浏览本文需要约10分钟,建议按照章节分段阅读。
在AI加速企业应用的时代,面对快速增长的数据,企业通常会构建高效、可扩展、低成本的分布式存储系统。既要保障数据的安全性与完整性,还要实现便捷的管理和灵活的访问,快速将海量数据高效输送到GPU等计算资源,支持AI训练与推理任务。
以下是在开源社区中,几个开源分布式文件系统常见的比较,包括GitHub星标情况及主要特点:
| 产品名称 |
GitHub Star 规模(2025年8月) |
主要特点简述 |
| JuiceFS |
约12k |
云原生设计,依赖对象存储,支持高性能、弹性扩展,适合云环境和大规模AI训练。官方文档及对比文章丰富 |
| Alluxio |
约7k |
主要用作分布式存储缓存层,支持多数据源聚合。非持久存储,适合作为加速层 |
| Ceph |
约15.3k |
企业级成熟系统,支持快照和细颗粒权限,适合私有云和IDC环境。配置和运维相对复杂 |
| GlusterFS |
约5k |
传统分布式文件系统,无中心元数据,简单部署,性能和扩展性相对有限 |
| SeaweedFS |
约25.3k |
高性能分布式存储,元数据操作较弱,但轻量且自包含。适合大对象存储 |
当前,大多数企业选择在多云环境的 Kubernetes 上运行AI应用通过 CSI Driver 实现与持久化存储的无缝集成,使用标准 POSIX 协议访问文件数据,能够支持大多数应用、框架和工具,例如 AI 训练平台、大数据分析以及常见数据处理程序等。在综合对比社区主流分布式存储项目以及客户在技术社区中的实践,JuiceFS 是当前符合上述需求的优选方案。本文将探讨在亚马逊云科技上构建 JuiceFS 的具体实践。
1. 构建方向
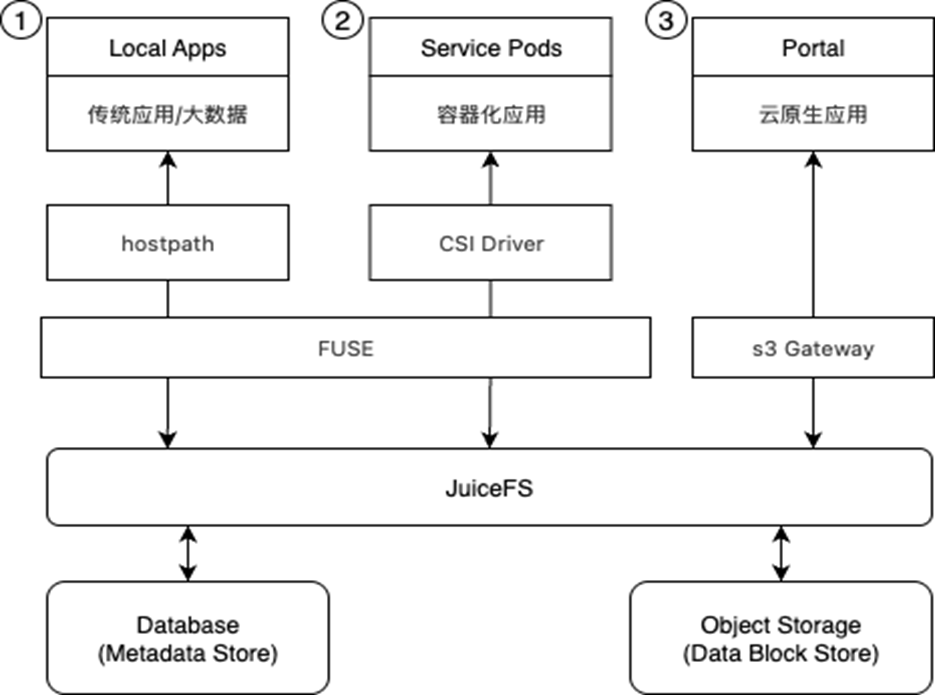
在选定 JuiceFS 作为存储层解决方案后,整体存储架构演变为下图的三种形态:
本文将从实际使用方式的三个环节进行详细说明,并首次对 JuiceFS CSI Driver on EKS部分进行系统性描述。
| 使用方式 |
使用场景 |
业务特点 |
技术优势 |
| HostPath |
直接处理百万级的训练数据并保持读取稳定,适配 AI/ML 训练、科学计算等高 I/O 场景 |
模型训练需处理超大规模数据集,且源数据大多分布在各类对象存储。当所有训练计算资源集中配置时,通常选择直接在物理机或容器上(HostPath)通过 FUSE 将 JuiceFS 卷挂载到本地目录 |
可以透明整合不同云存储来源的训练数据形成统一本地访问空间,无需人工拷贝或脚本同步,实现大规模并发高效、稳定的数据读取 |
| CSI Driver |
完成自动化部署、卷自动扩缩容、数据隔离等企业级生产需求,提升站点运维和弹性能力 |
k8s 上运行的大数据、微服务集群需要持久化共享存储,且多个 Pod/租户并行读写同一数据集 |
CSI Driver 管理的挂载点能够实现精细化资源调度与并发控制,避免资源冲突。例如,通过 pod 级访问控制和调度优化,有效解决早期的死锁、并发读写冲突等问题 |
| S3 Gateway |
企业内部构建自有文件共享服务,实现复杂的权限和时效性管理 |
无需单独开发权限体系,直接用 S3 标准工具(awscli、minio client 等)和 SDK 进行安全数据共享。
也可用于 Web 管理界面的跨平台文件操作和多云同步
|
S3 Gateway 提供角色与精细权限(基于 IAM/ACL)管理机制,可通过 Security Token 实现共享链接的时效管控,有效防止数据被滥用或恶意抓取 |
2. 环境准备
2.1 准备对象存储
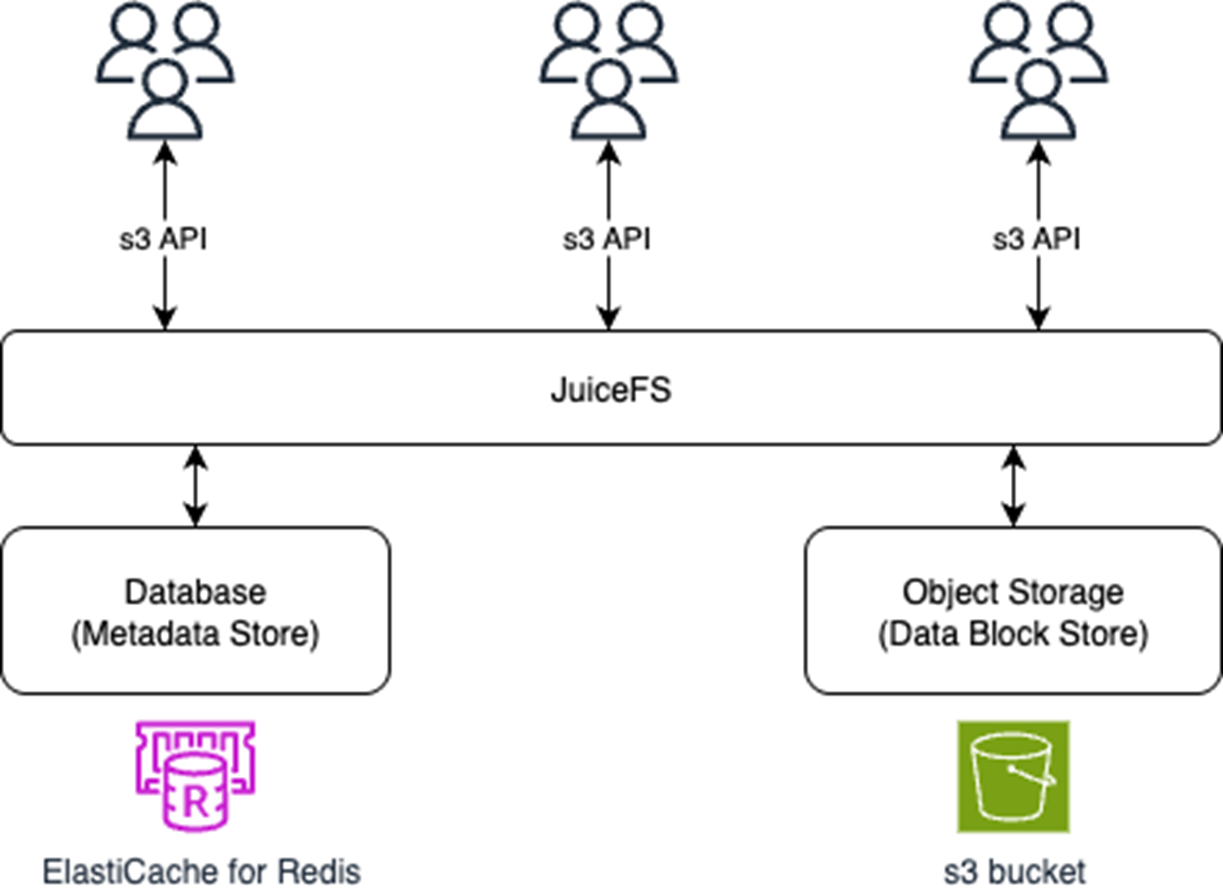
Amazon S3 是公有云对象存储服务的事实标准,其他主流云平台提供的对象存储服务通常也兼容 S3 API,这使得为 S3 开发的程序可以自由地在其他平台的对象存储服务之间切换。JuiceFS 完全支持 Amazon S3 以及所有类似 S3 的对象存储服务,所有支持的存储类型请参见 JuiceFS 的官方文档。
2.2 准备数据库
JuiceFS 主要支持三种类型的元数据引擎。
第一种是 Redis,它是 JuiceFS 自首次发布以来就支持的元数据引擎。JuiceFS 也支持兼容 Redis 协议的数据库,例如 KeyDB 和 Amazon MemoryDB。但是Redis 的可靠性和可扩展性有限,在数据安全性要求高或规模较大的场景下性能不佳。
第二种是类 SQL 引擎,例如 MySQL、MariaDB 和 PostgreSQL,通常具有良好的可靠性和可扩展性,JuiceFS 还支持嵌入式数据库 SQLite。
第三种是 TKV(事务性键值数据库),它拥有更简单的原生接口,在 JuiceFS 中可定制性更强,并且通常比 SQL 数据库性能更高。目前JuiceFS 支持 TiKV、etcd 和 BadgerDB(也是嵌入式数据库),FoundationDB 的支持也在开发中。
以上是基于数据库协议的分类,每个类别中又包含各种数据库,每个数据库都有各自的特点,下表是官方文档根据这些特点对常用数据库的比较。
|
Redis |
MySQL/PostgreSQL |
TiKV |
etcd |
SQLite/BadgerDB |
| 性能 |
高 |
低 |
中 |
低 |
中 |
| 扩展性 |
低 |
中 |
高 |
低 |
低 |
| 可靠性 |
低 |
高 |
高 |
高 |
中 |
| 可用性 |
