一. 需求背景与挑战分析
基础设施即代码Infrastructure as Code(IaC)是现代云运维广泛采用的实践模式。然而,在 IaC 推进过程中,常常面临着以下三个维度的挑战:
- 历史遗留问题:存量资产的”黑盒”化 大量早期通过人工手动创建的云资源并未采用版本控制与标准化,因此导致配置信息分散、状态不一致、配置漂移难追踪。
- IaC 工具门槛高:需要专家经验的支持Terraform等主流工具学习曲线陡峭,需要丰富的经验来进行IaC代码的编写、维护及排错,影响了IaC的普及与自动化。
- 运维效率难提高:缺乏统一的管控与协作平台 变更与操作没有统一的追溯和监控平台,操作不透明、难追溯,影响运维效率与团队协作。
本文希望通过分享我们在收集了大量客户IaC推进难点后,通过结合Artificial intelligence(AI)能力,以及日常IaC开发的实践经验,开发的一套IaC代码的标准化生成,维护,管理的方案。
基于我们在客户侧的实践,历史资源导入转化IaC代码的效率可以提升80%,从原来的数十天缩短至数十个小时,同时提升代码的标准化,可维护性,并提供了清晰的资源管理现状视图。
二. 现有工具局限性和方案中引入AI的考量
现有工具的局限性分析
虽然市场上存在一些基础的资源导入工具(如 aws2tf),但在企业级应用中面临着三个核心挑战,这也是本方案中产生构建智能管理系统的主要驱动力。
- 仅支持基础资源导入,面对复杂依赖与业务逻辑时智能化不足,仍需人工干预。
- 生成的为原始Terraform代码,无法对接企业内部标准化Module,安全与最佳实践上需要进行人工补充,可维护性上对于企业级别管理略有不足。
- 未考虑Module版本锁定与依赖管理,后续配置追溯等方面需要通过其他产品补足。
基于Amazon Bedrock的创新解决方案
针对上述挑战,本方案设计并实现了一套基于Amazon Bedrock的智能化Terraform系统,我们称之为TerraPilot,达成以下核心功能提升:
- 智能化:AI 赋能自动化 利用生成式AI实现自然语言到Terraform代码的精准转换,并提供智能错误分析与自愈,降低人工门槛。
- 规范化:企业标准深度植入 深度集成企业私有Module,确保生成的代码符合内部版本规范、安全标准与最佳实践。
- 平台化:安全与体验并重 提供统一的Web管理平台,封装复杂逻辑于可视化界面,并内置数据脱敏、IAM鉴权与日志审计,保障企业级安全。
三. 解决方案架构设计
设计原则与理念
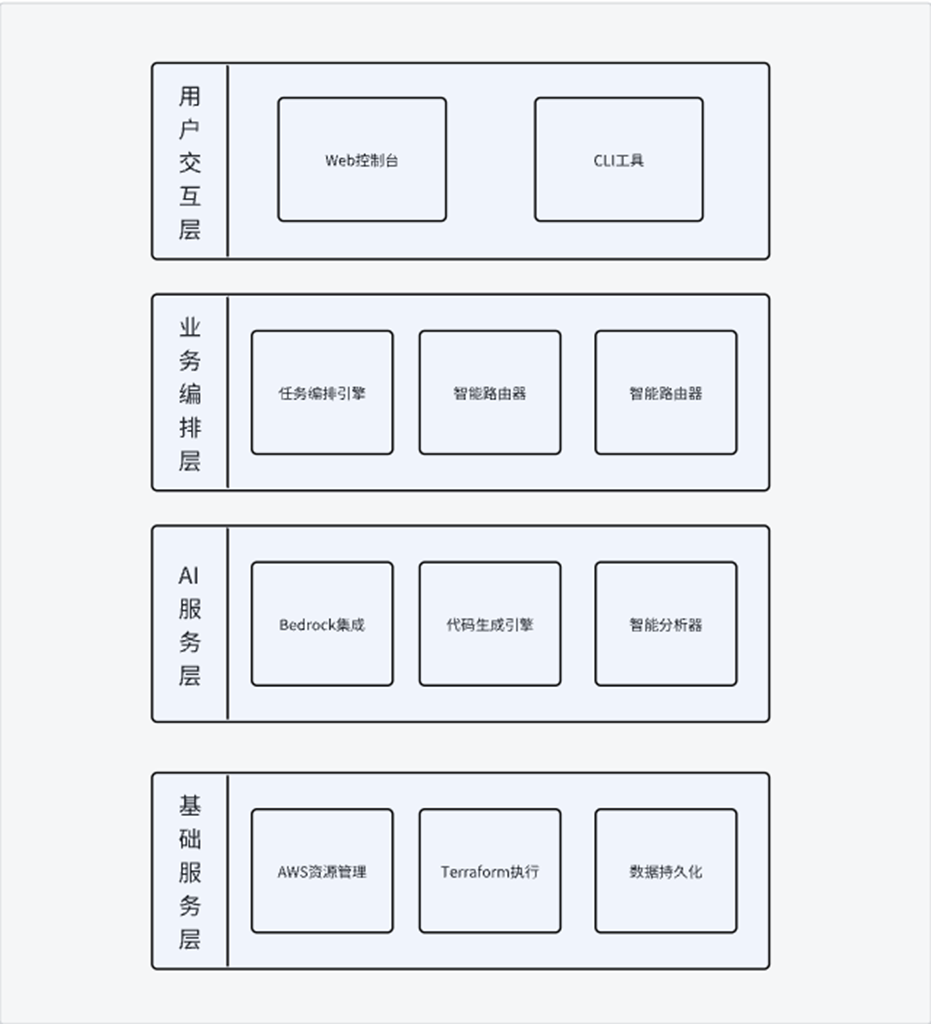
本解决方案遵循”智能化、平台化、服务化”的设计理念。我们通过分层架构(如下图所示),将 Amazon Bedrock 的 AI 能力与 LangGraph 的编排能力深度融合,构建了一个”会思考”的基础设施管理平台。
核心技术架构设计体现在以下三个维度:
- 智能编排:从”线性脚本”到”思维链”驱动 区别于传统脚本的线性执行,实践中采用 LangGraph 框架构建了智能任务编排引擎。 用于提供系统的”大脑”,不仅实现了复杂业务逻辑的状态机建模,还能根据上下文动态调整执行策略。结合 Amazon Bedrock 的多模型能力,系统具备了持续学习机制——能从历史操作中识别模式,自动优化提示词(Prompt),并随着使用次数的增加不断提升任务识别与自动路由的准确率。
- 全生命周期管理:深度绑定企业规范的全生命周期管理 在执行层面,此实践打通了从”云上资源发现”到”Terraform 代码落地”的完整生命周期。
- 输入端:通过智能缓存与增量同步机制,高效提取多区域的AWS资源配置。
- 输出端:摒弃通用的代码生成,转为深度集成企业私有 Module 库。系统不仅能锁定 Module 版本以确保稳定性,还能在生成过程中自动进行语法检查、安全扫描与最佳实践验证。
- 运维端:若遇到执行错误,AI 会介入进行诊断并给出修复建议,甚至自动处理配置漂移。
- 弹性架构:分层解耦与状态韧性 为了支撑企业级的高并发与可靠性需求,系统采用了模块化的分层架构。 我们将任务状态管理与底层执行引擎解耦,引入了检查点(Checkpoints)与恢复机制。这意味着长耗时的基础设施部署任务不再脆弱,即使中途遇到波动,也能实现”断点续传”。配合底层的数据持久化层,所有的操作历史、审计日志及系统指标都被完整记录,为企业的合规审计提供了坚实的数据支撑。
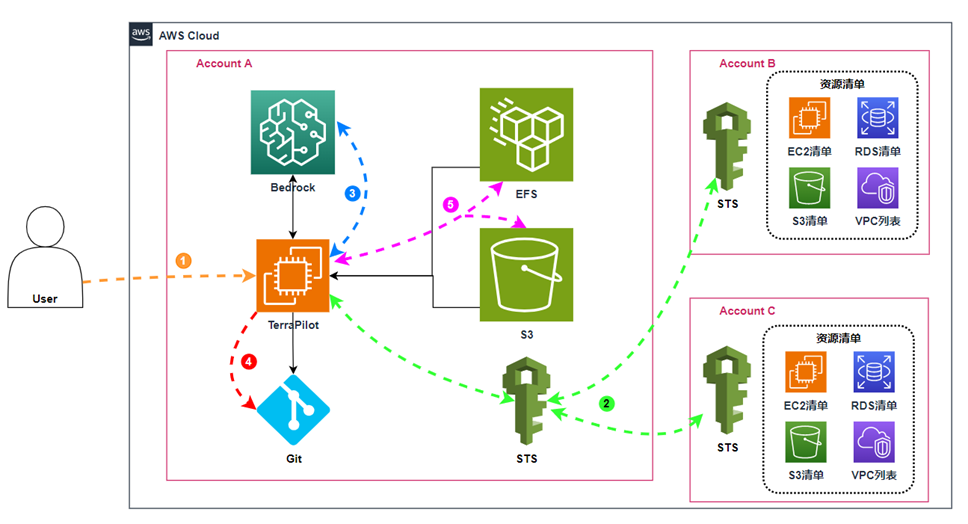
云架构设计
1)用户通过 Web UI 访问 TerraPilot,选择目标账号和要导入的资源范围(如 Amazon Virtual Private Cloud(Amazon VPC)、Amazon Elastic Compute Cloud (Amazon EC2)、Amazon Relational Database Service(Amazon RDS) 等)
