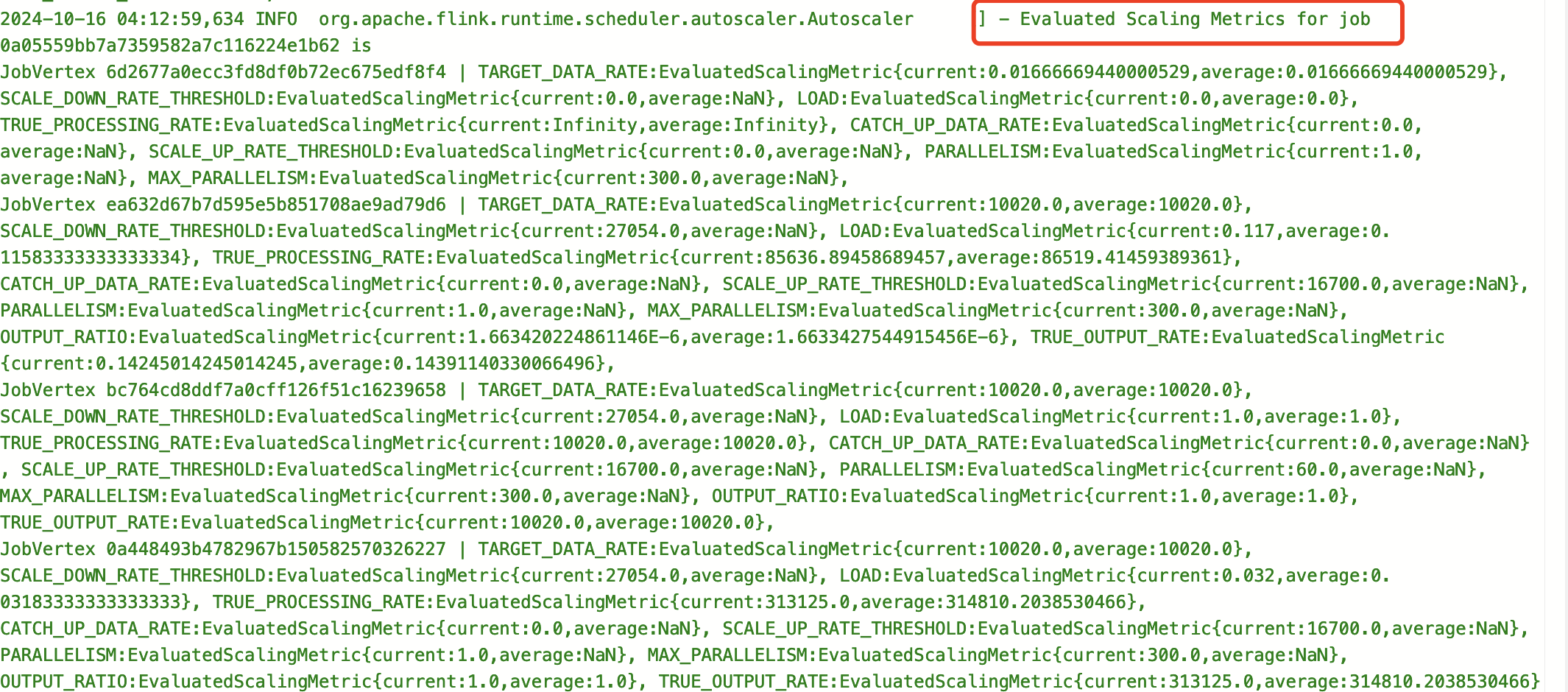
- 我们为Flink作业设定的目标利用率job.autoscaler.target.utilization, AutoScaler会尽可能保证作业在没有背压延迟的条件下,通过调整并行度,来满足设定的目标利用率。
2.3 提交作业
- 下面是启动Flink sql-client 指定到之前创建的flink session集群,同时关闭operator-chaining方便查看每个算子的并行度,注意不要在生产环境关闭,会影响性能。
2.4 观察AutoScaler
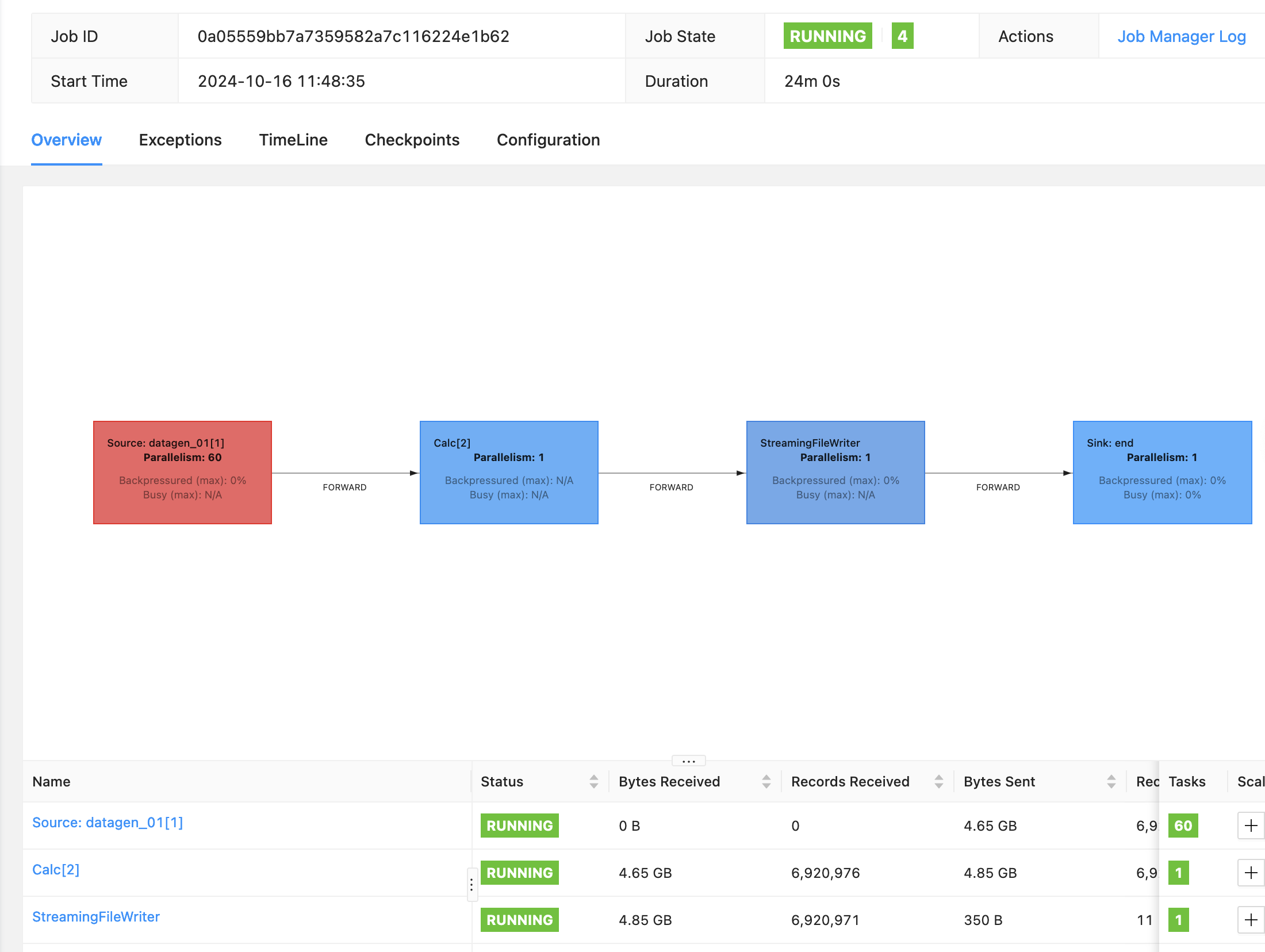
- 可以通过观察jobmanager日志和webui来看到AutoScaler的过程
 |
 |
 |
 |
2.5 Flink Iceberg
- 在EMR on EC2上使用Iceberg,只需在集群开启Iceberg配置即可, 启用方式在这里EMR Iceberg
- Flink 写Iceberg目前只有MOR模式,没有COW模式,即便显示配置COW也不会生效,这一点要注意。
