亚马逊AWS官方博客
Category: Storage

Amazon EFS 目录级配额监控:多租户 SaaS方案
Amazon EFS 不提供原生目录级配额能力。本文基于 AWS Lambda 双层 fan-out 架构与 Amazon EventBridge,给出按客户/项目两级目录粒度的存储用量监控方案,涵盖架构设计、完整代码、部署命令及成本分析。

AWS 一周综述:纽约峰会回顾、河内 Local Zone、Bedrock 中的 Grok 4.3、降价等(2026 年 6 月 22 日)
纽约峰会回顾、河内 Local Zone、Bedrock 中的 Grok 4.3、降价等
2026 年纽约 AWS Summit 的热门公告
今天在纽约市 AWS Summit 上,AWS 代理式人工智能副总裁 Swami Sivasubramanian 发表了当天的主题演讲。
Amazon S3 注释:将丰富的可查询上下文直接附加到您的对象
今天,我们宣布为 Amazon Simple Storage Service(Amazon S3)推出一项名为“注释”的全新元数据功能,该功能让您可以直接为对象挂载海量、丰富的业务上下文。您最多可以为单个对象存储 1000 个命名注释,单条注释的大小上限为 1MB,单对象注释的总大小最高为 1GB,支持 JSON、XML、YAML、纯文本等多种灵活格式。您可以随时修改、删除注释,无需重写对象,从而轻松实时更新对象上下文。
AWS 一周综述:Amazon Bedrock 中的 Claude Mythos 预览版、AWS 代理注册表等(2026 年 4 月 13 日)
Amazon Bedrock 中的 Claude Mythos 预览版、AWS 代理注册表等
如何在中国区使用 Amazon CloudFormation 堆栈集批量管理多账号 Amazon Backup备份计划
本篇文章主要介绍了如何结合Amazon CloudFormation的堆栈集功能实现Amazon Backup计划的统一部署及后续管理。用户可以创建一份通用的备份计划模板,然后通过Amazon CloudFormation控制台为特定账号列表或整个组织、特定OU批量部署相同的备份计划。如后续备份计划有调整,也可通过在堆栈集中更换模板的方式更新所有账户下的备份计划。

推出 S3 Files:使 S3 存储桶能够以文件系统形式直接访问
Amazon S3 Files 正式推出。这是一款全新的文件系统,能够将任意 AWS 计算资源与 Amazon Simple Storage Service(Amazon S3)无缝连接。
AWS 一周综述:Amazon S3 推出 20 周年、Amazon Route 53 Global Resolver 正式推出等(2026 年 3 月 16 日)
二十年前的上周,Amazon S3 于 2006 年 3 月 14 日公开发布。虽然 Amazon Simple Storage Service 通常被认为是定义云基础设施的基础存储服务,但最初的简单对象存储服务已发展成为范围和规模要大得多的服务。
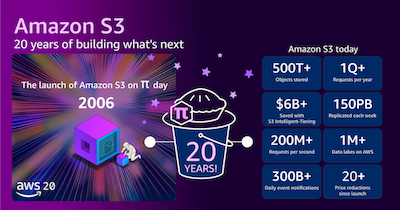
Amazon S3 二十周年:回望初心,共筑未来
二十年前的今天,即 2006 年 3 月 14 日,Amazon Simple Storage Service(Amazon S3)悄然上线。
为 Amazon S3 通用存储桶引入账户区域命名空间
今天,我们宣布推出 Amazon Simple Storage Service(Amazon S3)的一项新功能,您可以使用该功能在自己的账户区域命名空间中创建通用存储桶,从而在数据存储需求规模和范围增长时简化存储桶的创建和管理。您可以跨多个 AWS 区域创建通用存储桶名称,确保所需的存储桶名称始终可供您使用。