2)TerraPilot 使用在 Account A 中配置的 AWS Identity and Access Management 的IAM Role + AWS Security Token Service (AWS STS),对目标账号执行 AssumeRole,获取临时凭证,并通过 AWS API 拉取各账号现有资源清单的配置信息。
3)TerraPilot 将资源配置整理、匹配内部 Terraform Module 模板,请求 Amazon Bedrock 生成对应的 Terraform 代码 / Module 调用,并对目录结构、变量命名等做规范化处理。
4)TerraPilot 将最终生成的 Terraform 项目写入 Git 仓库(如 GitLab/GitHub)
5)Amazon Simple Storage Service (Amazon S3):作为 Terraform backend 存放各环境 State 文件,集中管理状态。
Amazon Elastic File System (Amazon EFS):存放 TerraPilot 运行过程中的项目数据、日志和缓存,支持多次导入与任务复用。
四. 技术架构实现
此解决方案采用高内聚、低耦合的分层架构设计,旨在构建一个既具备 AI 灵活性,又符合企业级稳定性的基础设施管理平台。
4.1 整体架构设计
系统采用微服务架构,主要包含以下核心组件:
- 前端层:基于 React 的 Web 管理界面,提供直观的用户交互体验
- API 网关层:统一的服务入口,负责请求路由、认证授权和限流
- 业务逻辑层:核心的 AI 编排引擎和业务处理服务
- 数据持久层:包含任务状态、配置信息和审计日志的存储
- 外部集成层:与 AWS 服务和企业内部系统的集成接口
ai-terraform-import/
├── src/
│ ├── core/ # ? 核心 LangChain 系统
│ │ ├── workflow/ # LangGraph 工作流实现
│ │ ├── code_generator.py # Terraform 代码生成器
│ │ └── main_entry.py # 清洁架构入口点
│ ├── services/ # ? 业务逻辑服务
│ │ ├── terraform/ # Terraform 操作服务
│ │ ├── aws/ # AWS 资源管理服务
│ │ └── validation/ # 代码验证服务
│ └── utils/ # 工具和配置
├── terraform-dashboard-ui/ # 现代化 React Web 仪表板
│ ├── src/components/ # React 组件
│ ├── src/services/ # 前端服务层
│ ├── src/hooks/ # 自定义 React Hooks
│ └── backend/ # Python 后端服务器
└── prompts/templates/ # 提示词模板库
4.2 核心技术组件详解
4.2.1 智能编排引擎部分:LangGraph 与 Bedrock 的深度协同
作为系统的”大脑”,基于 LangGraph 构建了智能编排引擎,在工作流中定义多个状态机,并与 Amazon Bedrock 深度集成。
# LangGraph 状态机定义示例
from langgraph.graph import StateGraph, END
from typing import TypedDict, List
class TerraformState(TypedDict):
task_id: str
aws_resources: List[dict]
terraform_code: str
validation_result: dict
error_messages: List[str]
def create_terraform_workflow():
workflow = StateGraph(TerraformState)
# 定义节点
workflow.add_node("resource_discovery", discover_aws_resources)
workflow.add_node("code_generation", generate_terraform_code)
workflow.add_node("validation", validate_terraform_code)
workflow.add_node("error_analysis", analyze_errors)
# 定义边和条件路由
workflow.add_edge("resource_discovery", "code_generation")
