亚马逊AWS官方博客
如何利用亚马逊云科技的原生服务提升SAP HANA集群监控中的可观测性
什么是可观测性?
控制理论中的可观察性(observability)是指系统可以由其外部输出推断其其内部状态的程度。系统的可观察性和可控制性是数学上对偶的概念。可观察性最早是匈牙利裔工程师鲁道夫·卡尔曼针对线性动态系统提出的概念。若以信号流图来看,若所有的内部状态都可以输出到输出信号,此系统即有可观察性。
对于IT系统而言,我们如何从系统的输出来推断其内部实际状态?很多年前人们就在利用各种监控手段。例如早期的随着Unix系统而来的vmstat,syslog和netstat等监控工具。其中涉及了两个问题。第一,是什么坏了,第二,为什么坏了? 这就要求监控系统能帮助我们做到,识别出问题,并且能找到问题原因。
对于SAP这样的关键业务应用,客户往往非常关注其RPO(恢复时间点目标)和RTO(恢复时间)指标。由于过去有超过5000家既有SAP企业客户的积累,亚马逊云科技总结了SAP跨可用区的高可用的最佳实践(参考这里),为企业客户SAP应用的可靠性和可用性提供了架构保障。运用跨可用区高可用的架构,在发生可用区级别的故障时,能够自动进行应用恢复。从系统运用维护的角度而言,感知SAP ERP/HANA服务以及相关指标的状态且及时获得指标异常的通知,对于预知并干预可能产生的风险,或在发生故障时更及时的解决故障,即减小平均修复时间MTTR(mean time to repair),有非常重要的意义。
但是,目前还有不少SAP用户,在基础架构层面会使用如Zabbix/Prometheus/Grafana等监控平台,但是在SAP应用层面,还是依赖于SAP Basis顾问使用SAP应用侧中的功能进行较为传统的监控和日常检查,核心指标的监控和通知功能分散于不同的平台或归属不同的组织架构体系,对整体系统的观察能力有待提升,发生问题时也较难在第一时间得到有效的体系化数据支撑,更多依赖运维人员的经验处理问题。当然,SAP用户也可以引入SAP相关生态产品如 SAP Solution Manager Focus Run 或第三方工具如SAP HANA® plugin for Grafana,Avantra等。
但系统监控不等于对系统的观察能力。那如何提高系统的可观察性?
对系统的观察能力,集中在三个技术方面。第一是logging日志记录,第二是metrics度量,第三是tracing跟踪。
日志是反映系统真实情况的源头,您监视和移植的度量标准应该来自您的日志。这三个技术都很重要,但是用途不同。但是我们认为日志记录是最基础的重要又是必须的技术手段。Logging every thing. 用日志记录所有事情,日志是对一切数字世界中发生了什么的洞察能力的源头。通过长期的日志系统的实践和积累的经验,我们建立了CloudWatch log的服务,通过它,你可以查看应用程序的日志。可以在日志中搜索特定的错误码,根据不同的领域进行筛选,或者针对不同的情况创建警报。当然,利用Amazon CloudWatch的metrics和dashboard,我们可以非常方便的将收集到的指标汇总和呈现出来。
今天以SAP HANA的集群为例,讨论如何利用亚马逊云科技的原生云服务构建一个端到端的可观测性系统。对于一个完整的SAP HANA集群,为了更直观的了解到SAP HANA的状态,哪些指标需要被纳入监控体系中来呢?
| SAP HANA指标类 | SAP HANA指标项 | 获取方法 | 主机脚本/SQL等 |
| 主机层信息 | CPU占用率 | CloudWatch原生指标 | N/A |
| 内存占用率 | EventBridge+Cloudwatch自定义指标 | free -m | |
| 磁盘空间占用率 | df -hP | ||
| Pacemaker集群和资源状态信息 | EC2 Stonith | EventBridge+Cloudwatch自定义指标 | crm_mon -1 |
| Overlay IP | |||
| SAP HANA CloneSet | |||
| SAP HANA服务状态信息 | indexserver | EventBridge+Cloudwatch自定义指标 | sapcontrol -nr $sysumber -function GetProcessList |
| daemon | |||
| compileserver | |||
| nameserver | |||
| preprocessor | |||
| xsengine | |||
| replication状态 | hdbcons -e hdbindexserver “replication info” | ||
| SAP HANA平台信息 | HANA alerts | Lambda(HDB Client)+Cloudwatch自定义指标 | _SYS_STATISTICS.STATISTICS_ALERTS_BASE |
| HANA crash dumps | hdbcons [-p <pid>] “runtimedump dump” | ||
| 备份历史 | Monitoring View: M_BACKUP_CATALOG | ||
| diagnosis files(log and trace files) | CloudWatch logs | /usr/sap/<SID>/HDB<instance>/<host>/trace |
表一:SAP HANA监控指标分类及指标数据获取方法
