亚马逊AWS官方博客
使用 JDBC 访问 Amazon Athena 的参数调优实践
1 背景介绍
Amazon Athena 是一种交互式查询服务,通过 Athena 我们能够轻松使用标准 SQL 直接分析 Amazon S3 中的数据。用户只需在 AWS 管理控制台中单击几下,即可将 Athena 指向自己在 S3 中存储的数据,并使用标准 SQL 执行临时查询获取结果。Athena 采用无服务器的设计,可以自动扩展并执行并行查询,因而对于大型数据集和复杂查询也可快速获取结果。 用户通常可以使用 Athena 处理日志、执行即席分析以及运行交互式查询。
除了通过亚马逊云科技云控制台执行交互查询外,Amazon Athena 还可以在 Glue 中通过 CATS(CREATE TABLE AS SELECT)方法辅助ETL过程,同时还可以和各种分析类报表和应用相结合来展示数据,这时候往往需要通过JDBC进行连接访问。由于亚马逊云科技中国区和全球的其他区域是隔离的, 因而在访问中国区时会有一些特殊的设置,另外 Athena JDBC 特殊的工作机制,需要我们根据实际情况对JDBC的性能进行适当的调优。
2 查询性能测试
2.1 通过 SQL Workbench 连接中国区 Athena 服务
在本实验中,我们在 SQL Workbench中,通过JDBC来访问Amazon Athena服务。由于中国区和全球的其他区域是相互隔离的,其JDBC访问的Athena服务终端节点域名不同,因此在JDBC URL中除了需要配置访问全球区的标准参数AwsRegion,还需要额外配置参数EndpointOverride来指定区域终端节点。EndpointOverride 参数的终端节点格式在中国区为 athena.aws-region.amazonaws.com.cn。例如访问中国宁夏区域的访问链接如下所示:
jdbc:awsathena://AwsRegion=cn-northwest-1;EndpointOverride=athena.cn-northwest-1.amazonaws.com.cn:443;