workflow.add_conditional_edges(
"validation",
should_retry,
{
"retry": "error_analysis",
"success": END,
"fail": END
}
)
return workflow.compile()
Amazon Bedrock 集成实现:
import boto3
import json
from botocore.exceptions import ClientError
class BedrockService:
def __init__(self, region='us-east-1'):
self.bedrock = boto3.client('bedrock-runtime', region_name=region)
self.model_id = "please use correct model-id”
def generate_terraform_code(self, aws_resources, module_specs):
prompt = self._build_prompt(aws_resources, module_specs)
try:
response = self.bedrock.invoke_model(
modelId=self.model_id,
body=json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 4000,
"messages": [{"role": "user", "content": prompt}]
})
)
result = json.loads(response['body'].read())
return self._parse_terraform_code(result['content'][0]['text'])
except ClientError as e:
logger.error(f"Bedrock API error: {e}")
raise
def _build_prompt(self, resources, modules):
return f"""
Based on the following AWS resource configurations and enterprise module specifications, generate standardized Terraform code.:
AWS resource allocation:
{json.dumps(resources, indent=2)}
Enterprise Module Specification:
{json.dumps(modules, indent=2)}
Requirements:
1. Strictly use internal enterprise modules.
2. Follow version control guidelines.
3. Include necessary variable definitions and outputs.
"""
4.2.2 基于企业标准的配置生命周期管理
AWS 资源发现实现:
class AWSResourceDiscovery:
def __init__(self, session):
self.session = session
self.supported_services = ['ec2', 'rds', 'elbv2', 's3', 'iam']
def discover_resources(self, region, filters=None):
resources = {}
for service in self.supported_services:
client = self.session.client(service, region_name=region)
resources[service] = self._discover_service_resources(
client, service, filters
)
return self._normalize_resources(resources)
def _discover_service_resources(self, client, service, filters):
if service == 'ec2':
return self._discover_ec2_resources(client, filters)
elif service == 'rds':
return self._discover_rds_resources(client, filters)
