亚马逊AWS官方博客
如何在Amazon Athena中在线解密在Amazon Glue DataBrew中加密的数据
 |
背景分析
在企业数字化转型的浪潮中,依托于数据驱动的决策和洞察变得尤为重要。云端数据湖已成为企业汇聚、加工和分析海量数据的重要平台。而于此同时,全球各国对个人隐私数据保护也越来越重视,要求企业在收集、使用和传输个人信息PII(Personally Identifiable Information)时遵守更加严苛的合规要求。因而,企业需要对敏感数据采取合适的保护措施,来防止个人身份信息 PII 数据泄露。
Amazon Glue DataBrew 是亚马逊云科技数据服务Amazon Glue中一款可视化数据处理工具。数据分析师不用编码,采用图形化的界面就可以对数据集进行操作。Amazon Glue DataBrew内置了多种功能,能够识别敏感数据并进行大规模预处理,其中一项关键功能就是对PII数据(如姓名、社保号、地址等)进行加密,防止数据泄露。虽然Amazon Glue DataBrew对加密的数据集提供了对应解密的方法,但是该方法仍然需要调用Amazon Glue DataBrew的Recipe解密方法进行数据解密处理,这不仅繁琐而且会形成多个副本,难以满足即时解密查询的要求。
本文介绍了如何在Amazon Athena中,通过用户定义函数UDF(User Defined Function)在查询过程中解密这些在Amazon Glue DataBrew中加密的数据。该UDF以Amazon Lambda函数的方式实现,通过精细的权限控制,可以确保只有获得授权的用户才能执行解密操作,查看明文数据,其他未授权用户只能看到加密后的字段。这种方法既保护了敏感数据的安全,又为授权用户提供了灵活的数据访问途径,实现了安全性与可用性的平衡。
方案场景说明
为了演示整个数据加密和解密流程,我们需要提前准备一份包含敏感信息的样例数据。我们从 DLPTEST (https://dlptest.com) 下载名为 sample_data.csv 的示例数据集。这个文件包含模拟的个人身份信息(PII)例如姓名、地址、电话号码、电子邮件地址和社会安全号码(SSN)等。该方案执行流程如下图所示,无论在亚马逊云科技的中国区域还是全球区域都可实现:
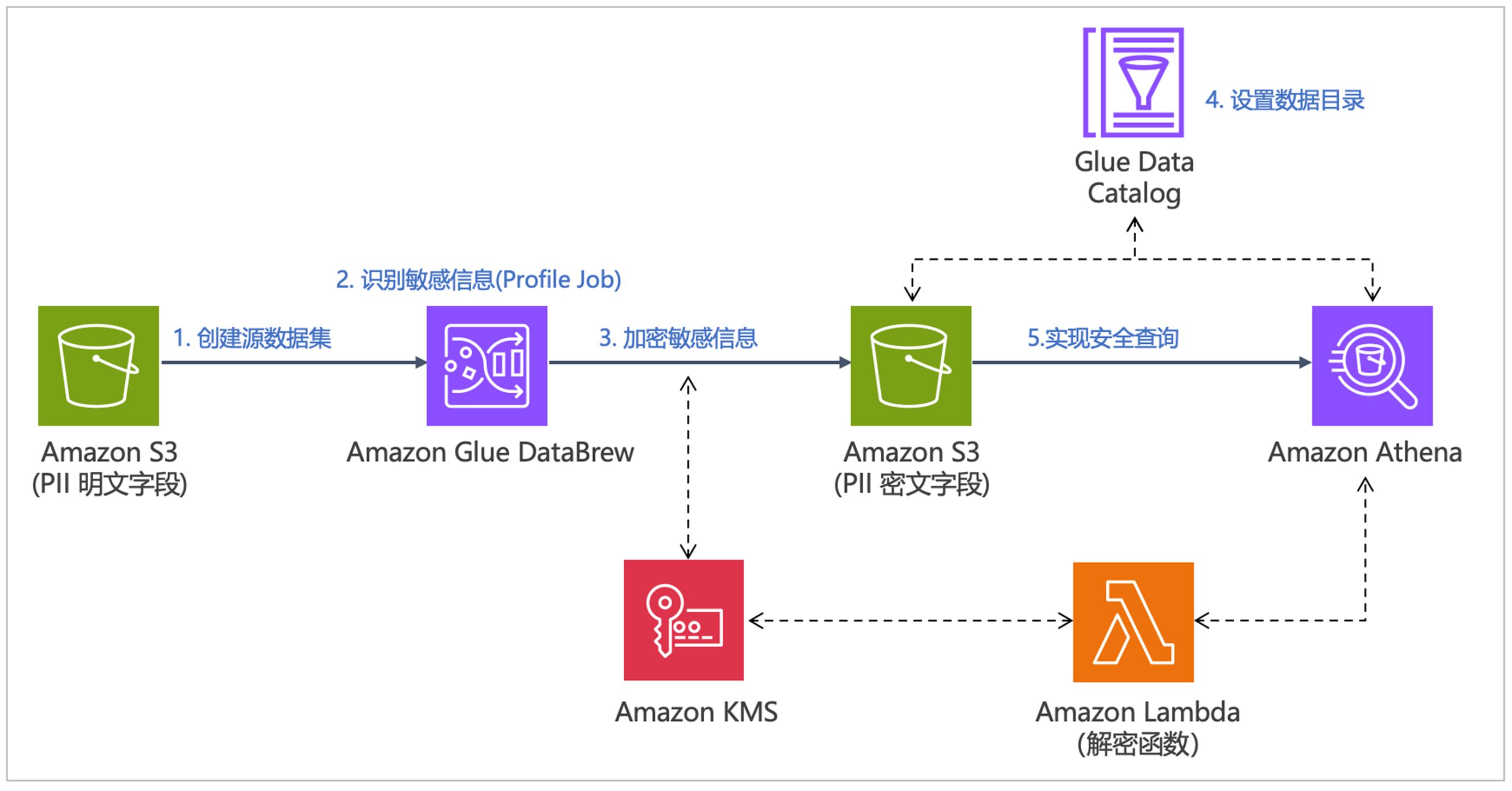 |
该方案的具体执行流程如下:
- 创建源数据集:我们将下载的包含敏感信息的样例数据上传到一个未加密的 Amazon S3 存储桶中。然后,在 Amazon Glue DataBrew 中创建一个新的数据集,建立与这个 S3 存储桶中数据的连接。方便后续的数据处理和加密操作。
- 识别敏感信息:利用Amazon Glue DataBrew 的内置功能来识别数据中的敏感信息列。在 DataBrew 的Profile Job中启用个人身份信息(PII)统计功能,该作业会自动扫描数据集,识别出可能包含 PII 的列,如姓名、地址、社会安全号码等。
- 加密敏感数据:针对识别的 PII 列,我们在 DataBrew 中创建一个 处置方案Recipe。这个 Recipe 包含了对特定敏感列应用加密转换函数的步骤。通过执行一个 DataBrew 作业,调用 Recipe中的加密过程加密源数据集的指定列。作业完成后,加密后的数据输出到指定的目标 S3 存储桶中,实现了加密后敏感数据的安全存储。
- 设置数据目录:为了便于后续查询和使用加密后的数据,我们需要建立相应的元数据目录。通过在Amazon Athena中运行DDL语句,在 Amazon Glue Data Catalog中,基于加密后的数据构建数据库和表,来创建元数据条目,这样,加密后的数据可以在Amazon Athena中通过标准 SQL 接口进行查询。