- Iceberg表如果使用upsert模式,分区键必须包含主键,Iceberg的compaction操作原则上是必须要做的,合并小文件提升查询性能。 尤其在upsert模式下,如果没有compaction流程,在大量写入upsert数据的场景下,查询性能表现会比较差,因为写入是MOR所以写入并不会有明显的瓶颈。
2.6 Flink Iceberg 使用Glue Catalog
- 我们使用Glue Catalog结合Flink写入Iceberg表做个例子, Flink Session和Flink Client创建
- 创建glue catalog,在glue catalog中创建flink iceberg database
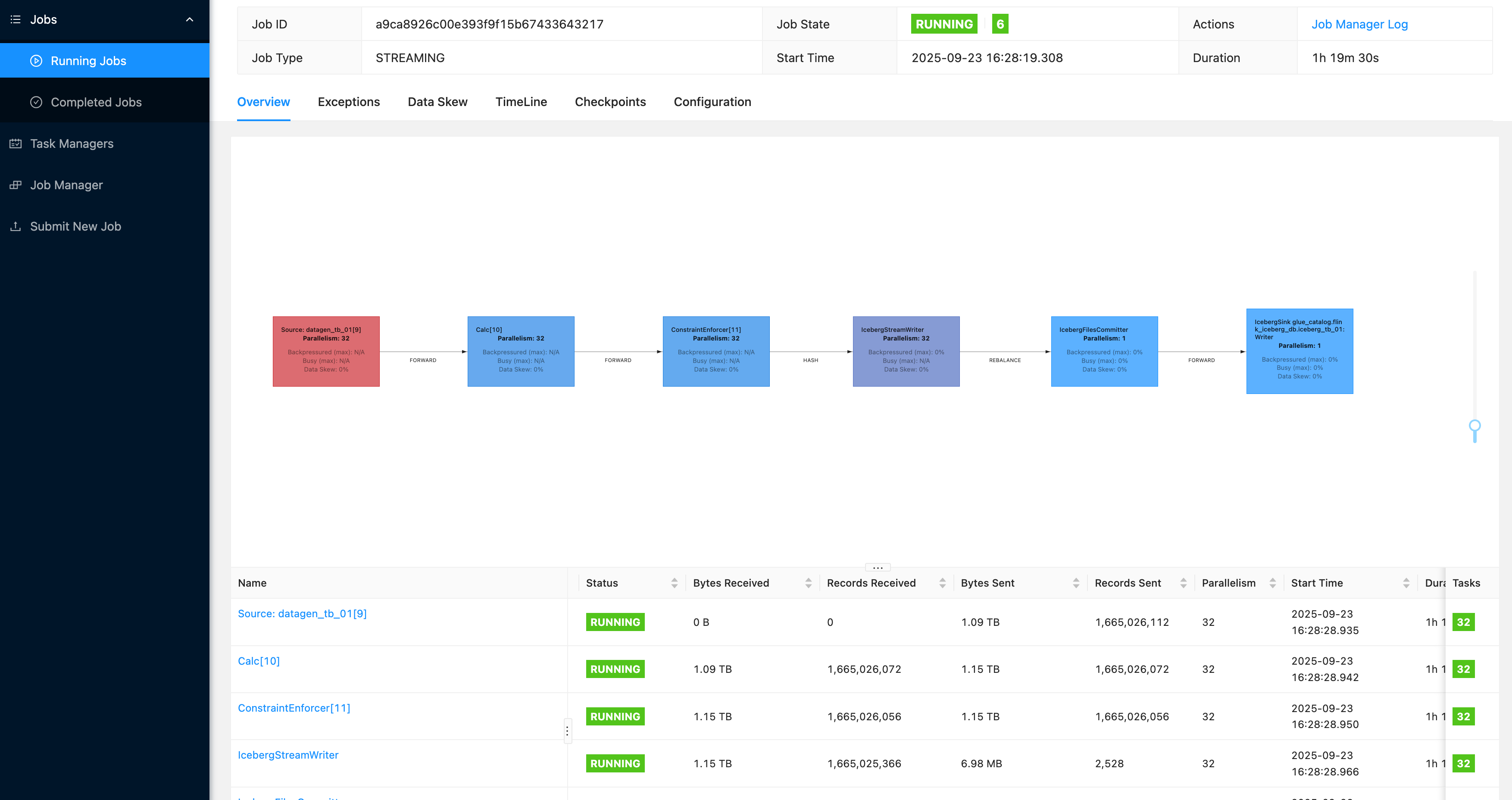
- Datagen生产测试数据写入Iceberg表
- 下图是Flink写入的Iceberg,append模式下的截图。当前配置下写入速度35w/s. 在Upsert模式下的写入速度也很快因为是MOR写,但是如果没有compaction,直接查询表速度会比较慢。
 |
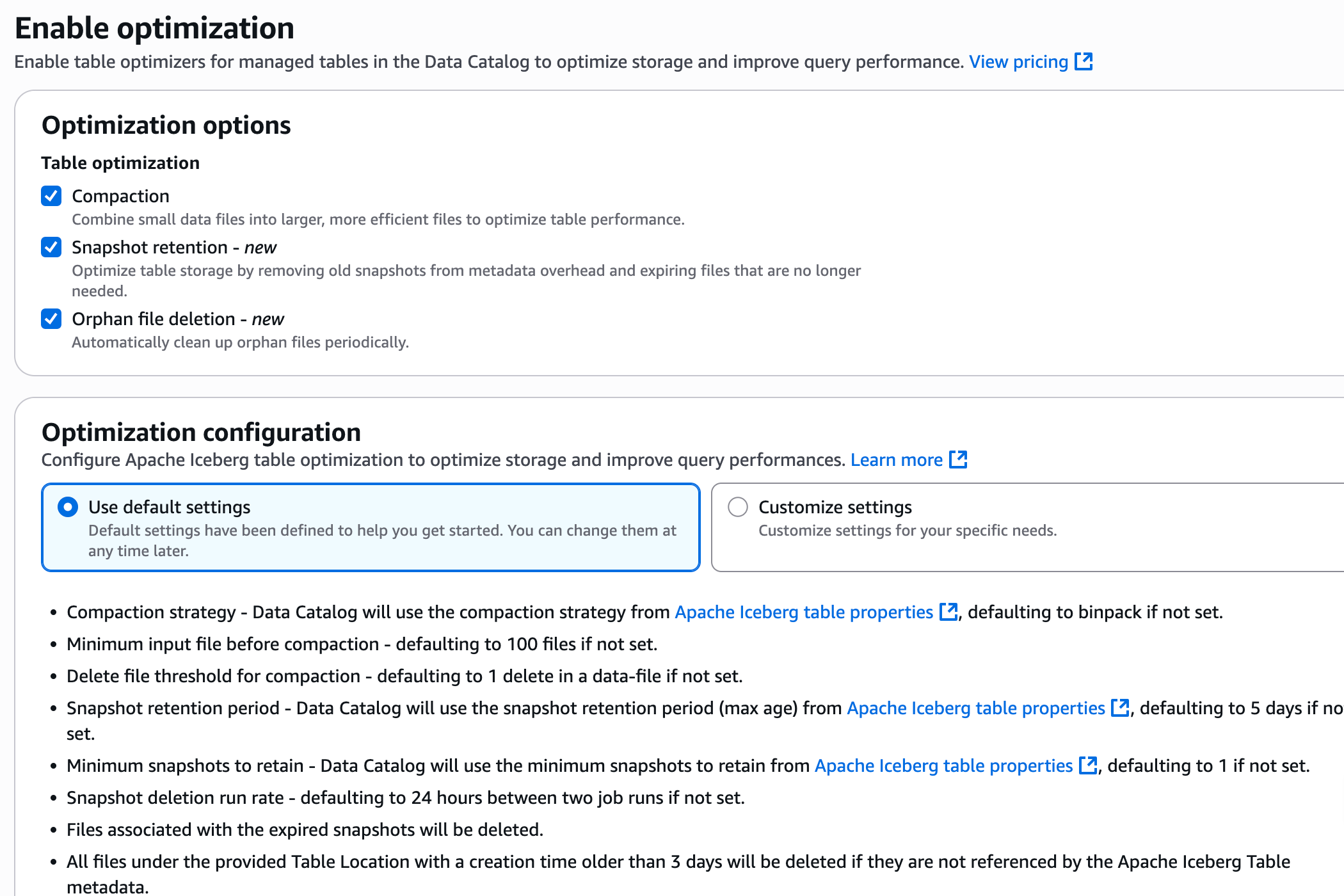