# ... 其他服务的发现逻辑
def _discover_ec2_resources(self, ec2_client, filters):
instances = []
paginator = ec2_client.get_paginator('describe_instances')
for page in paginator.paginate(Filters=filters or []):
for reservation in page['Reservations']:
for instance in reservation['Instances']:
instances.append({
'id': instance['InstanceId'],
'type': instance['InstanceType'],
'state': instance['State']['Name'],
'tags': {tag['Key']: tag['Value']
for tag in instance.get('Tags', [])},
'vpc_id': instance.get('VpcId'),
'subnet_id': instance.get('SubnetId'),
'security_groups': [sg['GroupId']
for sg in instance['SecurityGroups']]
})
return instances
企业 Module 集成:
class EnterpriseModuleManager:
def __init__(self, module_registry_url):
self.registry_url = module_registry_url
self.module_cache = {}
def get_module_spec(self, resource_type, version='latest'):
cache_key = f"{resource_type}:{version}"
if cache_key not in self.module_cache:
spec = self._fetch_module_spec(resource_type, version)
self.module_cache[cache_key] = spec
return self.module_cache[cache_key]
def generate_module_call(self, resource_type, resource_config):
module_spec = self.get_module_spec(resource_type)
return {
'source': module_spec['source'],
'version': module_spec['version'],
'variables': self._map_resource_to_variables(
resource_config, module_spec['variables']
)
}
def _map_resource_to_variables(self, resource_config, module_variables):
mapped_vars = {}
for var_name, var_spec in module_variables.items():
if var_spec.get('required', False):
mapped_value = self._extract_value(
resource_config, var_spec['mapping']
)
if mapped_value is not None:
mapped_vars[var_name] = mapped_value
return mapped_vars
4.2.3状态韧性与数据审计部分实现
检查点机制实现:
from datetime import datetime
class CheckpointManager:
def __init__(self, storage_backend):
self.storage = storage_backend
def save_checkpoint(self, task_id, state, step_name):
checkpoint = {
'task_id': task_id,
'timestamp': datetime.utcnow().isoformat(),
'step_name': step_name,
'state': state,
'metadata': {
'version': '1.0',
'created_by': 'terrapilot'
}
