亚马逊AWS官方博客
云端的开源数据科学应用框架 -Metaflow
TL;DR 如果你是个云计算的用户,且习惯于使用开源的工具,Metaflow 这款由Netflix打造的基于云的面向数据科学应用的Python框架绝对值得了解一下。
在去年底的AWS re:Invent大会上照例发布了许多新的技术与服务,其中就包括了这样一个开源项目- Metaflow。众所周知,Netflix这家视频流媒体巨头在其业务中大量使用了机器学习,涉及了剧本分析到优化制作的时间表、预测流动率、定价、内容翻译,以及优化其庞大的内容分发网络等。Netflix 在机器学习、数据科学领域的实践让我们意识到,数据科学家想要做的几乎所有事情在技术上都是可行的,但却没有一件事情是简单且容易的。因此,数据科学/机器学习基础架构团队的工作不应该仅仅是为了实现新技术的创新。 相反,其目标应该是让常见的数据处理变得更加简单,以至于数据科学家甚至都不会意识到它们以前如此的困难。在过去的两年中,Metaflow被广泛应用于Netflix许多业务领域,用于帮助数据科学团队提高生产力。于是,数据科学家、开发人员们专注于Python代码的业务逻辑,而不是花太多时间解决基础设施的工程问题。而正是由于Metflow的广泛采用,使许多项目加速了它们的开发周期,从而证明了这个开源项目的价值。
什么是Metaflow?
准确说来,Metaflow是由Netflix开发的一个适用于AWS云计算环境的,用于数据科学/机器学习的,基于Python语言的开源框架。项目的目标就是为了解决数据科学家在数据处理工作中可伸缩性和版本控制方面存在的一些挑战。从功能方面来看,Metaflow具有以下内置的功能:
- 管理计算资源
- 执行“容器化”操作
- 管理外部依赖性
- 版本管理,重放和恢复工作流程运行
- 客户端API可检查Notebook的运行情况
- 将本地的运算(例如在笔记本电脑上)转移到云端(例如AWS)上)执行
从这几项主要的功能来看,Metaflow在计算资源的顶部提供了一个抽象层。这意味着Metaflow的使用者可以专注于代码,而Metaflow将管理如何在一台或多台云上的计算实例上运行它。 从这个角度来看,我们可以把Metaflow的特点归纳为- 为数据科学的应用提供了“基础架构堆栈的统一API”。
Metaflow 的基本概念