2.7 Glue Catalog Iceberg Auto Optimization
- Glue提供了对于Iceberg表自动维护管理的功能,包括compaction,Snapshot retention,Orphan file deletion. 当使用Glue Catalog作为元数据管理时,对于格式是Iceberg的表类型,可以在Glue中通过启用Iceberg表优化,自动帮您完成Iceberg表运维管理工作。
 |
2.8 EMR on EC2 Flink作业监控
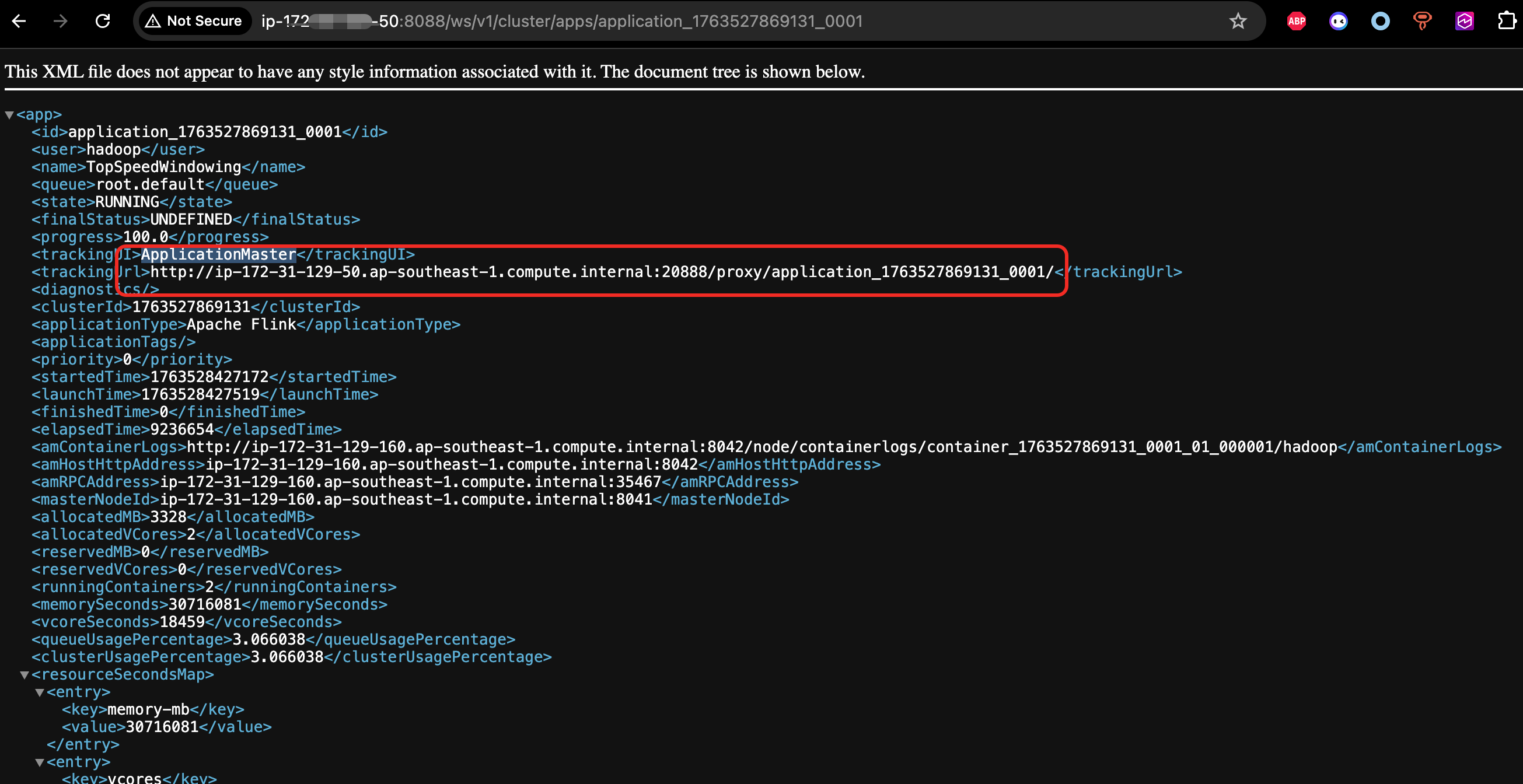
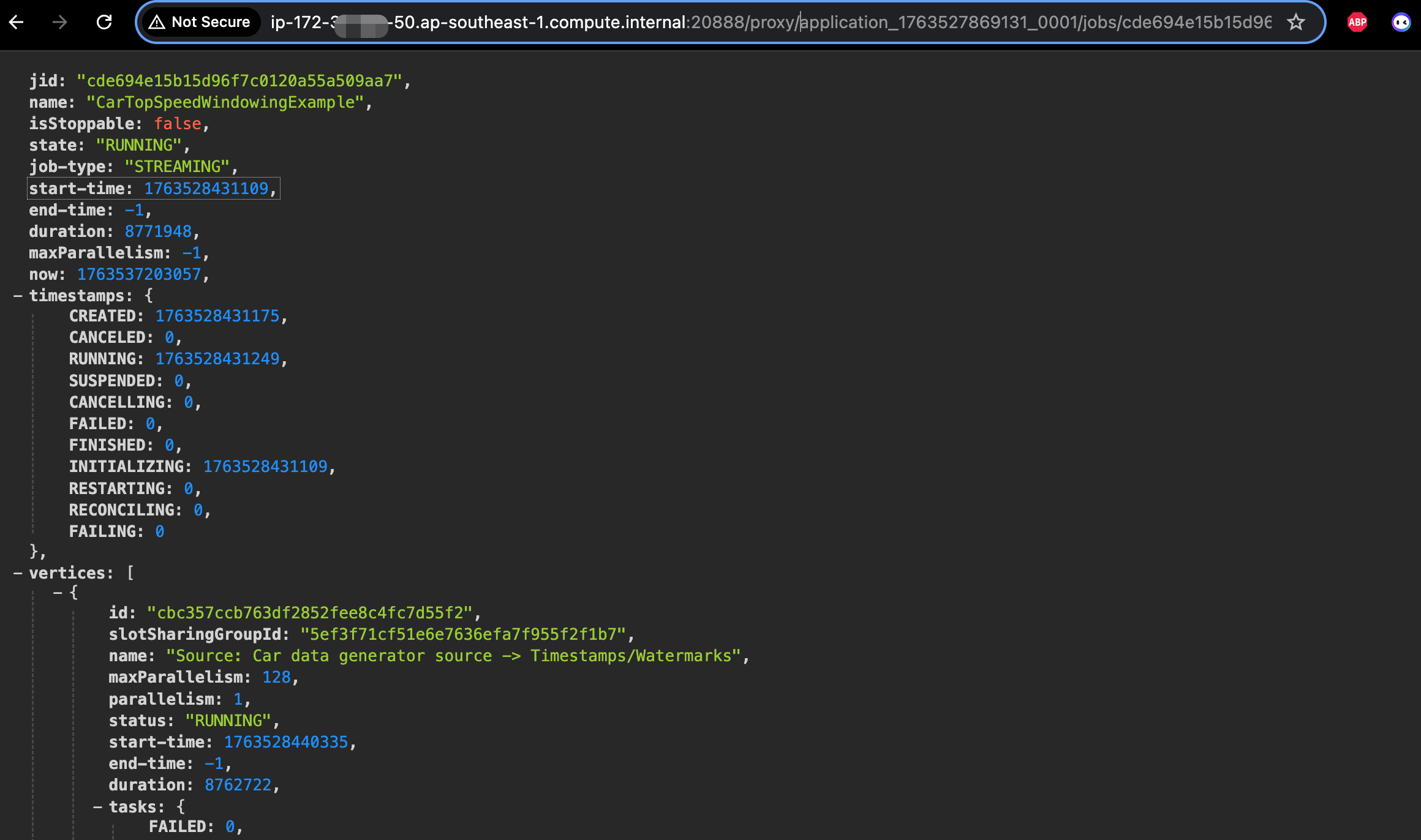
- 在EMR on EC2上对于系统指标的监控,比如CPU,内存,网络,磁盘等,EMR 7.0版本之后集成了cloudwatch agent,开启之后这些指标会自动发送到cloudwatch. 此外cloudwatch agent 还支持配置hdfs,yarn,hbase相关服务的JMX的监控指标。 但是对于Flink作业本身的metrics的监控,比如Flink作业的状态,restart次数,背压等,因为是在作业层面,EMR并不提供作业级别的Metrics. 