- 实现安全查询:开发并部署一个用户自定义函数(UDF)作为 Amazon Lambda 函数,用于解密数据。部署成功后,在 Amazon Athena 中引用这个 UDF,使其能够在查询执行时调用解密 Amazon Lambda 函数。这样,用户就可以通过 Amazon Athena 执行 SQL 查询,实时调用解密函数查看明文数据,实现了敏感数据的安全查询和访问。另外,通过严格的授权,可以防止非授权用户通过其他途径获取明文。
方案实现
准备源数据
测试数据来自于DLPTEST提供的样例数据,访问 https://dlptest.com/sample-data.csv 下载csv格式文件。通过控制台在中国宁夏区域 cn-northwest-1 中创建存储桶 databrew-pii-data-zhanla,并在存储桶内创建三个文件夹(Prefix),其中:
-
- sensitive_data_input用来存放源数据。
- encrypted_data_output用来存放加密后的输出文件。
- profile_job_out用来存放Profile作业的统计输出。
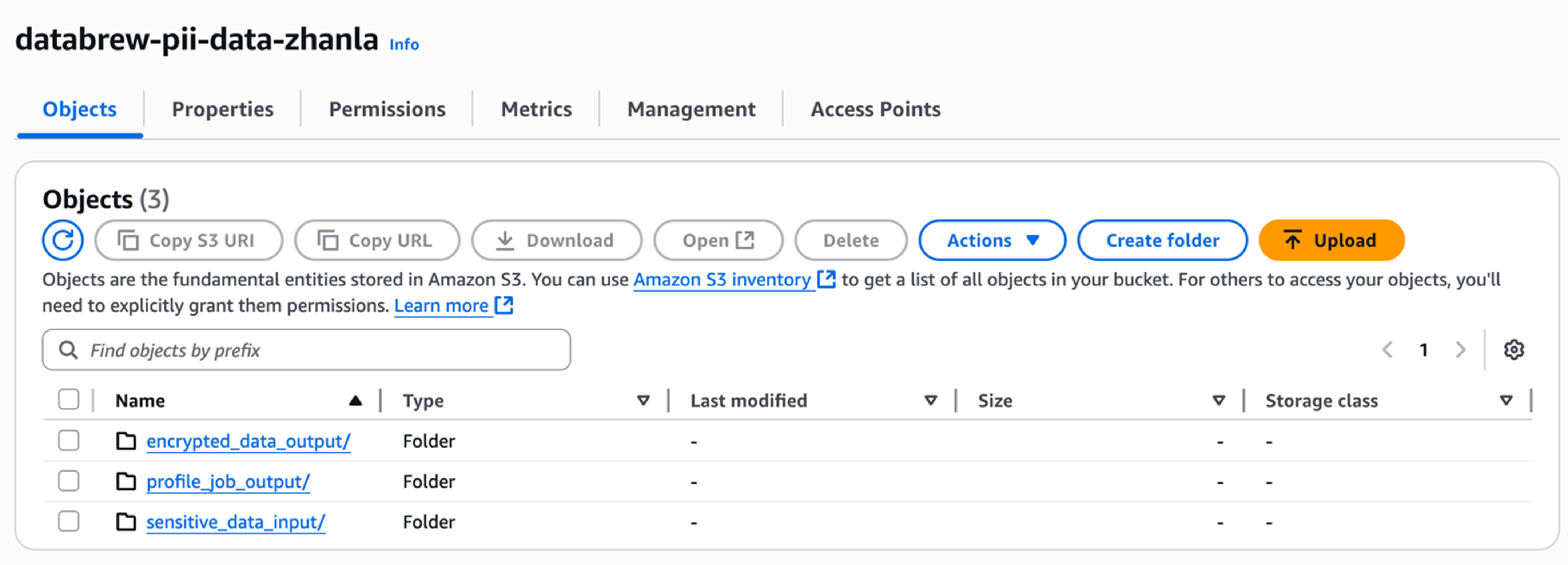 |
文件夹建好后,上传文件文件“sample-data.csv” 到该S3存储桶中的 “sensitive_data_input” 文件夹中。也可以运行如下的cli命令达到同样目的:
识别敏感信息
上载数据后,我们需要创建DataBrew数据集,运行DataBrew Profile作业,来分析数据集中的PII敏感数据列。
创建源数据集
按照以下步骤创建 Amazon Glue DataBrew 数据集DataSet:
- 在 DataBrew 控制台左侧的导航栏,选择数据集 “DATASETS”。
- 选择连接新数据集 “Connect new dataset”,在向导页中:
-
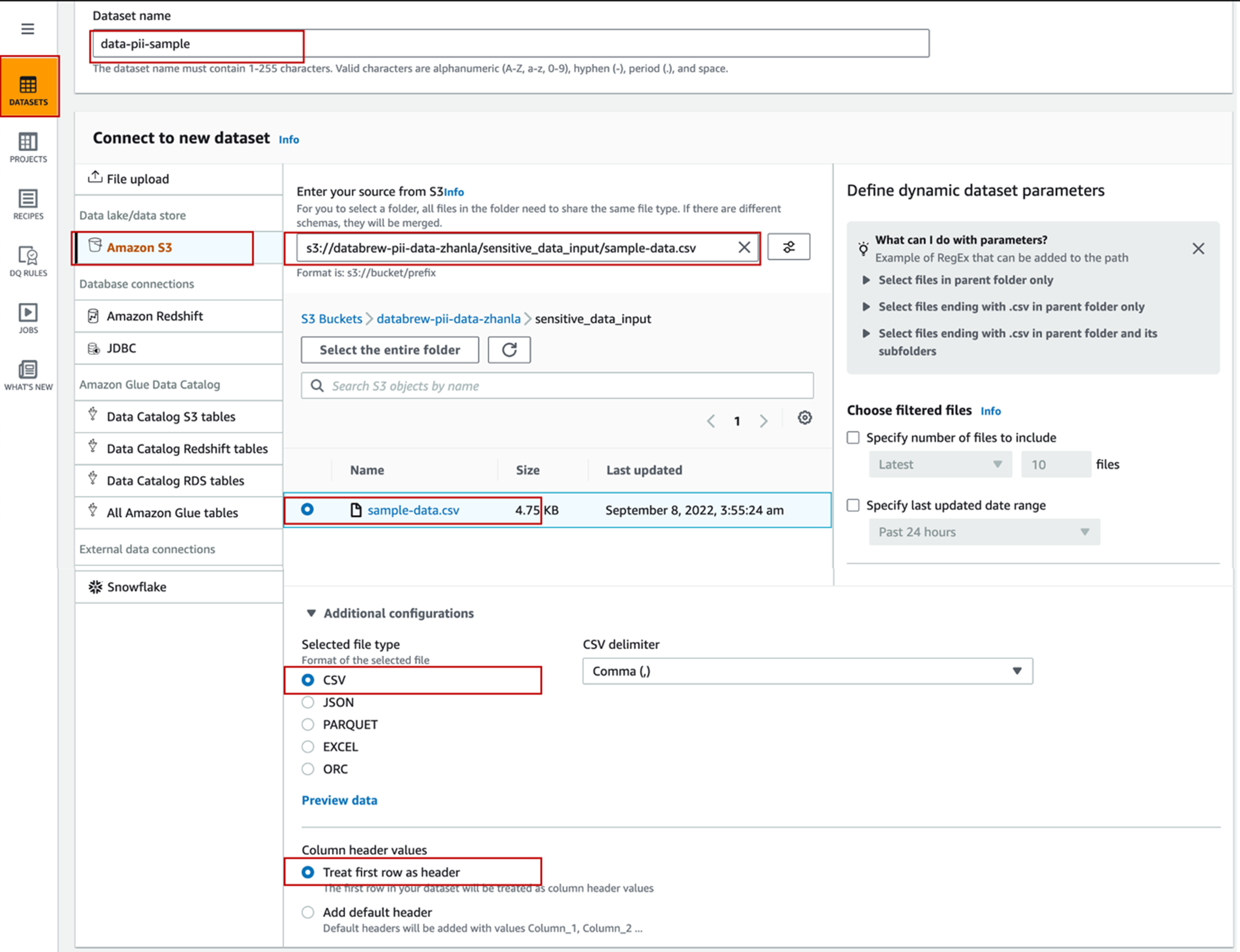
- 数据集名称 Dataset name,输入
data-pii-sample。 - 在连接到新数据集Connect to new dataset 下,选择 “Amazon S3” 作为数据源。
- 对于 S3文件的路径 Enter your source from S3,输入 “sample-data.csv” 文件的 S3 路径
s3://databrew-pii-data-zhanla/sensitive_data_input/sample-data.csv。 - 文件类型 Selected file type 选择 “CSV”。
- 列标题 Column header values 选择 “Treat first row as header”。
- 数据集名称 Dataset name,输入
 |
- 滚动到页面底部,点击【Create dataset】创建数据集。
运行源数据集的Profile Job
数据集的Profile Job可以让数据分析师了解数据集的数据形态,比如值的分布、区间、极值、平均值、有效值等,还可以帮助发现是否有PII数据。接下来我们创建并运行一个数据形态分析作业 Profile Job对数据进行分析。
- 在DataBrew左侧导航栏中,选择数据集“DATASETS”。
- 选择我们创建的数据集 “pii-sample”。
- 点击运行数据分析作业【Run data profile】,在弹出的对话框中,点击创建配置文件作业 【Create profile job】。
 |
- 在Create Job的向导页中,
-
- 在作业名称Job Name 中输入 pii-sample profile job。
- 在 Data Sample 中选择全部数据集 “Full dataset”.