如果您尚未在SQK WorkBench中设置Athena JDBC驱动,您需要下载驱动,并打开SQL Workbench 通过File → Manage Drivers进行JDBC驱动设置,如下图所示,具体可参照本文所附参考链接。本测试中采用AthenaJDBC 4.2 兼容版本,需要JDK8.0或者更高版本。
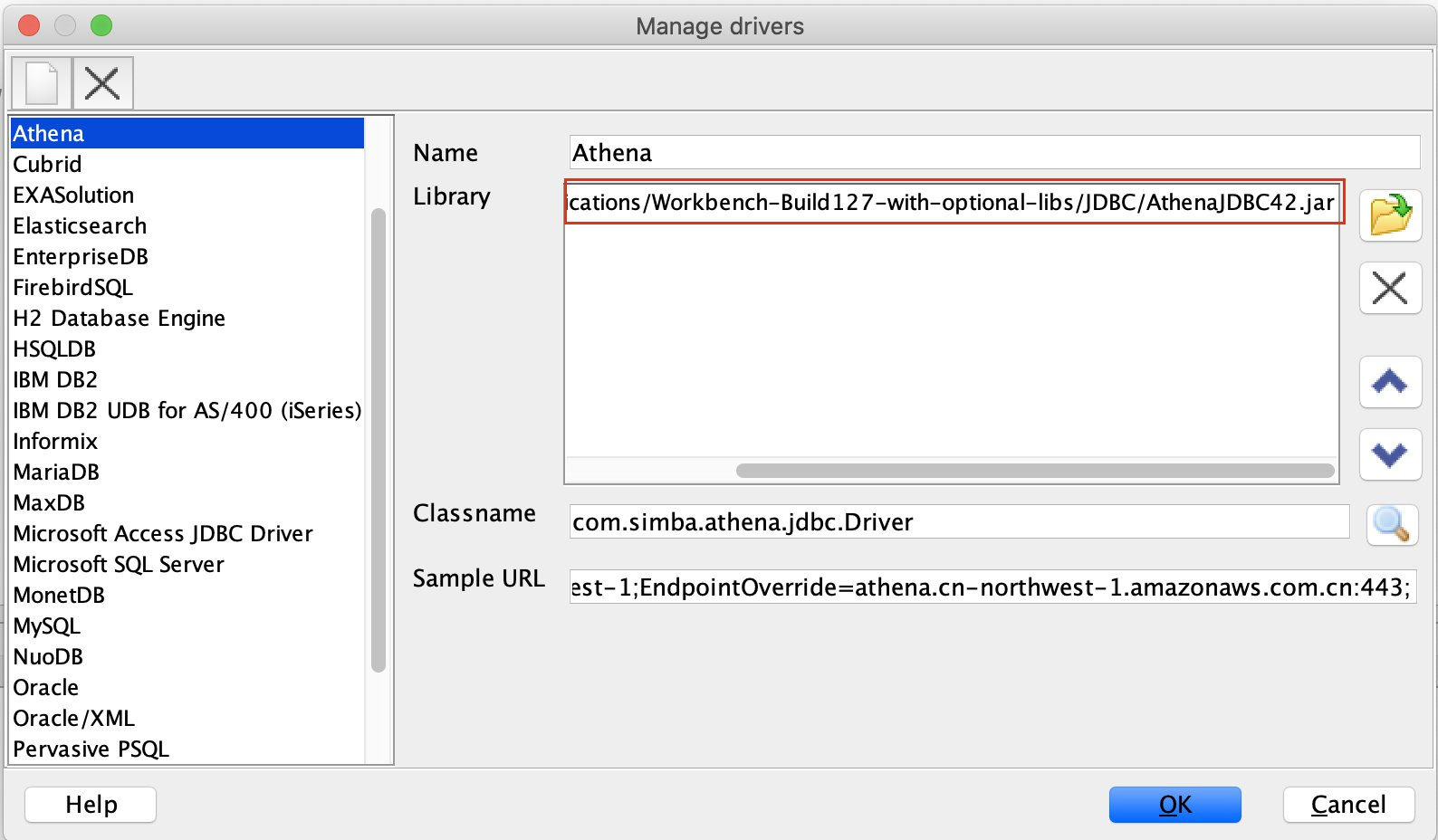
在配置JDBC驱动后,可以创建JDBC连接 ,如下图所示,点击菜单File → Connection Window,按如下图所示进行AthenaConnection配置 :

具体配置说明如下:
- Driver:Athena JDBC 驱动类名为
com.simba.athena.jdbc.Driver - URL: 访问 JDBC 的URL,需要显式指定中国区的服务终端节点:
jdbc:awsathena://AwsRegion=cn-northwest-1;EndpointOverride=athena.cn-northwest-1.amazonaws.com.cn:443 - UserName: 您的AWS账号的AccessKey
- Password: 您的AWS账号的Secret Access Key
以上JDBC连接中,AccessKey和Secret Access Key对应的亚马逊云科技用户需要有AWSQuicksightAthenaAccess权限,并对查询结果存储桶有写入权限(AmazonS3FullAccess), 或者直接授予AmazonAthenaFullAccess权限。
点击按钮 Extended Properties 可配置其他的参数如:S3OutputLocation用来存放查询结果的S3存储桶,该存储桶的配置和Athena 控制台中的配置一致,Workgroup默认为primary。如下图所示:

2.2 数据准备和查询
我们以美国交通事故的开放数据为测试数据,访问https://catalog.data.gov/dataset/traffic-collision-data-from-2010-to-present并下载CSV(Comma Separated Values File )格式数据 Traffic_Collision_Data_from_2010_to_Present.csv,下载后上传到 S3 源数据存储桶 athena-test-zhanla-001的traffic_collision文件夹中。