Metaflow 工作流在本质上是一个有向无环图(DAGs),图中的每个节点表示工作流中的一个处理步骤。Metaflow在工作流的每个步骤中执行我们开发的Python代码,就像在单独的“容器”中执行一样,这些“容器”被打包成相应的依赖项。Metaflow体系结构中的这一关键特性能够使得Metaflow可以从诸如Conda这样的生态系统中注入几乎任何外部Python库,而不是使用插件。 这也是Metaflow与其他解决方案(例如Airflow)的一个明显区别。在下图的这个例子中,工作流被设计为并行的训练模型的两个不同的版本,最终选择得分较高的那个模型。
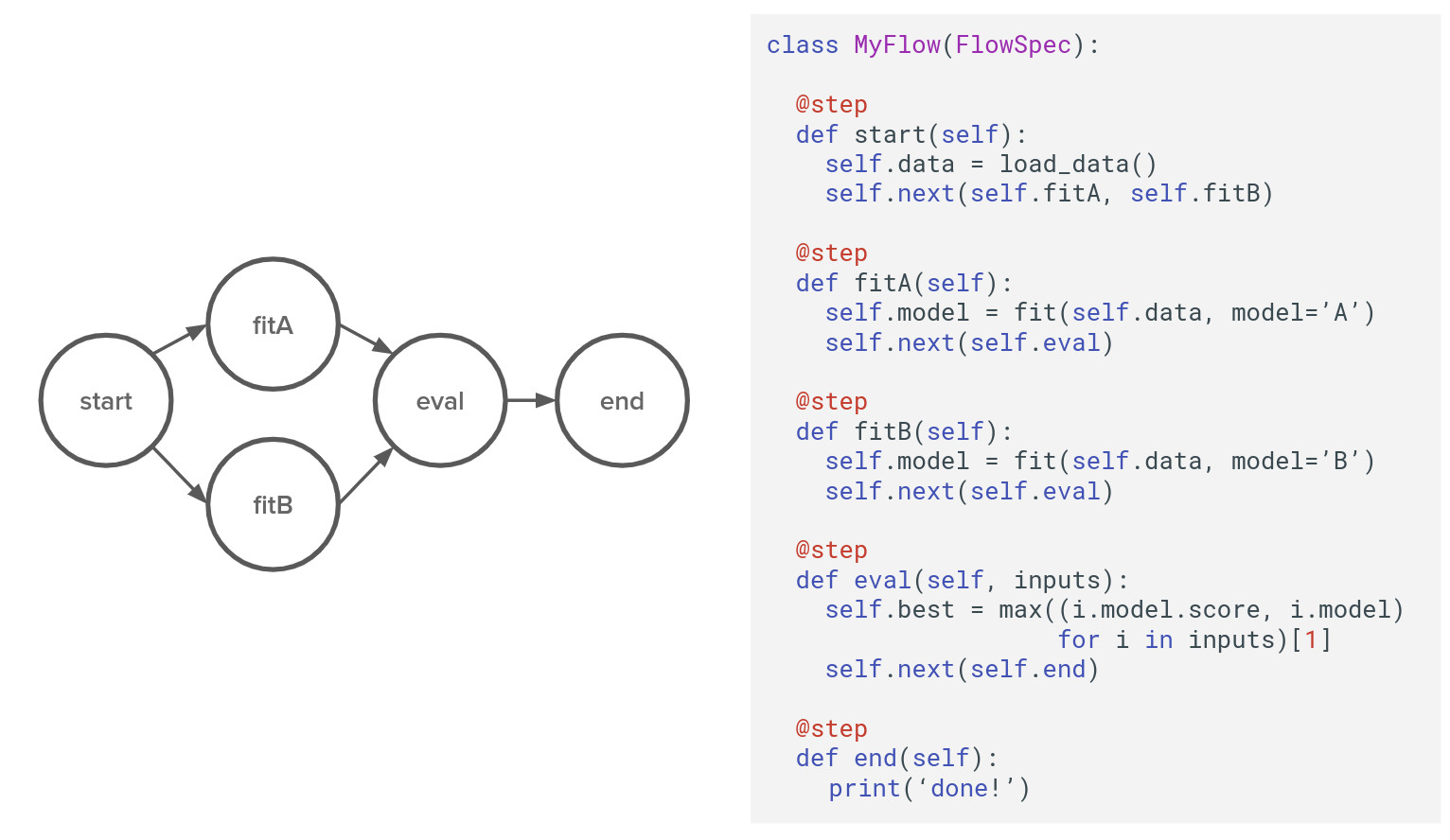
从表面上看,这种实现的方式极其常见。现有的许多框架,例如广泛流行的Airbnb 的Apache Airflow 以及Spotify的 Luigi,它们都设计为允许执行由任意Python代码组成的有向无环图(DAG)。与上述两个框架的差异在于Metaflow的许多精心设计的细节之中:例如,在上图的示例中,数据和模型是如何作为普通Python实例变量存储的。这使得代码即使在分布式计算平上台也可以正常执行,这要归功于Metaflow内置的内容寻址工件存储(Artifact Store)。在许多其它的框架中,工件的加载和存储这一类复杂的工作留给用户去实现,这就要求开发者来决定哪些应该持久化、哪些不应该持久化。而Metaflow则简化了这种额外的工作。事实上,Metaflow的设计中还有很多细节体现了这种“开发者友好”的特性,所有这些都有助于提高开发的的生产效率。
AWS 上的Metaflow
按照Netflix的介绍,他们的数据仓库包含有数百PB的数据。尽管在目前在Metaflow上运行的典型机器学习工作流仅涉及该数据仓库的一小部分数据,但从架构及功能方面来看,我们认为Metaflow可以处理TB级别的数据。
总所周知,Netflix 早在2008年就开始了云计算的旅程。当时Netflix经历了一次严重的数据库损坏故障,严重到三天之内Netflix无法将DVD交付给他们的会员。从那时,Netflix就意识到必须从传统的垂直扩展的具有单点故障的系统转向云计算高度可靠、可水平可扩展的分布式系统。于是,Netflix选择了AWS作为他们的云计算提供商,因为AWS为Netflix提供了最大的规模以及最广泛的服务和功能集。
