亚马逊AWS官方博客
Amazon EMR之EMR和Hadoop的前世今生
前言:
一转眼,从GFS论文发布到现在已经将近二十年了。从惊为天人到百家争鸣,再到现在各处都已经有Hadoop已死的消息。接下来就想和大家聊聊,当年Hadoop到底做对了什么事,又为什么在时代的发展中开始被大家逐渐抛弃。同时笔者看到关于Amazon EMR的中文资料甚至基础文档并不多,也会介绍一些进入云原生时代之后,作为领先的云厂商,亚马逊云科技基于Hadoop生态做出的产品,和原生Hadoop相比有何异同。以此为想要使用大数据,以及想要在云上搭建大数据平台的读者提供一些额外的信息和帮助。
初识Hadoop
Hadoop作为Google论文的开源实现,其实主要实现了两个功能:
1.分布式文件系统HDFS
进入互联网时代以来,数据量的总量和增速都越来越大,传统的文件系统无法承载如此巨大的数据;同时,专用的大容量存储设备不仅需要高昂的授权费用,还依赖专用的高端硬件。而HDFS一经的推出,就完美的契合了互联网对于性价比、可扩展和可靠性的核心诉求。成为了最广泛使用的分布式文件系统。
2.分布式计算调度系统YARN
同样,随着需要处理的日志量越来越大,高端的MPP或者HPC计算集群设计之初就是为了高性能计算场景打造,没有考虑太多成本的因素;用这些超算来处理海量日志确有杀鸡用牛刀之嫌,更别说在商业化运营为主的互联网世界里,盈利是重要的目的。于是基于打造HDFS的经验,YARN使用了类似的架构,实现了在普通x86服务器集群上分布式调度计算资源的能力;考虑到当时的网络IO能力,还引入了就近计算的概念,让计算任务跟着存储节点跑,挪任务不挪数据,极大降低了分布式计算任务中的IO开销。
3.分布式计算框架MapReduce
存储和计算都有了,但怎么让用户能够通过简单的代码或者规范来操作这些存储和计算还没有。MapReduce所做的就是在海量日志分析场景中,抽象出了Mapper和Reducer两种“简单”算子:用这两个算子排列组合,可以生成计数,排序,聚合等各种日志分析中常用的操作;而这两种算子本身,又很容易并发得分配给分布式计算任务系统YARN去调度执行。
以上三部分,就简单介绍完了Hadoop的基石。更多技术细节如果大家感兴趣,可以参考附录的三篇Google重量级论文的中文版,同时网上也有很多深入解读。而在后续的发展中,最为重要的里程碑则是Hive的发布,从此基于Hadoop生态圈有了对SQL语法的兼容的计算引擎,更进一步拓展Hadoop系统的使用场景。
Hadoop已死?
复习一下刚才介绍的Hadoop的特性,大家可以看到低成本,可靠性,大规模是Hadoop系统的核心竞争力,而这些核心竞争力又是基于当时大部分廉价商用服务器的硬件性能作出的最佳设计:内存不够大,就是用廉价的磁盘作为缓存和状态保存;网速不够快,就尽量在数据块所在的机器处理该数据块;CPU不够好,就尽量用简单的算子派发给CPU运算。是不是明白过来为什么过了二十年之后的今天,有这么多Hadoop已死的论调?
放眼当今,单机1TB的内存容量已经远超了当年的磁盘空间;网速从100M/1000Mbps发展到了100Gbps/400Gbps,超过100倍;而增长最为“缓慢“的CPU性能,虽然主频”只“是从1GHz爬升到了4GHz,但片上128核,和各种高端的向量化指令让IPC大大提升。更为突出的矛盾在于,传统的日志分析已经无法满足高速增长的业务需求,分析对象从日志变成了更加复杂的用户点击流,评论,图片,视频;分析对象的增加,也让数据量的增长远远超过对计算力的需求, Hadoop该何去何从?
从Hadoop到EMR
在大数据和Hadoop蓬勃发展的头十年,得益于硬件性能的发展和硬件虚拟化技术的成熟,还有一项技术也在如火如荼得进化:云计算。作为全球首屈一指的云计算巨头,亚马逊云科技始终引领着整个产业的发展方向。,在亚马逊云科技创立云计算以来,没有任何一个行业不跟云计算相关,没有任何一个颠覆性的创新缺少云计算的参与,云已经是不可逆的滚滚洪潮。在亚马逊云庞大的基础设施和技术支撑下,提供了过往难以比拟的的弹性,可以让我们在几分钟之内横向扩容成百上千台EC2,也可以在几分钟之内将2核16G的EC2纵向升级为128核1024G,且只需要为真实使用时长付费;与此同时,提供高达数Tbps带宽大规模并发读写性能的S3,也让用户无需管理繁琐的存储设备,只需为自己的实际存储的容量付费。
有了以上几点作为基石,我们再来看如何解Hadoop的难题:1、存储增长远超算力需求,产生了大量闲置算力;2、集群节点越来越多,主节点的负载水涨船高,稳定性堪忧;3、单一或几个集群的联邦,导致升级越来越困难,难以快速引入新型的计算引擎。有没有一种新的计算架构,既兼容Hadoop的生态,又将存储和计算剥离开来,可以分别独立扩展,同时还能保证任务的性能,那是不是就能为Hadoop生态延续活力?