登录Athena控制台,登录用户要求有AmazonAthenaFullAccess权限。通过在查询编辑器查询窗口输入如下命令,运行并创建一个新的数据库traffic_db。
create database traffic_db
在数据库的下拉栏里选择新建的 traffic_db,并在查询窗口里执行如下命令基于S3文件创建新表:
2.3 查询比较分析
数据准备好以后我们在Athena查询窗口里输入如下的查询语句进行查询:
select * from traffic_db.traffic_collision_data
order by date_reported, date_occurred, area_id, crime_code limit 1000
我们在Athena的查询窗口可以看到Athena查询引擎运行的时间。本次测试中,Athena引擎执行时间为4.39秒。
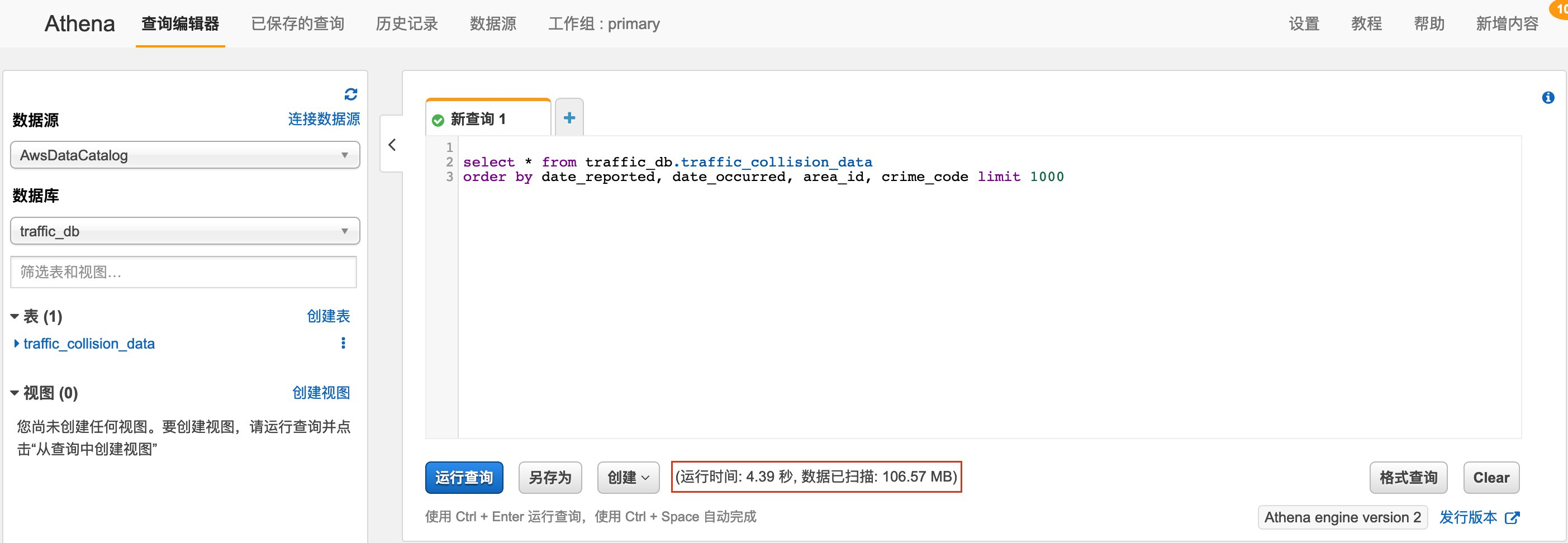
同样在SQL Workbench中执行该语句,得到如下结果,显示总用时为6.42秒。

我们在 SQL Workbench 里面进行10次查询,分别记录在 SQL Workbench 中终端查询的消耗时间和对应的 Athena 控制台中历史记录中查询引擎运行时间(如下图):
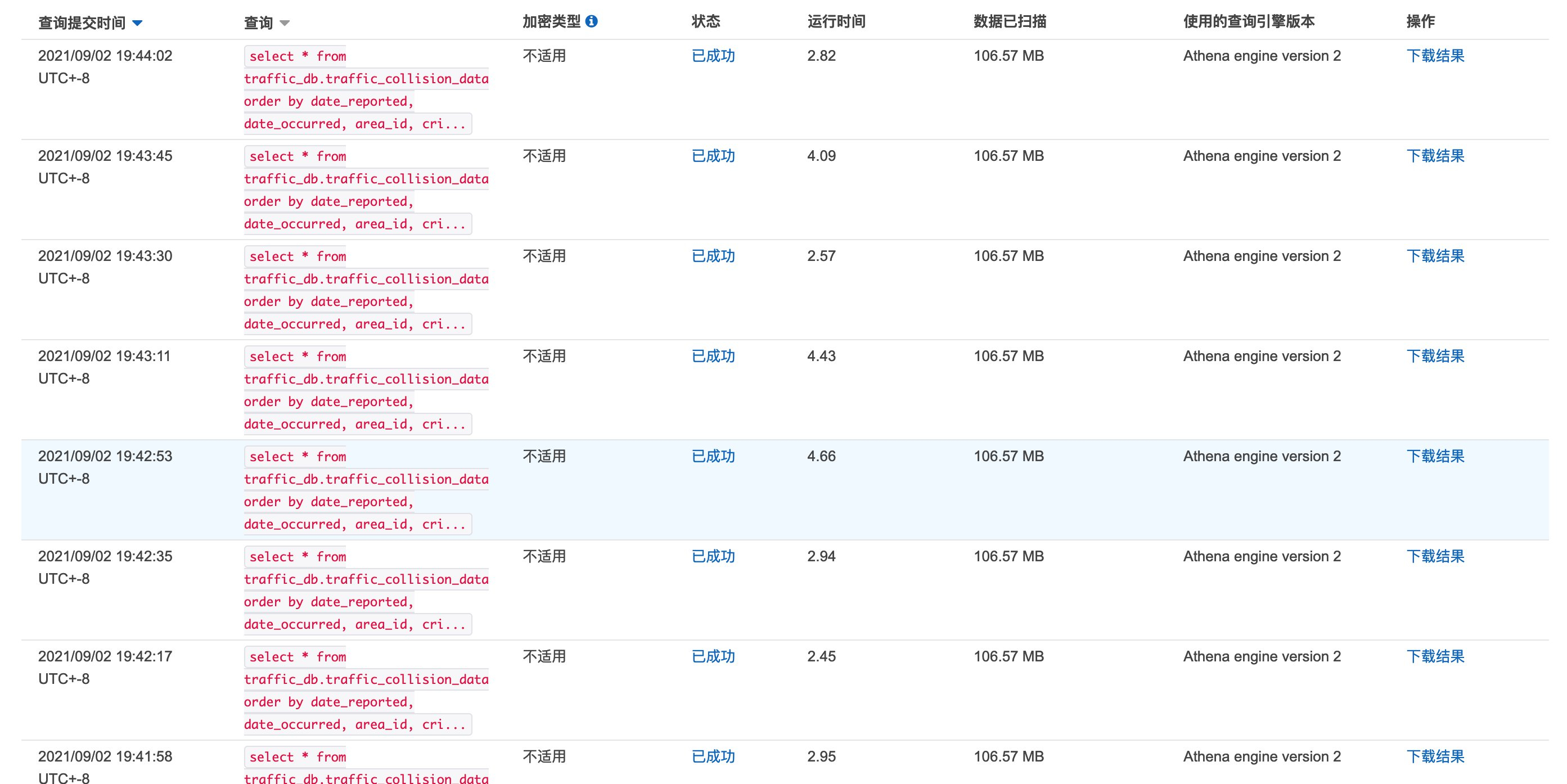
我们将SQL Workbench查询用时和Athena历史记录查询时间进行了对比,如下表所示。虽然通过SQL Workbench查询会有查询语句发起和查询结果返回的额外消耗,但是二者的时效差距明显。
| 查询时间比较 | 第1次 | 第2次 | 第3次 | 第4次 | 第5次 | 第6次 | 第7次 | 第8次 | 第9次 | 第10次 |
| SQL Workbench显示总查询时间 | 3.91 | 6.12 | 6.03 | 3.55 | 6.02 | 6.62 | 6.14 | 3.51 | 6.12 | 6.07 |
| Athena历史记录显示时间 | 2.5 | 3.06 | 2.95 | 2.45 | 2.94 | 4.66 | 4.43 | 2.57 | 4.09 | 2.82 |