- 在作业的输出设置区Job output settings 中,选择S3 的输出目录为 s3://databrew-pii-data-zhanla/profile_job_output/。
-
- 在 PII statistics中选择 “Enable PII statistics”,这样Profile Job 就会识别数据集中的PII列。注意:该选项默认是Disable的,需要手动激活。对于 PII categories, 选择 “All categories”。
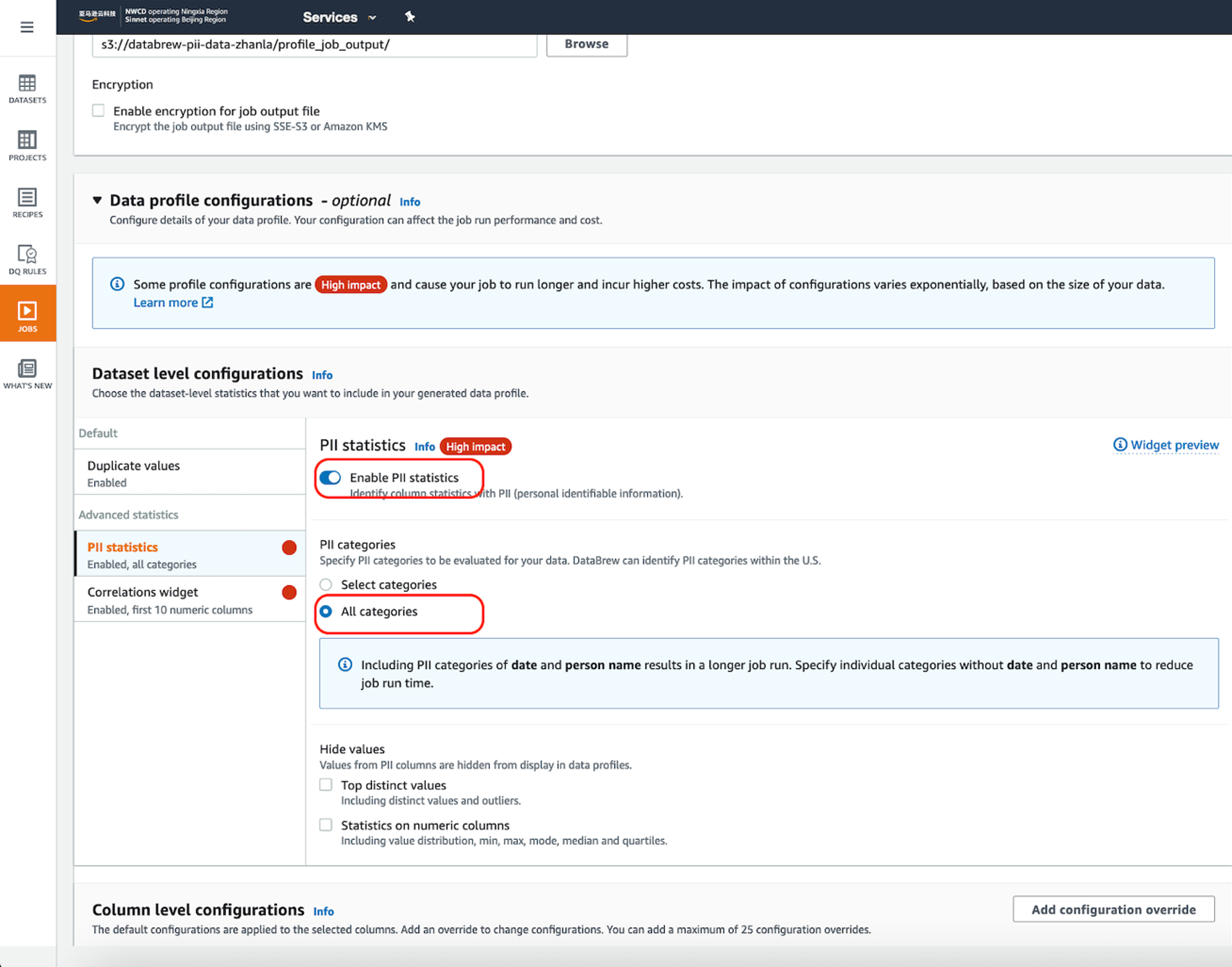 |
-
- 其他的设置保持缺省值不改变。在Permissions选项中, Role name中选择 “Create New IAM Role”, 在new IAM role suffix 中输入PII-DataBrew-Role。这样会自动创建以PII-DataBrew-Role为后缀的Glue运行角色。
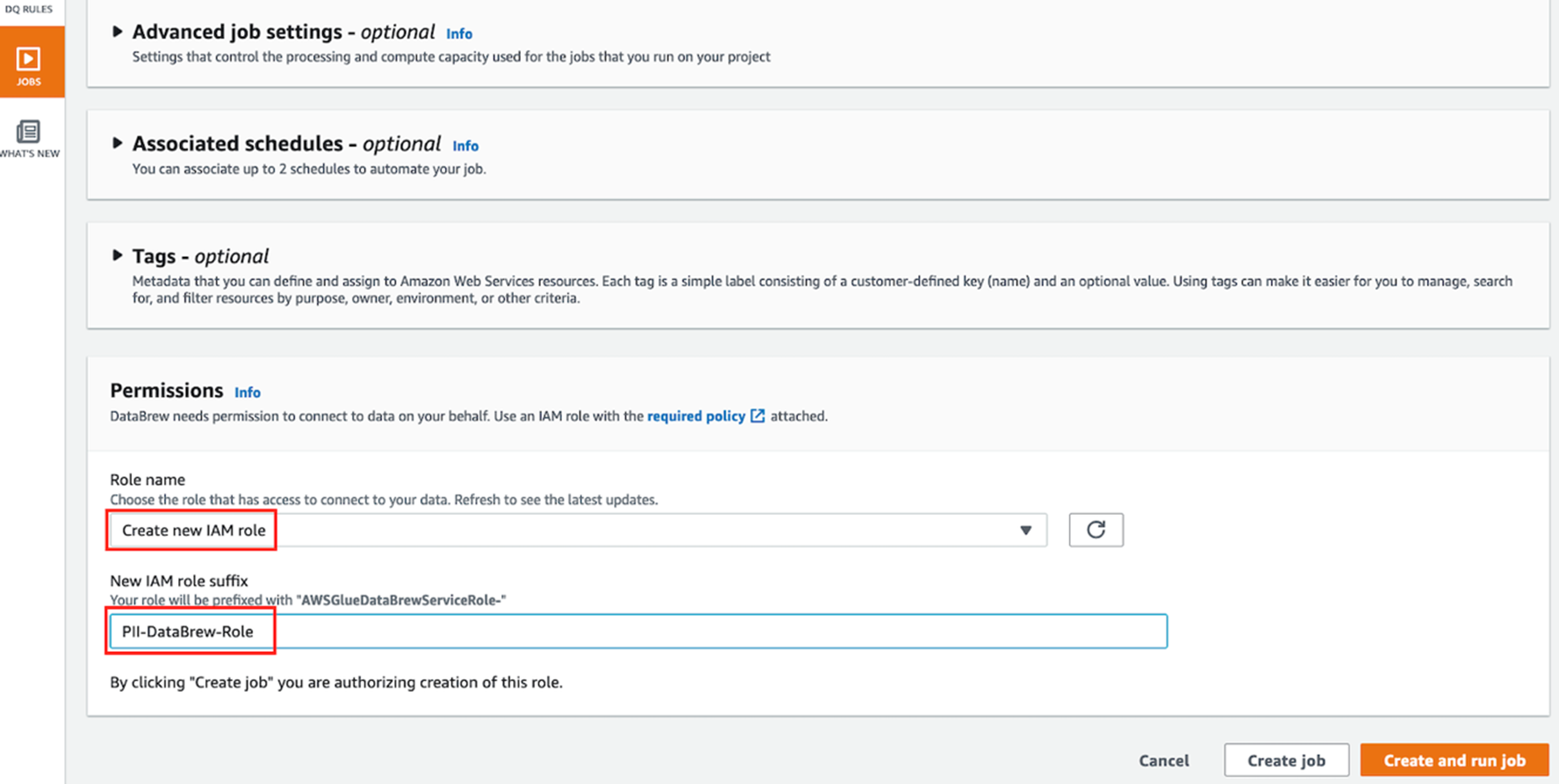 |
- 点击【Create and run job】来运行作业,等待数据分析作业Profile Job运行完毕后,可以在数据集中的 Data profile overview选项卡中来查看数据状况。PII的识别信息显示在选项卡的右面,包括已识别的 PII 列,以及这些列映射到的 PII的统计类别。
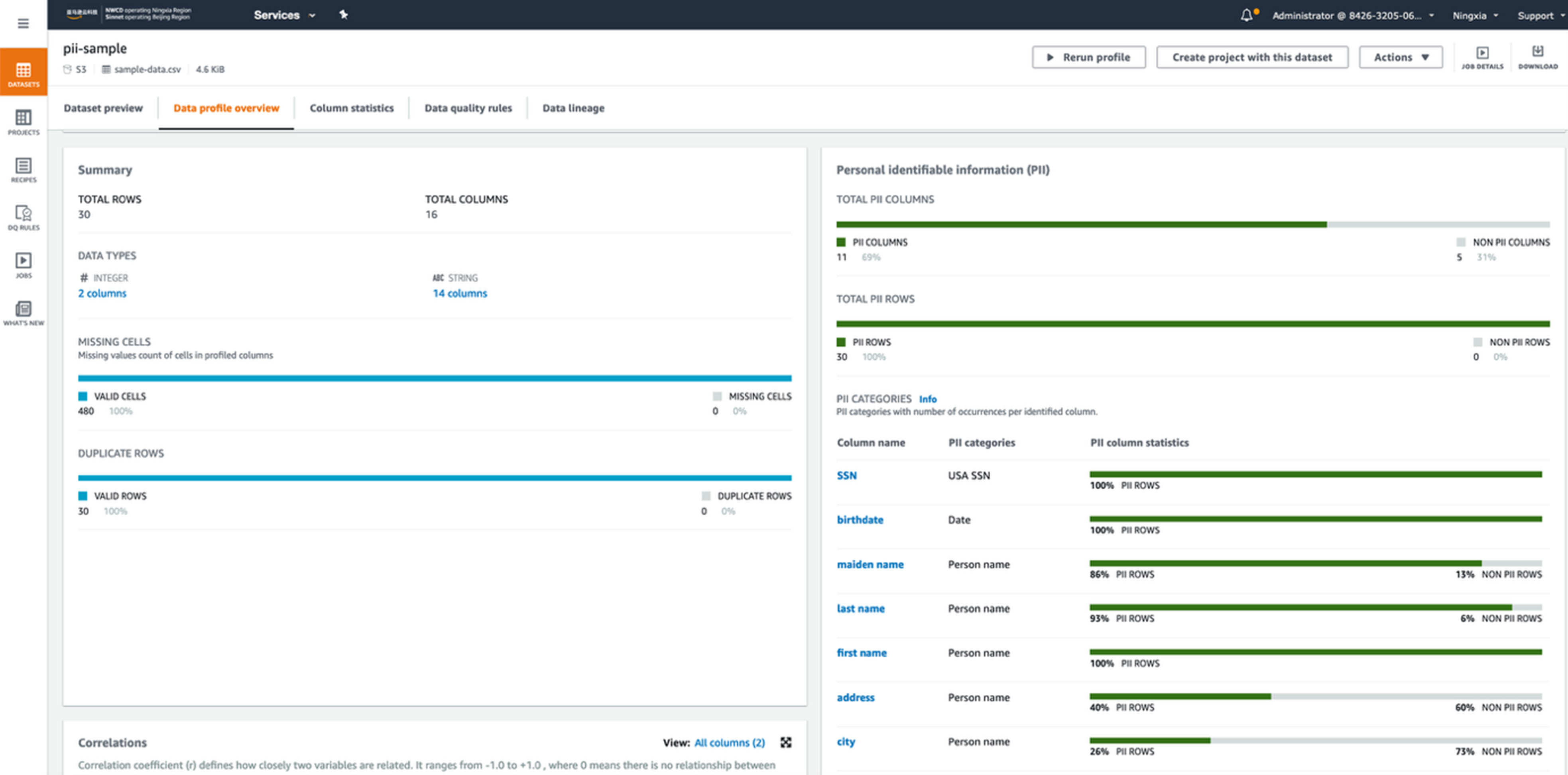 |
以上,通过运行数据集的Profile作业,对源数据Dataset进行初步的分析,识别出了存放PII的信息列,在接下的处理中,我们会对识别的PII列的数据进行加密。
加密敏感数据
在Amazon Glue DataBrew中有多种对敏感数据的处理方式, 包括屏蔽、哈希或者加密等。当下游的应用程序需要获取原始的数据时,需要采用加密的方式进行处理。Amazon Glue DataBrew提供了两种加密方式: 确定性加密(Deterministic Encryption) 和非确定性概率加密(Probabilistic Encryption)。
- 其中确定性加密(Deterministic Encryption)调用DataBrew中RECIPE的 “DETERMINISTIC_ENCRYPT” 方法加密。其原理是通过访问以Base64编码格式存储在Amazon Secrets Manager中的256位密钥 AES-GCM-SIV进行加密,加密算法使用内置的Amazon LC github 库。 采用这种方式加密后的数据只能通过Amazon Glue DataBrew中的“DETERMINISTIC_DECRYPT”方法进行解密。该方法适合加密一些不需要参与运算,却需要以确定值参与统计,并且最后还可以还原的字段。
- 非确定性概率加密(Probabilistic Encryption)调用RECIPE中的 “ENCRYPT” 方法,借助Amazon KMS服务对源列中的值进行加密。由于加密过程是调用标准的加密SDK进行加密的,因而解密过程不但可以在DataBrew内部调用“DECRYPT” 进行解密,还可以使用加解密SDK在DataBrew外部解密。该方法适合加密一些不需要参与运算,也不需要参与统计,但是在特定时刻,有特定权限的人还是可以将其还原的数据处理。
在本方案中,我们对源数据集中的PII列SSN进行非确定性加密后,在Athena中调用UDF进行解密。
创建KMS Key
在加密前,我们需要创建一个Amazon KMS Key。在Amazon KMS服务的控制台中,点击 【Create a Key】,进入创建Amazon KMS Key的向导页面:
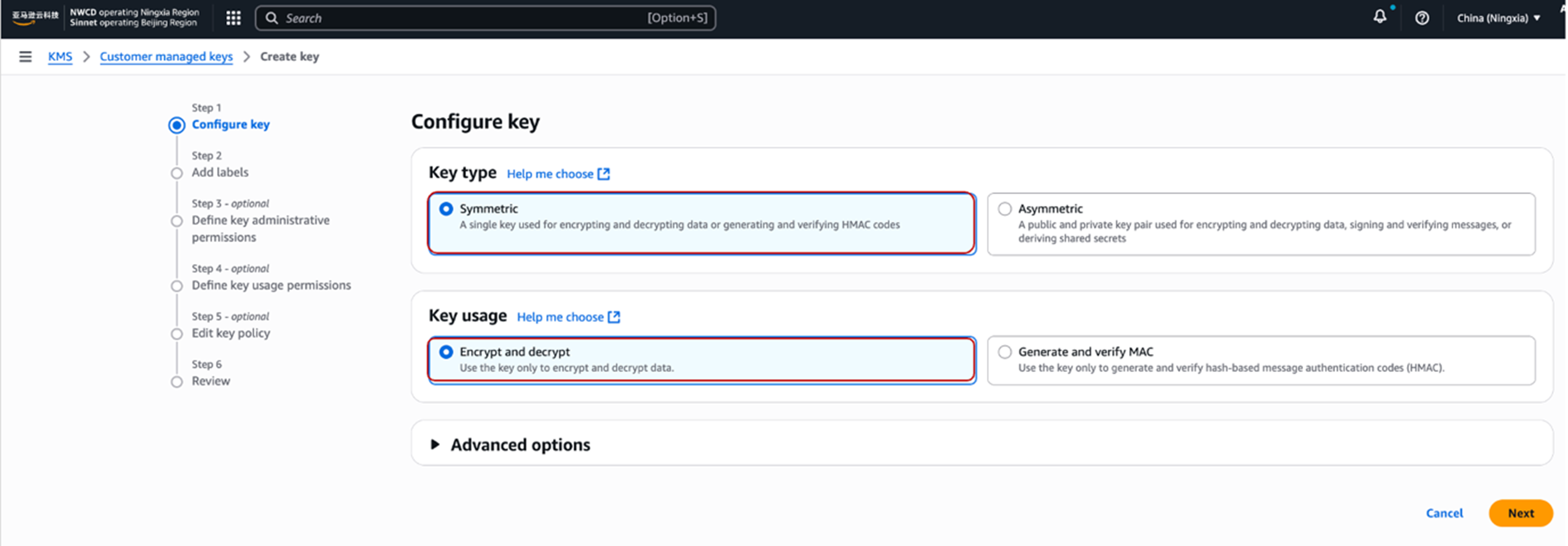
