亚马逊AWS官方博客
使用运行在 Amazon EC2 G4 实例上的 Amazon EMR,提升 RAPIDS XGBoost 性能并降低运营成本
本文为英伟达集团解决方案架构师Kong Zhao撰写的特约文章。
本文分享了英伟达集团如何使用Amazon EMR运行Amazon Elastic Compute Cloud (Amazon EC2) G4实例,借此实现4.5倍性能提升并将成本降低至此前的约18.5%。
梯度提升是一种强大的机器学习(ML)算法,能够在回归分析、分类以及排名等任务场景下实现最理想的准确率水平。事实上,深度神经网络与梯度提升已经成为解决此类问题的两大首选技术方案。
目前,来自各个行业的数据科学家们都在使用开源XGBoost库:
- 金融服务——预测贷款绩效与其他金融风险。
- 零售——预测客户流失率。
- 广告宣传——预测点击率。
Amazon EMR与英伟达GPU实例
Amazon EMR为行业领先的云大数据平台,可通过Apache Spark、Apache Hive、Apache HBase、Apache Flink、Apahce Hudi以及Presto等多种开源工具处理海量数据。在Amazon EMR的加持下,您能够以不足传统本地解决方案一半的运营成本执行PB级数据分析,并获得超过标准Apache Spark三倍以上的性能表现。数据科学家正广泛使用Amazon EMR运行各类开源深度学习与机器学习工具(包括TensorFlow与Apache MXNet),以及各类专用型工具与库。只需数次单击,大家即可在Amazon EMR控制台中使用最新GPU实例快速创建安全性极高的可扩展集群,并在其上运行多种分布式机器学习训练。
关于Amazon EMR的更多入门使用信息,请参阅Amazon EMR是什么?
Amazon EMR上的G4实例
Amazon EMR一直在不断升级可用GPU实例选项,并与英伟达等伙伴合作改善平台性能。我们的最新成果为配备英伟达T4 Tensor Core GPU的EC2 G4实例类型,该GPU具备16 GB GPU内存,采用Nitro虚拟机管理程序,每节点包含1至4个GPU。该实例还提供高达1.8 TB的本地非易失性内存标准(NVMe)存储,以及高达100 Gbps的网络传输带宽。
英伟达的T4 Tensor Core GPU产品是一种经济高效的通用型GPU实例,可用于加速机器学习模型的训练与推理、视频转码以及其他计算密集型工作负载。G4实例包含多种具体实例大小,您可以选择单一GPU配置,或者采用具有不同vCPU与内存容量的多GPU类型,更灵活地为应用程序选择适合的实例大小。
英伟达将加速XGBoost开源库与Apache Spark加以集成
尽管大规模机器学习能够为数百万用户提供强大的预测功能,但在实现预期效果之前,我们首先需要克服基础设施中的两大关键挑战,从而节约成本并更快交付结果:加快大量数据的预处理速度,以及加速计算密集型模型的训练流程。
为了应对这些挑战,英伟达正在孵化RAPIDS,即一组开源软件库的集合。RAPIDS团队还与分布式机器学习公约(DMLC)XGBoost组织紧密合作,以获取上游代码并保证GPU中的所有组件均可顺畅匹配分析生态系统的开发成果。我们还使用了XGBoost4J-Spark开源库,该库可以在各Apache Spark节点之间执行XGBoost模型的训练与推理。使用GPU,您可以通过列式处理代替最初针对CPU计算单元设计的传统行式读取,进而充分利用数据并行优势,借此节约成本并提高性能表现。
通过GPU实例实现Amazon EMR的高性能与低成本目标
我们在运行有Apache Spark的EC2 G4实例上,通过EMR集群对最新的RAPIDS-Spark XGBoost4j开源库进行了基准测试。我们直接在Amazon Simple Storage Service (Amazon S3)上使用大小为1 TB的Criteo开源数据集执行基准测试。Criteo主要用于预测广告展示内容的点击率情况。这里使用Amazon S3充当数据存储方案。
下图所示,为我们在训练时间与训练成本方面的改进结果。