通过对以上的实验数据分析,我们发现:
- 在SQL Workbench中的查询时间通常为3秒左右和6秒左右,没有出现过4秒或5秒的情况。
- 当Athena引擎本身的执行时间大于5秒的时候,无论Athena查询引擎本身的执行时间为多少,SQL Workbench的查询时间均为6秒多。
3 解决方案
在阅读了官方的文档后我们发现,Athena在运行的过程中会将查询结果存储到S3OutputLocation指定的S3存储桶当中,JDBC客户端会不断轮询该S3存储桶获取查询结果并下载到本地。由于轮询机制采用指数退避(Exponential backoff )的方法,从而导致了SQL Workbench端查询效率的明显波动。在Athena JDBC连接器中,对查询结果的轮询有几个重要的参数和默认值如下:
- MinQueryExecutionPollingInterval = 5 (ms), JDBC连接器的默认最小起始轮询时间间隔(毫秒)。
- MaxQueryExecutionPollingInterval = 1800000 (ms),JDBC连接器最大的轮询时间间隔(毫秒)。
- QueryExecutionPollingIntervalMultiplier = 2,指数退避中的乘数。
在以上参数设置下,JDBC连接器从最小轮询间隔(MinQueryExecutionPollingInterval )开始对服务器发起结果查询,如果Athena还没有返回结果,JDBC连接器会使用乘数(QueryExecutionPollingIntervalMultiplier)增加轮询间隔,直到达到 最大轮询时间间隔(MaxQueryExecutionPollingInterval)后,不再增加。然后,连接器继续使用此最大时间间隔对服务器进行轮询,直到返回查询结果。我们按照上面的设置,对整个过程的轮询间隔和总等待时间进行计算,如下表所示:
| 轮询的次数 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | … | n |
| 查询时间间隔(ms) | 5 | 10 | 20 | 40 | 80 | 160 | 320 | 640 | 1280 | 2560 | 5120 | 10240 | 20480 | 40960 | 81920 | … | 5*(n-1) |