- 在第一步Configure Key 中选择Key类型为对称 “Symmetric”, Key的用途选择 “Encrypt and decrypt”。
 |
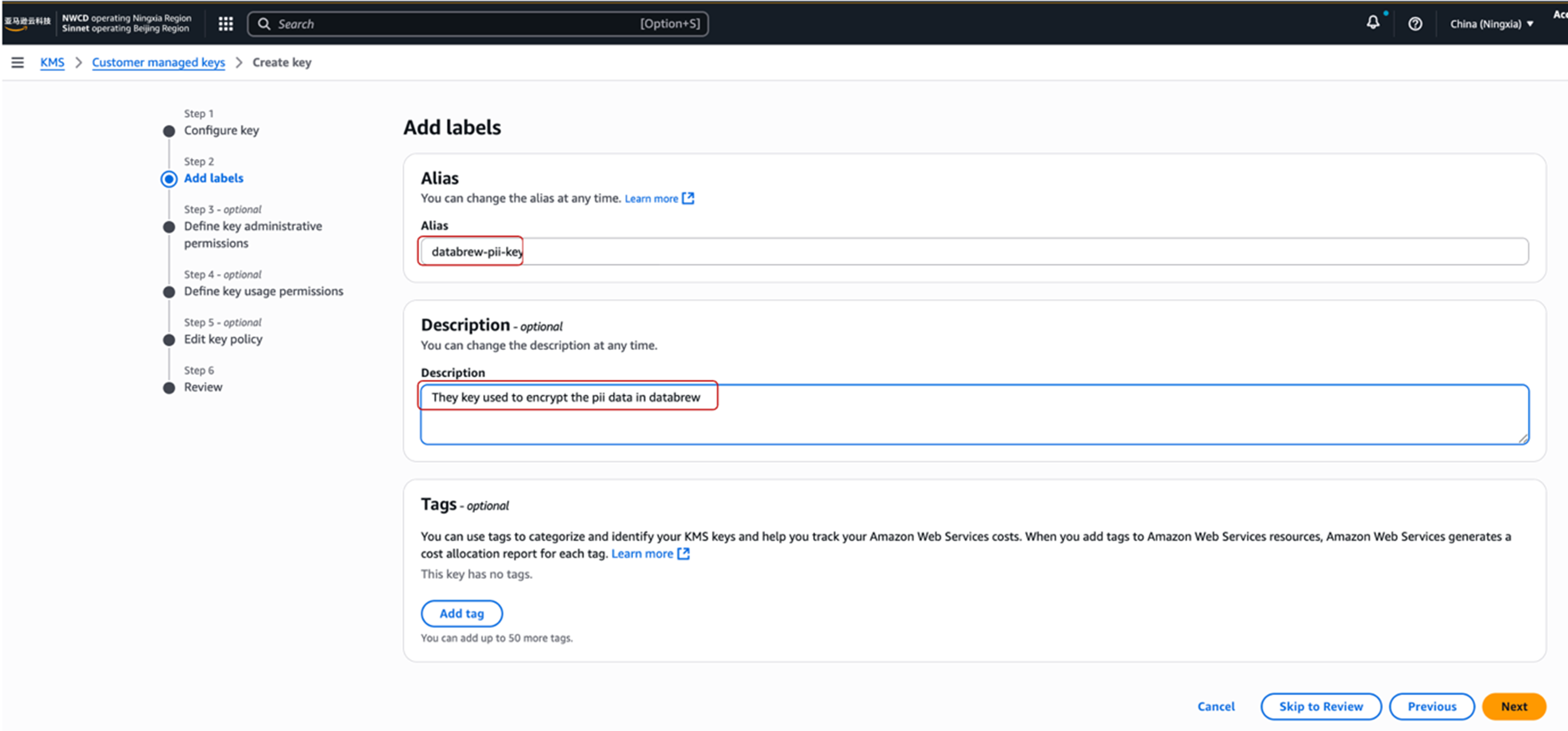
- 在第2步 Add Labels 中, 填入Key的别名:databrew-pii-key。
 |
- 在第3步选择可以管理该Key的用户或者角色。
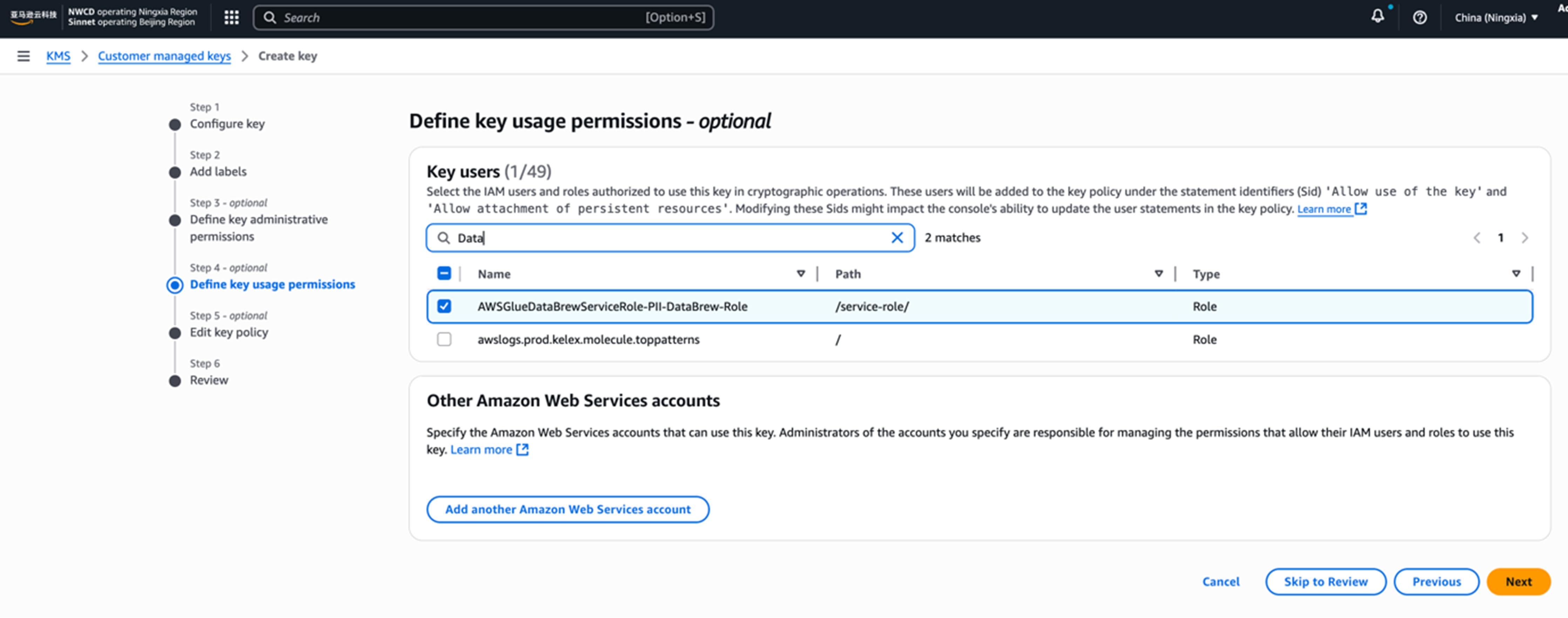
- 在第4步中需要赋权给相应的databrew中Job运行的Role,选择我们前面在创建分析Profile作业时,已经自动创建的角色:AWSGlueDataBrewServiceRole-PII-DataBrew-Role。
 |
- 完成剩余步骤,直到该Amazon KMS Key创建成功。这里可以查看Amazon KMS Key的Key Profile,需要对后面的Amazon Lambda进行授权。
创建处置方案Recipe,对敏感字段进行加密
在识别出数据集中的 PII 列,并创建了Amazon KMS Key之后,我们在 DataBrew 项目中使用敏感类的转换函数来执行加密过程。
按照如下步骤创建 DataBrew 项目:
- 在 DataBrew 控制台左侧导航栏,选择项目Projects。
- 点击创建项目【Create Project】后,在Create Project 引导页面中:
-
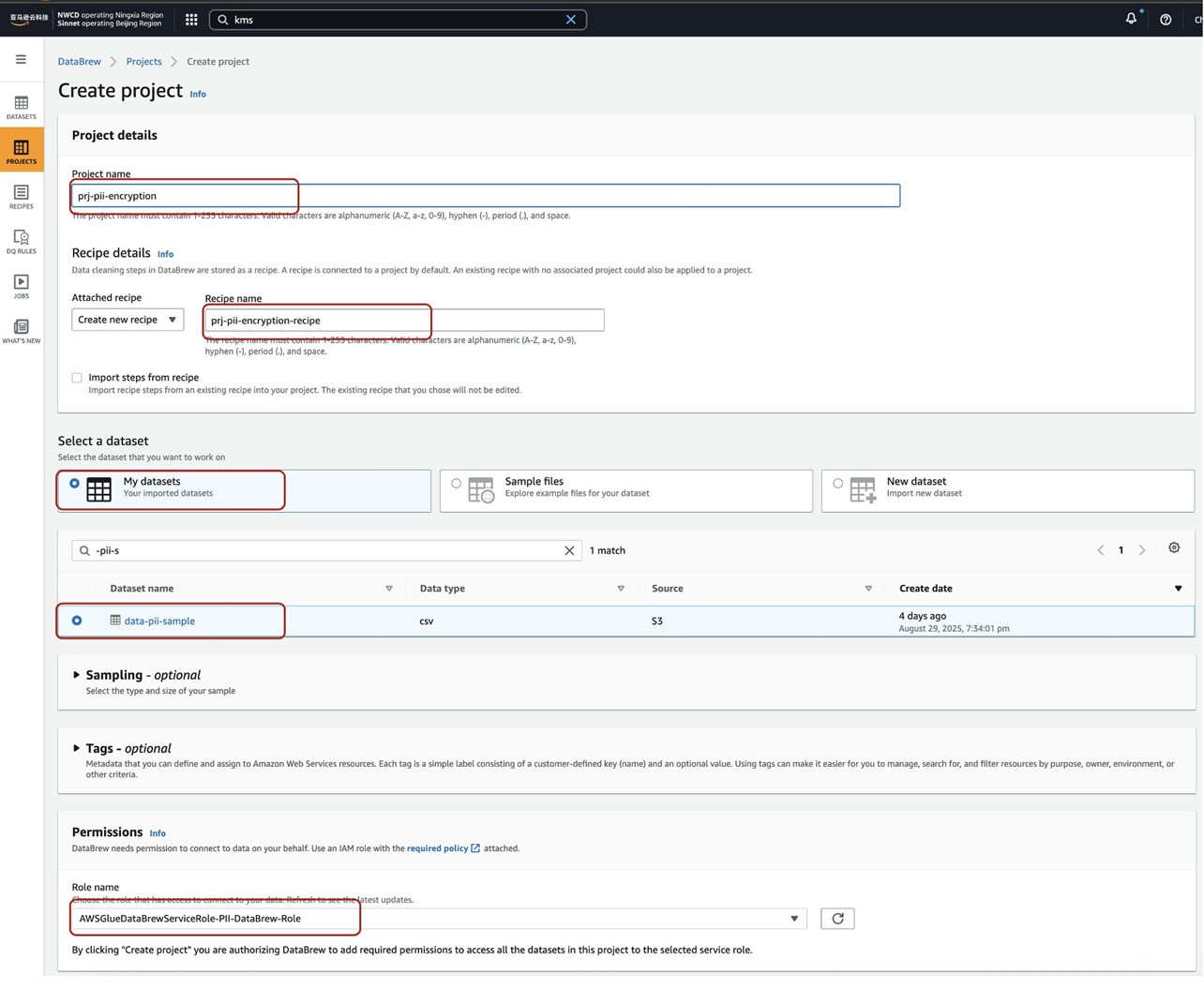
- 在项目名称Project Name,输入:prj-pii-encryption,系统会自动填充Recipe Name为:prj-pii-encryption-recipe。
- 对于选择数据集 Select a Data Set,选择我的数据集 “My DataSets”,然后,选择前面创建的数据集 “data-pii-sample”。
- 在Permissions 中选择同样的前述生成的IAM角色:AWSGlueDataBrewServiceRole-PII-DataBrew-Role。
-
- 点击创建项目【Create Project】,数据集在经过几分钟加载后,在完整的编辑器上面有一排图标。通过这些图标,可以对给定的行列进行各种编辑,包括进行加密的操作。我们这里以列SNN为例进行加密。
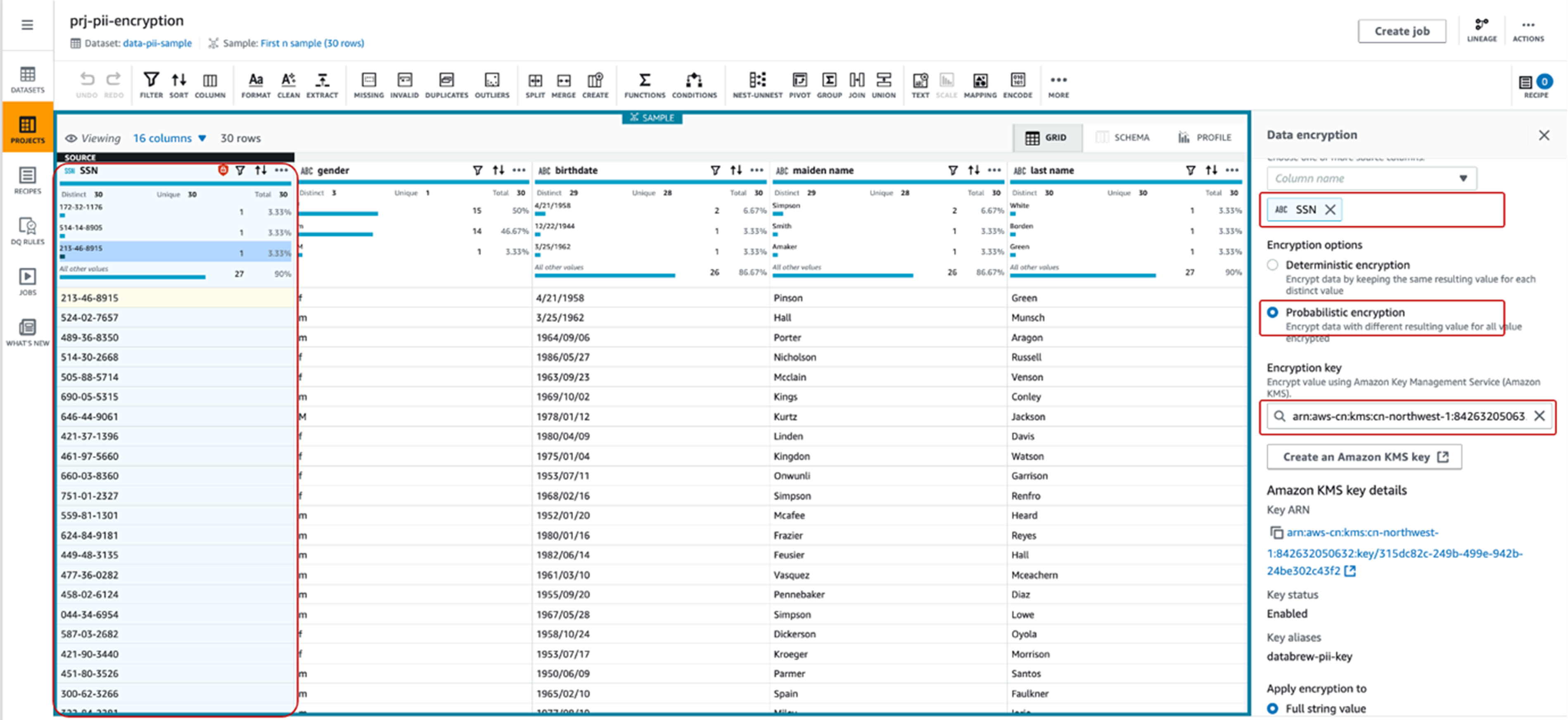
- 选中 SSN列,在菜单【MORE】→【SENSITIVE】中,选择 Encryption->Probabilistic Encryption。
- 在 Data Encryption 的具体配置向导中,确保:
-
- Source columns选择 “SSN”。
- Encryption options 选择不确定性概率加密 “Probabilistic encryption”。
- Encryption key 选择我们预先生成的Key “databrew-pii-key” 的arn: “arn:aws-cn:kms:cn-northwest-1:842632050632:key/315dc82c-249b-499e-942b-24be302c43f2” 。
- Apply encryption to 选择完整字符串值 “Full string value”。
- Apply transform to 选择 “All rows”。
-
- 点击 Apply按钮,可以看到数据已经被加密。
- 点击 【Publish】按钮发布该处置方案Recipe。
创建并运行 DataBrew 作业对数据集加密
基于我们准备好的Recipe,创建一个作业来将RECIPE中设定的数据变换逻辑应用到创建的 pii-example 数据集。