中 |
高 |
高 |
高 |
低 |
| 流行度 |
高 |
高 |
中 |
高 |
中 |
云平台通常都提供种类丰富的云数据库提供,比如 Amazon RDS 提供各类关系型数据库的版本,Amazon ElastiCache 提供兼容 Redis 的内存型数据库产品,经过简单的初始化设置就可以创建出多副本、高可用的数据库集群。
目前Redis 单机架构和Redis Cluster 都无法提供强一致性的保证,这个话题本文不再赘述,读者可以参考JuiceFS的官方说明。
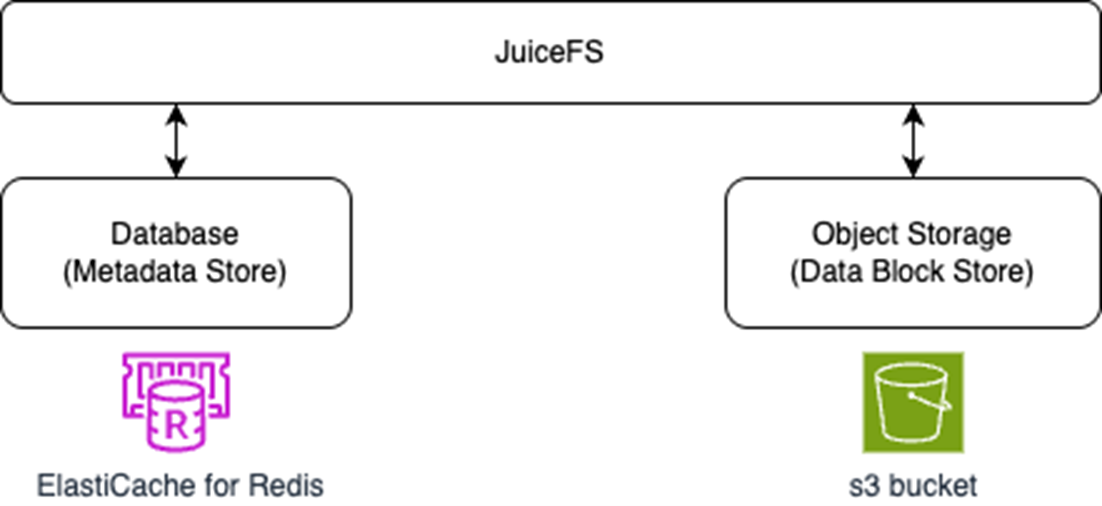
生产环境下,建议使用Amazon MemoryDB for Redis服务,这是一个兼容 Redis 协议的全托管存储服务,它具有微秒级的读取性能以及毫秒级的写入性能,并提供强一致性保证,这是通过将写操作持久化到一个分布式事务日志系统来实现的,以确保成功写入的数据不会丢失。Amazon ElastiCache for Valkey也是兼容 Redis 协议的全托管服务,主要作为内存缓存使用,提供极低的读写延迟,支持自动扩展和多可用区高可用,但它不提供强一致性保证,写入持久化机制和容错设计与 MemoryDB 不同,适合对一致性要求较低的缓存场景。
本文以在客户环境中经常使用的Redis为例,使用Amazon ElastiCache for Valkey和Amazon s3进行介绍。
Valkey是一个开源的高性能键值数据存储系统,由Linux基金会管理(由40多家大型全球企业来支持)。Valkey是Redis OSS闭源后的直接替代品,同样由Redis OSS的社区开发者开发和维护,自2024年3月项目启动以来,Valkey已经在业界被广泛使用。
Valkey配置过程请参考官方文档,其中分片个数,访问控制方式及需要注意的参数,请参考下边的表格:
| 参数 |
推荐值 |
说明 |
| Number of shards |
1~3 |
小规模测试选择1即可,或最多3分片模拟多分片场景 |
| Replicas per shard |
0 或 1 |
0副本模拟单节点部署,1副本模拟简易高可用测试
副本数设置为 0 时,无法启用多可用区。需选择一个或多个副本来启用多可用区。
|
| 访问控制方式 |
认证强度 |
适用场景 |
推荐程度 |
| No Access Control |
无认证 |
测试/内部隔离环境 |
不推荐 |
| Auth Default User Access |
基础认证
Auth Default User Access
|
小规模、权限简单的应用 |
可用,非最佳 |
| User Group Access List (RBAC) |
多用户多权限 |
多租户、复杂权限、高安全需求场景 |
推荐,最佳实践 |
| 参数名 |
调整方式 |
注意事项 |
| appendonly |
不能启用(保持 no) |
ElastiCache 不支持开启 AOF,使用多 AZ 多副本替代 |
| maxmemory-policy |
设置为 noeviction |
可通过参数组选项修改,保证元数据不会被驱逐 |
2.3 准备IAM策略
创建 IAM 策略juicefs-policy,包含访问 S3 以及对 Redis 访问所需权限
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowS3Access",
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:PutObject",
"s3:GetObject",
"s3:DeleteObject",
"s3:ListMultipartUploadParts",
"s3:AbortMultipartUpload"
],
"Resource": [
"arn:aws:s3:::juicefs-demo-eks",
"arn:aws:s3:::juicefs-demo-eks/*"
]
},
{
"Sid": "AllowValkeyAccess",
"Effect": "Allow",
"Action": [
"elasticache:Describe*",
"elasticache:ListTagsForResource"
],
"Resource": "*"
}
]
}
2.4 部署环境
| 节点名称 |
操作系统 |
配置 |
内网IP |
可用区 |
| Kubectl Console |
Amazon Linux 2023 |
t3.medium 2C/4G/50G |
10.28.6.94 |
ap-northeast-2a |
| EKS |
1.30 |
| node01 |
Amazon Linux 2 |
g5.xlarge 4C/16G/250G |
10.28.6.83 |
ap-northeast-2a |
| node02 |
Amazon Linux 2 |
g5.xlarge 4C/16G/250G |
10.28.6.176 |
ap-northeast-2b |
| 对象存储 |
Amazon S3 |
juicefs-demo-eks |
| 元数据引擎 |
Valkey caches 8.1.0 |
cache.r5.large 2C/13G |
| JuiceFS version |
1.3.0+2025-07-03.30190ca |
| juicefs-csi-driver version |
v0.26.4 |