因此如果果要对每个Flink作业做监控,我们可以使用如下两种方式,1. YARN Flink Rest API 2. Flink Prometheus Exporter。Rest API 方式更加简单,yarn 应用指标通过
http://master_ip:8088/ws/v1/cluster/apps/application_id获取,flink job 指标通过yarn代理过去的flink restapi 获取http://application_master_id:20888/proxy/application_id/jobs/job_id这里的application_master_id 通过yarn的rest api可以获取到ApplicationMaster地址。 相关截图如下:
- 通过这两个restapi可以获取到所有flink rest api 支持的全部指标查看所有Rest指标。有了这两个获取指标的URL,接下来如果要开发一个根据这两个URL展示的指标转换为Prometheus接口的数据的程序,这种开发操作,完全不用人工从头开发,只需要借助AI变成工具Kiro就可以帮你完成开发,您也可以直接在EC2或者EMR Master节点上安装Kiro CLI ,通过CLI开发,这样因为网络环境是通的,可以让他帮你直接开发调试,指导程序符合逾期。您可以去尝试一下,一定会有意外的惊喜,注意请在测试环境中调试开发。
- 对于使用Prometheus Exporter收集指标,这也是Flink官方提供的一种方式,需要安装Prometheus Pushgateway,启动作业配置发送或者全局配置发送Metrics. 下面代码是一个例子,供参考。
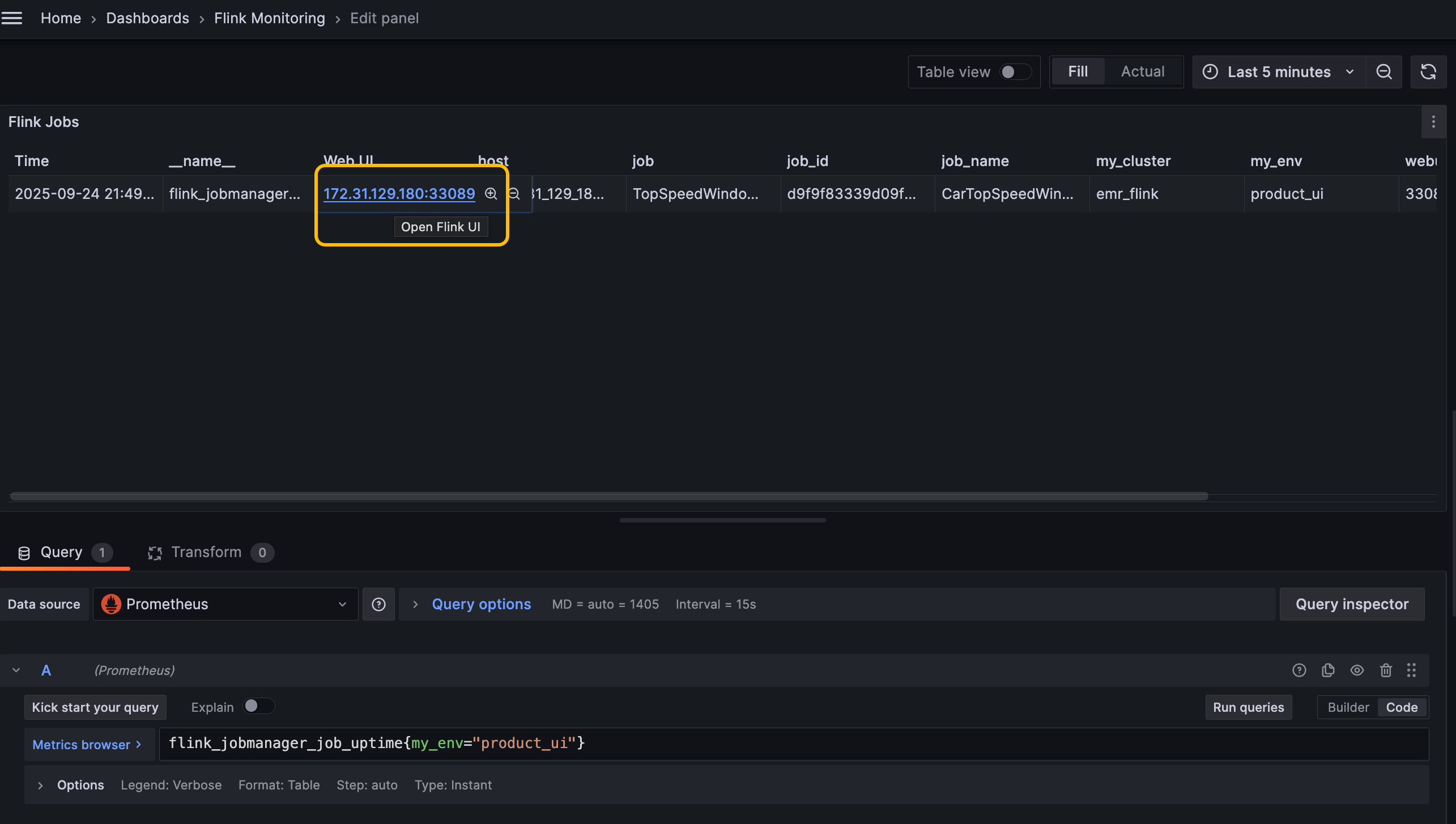
- flink prometheus metric reporter是不能获取到yarn的application id的,只能获取到flink job id. 所以无法自爱grafana上直接跳转到webui, 有一个折中的办法,可以在启动作业的时候指定webui端口,然后这个配置也传递到metric,这样就可以通过job manager 地址和port直接访问的flink webui了,如下配置。