- 在 DataBrew 控制台上,选择作业 Job。
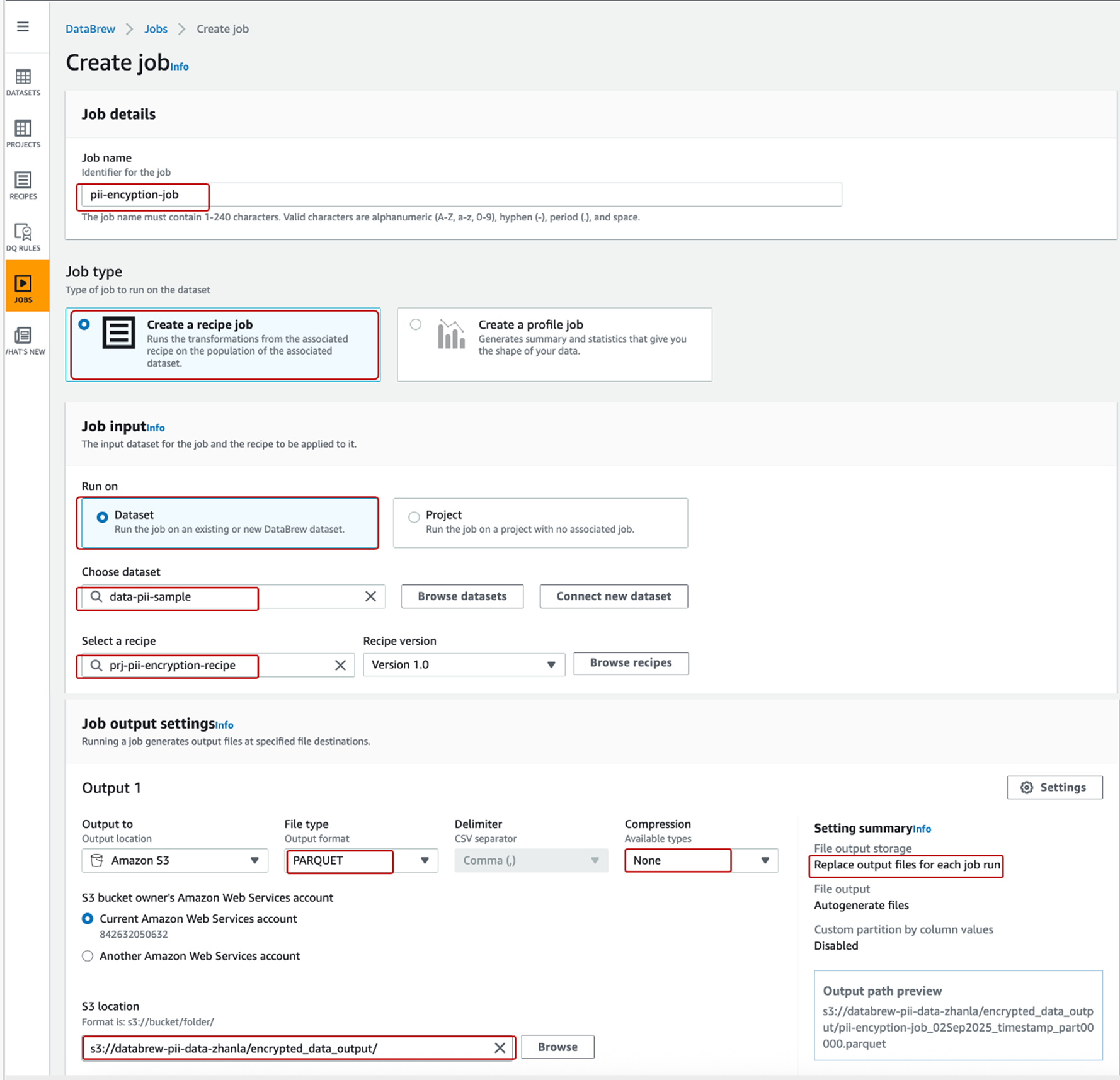
- 选择创建作业Create job。在Create Job的向导页上:
-
- 对于作业名称Job Name,输入名称: pii-encyption-job。
- Job type 选择 “Create a recipe job”。
- 在Job Input中,Run On 选择 “Dataset”,通过查询选择输入Choose dataset: pii-sample 数据集, Select a recipe 选择prj-pii-encryption-recipe 作为处置方案。
- 在文件类型的作业输出Job output settings 设置下,可以选择最终存储格式为 “Parquet”,对于压缩 Compression,选择 “None”。
- 对于 File output storage,通过点击【Settings】选择 “Replace output files for each job run”。
- 对于 S3 位置,选择 S3 输出为 s3://databrew-pii-data-zhanla/encrypted_data_output/。
- 在Permissions 中,对于角色名称 Role Name,依然选择我们之前已经创建的 IAM 角色: AWSGlueDataBrewServiceRole-PII-DataBrew-Role。
-
- 点击按钮【Create and run job】创建并运行作业 , 该作业会自动运行并对源数据集中的数据列SSN进行加密后输出到指定的S3文件夹中。
创建数据目录
通过在Athena的查询编辑器中运行如下SQL, 在Amazon Glue Data Catalog中创建相应数据库 “pii_sample_db” 以及表 “databrew_pii_sensitive_data” 和 “databrew_pii_encrypted_data” 。这两个表分别对应加密前的数据和加密后的数据。
create database pii_sample_db
--Create table databrew_pii_sensitive_data from S3 file with csv format
CREATE EXTERNAL TABLE `databrew_pii_sensitive_data`(
`SSN` string,
`gender` string,
`birthdate` string,
`maidenname` string,
`lastname` string,
`firstname` string,
`address` string,
`city` string,
`state` string,
`zip` string,
`phone` string,
`email` string,
`cc_type` string,
`CCN` string,
`cc_cvc` string,
`cc_expiredate` string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LOCATION
's3://databrew-pii-data-zhanla/sensitive_data_input/'
TBLPROPERTIES ("skip.header.line.count"="1");
--Create table databrew_pii_encrypted_data from S3 file with Parquet format
CREATE EXTERNAL TABLE `databrew_pii_encrypted_data` (