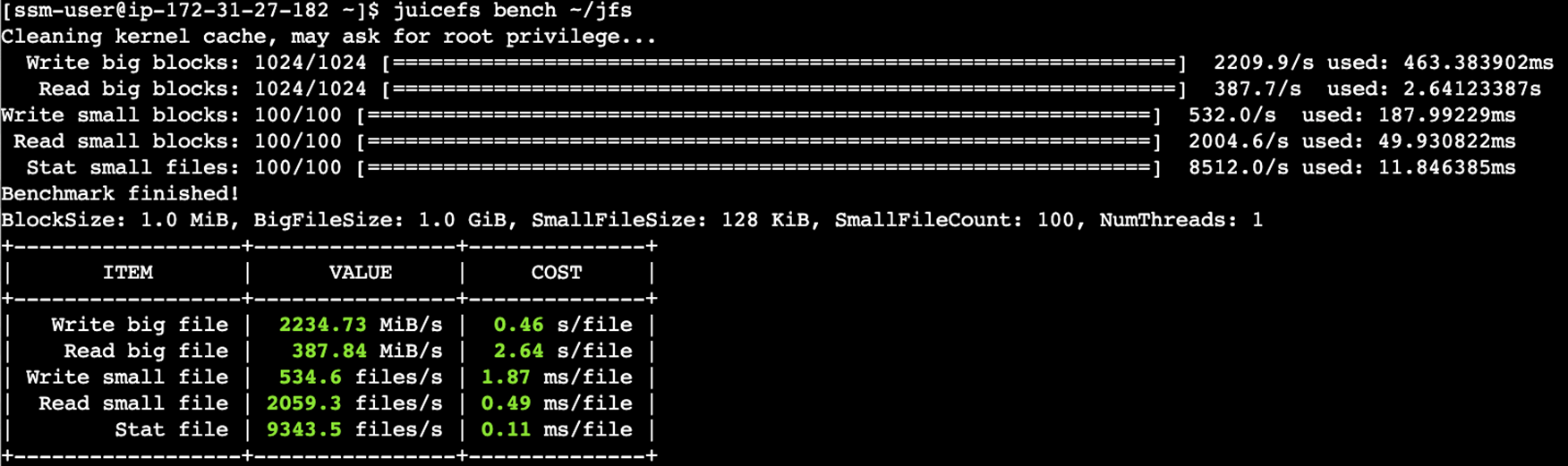
2.5 性能评估
以上的部署环境,是构建在一个通用场景下,适合中等规模、多样化计算需求、对存储性能和系统可靠性有较高要求的云原生应用。在准备交付生产之前,需要评估下使用场景,对部署的资源进行调整,包括:
- 对接的应用是什么?比如 Apache Spark、PyTorch 或者是自己写的程序等
- 应用运行的资源配置,包括 CPU、内存、网络,以及节点规模
- 预计的数据规模,包括文件数量和容量
- 文件的大小和访问模式(大文件或者小文件,顺序读写或者随机读写)
- 对性能的要求,比如每秒要写入或者读取的数据量、访问的 QPS 或者操作的延迟等
3. 构建过程
3.1 安装客户端
在所有需要挂载文件系统的计算机上安装 JuiceFS 客户端,一键安装脚本适用于 Linux 系统,会根据EC2架构自动下载安装最新版 JuiceFS 客户端。
# 默认安装到 /usr/local/bin
sudo curl -sSL https://d.juicefs.com/install | sh -
# 确认安装的版本
[ec2-user@ip-172-31-27-182 bin]$ juicefs -V
juicefs version 1.3.0+2025-07-03.30190ca
3.2 创建文件系统
[ssm-user@ip-172-31-66-201 ~]$ juicefs format --storage s3 --bucket https://s3.ap-northeast-2.amazonaws.com/juicefs-demo-eks rediss://default:juicefspasswordabc@clustercfg.juicefs-valkey.kjmaj8.apn2.cache.amazonaws.com:6379/1 juicefs-apn2
3.3 挂载文件系统
在一台EKS node上挂载文件系统
[ssm-user@ip-172-31-66-201 ~]$ sudo /usr/local/bin/juicefs mount -d rediss://default:juicefspasswordabc@clustercfg.juicefs-valkey.kjmaj8.apn2.cache.amazonaws.com:6379/1 /mnt/juicefs
2025/08/04 09:43:25.707487 juicefs[604981] <INFO>: Meta address: rediss://default:****@clustercfg.juicefs-valkey.kjmaj8.apn2.cache.amazonaws.com:6379/1 [NewClient@interface.go:578]
2025/08/04 09:43:25.724902 juicefs[604981] <INFO>: redis clustercfg.juicefs-valkey.kjmaj8.apn2.cache.amazonaws.com:6379 is in cluster mode [newRedisMeta@redis.go:214]
2025/08/04 09:43:25.737225 juicefs[604981] <WARNING>: AOF is not enabled, you may lose data if Redis is not shutdown properly. [checkRedisInfo@info.go:84]
2025/08/04 09:43:25.737951 juicefs[604981] <INFO>: Ping redis latency: 619.556µs [checkServerConfig@redis.go:3692]
2025/08/04 09:43:25.739458 juicefs[604981] <INFO>: Data use s3://juicefs-demo-eks/juicefs-apn2/ [mount@mount.go:588]
2025/08/04 09:43:26.241453 juicefs[604981] <INFO>: OK, juicefs-apn2 is ready at /mnt/juicefs [checkMountpoint@mount_unix.go:235]
自动挂载
# 将 juicefs 客户端重命名为 mount.juicefs 并复制到 /sbin/ 目录
[root@ip-172-31-65-22 ~]# cp /usr/local/bin/juicefs /sbin/mount.juicefs
# 编辑/etc/fstab配置文件,添加下边的新记录
rediss://default:juicefspasswordabc@clustercfg.juicefs-valkey.kjmaj8.apn2.cache.amazonaws.com:6379/1 /mnt/juicefs juicefs _netdev,cache-size=20480 0 0
3.4 验证文件系统
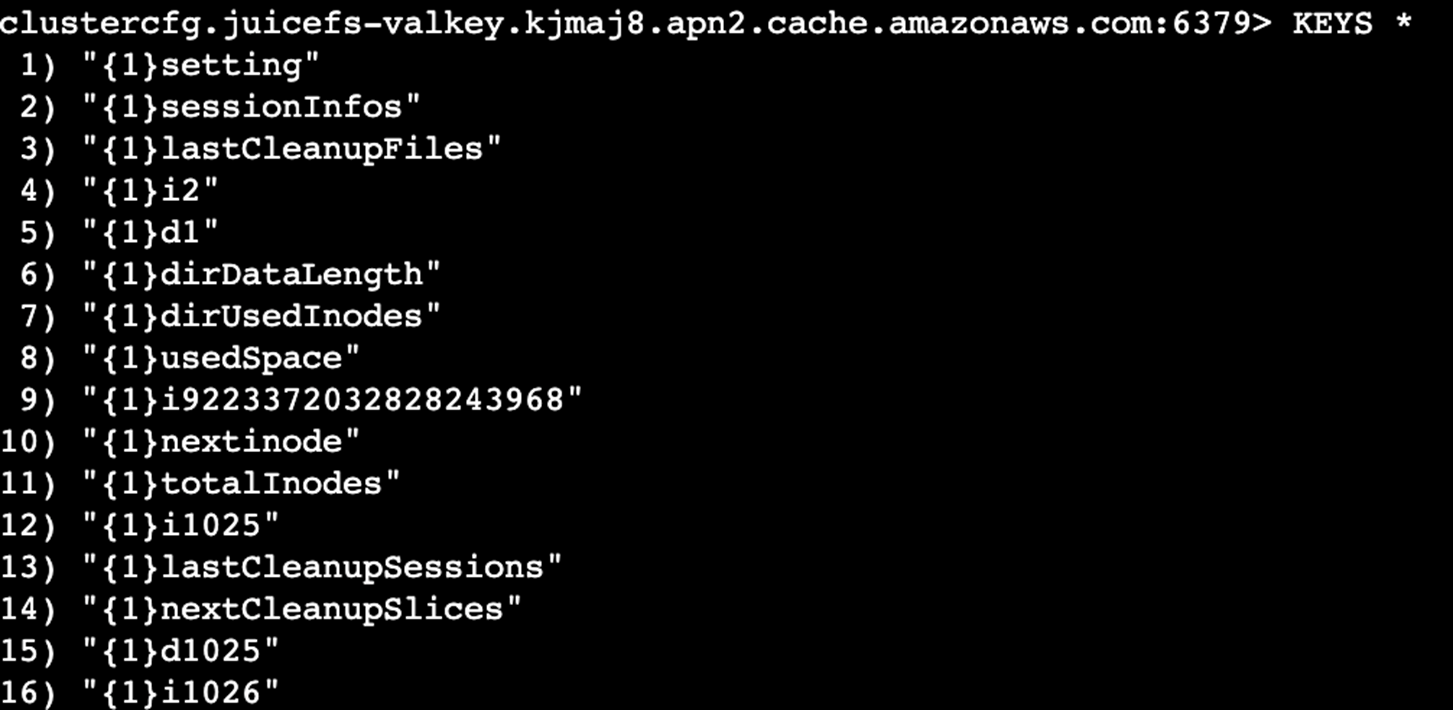
3.5 查看源数据
Valkey 完全兼容 Redis 7.2+ 的命令,使用标准的 redis-cli 工具来连接和查询数据。在EC2实例上安装valkey-cli的具体步骤如下,适用于Amazon Linux或类似的Linux发行版:连接到EC2实例,确保已具备sudo权限。