于是基于亚马逊云服务的EC2和S3,诞生了EMR这样一个托管服务,全称是ElasticMapReduce,弹性MapReduce服务。EMR完美继承了EC2和S3的一切特性:可以在数分钟内启动一个完整的集群;基于S3达成了存储无限扩容的特性;亚马逊还为Amazon EMR研发了兼容Hadoop生态的EMRFS协议,依赖EC2的高带宽,获得了媲美甚至超越HDFS的磁盘的吞吐性能,同时达成了存储和计算的分离;通过定制的AMI和托管的服务,不仅支持在单一集群上自动化安装包含Hive,Spark,Flink等多种包含在YARN体系内的应用,也有Presto这样MPP架构的SQL引擎,甚至还支持TensorFlow,MXNet这些机器学习的通用框架。托管式的服务极大降低了Hadoop集群的搭建和管理成本,存算分离的架构为计算扩张和集群升级带来了传统Hadoop所不具备的灵活性,将EMR变成了无状态的Hadoop集群,可以随时起停。下面让我们来看看Amazon EMR的设计架构图并简单介绍。
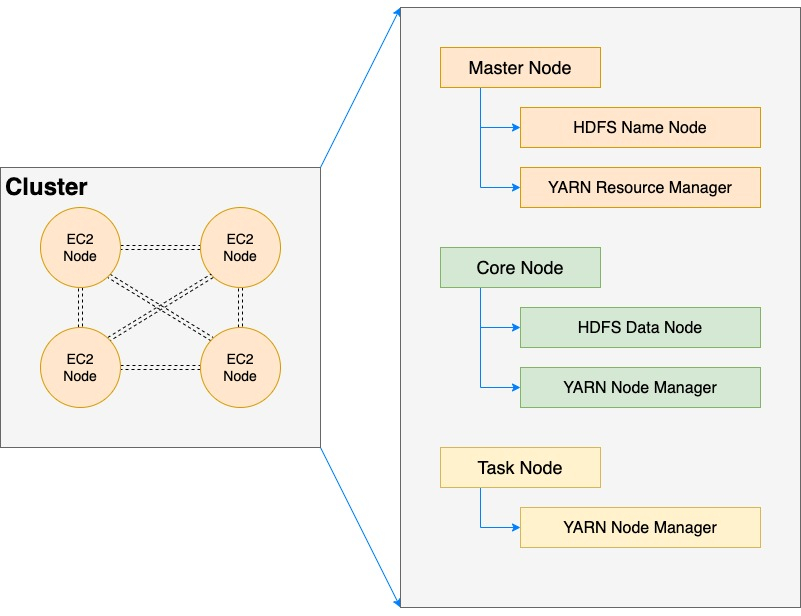
和一般的Hadoop集群略有不同,Amazon EMR分成了三个部分:
第一部分是Master,和传统的Hadoop主节点一样,主要运行Name Node 和Resource Manager,如果是非高可用集群,Master是一个单点,如果是启用高可用选项,Master是三台,一主两备且数量不可变更;
第二部分是Core,Core和一般的Hadoop子节点一样,运行Data Node和Node Manager,承担存储节点和计算任务。虽然EMR可以通过EMRFS将数据存储在S3,但Hadoop本身还是依赖一些HDFS的场景(包括但不限于任务jar包的分发,日志的聚合),所以Amazon EMR仍然保留了Data Node。需要注意的是每个EMR集群只能有一个Core节点组,所以只能选择一种机型,且一旦集群启动完毕,Core节点组只能水平扩容和缩容,无法变更机型。同时如果想要通过lift&shift模式将线下CDH/HDP等Hadoop集群迁移上来,可以继续使用同样的架构,只使用Core节点就行;同时由于Core节点组存在HDFS,不推荐频繁扩缩容,会引发rebalance,特别是对于传统的重度HDFS使用环境来说,会极大影响性能。当然了,因为Core节点相对比较稳定的特性,我们也会在进阶EMR的应用中看到一些特别的用法。
第三部分就是Amazon EMR相对比较特色的Task节点,Task节点最为简单,只需要跑Node Manager就行,所有的数据都会通过网络访问S3或者别的节点上来获取,计算完成之后也会全部写回S3或者别的节点。Task节点的存在为EMR节点带了无状态的特性,可以随意丢弃,所以都可以异常轻松的扩缩容——甚至可以使用亚马逊云科技特别的Spot实例,并且不用担心该实例被强制回收。而Task节点的另外一个好处就是异构,和Core节点组只能有一组且相对比较固定不同,我们可以通过使用多个Task节点组,混用各种不同类型不同规格不同计费方式的实例,Amazon EMR都会妥善得自动管理,最大化得利用这些节点的计算资源。
结语:
本篇为大家初步介绍了Hadoop基础,同时说明了Amazon EMR和Hadoop的相同与不同之处。后续我们会进一步介绍基于Amazon EMR的不同之处,我们如何更好得使用云原生的方式构建我们的数据分析架构。
附录:
参考动手实验:
日常可能需要几天才能搭建完成的Hadoop测试集群,在亚马逊云上只需要半天,就可以完成从集群搭建到完整的ETL PoC体验。
参考Amazon EMR官方文档:
https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-what-is-emr.html
参考的Google论文:
http://static.googleusercontent.com/media/research.google.com/zh-CN/us/archive/gfs-sosp2003.pdf
http://static.googleusercontent.com/media/research.google.com/zh-CN/us/archive/mapreduce-osdi04.pdf