`SSN` string,
`gender` string,
`birthdate` string,
`maidenname` string,
`lastname` string,
`firstname` string,
`address` string,
`city` string,
`state` string,
`zip` int,
`phone` string,
`email` string,
`cc_type` string,
`CCN` string,
`cc_cvc` int,
`cc_expiredate` string
)
STORED AS PARQUET
LOCATION 's3://databrew-pii-data-zhanla/encrypted_data_output/'
执行如下查询可以查看到数据表 databrew_pii_encrypted_data 中列SSN为加密字段
SELECT SSN from databrew_pii_encrypted_data
该加密字段由于采用标准信封加密,所以比明文本身增添了较多的字节。
实现安全查询
这里我们会通过Amazon Lambda创建UDF,并在在Amazon Athena中调用UDF,解密表 databrew_pii_encrypted_data 中被加密的字段 SSN。
创建解密Lambda函数
基于如下java代码创建Amazon Lambda函数 “athena-udf-gluepii”。主入口函数decrypt接受两个入参,“ciphertext” 为加密后的密文字符串, “keyArn” 为Amazon KMS Key对应的arn。源代码可以访问代码库。
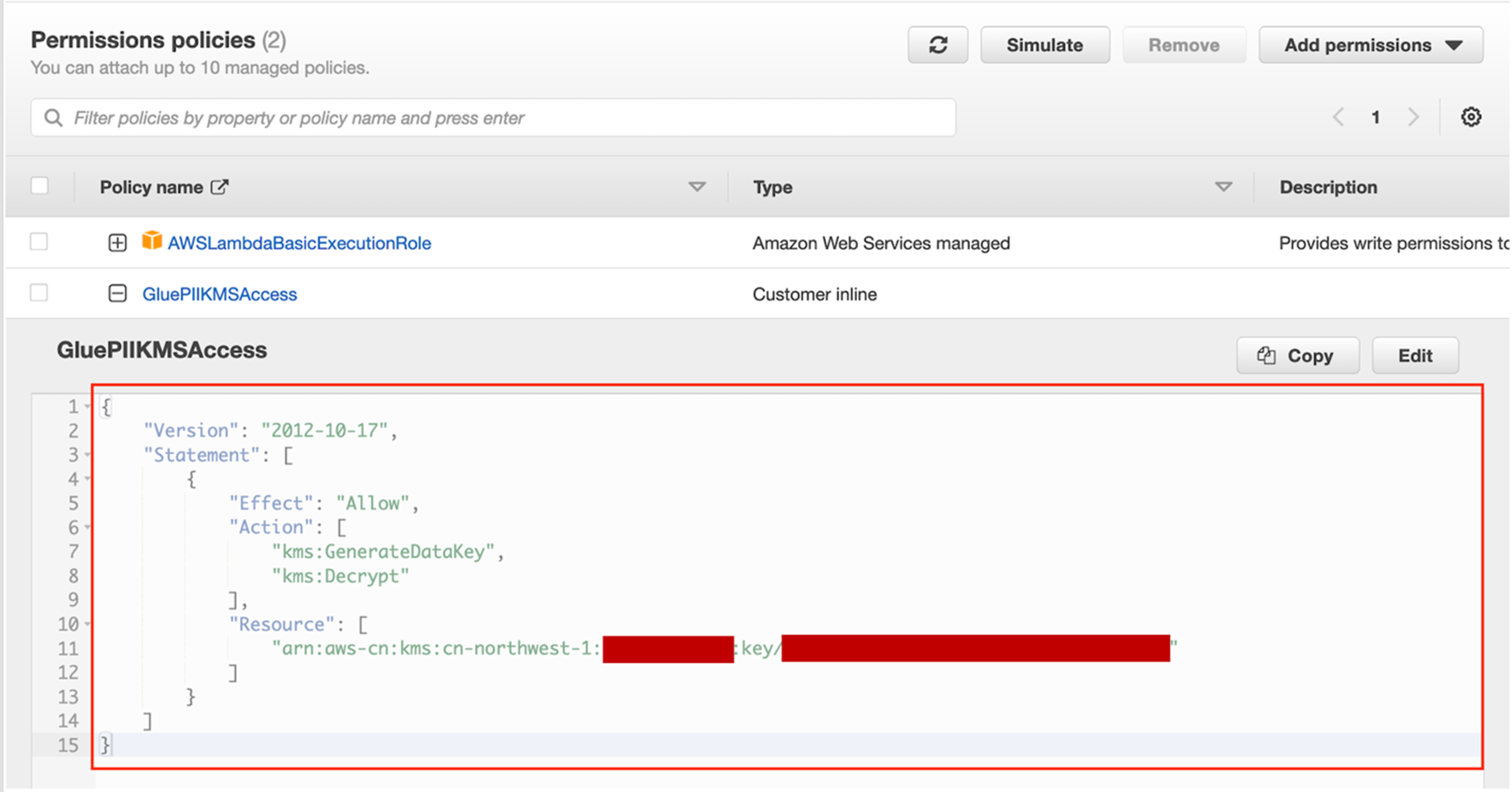
由于所创建的Amazon Lambda需要访问前面创建的Amazon KMS Key进行解密,因此需要为Amazon Lambda的运行角色Role提供访问Key的权限,用来解密:
 |
在Amazon Athena中通过UDF调用Lambda函数
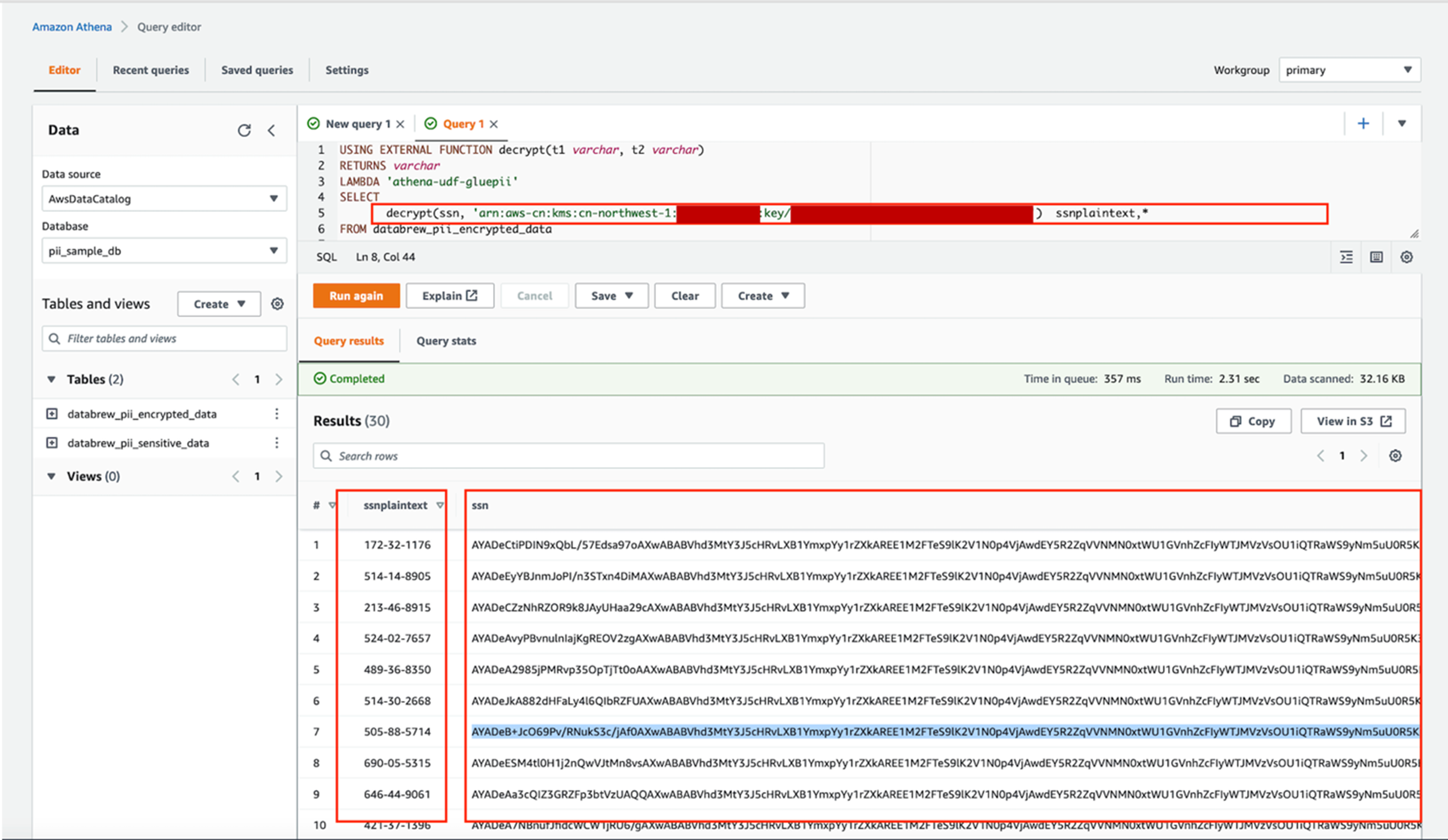
在Amazon Athena的查询窗口中,执行带有UDF的查询语句进行解密操作:
USING EXTERNAL FUNCTION decrypt(t1 varchar, t2 varchar)
RETURNS varchar
LAMBDA 'athena-udf-gluepii'
SELECT
decrypt(ssn, 'arn:aws-cn:kms:<region>:<account-id>:key/<key-id>') ssnplaintext,*
FROM databrew_pii_encrypted_data
运行结果如下图所示,密文经过UDF调用Amazon Lambda 被解密出来。
 |
比较原PII数据和解密后的数据
我们通过运行如下SQL语句来查询SSN未加密的数据以及SSN经过解密后的数据,进行对比。
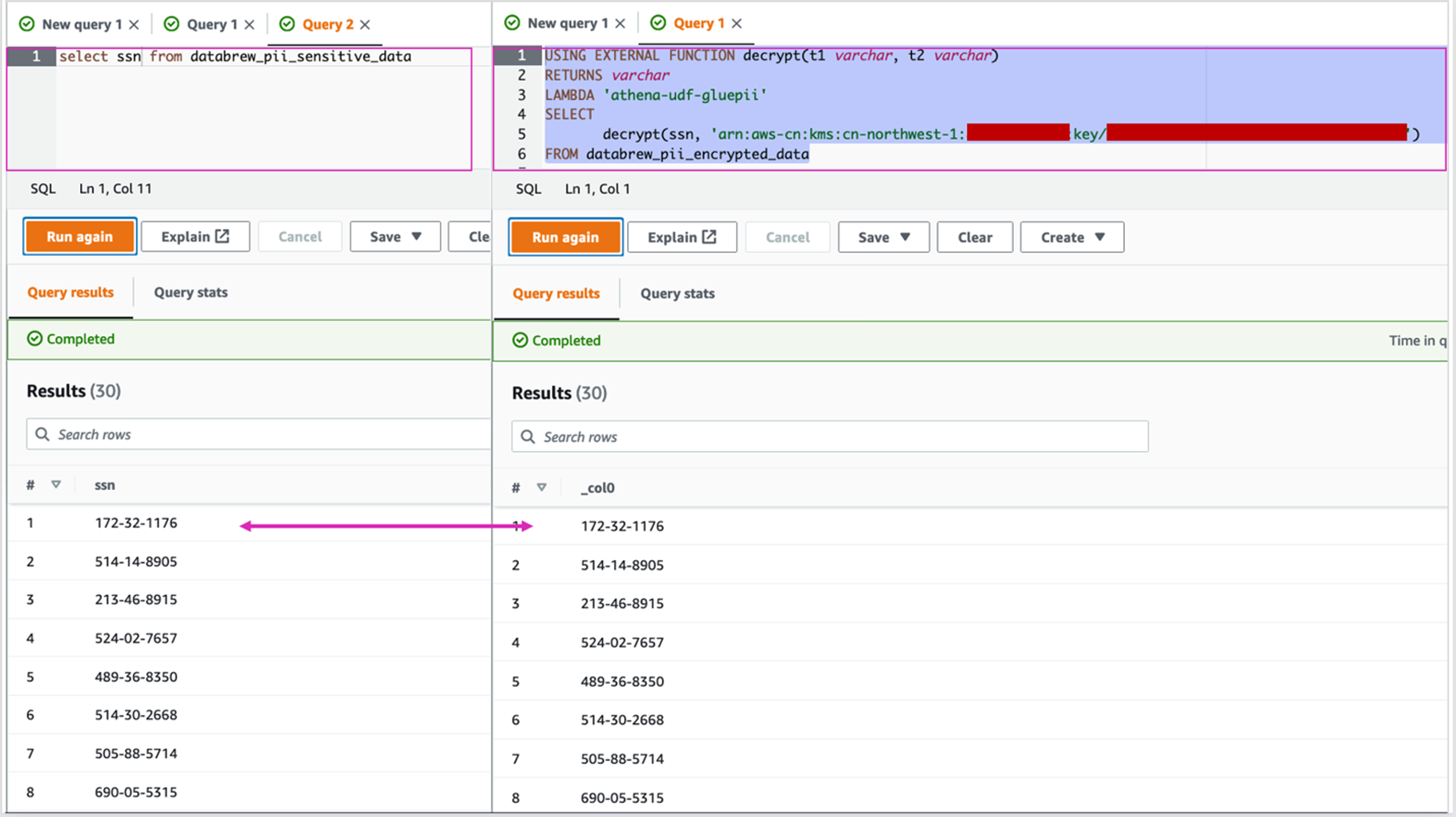 |
对比结果完全一样,可见我们成功的实现了在Amazon Glue DataBrew中加密后存储,而在Amazon Athena中运行在线查询解密的功能。
数据安全考虑
在本方案中,通过在Amazon Athena调用UDF访问KMS对加密的数据进行解密,但是,要达到数据的安全,必须对Amazon Athena, Amazon Lambda,Amazon KMS Key等的权限进行严格的授权,因此建议建立专门的Amazon KMS Key, Amazon Lambda以及Amazon Athena工作组。