安装必需的依赖工具
sudo yum install -y gcc jemalloc-devel openssl-devel tcl tcl-devel make
# 下载valkey-cli的源码包(以最新版本为例,这里用的是8.1.3版本):
wget https://github.com/valkey-io/valkey/archive/refs/tags/8.1.3.tar.gz
# 解压源码包:
tar xvzf 8.1.3.tar.gz
cd valkey-8.1.3/
# 编译valkey-cli:
如果是第一次编译,建议先执行清理:
make distclean
# 然后带TLS支持编译valkey-cli:
make valkey-cli BUILD_TLS=yes
# 编译成功后,执行安装
sudo make install
# 安装完成后,可以用以下命令验证valkey-cli是否可用:
valkey-cli –version
连接到Valkey查看键值
[ssm-user@ip-172-31-27-182 ec2-user]$ valkey-cli --tls -h clustercfg.juicefs-valkey.kjmaj8.apn2.cache.amazonaws.com -p 6379 -a juicefspasswordabc
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
clustercfg.juicefs-valkey.kjmaj8.apn2.cache.amazonaws.com:6379> KEYS *
4. 三种使用方式的实践
4.1 HostPath
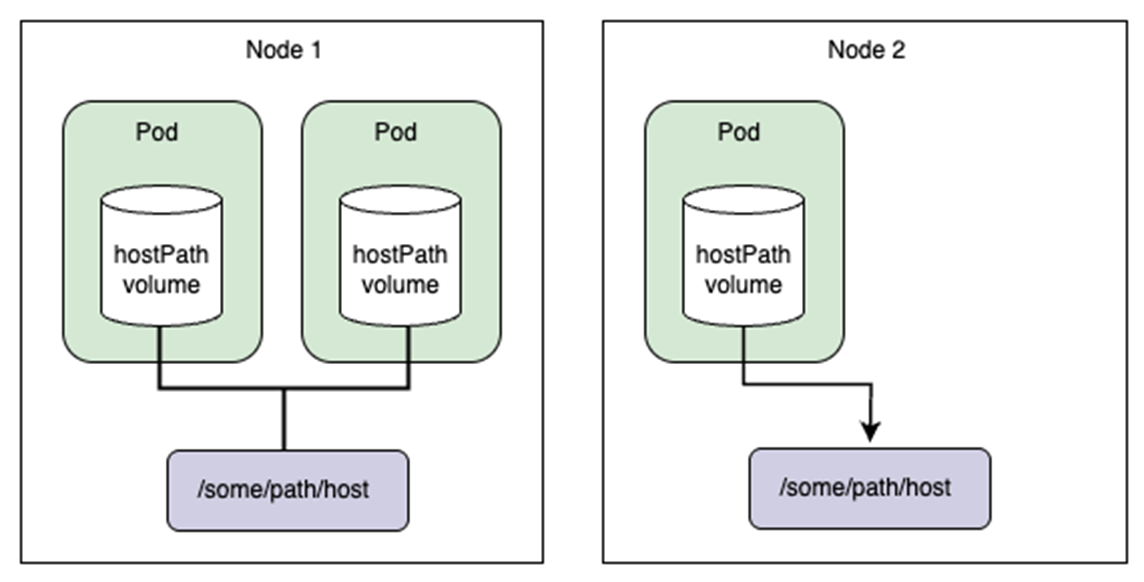
在Amazon EKS集群中使用JuiceFS,常见的方式是通过FUSE接口进行文件系统挂载。FUSE客户端需要运行在宿主机节点上,通常以DaemonSet形式部署,负责将后端对象存储挂载为节点上的本地目录。当Pod访问该文件系统时,通常采用HostPath卷方式,将宿主机上的FUSE挂载目录直接映射至容器内。
4.1.1 添加IAM策略
找到现有NodeInstanceRole,关联“准备IAM策略”中的juicefs-policy
4.1.2 Pod 配置示例(直接访问挂载目录)
假设节点上 JuiceFS 已挂载路径为 /mnt/juicefs/,直接使用 ls 查看该目录
apiVersion: v1
kind: Pod
metadata:
name: juicefs-hostpath
spec:
containers:
- name: juicefs-app
image: busybox
command: ["/bin/sh", "-c", "ls /mnt/juicefs && sleep 3600"] # 列出挂载目录内容后休眠,方便调试查看
volumeMounts:
- name: juicefs-volume
mountPath: /mnt/juicefs
volumes:
- name: juicefs-volume
hostPath:
path: /mnt/juicefs/ # JuiceFS 在节点上的挂载目录
type: Directory
kubectl get nodes # 确认节点状态
kubectl apply -f juicefs-hostpath.yaml # 创建pod
kubectl get pod juicefs-hostpath-example # 检查 Pod 状态
[ec2-user@ip-172-31-27-182 ~]$ kubectl get pod
NAME READY STATUS RESTARTS AGE
backend-655f66b77-94jds 1/1 Running 0 238d
frontend-64db969c4c-wfstf 1/1 Running 0 238d
juicefs-hostpathe 1/1 Running 0 20s
php-apache-77b9d477b8-9t7qn 1/1 Running 0 236d
kubectl exec -it juicefs-hostpath-example -- sh # 进入容器验证
ls -l /mnt/juicefs
[ec2-user@ip-172-31-27-182 ~]$ kubectl exec -it juicefs-hostpath -- sh
/ # ls -l /mnt/juicefs
total 0
-rw-rw-r-- 1 1001 1001 0 Aug 4 14:58 test.txt
4.1.3 并发的考虑
对于多客户端同时挂载读写同一个文件系统的情况,JuiceFS 提供关闭再打开(close-to-open)一致性保证,即当两个及以上客户端同时读写相同的文件时,客户端 A 的修改在客户端 B 不一定能立即看到。但是,一旦这个文件在客户端 A 写入完成并关闭,之后在任何一个客户端重新打开该文件都可以保证能访问到最新写入的数据,不论是否在同一个节点。
4.2 CSI Driver
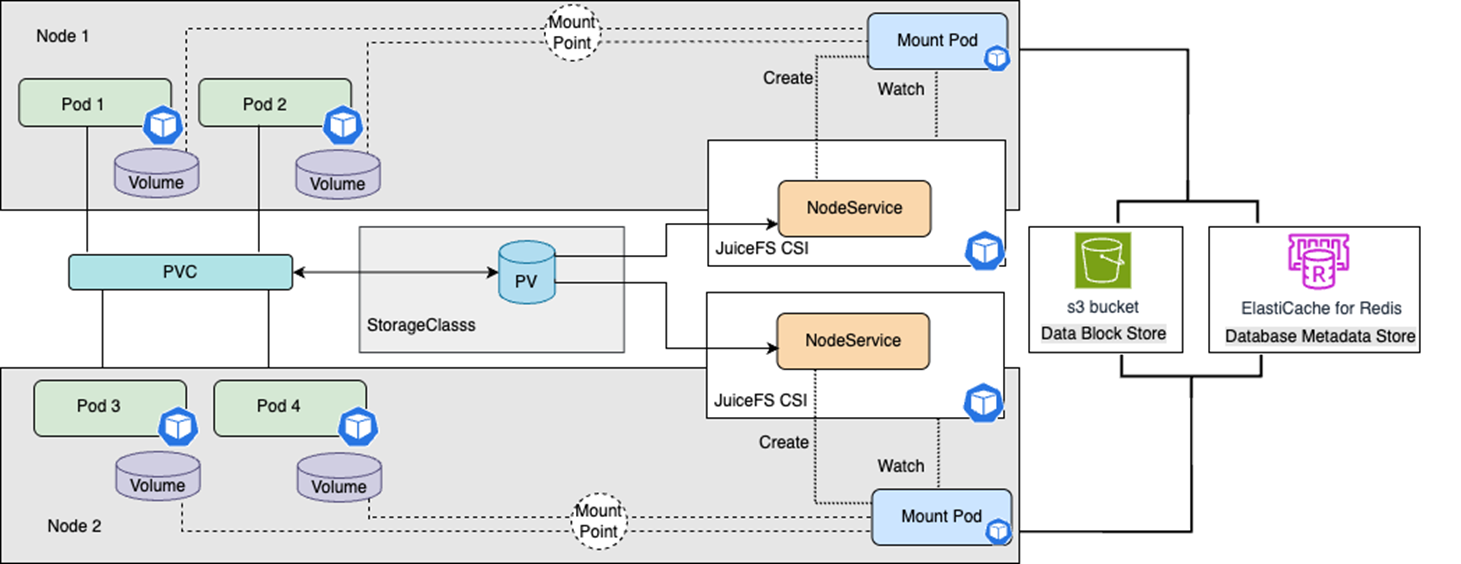