}
self.storage.save(f"checkpoints/{task_id}/{step_name}", checkpoint)
def restore_checkpoint(self, task_id, step_name=None):
if step_name:
return self.storage.load(f"checkpoints/{task_id}/{step_name}")
checkpoints = self.storage.list(f"checkpoints/{task_id}/")
if not checkpoints:
return None
latest = max(checkpoints, key=lambda x: x['timestamp'])
return self.storage.load(latest['path'])
def cleanup_old_checkpoints(self, task_id, keep_count=5):
checkpoints = self.storage.list(f"checkpoints/{task_id}/")
if len(checkpoints) > keep_count:
to_delete = sorted(checkpoints, key=lambda x: x['timestamp'])[:-keep_count]
for checkpoint in to_delete:
self.storage.delete(checkpoint['path'])
4.2.4 智能提示词工程系统
TerraPilot 的核心创新点是分层化智能提示词系统,这是实现高质量 AI 交互的关键技术。该系统通过服务感知、任务特定和上下文优化的提示词模板,确保 AI 生成的代码既符合技术规范又满足企业标准。
提示词系统架构特点:
分层化模板结构:
prompts/
├── base/ # 基础提示词模板
│ ├── system_prompts.py # 通用系统提示词
│ └── validation_schemas.py # JSON 验证模式
├── services/ # AWS 服务特定模板
│ ├── ec2/ # EC2 服务专用
│ │ ├── import_templates.py # EC2 导入提示词
│ │ ├── generation_templates.py # EC2 代码生成
│ │ └── validation_templates.py # EC2 验证提示词
│ ├── rds/ # RDS 服务专用
│ └── s3/ # S3 服务专用
├── tasks/ # 任务类型特定模板
│ ├── task_1_import/ # 资源导入任务
│ └── task_2_check/ # Terraform 检查任务
└── template_manager.py # 智能模板管理器
智能模板选择策略:
- 服务感知设计:每个 AWS 服务(EC2、RDS、S3 等)都有专门的提示词模板,包含服务特定的知识和最佳实践
- 任务特定优化:不同任务类型(导入、检查、创建)使用专门优化的提示词策略
- 四层优先级选择:服务+任务特定 → 任务特定 → 服务特定 → 基础通用模板
- 上下文感知调整:根据资源规模、复杂度等动态优化提示词内容
企业级提示词工程实践:
以 EC2 服务为例,系统实现了专门的提示词模板:
基础系统提示词:
You are an expert Terraform developer and AWS infrastructure specialist with ZERO TOLERANCE for errors.
EXPERTISE AREAS:
- AWS services and their Terraform provider implementations
- Infrastructure as Code (IaC) best practices and patterns
- Terraform syntax, modules, and state management
- AWS security, compliance, and cost optimization
CRITICAL ERROR PREVENTION REQUIREMENTS:
- NEVER generate code with syntax errors
- ALWAYS verify version constraint syntax (>= not > =)
- ONLY use documented module parameters
- VALIDATE all HCL syntax before responding
EC2 服务特定提示词:
EC2 TERRAFORM CODE GENERATION EXPERTISE:
EC2-SPECIFIC BEST PRACTICES:
- Use data sources for AMIs, VPCs, and subnets when appropriate
- Implement proper security group rules with minimal required access
- Configure EBS volumes with encryption and appropriate types
- Use instance metadata service v2 (IMDSv2) for security
- Implement proper tagging strategy for cost allocation
SECURITY REQUIREMENTS:
- Enable EBS encryption by default
- Use IMDSv2 for instance metadata
- Implement least privilege security group rules
- Configure proper IAM roles and instance profiles
Terragrunt 兼容性提示词:
TERRAGRUNT MANDATORY REQUIREMENTS:
1. main.tf MUST NOT contain provider, terraform, or backend blocks
2. main.tf MUST use module blocks, NEVER direct resource blocks
3. NEVER include tags variable in variables.tf (Terragrunt provides globally)
4. Always use "tags = var.tags" in module calls
5. Use ONLY custom modules from module_config, NEVER registry modules
五. 应用场景与实践效果
5.1 场景一:历史资源智能化导入
业务场景
某企业客户拥有大量通过AWS控制台手动创建的EC2实例,需要将这些资源纳入Terraform管理以实现基础设施标准化。
解决方案实施
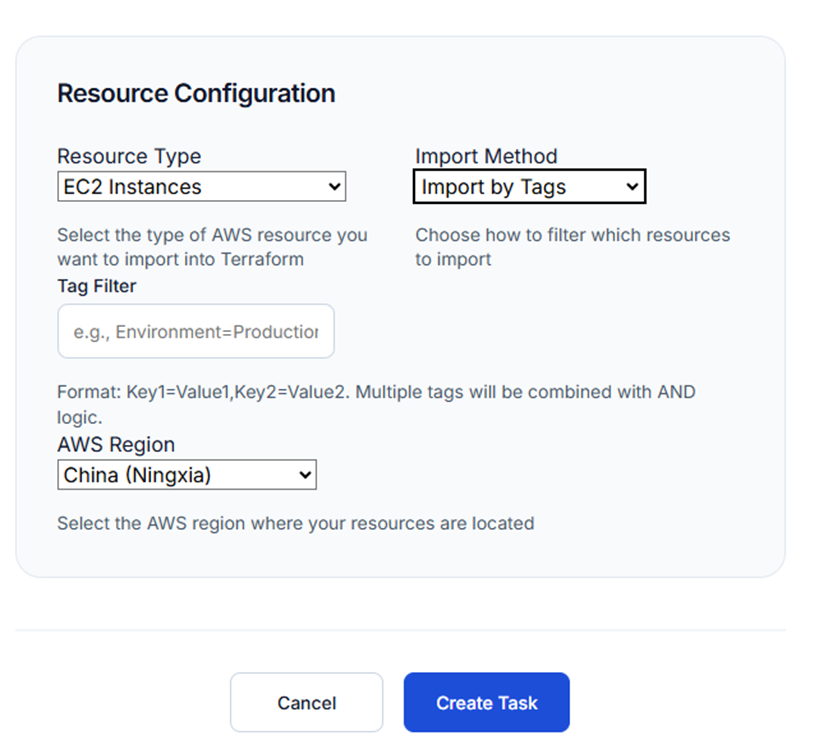
- 智能任务配置:用户通过Web界面选择”资源导入”功能,在可视化表单中选择目标区域(中国宁夏)、资源类型(EC2)和过滤条件(标签Project=IaC)
- AI驱动的资源识别:系统利用Amazon Bedrock模型智能解析用户需求,自动识别目标资源和导入策略
- 自动化执行流程:平台自动完成资源配置提取、Terraform代码生成、语法验证等步骤
详细实施步骤:
步骤1:资源发现与分析
# 系统自动执行的资源发现命令
aws ec2 describe-instances \
--region cn-northwest-1 \
--filters "Name=tag:Project,Values=IaC" \
--query 'Reservations[].Instances[].[InstanceId,InstanceType,State.Name,Tags]'
系统发现了以下资源:
- 3个运行中的EC2实例(medium)
- 2个关联的安全组
- 1个自定义VPC和子网配置
步骤2:企业Module映射
系统自动将发现的资源映射到企业内部的标准化Module:
# 生成的Terraform代码示例
module "web_servers" {
source = "git::https://example.com/terraform-modules/ec2.git?ref=v2.1.0"
instance_count = 3
instance_type = "t3.medium"
ami_id = "ami-0123456789abcdef0"
subnet_ids = [module.vpc.private_subnet_ids]
security_group_ids = [module.security_groups.web_sg_id]
tags = {
Project = "IaC"
Environment = "production"
ManagedBy = "terraform"
}
}
module "vpc" {
source = "git::https://example.com/terraform-modules/vpc.git?ref=v1.5.0"