但这个方法需要注意每个作业的port需要不一样,默认这个port是随机的,我们手动指定后每个作业的port,每个作业需要不同,因为不同作业的job manager会调度到同一台机器,所以端口要不同,这个对么个作业配置就可以。 同时咱们网络要能访问emr各个节点,就可以直接访问了,本地可以可以ssh 动态端口转发
注意修改完配置,restart prometheus就可以,或者动态加载,这个是Prometheus的配置,不是pushgateway
- 再提示您一下,指标到了Prometheus,你想要开发Dashboard, 也不用自己开发Kiro CLI可以直接帮你生成你想要的dashbaord创建好,你给到Kiro CLI Grafnan的地址和访问权限,他就可以帮你自动创建了。
三、MSF Flink使用指南
3.1 MSF Flink说明
关于MSF的基础知识本文不再赘述,本文会以一个python flink使用MSF写Iceberg的例子来做一个使用说明。对于MSF这里说明两个重要点。1. MSF的运维相比EMR on EC2 Flink的运维是要轻很多的。比如Metrics指标,日志这些都会自动发送到Cloudwatch,也不需要管理底层资源。2. MSF的成本相比EMR on EC2 Flink在大部分场景下从列表价看是要高的,但如果您的Flink作业较少,在EMR on EC2上开启高可用需要3个Master节点这会带来成本的增加,而在MSF上本身作业就是支持高可用且支持跨AZ容灾的,EMR on EC2只支持单AZ,同时是安装作业指定的KPU(1C/4GB)来计费的,因此这种情况下,MSF的成本并不一定比EMR on EC2高。
3.2 python flink SQL写Iceberg
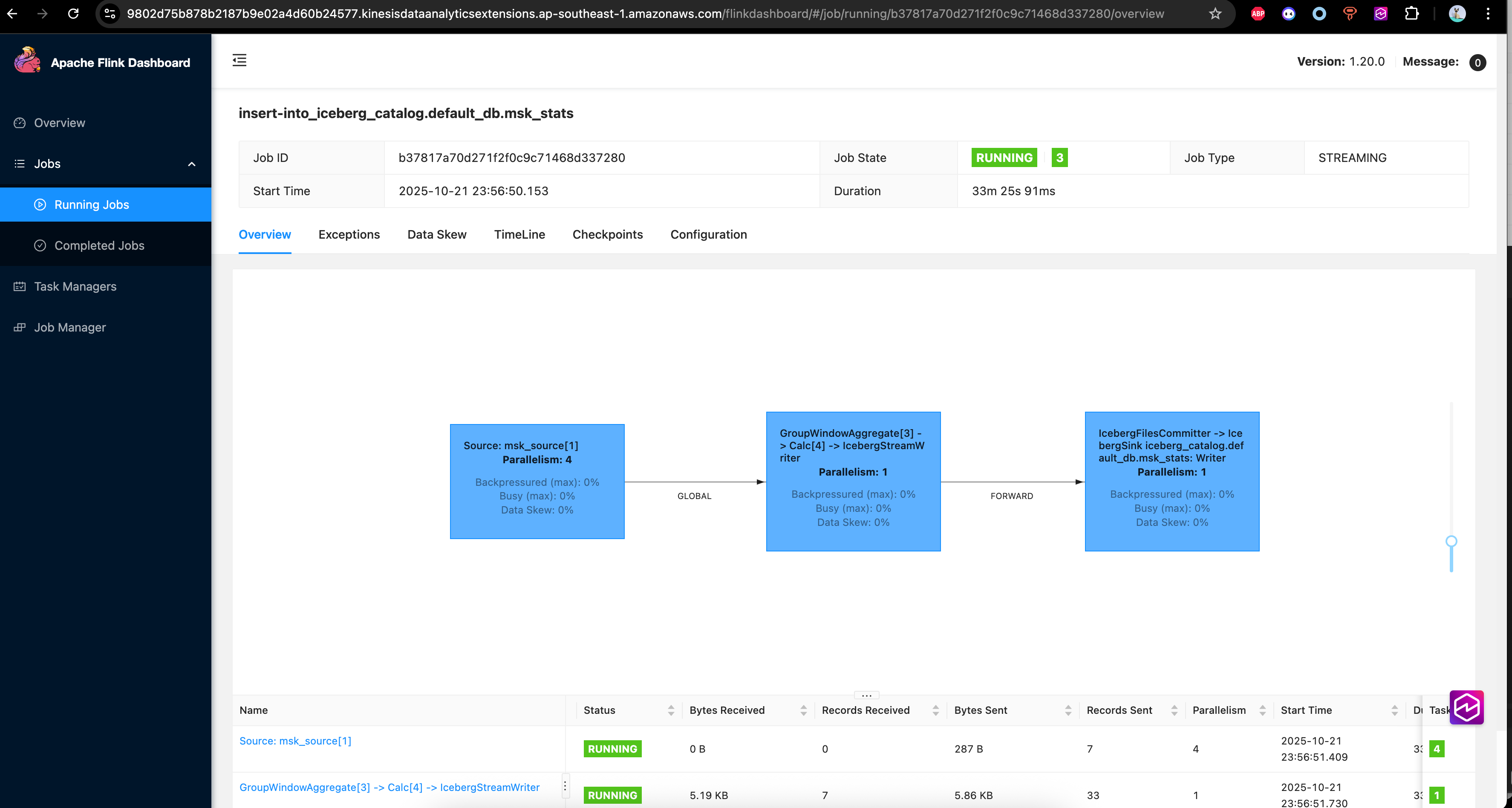
- 下面是python flink消费MSK(Kafka)数据Sink Iceberg的程序,可以看到和我们平时开发flink作业没有区别,对于使用MSF而言,最主要的是开发和调试相对不是特别遍历,可以使用python flink local模式调试,调试完毕后再部署到MSF。也有客户会选择EMR on EC2作为开发环境调试环境,MSF作为生产环境。
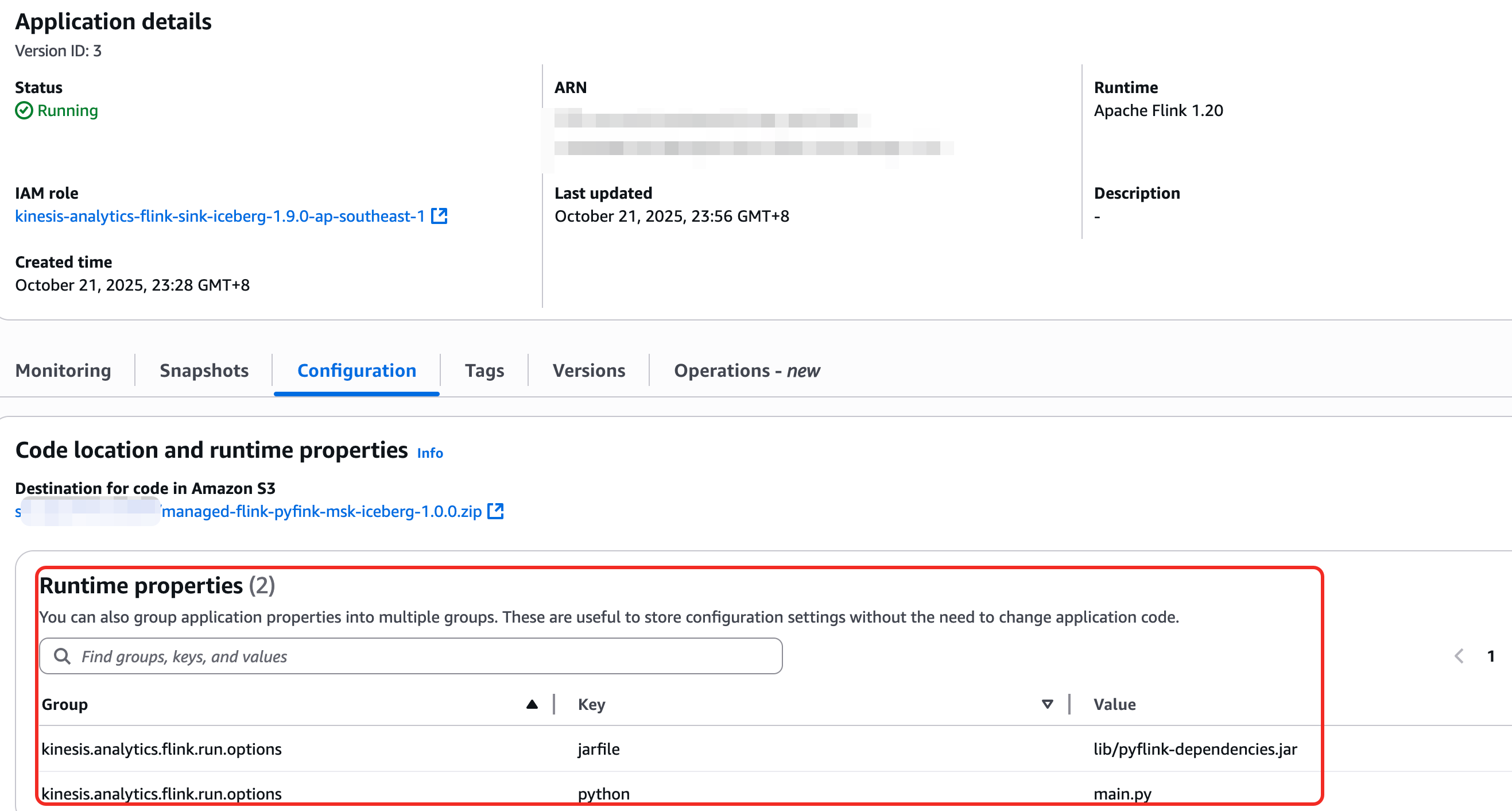
- 使用MSF时, pyflink相关的依赖jar,比如iceberg,kafka 等,都需要maven 编译打包到zip中使用,使用udf需要python的额外库,可以在添加requirenments.txt。可以参考这里
- 对于下面例子完整的MSF的作业API提交,local调试的相关代码和说明可以点击这里查看MSF-PYTHON-Flink
 |
 |
四、总结
本文内容说明了Flink引擎在亚马逊云科技上使用的最佳实践。亚马逊云科技提供了对Flink引擎的全面支持,可以满足您在不同场景的需求。Amazon EMR on EC2 Flink提供了最灵活可控的Flink运行时,Amazon Managed Service for Apache Flink提供了Serverless运行时,可以大幅度减少对Flink作业的运维,同时可以做到资源的弹性扩缩。而EMR on EKS Flink对于K8S技术栈的客户提供了便利支持。需要强调的是亚马逊云科技的Flink相比开源的Flink在AutoScaler的能力上做了扩展和增强,无论在EMR on EC2,EMR on EKS你都可以体验AutoScaler的功能带来的优势和成本节省。
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心: 云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