除了上述传统的hostPath方式,在Kubernetes下标准化的做法是使用JuiceFS的CSI驱动,在Amazon EKS中实现对JuiceFS存储的动态管理和挂载。 JuiceFS CSI Driver将底层复杂的 FUSE 管理抽象成 Kubernetes 原生资源(PVC、PV、StorageClass),它部署在集群中,包括控制器Pod和节点守护进程(DaemonSet),对外提供Kubernetes标准的PersistentVolume(PV)和PersistentVolumeClaim(PVC)接口。
JuiceFS CSI Driver 有两种主要的存储卷配置方式,本文讨论的是动态配置:
| 方式 |
说明 |
适用场景 |
优缺点 |
| 动态配置(Dynamic Provisioning) |
用户只需创建 StorageClass 和 PersistentVolumeClaim (PVC),Kubernetes 会根据 StorageClass 自动创建和绑定 PersistentVolume (PV),CSI Driver 会在 JuiceFS 文件系统中为每个 PVC 自动创建子目录进行隔离 |
多应用共享同一个 JuiceFS 文件系统时,且希望数据隔离,简化管理员管理时;大多数生产场景使用。 |
自动化程度高,支持数据隔离和多租户,减少了管理员手动维护PV的工作量。 |
| 静态配置(Static Provisioning) |
系统管理员预先创建好 PV 并绑定指定 JuiceFS 根目录或子目录,用户通过 PVC 绑定已有 PV |
已有大量 JuiceFS 数据;或简单快速验证 CSI 驱动时使用。 |
简单直接,适合单租户或测试环境,但缺乏自动资源编排和隔离能力。 |
4.2.1 添加IAM策略
建议使用 IAM Roles for Service Accounts (IRSA) 方式,安全且符合云原生最佳实践,JuiceFS CSI Controller Pod 在相应的命名空间使用的服务账户就自动拥有了访问 AWS 资源的权限。
4.2.2 安装配置过程
- 配置过程如下所示:
| 步骤 |
目的 |
| 创建ServiceAccount |
JuiceFS Driver Pod 能够安全地调用这些 API |
| 安装 JuiceFS CSI Driver |
用动态方式(Dynamic Provisioning)部署 JuiceFS CSI Driver |
| 创建Kubernetes Secret |
存储访问JuiceFS的配置信息 |
| 创建 StorageClass |
提供一个简单申领持久化存储(PVC)的标准方式 |
| 创建 PVC 并绑定 StorageClass |
为应用程序动态的申领和获取持久化存储资源 |
| 创建测试Pod |
测试是否可以正常访问juicefs |
- EKS 集群已开启 OIDC 提供商(OIDC provider),可使用命令查看
- 创建ServiceAccount
# 附加“环境准备”章节的安全策略juicefs-policy(替换YOUR_POLICY_ARN)
eksctl create iamserviceaccount \
--name juicefs-csi-controller-sa \
--namespace kube-system \
--cluster three-tier-cluster \
--attach-policy-arn arn:aws:iam::1234567890:policy/juicefs-policy \
--override-existing-serviceaccounts \
--approve
# 检查已附加的策略
aws iam list-attached-role-policies --role-name JuiceFS-CSI-Driver-Role
- 安装 Helm(如果未安装)
curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash
- 添加 JuiceFS Helm 仓库
helm repo add juicefs https://charts.juicefs.com
helm repo update
- 创建 JuiceFS CSI Driver 配置文件 values.yaml,用动态方式(Dynamic Provisioning)部署 JuiceFS CSI Driver,这段 values.yaml 的基础配置示例如下,可以根据使用场景做调整和补充:
kubeletDir: "/var/lib/kubelet"
mountMode: "process" # 这里为 process 模式
image:
repository: "juicedata/juicefs-csi-driver"
tag: "v0.26.4"
webhook:
certManager:
enabled: false
provisioner:
enabled: true # 开启动态 Provisioner, 支持自动创建 PV 和挂载 JuiceFS 子目录
controller:
resources:
limits:
cpu: 1000m
memory: 512Mi
requests:
cpu: 200m
memory: 256Mi
node:
resources:
limits:
cpu: 500m
memory: 256Mi
requests:
cpu: 100m
memory: 128Mi
- 生成这个 values.yaml 文件后,用 Helm 安装,安装 JuiceFS CSI Driver