| 总等待时间(ms) | 5 | 15 | 35 | 75 | 155 | 315 | 635 | 1275 | 2555 | 5115 | 10235 | 20475 | 40955 | 81915 | 163835 | … | 5*(2n-1) |
我们发现,如果JDBC连接器在2.555秒(2555毫秒)的轮询中,如果还查询不到结果,那么就会等待2.56秒(2560毫秒)才进行下一次轮询,而等到这一次轮询的结束的时候,查询总用时到了5.115秒(5115毫秒)。这和我们观察中的测试结果是一致的。针对这一情况我们在SQL Workbench中可以通过设置extended properties将MaxQueryExecutionPollingInterval 按照实际需求设置为合适值(例如20毫秒)后进行测试。
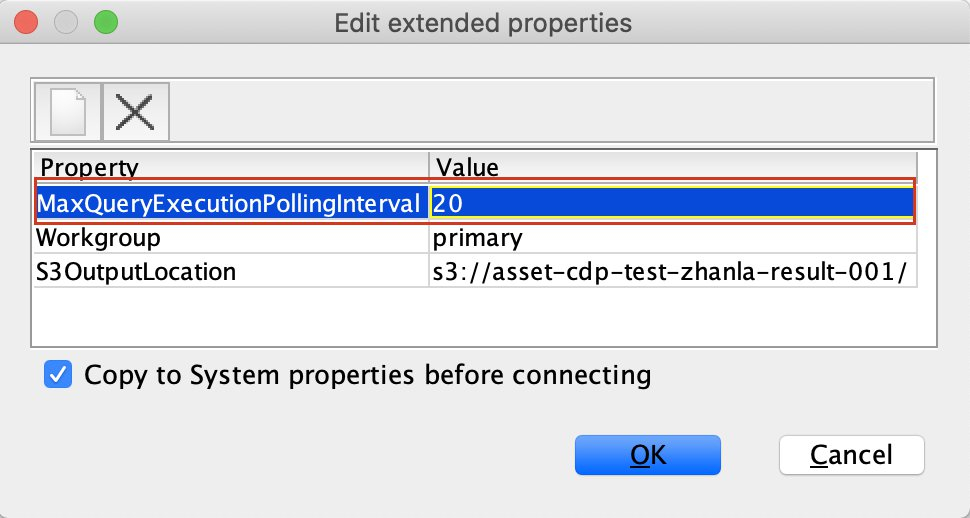
在重新配置参数后,我们进行同样的对比测试,测试结果如下表所示:
| 查询时间比较 | 第1次 | 第2次 | 第3次 | 第4次 | 第5次 | 第6次 | 第7次 | 第8次 | 第9次 | 第10次 |
| SQL Workbench显示总查询时间 | 3.87 | 4.67 | 3.73 | 4.62 | 4.17 | 4.74 | 4.03 | 3.59 | 3.73 | 3.34 |
| Athena历史记录显示时间 | 2.78 | 4.08 | 2.92 | 3.75 | 3.54 | 4.17 | 3.28 | 3.01 | 2.88 | 2.86 |
通过设置新的参数,使得SQL Workbench端的查询时间明显缩短并更加稳定,其相对于Athena查询引擎本身的时间更多的只消耗在查询请求提交和查询结果下载上,而不是不断延长的等待时间上。 我们可以通过下图来进一步分析在不同的场景下,参数修改带来的效率提升:

场景一和场景二都进行了四次轮询,而二者可以通过参数节省的时间却不同,场景一的查询执行时间正好刚比第四个轮询时间点长一点,因而通过修改缺省时间的空间大;相反,场景二的空间却不大。另外,在本实验中,我们通过设置JDBC连接参数MaxQueryExecutionPollingInterval来指定轮询的最大间隔,来保证 JDBC 终端的查询效率,但这同时也增加了JDBC客户端在查询时候的API调用次数,会造成API调用的费用增加。