在2016年的一篇博客中“Completing the Netflix Cloud Migration”。Netflix正式宣布,在经过七年的努力之后,Netflix终于在2016年1月初完成了云迁移,并关闭其使用的最后剩余的数据中心。
基于这样的一个背景,不难猜得出来 Metaflow注定就是一个云原生的框架。它通过设计充分利用了云计算的“弹性”来处理计算和存储。 作为过去十二年的AWS的用户,Netflix在云计算方面,尤其是在AWS的使用方面积累了丰富的运营经验和专业知识。因此, Metaflow实现了与多种AWS服务之间的无缝集成。
Metaflow具有内置功能,可以自动快照Amazon S3中的所有代码和数据,这是Netflix内部Metaflow设置键-值(Key-Velue)的方法。通过这种方法实现了版本控制和实验数据的跟踪,并且无需任何用户干预,作为一个生产级别的机器学习/数据科学基础架构的这是一个非常重要的特性。
此外,Metaflow提供了一个高性能的Amazon S3客户端,该客户端可以加载高达10Gb/秒的数据。该客户端在Netflix的使用中受到了广泛欢迎,在将数据加载到工作流中,速度比以前快一个数量级,从而可以加快迭代周期。

对于通用数据处理的任务,Metaflow实现了与AWS Batch的集成。所谓的AWS Batch是AWS提供的基于容器的托管计算平台,用来运行批处理计算作业。 通过在代码中添加一行:@batch,用户可以从AWS 无限扩展的计算集群中受益。 对于训练机器学习模型,除了编写自己所需的的功能外,用户还可以选择使用AWS Sagemaker,这个服务提供了多个模型的高性能实现,其中许多模型都支持分布式训练。以下是一个简单的例子,可以让我们了解一下Metaflow 与AWS服务的集成-
设置与部署
首先,需要在AWS上进行一次性设置,以创建Metaflow运行所需的资源。如果希望共享任务,团队可以使用相同的资源。在AWS上设置与部署可以说非常的简便,因为Metaflow提供了一个Cloudformation模板。
然后,在本地系统上运行metaflow configure aws,并按照提示信息提供相应的配置项。现在就可以在云上运行任何工作流,所要做的就是将 – with batch添加到run命令中。对于混合运行模式,也就是说在本地运行几个步骤,在云计算中运行几个步骤。那就要在希望在云中运行的工作流中的步骤中添加@batch装饰符。例如:@batch(cpu=1, memory=500)
Metflow 的安装方法与运行
安装