helm upgrade --install juicefs-csi-driver juicefs/juicefs-csi-driver -n kube-system -f values.yaml
- 创建Kubernetes Secret,因为已经配置了IRSA ,此处access-key 和secret-key留空
apiVersion: v1
kind: Secret
metadata:
name: juicefs-secret
namespace: kube-system
type: Opaque
stringData:
name: juicefs-apn2 #之前创建的juicefs
metaurl: "rediss://default:juicefspasswordabc@clustercfg.juicefs-valkey.kjmaj8.apn2.cache.amazonaws.com:6379/1"
storage: s3
bucket: "https://s3.ap-northeast-2.amazonaws.com/juicefs-demo-eks"
access-key: ""
secret-key: ""
- 创建StorageClass并引用Kubernetes Secret
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: juicefs-csi
provisioner: csi.juicefs.com
parameters:
# 引用 Secret
csi.storage.k8s.io/provisioner-secret-name: juicefs-secret
csi.storage.k8s.io/provisioner-secret-namespace: kube-system
csi.storage.k8s.io/node-publish-secret-name: juicefs-secret
csi.storage.k8s.io/node-publish-secret-namespace: kube-system
reclaimPolicy: Delete
volumeBindingMode: Immediate
- 创建 PVC 并绑定 StorageClass
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: juicefs-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
storageClassName: juicefs-csi
- 创建测试Pod
apiVersion: v1
kind: Pod
metadata:
name: juicefs-test
spec:
containers:
- name: app
image: alpine:latest # 轻量级测试镜像
command: ["sh", "-c", "echo 'JuiceFS Test' > /data/juicefs.txt && sleep 3600"]
volumeMounts:
- name: juicefs-pvc
mountPath: /data # 挂载路径
volumes:
- name: juicefs-pvc
persistentVolumeClaim:
claimName: juicefs-pvc # 必须与当前的PVC名称一致
4.2.3 验证过程
# 查看 CSI Driver Pod 运行状态:
kubectl get pods -n kube-system -l app=juicefs-csi-driver
#创建 Pod 并进入容器,测试读写挂载目录:
kubectl exec -it juicefs-app -- sh
touch /data/testfile
ls -l /data/testfile
4.2.4 CSI Driver和HostPath的特性比较
| 特性 |
CSI Driver |
手动 FUSE (DaemonSet) |
| 集成度 |
原生 Kubernetes 方式,自动化 |
需手动或脚本管理 |
| 生命周期 |
自动挂载/卸载、清理 |
手动管理,易泄露 |
| 配置方式 |
动态配置 StorageClass |
静态配置 (手动PV) |
| 隔离性 |
强,使用独立 Mount Pod |
弱,通常共享挂载点 |
| 安全性 |
高,IAM Role for Service Account on Pod |
低,通常需特权模式 |
| 多版本/配置 |
支持,不同StorageClass不同配置 |
困难,节点共享配置 |
| 可观测性 |
高,标准 Pod 日志监控 |
低,需登录节点排查 |
4.2.5 模型训练的场景
请参考代码示例,在EKS环境下,使用Juice CSI Driver,通过PyTorch构建端到端的自动驾驶神经网络。该网络由CNN特征提取器和全连接控制预测器组成,能够直接从图像输入预测车辆的转向、油门和刹车控制信号。训练完成后,会保存模型权重文件、训练历史记录和损失曲线图。
4.3 S3 Gateway
JuiceFS S3 Gateway 基于 MinIO Gateway 开发,实现了S3 API,允许用户通过任何兼容 S3 的客户端访问和管理 JuiceFS 文件系统中的数据。它能够将 JuiceFS 文件系统以 S3 协议的形式对外提供服务,使用户能够构建独立的文件服务,用于安全地共享内部文件。