相较于使用EC2 R5内存优化型实例,运行G4dn实例上的EMR集群成本仅为前者的约18.5%,性能却提升达4.5倍。与EC2 P3实例相比,采用G4dn GPU实例的EMR集群虽然在训练时间方面与前者基本持平,但训练成本却降低了一半。下表为此次基准测试的结果汇总。
| 类型 | 实例数量 | 每实例硬件配置 | 实例类型 | Amazon EC2每小时使用成本 | Amzon EMR每小时使用成本 | 训练时长(分钟) | 训练成本 |
| GPU | 16 | 4x T4 | g4dn.12xlarge | 3.912美元 | 0.27美元 | 6 | 6.69美元 |
| GPU | 6 | 8 x V100 | p3.16xlarge | 24.48美元 | 0.27美元 | 5 | 12.38美元 |
| CPU | 16 | 64 vCPU | r5a.16xlarge | 4.608美元 | 0.27美元 | 33 | 42.93美元 |
解决方案概述
大家可以使用以下分步演练,在EMR GPU集群上使用开源XGBoost库运行示例贷款数据集。关于更多示例,请参阅GitHub repo。
解决方案的实现具体分以下几个步骤:
- 创建一个EMR notebook,并使用英伟达GPU节点启动Amazon EMR。
- 在notebook上运行开源XGBoost库与Apache Spark示例。
- 查看训练与转换结果及基准。
- 使用Apache Spark
spark-submit启动示例应用程序。
使用英伟达GPU节点创建EMR notebook并启动Amazon EMR
EMR notebook即无服务器Jupyter notebook。与传统notebook不同,EMR notebook的内容(包括方程、可视化、查询、模型、代码与叙述文本)与代码代码的集群分保存在Amazon S3当中。通过这种方式,EMR notebook在存储持久性、访问效率以及灵活性等方面都有所提升。
要创建notebook并启动Amazon EMR,请完成以下操作步骤。
- 在Amazon EMR控制台上,选择您希望启动集群的对应区域(通常应选择大型训练数据集存储所在S3存储桶的同一区域)。
- 选择Notebooks。
- 选择Create notebook。
- 通过设置GPU节点创建一个带有notebook实例的新集群。
在本用例中,我们向新集群中添加3个EC2 g4dn.xlarge GPU节点。

如果大家希望使用高级配置创建自定义集群,则可分别创建一个GPU集群,而后再单独创建EMR notebook并接入该GPU集群。您可以在AWS命令行界面(AWS CLI)中输入以下代码,从而启动以2个EC2 G4dn实例为核心节点的GPU集群:
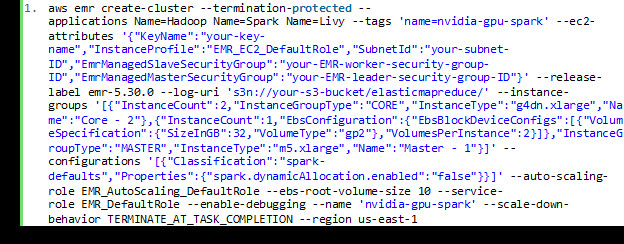
将其中的 KeyName, SubnetId, EmrManagedSlaveSecurityGroup, EmrManagedMasterSecurityGroup以及S3存储桶的值替换为您的实际日志、名称与区域。
大家也可以使用AWS管理控制台配置这套EMR集群。关于更多操作说明,请参阅GitHub上的XGBoost4J-Spark on AWS EMR入门指南。
在EMR notebook上运行XGBoost库与Apache Spark示例
当集群准备就绪之后,转到Amazon EMR notebooks,选择notebook实例,而后选择Open in Jupyter。如果notebook实例还未运行,请将其启动。
从GitHub上的 Rapids/spark-examples处下载示例notebook EMR_Mortgage_Example_G4dn.ipynb,并将其上传至EMR notebook实例。关于更多Scala示例代码,请参阅 GitHub repo。
输入贷款示例notebook,在开源XGBoost库上运行指向Amazon S3小型贷款数据集的GPU加速Apache Spark代码。如果notebook内核未被设定为Apache Spark,则选择Kernel、Change Kernel并将Apache Spark设置为内核。EMR notebook现在已经开始使用Apache Livy与运行有Apache Spark的EMR集群通信。下图所示,为这套架构的基本构成。

大家还可以定制调整自己的Apache Spark作业配置,例如执行程序数量、核心数量以及GPU集群上的执行程序内存容量等等。每个GPU对应一个执行程序。
查看训练与转换结果及基准
在EMR notebook中,大家可以查看Apache Spark作业的执行进度与基准测试结果。您还可以将训练后的模型保存在本地文件夹或者S3存储桶当中。以下截屏所示,为我们的作业进度。

以下代码,为本用例的基准测试结果:
—— Training ——==> Benchmark: Elapsed time for [train]: 37.881smodel: ml.dmlc.xgboost4j.scala.spark.XGBoostClassificationModel = xgbc_d5a83fea59b5 —— Transforming ——==> Benchmark: Elapsed time for [transform]: 0.115s…——Accuracy of Evaluation——evaluator: org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator = mcEval_daa2cccd95a4accuracy: Double = 0.98750075898030530.9875007589803053
…
使用spark-submit脚本启动示例应用程序
或者,您也可以通过SSH接入EMR主节点,并使用Apache Spark spark-submit脚本直接在集群上启动应用程序。请参考GitHub repo上的演练过程,使用Apache Maven创建一个包含贷款数据集及其依赖项的示例代码jar文件,而后使用Apache Spark spark-submit脚本CLI启动该应用程序。
资源清理
为了避免基准测试中使用的资源持续产生成本,请删除为其创建的所有资源,具体包括S3存储桶、EMR集群以及EMR notebook上的数据。
总结
感兴趣的朋友不妨马上开始体验Amazon EMR;如果您需要将大数据与应用程序迁移至AWS,请联系我们寻求帮助。您还可以了解更多为英伟达RAPIDS项目做出贡献的详细信息。
本文中的内容与观点来自第三方作者,AWS对本文的内容或准确性不承担任何责任。