- Amazon Athena 工作组授权:建立专门的Amazon Athena工作组,将该Amazon Athena 工作组授权给合适的Amazon IAM用户或者用户组。
- Amazon Athena 工作组执行角色: 为Amazon Athena 工作组明确指定执行角色, 该角色可以调用创建的Amazon Lambda,并访问相应的Amazon Glue Data Catalog和S3文件。
- Amazon Lambda的授权: Amazon Lambda可以考虑通过创建Resource-based policy statements,仅授权Athena服务调用该Lambda,防止用户直接调用Lambda。
- Amazon KMS Key的授权:Amazon KMS Key Policy只授权给Amazon Glue DataBrew运行Job的角色,以及Amazon Lambda的执行角色。
分析总结
数据合规是越来越值得重视的话题,为了合规,数据持有者必须高度重视访问控制。Amazon Glue DataBrew作为一个无服务器的可视化数据处理服务, 非常适合数据科学家、业务专家等对业务熟悉但对底层技术研究不深的用户快速搭建一套弹性的数据处理流水线,把更多的精力放在业务上。Amazon Glue DataBrew 引入了 PII 数据处理转换,使用户能够对敏感应用数据进行屏蔽、加密、解密和其他操作,进一步增强了安全性。对于Amazon Glue DataBrew中的两种加密方法的比较如下表所示,无论是哪种加密方式,相对于原始的明文,明显需要更大的存储空间。
| 比较点 | 确定性加密
Deterministic Encryption |
不确定性概率加密
Probabilistic Encryption |
| 加密Key | 以Base64方式存储于Amazon Secrets Manager 中的256位密钥。 | 存储于Amazon KMS中的对称密钥。 |
| 加密方式 | 访问Amazon Secrets Manager获得密钥,调用 Amazon Web Service libcrypto加密库进行加密。 | 通过Amazon KMS Key对密钥进行加密,完成最终数据的标准信封加密。 |
| 解密方式 | 只能在Amazon Glue DataBrew中进行相应的解密。 | 可以在Amazon Glue DataBrew中进行解密,也可以在外部的其他服务中调用SDK进行解密。 例如Amazon Athena中通过UDF调用Amazon Lambda进行解密。 |
| 安全性 | 通过指定密钥和给定算法进行加减密,安全性较低。 | Key不离开Amazon KMS服务,采用信封加密,安全性显著更高。 |
| 密钥轮转 | 如果要对Amazon Secrets Manager中的密钥进行轮转,需要注意如下的几个问题:
1. 密钥的轮转需要保证轮转后的Base64编码满足256位密钥要求。 2. 加密后的密文不包含Secret值的版本信息, 版本关联信息仅存储在DataBrew RECIPE转换脚本中。 3. 当原加密密钥在轮转后不再是AWSCURRENT版本时,必须在解密操作中显式指定正确的密钥版本进行解密。 4. 轮转后的旧密钥如未添加自定义标签(Label)将被系统自动回收, 为确保数据可持续解密,必须为需要保留的旧版本密钥添加自定义标签。 |
密文中会存放Key的版本信息,因而 1. Amazon KMS本身Key的轮转,不会影响解密。
|
| 密文确定性 | 使用固定参数的加密算法, 相同明文的加密结果相同。 | 使用随机初始化向量(IV), 相同明文对应的密文每次不同。 |
| 密文长度 | 密文较长。 | 密文非常长,原因是用了标准的信封加密。 |
| 加密后分析 | 虽然对明文进行了加密,但是仍然可以进行数据量的聚合统计计算等。 | 虽然加密在一定条件下可以解密,但是加密后的文本无法直接进行聚合统计。 |