面对复杂的权限与时效性管理需求,该方案不仅满足基本共享要求,还通过 Security Token 机制实现了对共享链接时效性的精细控制。这一机制有效防止了数据被恶意抓取的风险,进一步增强了文件共享的安全性。
4.3.1 创建和执行Dockerfile
1.创建Dockerfile,当前官方版本镜像不能正常使用,需要新建Docker镜像
FROM ubuntu:22.04
# 设置JuiceFS版本
ARG JUICEFS_VERSION=1.3.0
# 安装依赖
RUN apt-get update && apt-get install -y \
ca-certificates \
curl \
fuse3 \
&& rm -rf /var/lib/apt/lists/*
# 下载并安装JuiceFS
RUN set -eux; \
ARCH=$(uname -m); \
case "${ARCH}" in \
x86_64) ARCH=amd64 ;; \
aarch64) ARCH=arm64 ;; \
*) echo "unsupported architecture: ${ARCH}"; exit 1 ;; \
esac; \
curl -fSL "https://github.com/juicedata/juicefs/releases/download/v${JUICEFS_VERSION}/juicefs-${JUICEFS_VERSION}-linux-${ARCH}.tar.gz" -o juicefs.tar.gz; \
tar -xzf juicefs.tar.gz; \
install juicefs /usr/local/bin/juicefs; \
rm juicefs.tar.gz juicefs; \
juicefs version
# 创建用户和目录
RUN groupadd -r juicefs && useradd -r -g juicefs juicefs
RUN mkdir -p /var/juicefs && chown juicefs:juicefs /var/juicefs
WORKDIR /var/juicefs
USER juicefs
EXPOSE 9000
# 设置入口点,支持自定义参数
ENTRYPOINT ["juicefs"]
CMD ["gateway", "--help"]
2.构建Docker镜像
#!/bin/bash
# JuiceFS Gateway镜像构建脚本
set -e
# 配置变量
IMAGE_NAME="juicefs-gateway"
TAG="latest"
JUICEFS_VERSION="1.3.0"
echo "开始构建JuiceFS Gateway镜像..."
echo "JuiceFS版本: v$JUICEFS_VERSION"
# 构建镜像
docker build \
--build-arg JUICEFS_VERSION=$JUICEFS_VERSION \
-t $IMAGE_NAME:$TAG .
echo "镜像构建完成: $IMAGE_NAME:$TAG"
# 测试镜像基本功能
echo "测试镜像功能..."
docker run --rm $IMAGE_NAME:$TAG version
docker run --rm $IMAGE_NAME:$TAG gateway --help | head -5
echo "构建和测试完成!"
3.上传镜像到AWS ECR
set -e
# 配置变量
IMAGE_NAME="juicefs-gateway"
TAG="latest"
AWS_ACCOUNT_ID="1234567890" # 替换AWS账户ID
AWS_REGION="ap-northeast-2" # 根据EKS区域调整
ECR_REPO_NAME="juicefs-gateway"
echo "登录到AWS ECR..."
# 获取ECR登录密码并登录
aws ecr get-login-password --region $AWS_REGION | docker login --username AWS --password-stdin $AWS_ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com
echo "检查ECR仓库..."
# 检查仓库是否存在,如果不存在则创建
if ! aws ecr describe-repositories --repository-names $ECR_REPO_NAME --region $AWS_REGION > /dev/null 2>&1; then
echo "创建ECR仓库: $ECR_REPO_NAME"
aws ecr create-repository \
--repository-name $ECR_REPO_NAME \
--region $AWS_REGION \
--image-scanning-configuration scanOnPush=true \
--image-tag-mutability MUTABLE
fi
echo "标记镜像..."
# 标记镜像用于ECR
docker tag $IMAGE_NAME:$TAG $AWS_ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com/$ECR_REPO_NAME:$TAG
echo "推送镜像到ECR..."