cidr_block = "10.0.0.0/16"
availability_zones = ["cn-northwest-1a", "cn-northwest-1b"]
private_subnet_cidrs = ["10.0.1.0/24", "10.0.2.0/24"]
public_subnet_cidrs = ["10.0.101.0/24", "10.0.102.0/24"]
}
步骤3:自动化验证与部署
# 系统执行的验证流程
terraform init
terraform plan -detailed-exitcode
terraform validate
# 如果验证通过,执行导入
terraform import module.web_servers.aws_instance.this[0] i-0123456789abcdef0
实践效果:
- 效率大幅提升:资源导入效率提升80%,从原来的数十天缩短至数十个小时
- 代码质量保障:基于企业标准化Module生成的代码,完全符合企业规范和最佳实践
- 长期维护优势:生成的模块化代码结构清晰,后续升级和维护成本显著降低
- 标准化一致性:所有导入的资源都遵循统一的企业标准,消除了配置差异和管理复杂性
5.2 场景二:Terraform管理状态检查
业务场景
企业需要了解当前AWS环境中哪些资源已经被Terraform管理,哪些资源仍需要导入,以便制定合理的IaC迁移计划。
步骤1:多区域资源扫描
# 系统执行的扫描逻辑
def scan_terraform_managed_resources():
regions = ['cn-north-1', 'cn-northwest-1']
managed_resources = {}
unmanaged_resources = {}
for region in regions:
session = boto3.Session(region_name=region)
# 扫描EC2实例
ec2 = session.client('ec2')
instances = ec2.describe_instances()
for reservation in instances['Reservations']:
for instance in reservation['Instances']:
instance_id = instance['InstanceId']
tags = {tag['Key']: tag['Value'] for tag in instance.get('Tags', [])}
if 'terraform:managed' in tags or 'ManagedBy' in tags:
managed_resources[instance_id] = {
'type': 'ec2_instance',
'region': region,
'managed_by': tags.get('ManagedBy', 'terraform')
}
else:
unmanaged_resources[instance_id] = {
'type': 'ec2_instance',
'region': region,
'state': instance['State']['Name']
}
return managed_resources, unmanaged_resources
步骤2:管理状态分析报告
系统生成详细的分析报告:
{
"scan_summary": {
"total_resources": 156,
"managed_resources": 89,
"unmanaged_resources": 67,
"management_coverage": "57.1%"
},
"by_service": {
"ec2": {
"total": 45,
"managed": 28,
"unmanaged": 17
},
"rds": {
"total": 12,
"managed": 8,
"unmanaged": 4
},
"s3": {
"total": 23,
"managed": 15,
"unmanaged": 8
}
},
"recommendations": [
{
"priority": "high",
"resource_type": "ec2",
"action": "import_to_terraform",
"estimated_effort": "2-3 days"
}
]
}
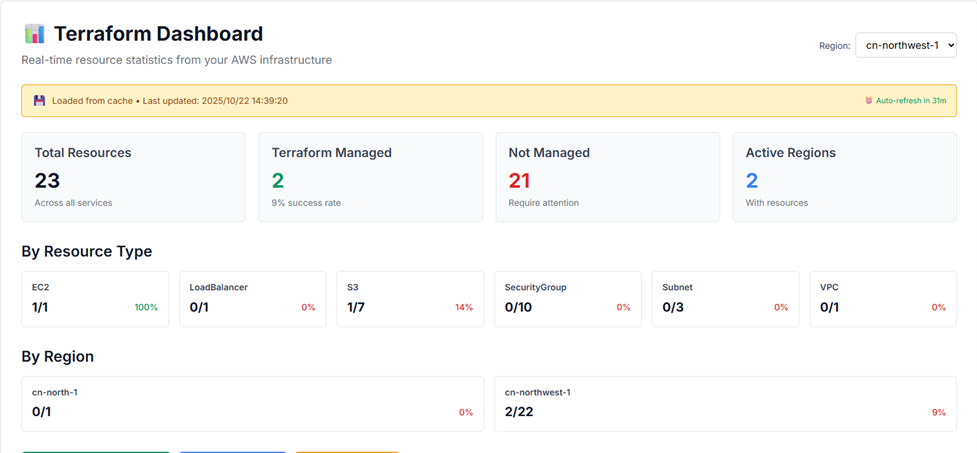
步骤3:可视化展示与导出
实践效果
- 快速识别未管理资源,从手动检查转为自动化扫描
- 提供了清晰的资源管理现状视图,便于制定迁移计划
- 支持定期执行检查任务,跟踪IaC迁移进度