| 适用场景 | 适用于一般的对个人数据等敏感数据的加密,既可以保护个人数据,又不影响整体分析。例如欧盟GDPR (General Data Protection Regulation)。 | 适用于针对国家安全的敏感信息(包括个人信息)处理,例如E.O.14117,防止接收方通过数据统计分析进一步获得信息。 |
本文中,我们通过对Amazon Glue DataBrew中对敏感数据的相关加密功能做了介绍,并通过在Athena 中调用UDF对Amazon Glue DataBrew中加密的字段进行在线解密,保证了数据安全的同时,提升了数据使用的便捷性。通过Amazon Athena 和Amazon Lambda的最小授权,可以控制用户对UDF/ Amazon Lambda的调用,进而控制用户解密的权限。该方法不但可以部署在亚马逊云科技的中国区,还可以部署在全球区域。
除了本文中所示例的加密和解密方法,对于数据湖中的加密数据,还可以结合其他的安全进行权限管控,例如:
- 如果在本组织内使用数据,可以将数据存储到KMS加密的S3中提高安全性,同时在通过Amazon Glue DataBrew进行数据准备时,在创建加密字段的同时,还可以保留明文字段,并结合Amazon Lake Formation更加精细的权限控制,来控制数据的访问。
- 在数据需要显式传输的情况下,对于密文数据来说,可以在加密数据发送给数据接收方后,通过控制KMS的跨账号访问权限,来控制对方是否可以获得明文解密数据。
参考文档
Introducing PII data identification and handling using AWS Glue DataBrew
Build a data pipeline to automatically discover and mask PII data with AWS Glue DataBrew
Identifying and remediating PII data in AWS Glue
https://www.linkedin.com/pulse/identifying-remediating-pii-data-aws-glue-tom-reid
PII Recipe Steps
https://docs.aws.amazon.com/databrew/latest/dg/recipe-actions.ENCRYPT.html
What is the AWS Encryption SDK?
https://docs.aws.amazon.com/encryption-sdk/latest/developer-guide/introduction.html
使用 Amazon Glue DataBrew 对数据进行预处理
https://aws.amazon.com/cn/blogs/china/preprocess-the-data-with-amazon-glue-databrew/
Use IAM policies to control workgroup access
https://docs.aws.amazon.com/athena/latest/ug/workgroups-iam-policy.html
Allow access to Athena UDFs: Example policies
https://docs.aws.amazon.com/athena/latest/ug/udf-iam-access.html
Viewing resource-based IAM policies in Lambda
https://docs.aws.amazon.com/lambda/latest/dg/access-control-resource-based.html