# 推送镜像到ECR
docker push $AWS_ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com/$ECR_REPO_NAME:$TAG
echo "镜像推送完成!"
echo "ECR镜像地址: $AWS_ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com/$ECR_REPO_NAME:$TAG"
# 显示仓库信息
echo "ECR仓库信息:"
aws ecr describe-repositories --repository-names $ECR_REPO_NAME --region $AWS_REGION --query 'repositories[0].repositoryUri' --output text
4.3.2 在AWS EKS上部署 JuiceFS Gateway 并通过 Ingress 方式暴露给内部团队
- 部署过程如下表所示:
| 步骤 |
目的 |
| 安装 AWS Load Balancer Controller |
EKS支持ALB Ingress |
| 创建 Deployment |
定义并部署应用程序 Pod(JuiceFS 相关组件或应用) |
| 创建 Service |
暴露Pod 端口给ALB |
| 创建 IngressClass |
关联AWS ALB Controller |
| 创建 Ingress |
配置路由规则给Service |
| 获取ALB地址并访问 |
内部客户访问服务 |
- 具体步骤如下:
确保 EKS 集群已经部署了 Ingress Controller,这里推荐使用AWS ALB Ingress Controller,具体步骤参考ALB Ingress Controller 官方文档。
定义并部署应用程序 Pod,指定镜像的ECR地址,ElastiCache for Valkey 的配置端点,s3 gateway的根用户名和访问密钥。
apiVersion: apps/v1
kind: Deployment
metadata:
name: juicefs-s3-gateway
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app: juicefs-s3-gateway
template:
metadata:
labels:
app: juicefs-s3-gateway
spec:
containers:
- name: juicefs-s3-gateway
image: 1234567890.dkr.ecr.ap-northeast-2.amazonaws.com/juicefs-gateway:latest # 指定ECR的地址
env:
- name: MINIO_ROOT_USER
value: "admin"
- name: MINIO_ROOT_PASSWORD
value: "password"
command: ["juicefs"]
args:
- "gateway"
- "rediss://default:juicefspassword@clustercfg.juicefs-valkey.kjmaj8.apn2.cache.amazonaws.com:6379/1" # 指定valkey访问链接的用户名和口令
- "0.0.0.0:9000"
ports:
- containerPort: 9000
- 创建 Service(ClusterIP 或 NodePort)
为了让 Ingress 能访问 Pod,需要先创建一个对应的 Service,暴露 JuiceFS Gateway 的 9000 端口。示例 Service YAML如下:
apiVersion: v1
kind: Service
metadata:
name: juicefs-s3-gateway
namespace: kube-system
spec:
selector:
app: juicefs-s3-gateway
ports:
- port: 9000
targetPort: 9000
protocol: TCP
type: NodePort # ALB 需要用 NodePort 或 LoadBalancer 类型
- 创建 IngressClass 资源,绑定 ALB
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: alb
annotations:
ingressclass.kubernetes.io/is-default-class: "true" # 设置默认 ingressclass(非必需)
spec:
controller: eks.amazonaws.com/alb
parameters:
apiGroup: eks.amazonaws.com
kind: IngressClassParams
- 创建 Ingress 资源,将流量路由到 Service
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: juicefs-s3-gateway-ingress
namespace: kube-system
annotations:
kubernetes.io/ingress.class: alb
spec:
rules:
- http:
paths:
- path: /*
pathType: ImplementationSpecific
backend:
service:
name: juicefs-s3-gateway
port:
number: 9000
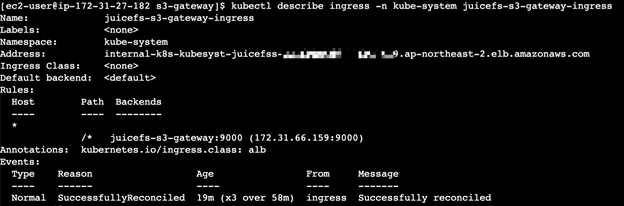
等待几分钟后,通过以下命令查看 ALB 地址(DNS 名称)
kubectl get ingress -n kube-system juicefs-s3-gateway-ingress -o jsonpath='{.status.loadBalancer.ingress[0].hostname}'
内部客户可以直接使用这个 ALB 地址访问 JuiceFS Gateway
请参考Juicefs官方文档身份和访问控制
5. 总结
本文主要讲述了在AWS EKS环境下构建JuiceFS的三种不同的使用方式:HostPath,CSI Driver和S3 Gateway,并首次对 JuiceFS CSI Driver on EKS部分进行了系统性描述。在生产环境下可以结合自身的需求选择适合的JuiceFS架构,满足海量数据下的高效AI训练与推理需求。
AWS FSx for Lustre是亚马逊云科技提供的一项全托管的高性能并行文件存储服务。它的核心设计目标是为运行在 AWS 上的计算密集型工作负载提供极致的吞吐量,和满足低延迟高性能的需求。AWS FSx for Lustre 与 Intelligent Tiering 的结合,更是显著降低长期存储成本。在实际架构选型中,选择开源版 JuiceFS还是选择 AWS FSx for Lustre或AWS FSx for Lustre + Intelligent Tiering,可以参考下表:
| 对比维度 |
开源版 JuiceFS |
AWS FSx for Lustre |
FSx for Lustre + Intelligent Tiering |
| 部署纬度 |
支持跨云、混合云部署 |
仅限 AWS 区域内使用 |
仅限 AWS 区域内使用 |
| 部署方式 |
需要依赖外部元数据引擎(Redis/MySQL等) |
不依赖外部元数据引擎,与EKS集群独立存在 |
不依赖外部元数据引擎,自动化分层管理 |
| 成本效益 |
利用低成本对象存储,缓存加速,性价比高 |
全托管服务,费用略高 |
智能分层大幅降低存储成本,热数据高性能访问 |
| 存储协议支持 |
支持POSIX、S3 Gateway、HDFS 等 |
支持 POSIX,与 S3 可双向同步 |
支持 POSIX,自动S3分层,透明访问 |
| 管理/运维复杂度 |
需要维护文件系统与元数据库,复杂度高 |
托管式服务,管理成本低 |
零运维,自动化数据生命周期管理 |
| 数据分层策略 |
手动配置缓存策略,需要运维介入 |
手动管理S3导入/导出 |
基于访问模式自动分层,无需人工干预 |
| 性能表现 |
通过缓存实现高性能读写,适合数据密集场景 |
极低延迟和高吞吐,专为 HPC 和密集型 AI 训练优化 |
热数据毫秒级访问,冷数据秒级恢复,性能与成本平衡 |
| 弹性扩展 |
需要预先规划缓存容量 |
支持动态扩展,但需要手动管理 |
自动根据访问模式调整存储层级,无限扩展 |
| 自动驾驶场景优势 |
适合多云环境下的数据湖场景 |
高性能训练数据访问,模型推理加速 |
训练数据自动分层,历史数据低成本存储,实时数据高性能访问 |
| 数据生命周期管理 |
需要自行开发脚本管理 |
手动设置S3同步策略 |
智能识别数据访问模式,自动优化存储成本 |
| 适用业务场景 |
AI 训练、数据湖、容灾备份、低成本扩展 |
高性能计算、AI训练、原生云上应用 |
大规模自动驾驶数据处理、智能训练数据管理、成本敏感的AI工作负载 |
6. 参考资料
[1] 多云架构、 POSIX 全兼容、低运维的统一存储
[2] 性能评估指南
[3] JuiceFS 元数据引擎选型指南
[4] JuiceFS CSI Driver 架构设计详解
[5] JuiceFS CSI 驱动遵循 CSI 规范
[6] JuiceFS 与 Amazon MemoryDB 夯实企业数据基石
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者