如上表所示,有四个层面的指标内容需要被纳入进来,第一个层面是承载SAP HANA的主机层面的基础架构信息,包括CPU,内存,磁盘空间的利用率等,第二个层面涉及到和SAP HANA集群状态相关的指标信息,包括集群中Stonith,Overlay IP,CloneSet 的状态以及 pacemaker 的日志,第三个层面涉及SAP HANA服务状态和核心的参数指标,包括nameserver, indexserver, xsengine 以及SAP HANA replication状态等。除此以外,第四个部分还可以将SAP HANA层面的如告警、HANA备份历史、诊断文件等内容纳入进来。
从获取信息的方法而言,一部分内容可以直接从默认的EC2的CloudWatch指标获取,如CPU占用率,网络吞吐等;一部分应用程序的日志可以通过CloudWatch log获得,一部分HANA层面的信息需要用Amazon Lambda使用HANA client执行对应的SQL脚本获得(参考这里),除此以外,绝大多数的内容,使用Amazon EventBridge (Amazon CloudWatch rule)调用SSM document(每分钟一次),SSM 在相应的节点上运行脚本从而得到对应的指标结果并反馈到Amazon CloudWatch,通过Amazon CloudWatch 的自定义控制面板能够得到预配置的图表集合,展现SAP HANA及集群状态的多维度信息,且不会产生额外的软件授权费用。
需要特别指出的是,现在我们已经可以使用CloudWatch Application Insights 来为 SAP HANA 数据库设置监控。相关步骤可参考这里。需要注意是CloudWatch Application Insights支持操作系统的版本。下文介绍的是更为通用的方法,也可以扩展到SAP S/4 HANA等应用层的监控。
下文以云上SAP HANA跨可用区架构为例,讲解如何使用Amazon EventBridge 和Amazon CloudWatch 的自定义指标监控SAP HANA及其集群状态,架构图如下所示:
 图一:Publish CloudWatch custom metrics
图一:Publish CloudWatch custom metrics
下文将展示如何使用Amazon EventBridge 执行脚本并将相应指标推送到CloudWatch等自定义指标中,再通过Amazon CloudWatch 控制面板进行展现,同时配置对应的Amazon CloudWatch Alert推送到对应的SNS Topic中。
前提条件和准备:
部署:
可以将对应的Amazon CloudFormation模版上传至S3目录,一键生成相应的资源。
这里分步骤演示不同的Cloudformation模版的功能。(参考这里)
步骤1:创建IAM角色:
iamroles.yaml sample:
系统将创建SSMDocumentRole和EventRole两个IAM角色。
步骤2:创建Amazon EventBridge规则:
hanaclustermon.yaml 范例:
系统会创建Event Rule和SSM Document资源
 图二: Amazon EventBridge规则
图二: Amazon EventBridge规则
步骤3:使用已创建的自定义指标创建Amazon Cloud Watch控制面板:
将如下脚本中的变量替换成实际SAP HANA主机的instance id即可。
hanacluster_cloudwatch.yaml sample:
创建好的Amazon CloudWatch 中的控制面板如图所示(范例):
 图三: Amazon CloudWatch自定义控制面板
图三: Amazon CloudWatch自定义控制面板
可根据具体的需求在控制台进行拖拽,从而调整控制面板中图表的布局,或修改对应的自定义面板的json文件。
步骤4:创建CloudWatch警报
以HANA的nameserver服务为例创建Amazon CloudWatch警报(在创建CloudWatch警报之前,建议先创建SNS主题并确认订阅成功)

图四:创建CloudWatch警报的指标
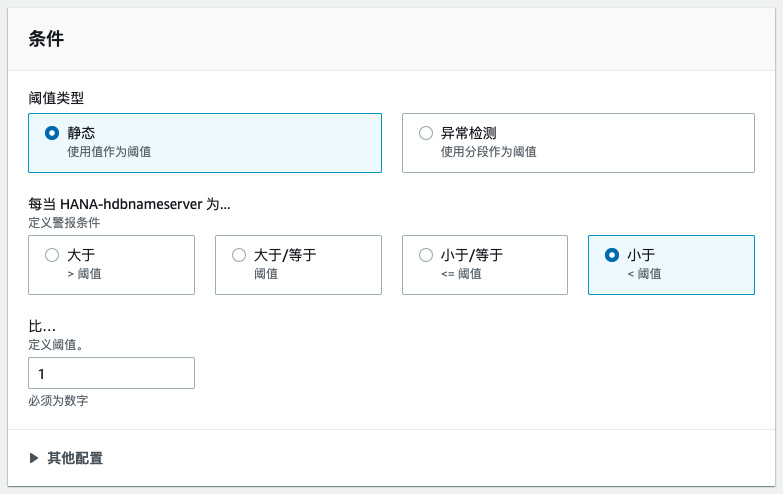
图五:创建CloudWatch警报的条件

图六:创建CloudWatch警报的通知目标
总结:
对于SAP ERP/HANA这样的承载企业核心关键的应用,从基础架构层,到高可用架构,再到应用层,有纷繁复杂的各种指标,能够至下而上的实时监控和感知并提前干预且对于应用的可用性和可靠性有重大意义。通过使用Amazon EventBridge结合Amazon CloudWatch的自定义指标,能够按需获取离散在不同层面的各种关键参数指标,并在自定义面板进行统一展示,利用Amazon CloudWatch的警报功能能够及时的将指标的异常通知相关人员,相较于传统的依赖人工的日常检查作业无疑更为敏捷和便利。
注: 本环境在SLES 12sp4和HANA2.0 SPS05测试通过,在考虑版本的兼容性问题时,注意获取参数的命令行在不同操作系统的差异。
参考资料:
http://zh.wikipedia.org/wiki/%E5%8F%AF%E8%A7%80%E6%B8%AC%E6%80%A7
https://docs.amazonaws.cn/eventbridge/latest/userguide/eb-create-rule-schedule.html
Kalman R. E., “On the General Theory of Control Systems”, Proc. 1st Int. Cong. of IFAC, Moscow 1960 1481, Butterworth, London 1961.