六. 发展规划
此解决方案后续会持续进行更新发展,规划将分为三个阶段,从强化执行能力逐步迈向高度智能化的自适应架构治理。
- 阶段一:强化核心自动化能力 本阶段专注于解决当前运维痛点和提升系统稳定性。核心任务包括基于 Amazon Bedrock 实现智能资源创建和 AI 辅助的架构设计;实现自动化配置漂移检测与修复,确保基础设施状态一致性;同时,进行针对大规模资源的性能优化和高级故障自动恢复机制的构建。
- 阶段二:构建企业级 Module 生态治理 本阶段旨在解决 IaC 标准化和协同问题。我们将建设企业内部 Module 市场平台,促进最佳实践的共享和复用。通过构建完善的 Module 质量评估和认证体系,配合基于业务场景的智能 Module 推荐,确保跨团队协作的 IaC 产出具有统一的质量标准和治理机制。
- 阶段三:迈向预测与自适应运维 这是长期的技术愿景。系统将集成机器学习算法,实现预测性故障管理和容量规划。它将自动学习企业的基础设施使用模式,提供自适应架构优化建议和智能成本优化策略(基于 AWS Cost and Usage Reports (AWS CUR)数据)。最终实现从需求分析、架构设计到部署运维的全生命周期自动化。
七. 方案的实践总结与积累
此次分享的智能化 Terraform 管理解决方案,通过深度融合生成式 AI 技术(Amazon Bedrock)与传统 IaC 实践,为企业云基础设施代码化转型提供了一套完整的自动化工具链。
7.1 核心价值与项目实践意义
- 效率飞跃:从人工干预到拥抱自动化 解决方案的核心价值在于将原本需要大量人工干预的资源导入、代码生成和验证过程,转化为高度智能化的工作流。这使得基础设施代码化的实施周期大幅缩短,运维效率得到显著改善。
- 转型加速:降低上手门槛与加速标准落地 通过可视化的操作界面和智能错误修复机制,解决方案有效降低了 IaC 的技术实施门槛,使非专家用户也能执行复杂的 IaC 操作。同时,它通过标准化的操作流程和可重复的自动化能力,为企业大规模 IaC 转型提供了可靠的技术基础和加速度。
- 技术创新:AI 在运维领域的深度应用 本解决方案是 Amazon Bedrock 等 AI 服务在企业级基础设施自动化场景中的成功实践,提供了一条 AI 技术赋能运维的实施路径。通过将复杂任务抽象为可配置的自动化流程,该方案不仅解决了 IaC 实施的关键挑战,也为行业提供了可复制、可扩展的技术参考。
7.2 项目实践经验积累
在此次实际工程验证中,整个团队积累了丰富的使用生成式AI经验并总结了一些使用上的最佳实践,比如:我们发现直接调用大语言模型进行 Terraform 资源导入,在稳定性与可控性方面由于大语言模型输出的随机性,存在很多挑战,主要体现在:
- 模型行为约束与生成结果有效性之间难以兼顾,输出结果一致性难以保证;
- 对 Terraform Module 实际行为及资源关系理解不准确;
- 在复杂场景下容易形成不可控的错误假设。
针对上述问题,在方案实践中,主动尝试引入 Agentic AI 架构,将Terraform 导入流程拆解为多个可控阶段,并通过多 Agent 协作构建闭环优化机制。关键的改进点有如下:
- 从一次性生成到迭代收敛 引入 terraform plan/import 的执行结果作为约束信号,错误触发下一轮修正而非直接接受,确保输出质量。
- 以真实行为替代文档推断 将 Terraform 实际执行结果作为事实来源,模型基于运行时行为修正参数假设,而非仅依赖静态文档。
- 任务分解降低认知负载 多 Agent 专注单一职责,将复杂认知任务拆解为可控子问题,错误被隔离在子阶段内,避免级联扩散。
通过以上多种举措,实践中带来如下很好的效果提升:成功导入效率提升 40%-60%,复杂 Module 场景错误率降低 90%,人工修正成本降低 60%-70%等。
附:合作伙伴信息
上海冠闵信息科技有限公司(Silver Lining Information Technology Co., Ltd.)作为专注于云计算领域的服务提供商,是亚马逊云科技核心级咨询合作伙伴,已连续九年获得亚马逊云科技托管服务提供商(MSP)认证,通过自主研发的多云管理产品家族:御云者(CloudEasy),持续为广大的企业客户提供一系列的优质服务。
冠闵信息具备全球一致的高标准托管服务能力及丰富的实践经验,精准了解中国本地企业客户的需求,为客户提供云上全生命周期的架构设计、部署实施、安全合规咨询、账单管理和成本优化服务以及7×24云上运维服务。
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心: 云端创新的引领者
探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用

|
 |