Metaflow是运行在MacOS和Linux的Python包。安装的方法既可以访问该项目GitHub存储库或者从PyPI获得最新版本。简单的安装可以通过pip 命令完成 –
pip install metaflow
此外,Conda 也是许多Python开发人员的选择。通过Conda 完成安装也不是件复杂的事情。
- 下载并安装Miniconda或者Anaconda (如果还没有安装conda)
- 添加一个conda channel:conda config –add channels conda-forge
- 安装:conda install -c conda-forge metaflow
如果使用了conda,一个有意思的的方法就是在工作流程中注入conda依赖项。此外,Metaflow通过Python的 @conda装饰符支持几乎所有常见的机器学习框架,这些框架所需的外部依赖关系也可以通过这个方式加以实现。 而@conda装饰符还帮助开发者“冻结”执行环境,从而确保在本地以及在云中执行时的可重复性。
注意:众所周知,Python 2 的生命周期截止于2020年1月1日。强烈建议在使用Metaflow的过程中使用Python 3。事实上,Metaflow对遗留应用仍然提供了对Python 2.7的支持。但是Metaflow项目中Python 3的Bug更少,而且比已弃用的Python 2.7支持得更好。
运行
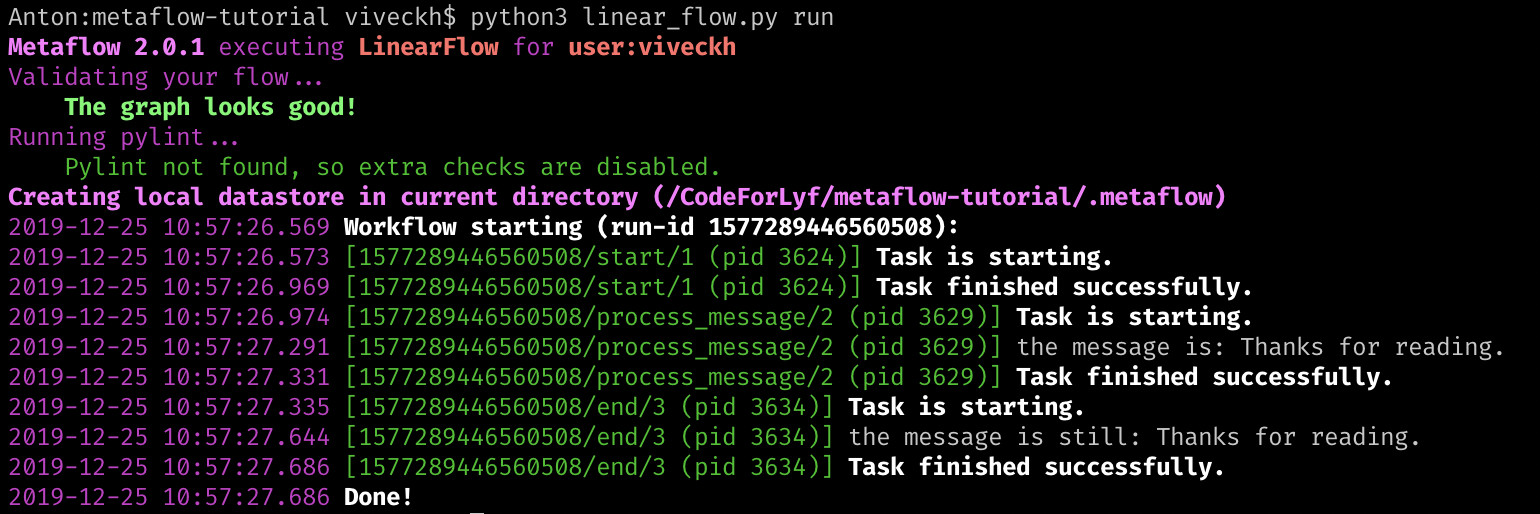
在完成简单的安装以后,我们来体验一下如何运行Metflow 的“流”应用。这里是一个简单的Python 程序,我们将其保存为linear_flow.py。
我们现在来做如下操作:
- 查看此流程的设计:python3 linear_flow.py show
- 运行这个流:python3 linear_flow.py run

结语
通过上文简单的介绍,我们能够得到这样的结论。Metaflow的目标是实现数据科学/机器学习处理的“无缝的可扩展性”,并且看起来做得很好。并且,提供了与AWS云计算的紧密集成。也许这是一个小小的不足,Metaflow完全基于命令行工具,不提供任何图形用户界面的工具,这与Airflow等其他通用工作流框架有所不同。
最后,我想说的是如果您可能需要将您的数据科学/机器学习项目扩展到云中并且,则应该考虑一下Metaflow。相信它会带给你惊喜!