实际上关于轮询的三个参数可以根据查询的实际时长的分布综合考虑,灵活制定,从而达到效率和成本的平衡。例如:
- 可以通过增加最小轮询间隔MinQueryExecutionPollingInterval来减少无用的轮询次数,但是这可能不适合低延迟的查询。
- 可以通过减小MaxQueryExecutionPollingInterval参数来避免最坏情况下(场景一)下的无效等待时间,但是会增加轮询次数。
- 通过修改QueryExecutionPollingIntervalMultiplier来确定查询等待时间的指数增长速度,甚至可以改为1,改为固定时间轮询。
上面同样的方法,在java程序中通过JDBC访问Athena,也可以采取同样类似设置,示例代码如下:
4 其他参数
在AthenaJDBC驱动的4.2版本中,支持很多的属性参数,可以通过参数设置Athena查询服务的登录认证方式, 查询结果是否加密,设置代理连接等,具体可以查看相关的JDBC手册,这里将其中的一些重要的参数列表如下:
| 参数名称 | 说明 | 默认值 |
| LogLevel | 可以根据需要来指定输出的日志级别,方便问题诊断;
范围为0-6, 数值越大,日志信息越详细,日志输出会影响应用的性能; 可以配合属性参数LogPath指定日志输入路径,以及UseAwsLogger使用; |
0 – 不输出日志 |
| LogPath | 日志输出目录,其中
AthenaJDBC_driver.log日志文件存储和连接无关的日志信息; AthenaJDBC_connection_[Number].log存储查询连接相关的信息; |
如果此参数没有设置或者设置错误,默认输出到标准输出控制台 |
| UseAwsLogger | 此属性指定连接器是否记录AWS API 调用;
1 – 如果启用日志记录,连接器会在连接器日志文件中记录AWS API 调用的日志输出; 0 – 连接器不记录 AWS API 调用; |
0 – 连接器不记录 AWS API 调用 |
| ConnectionTimeout | 建立连接的超时时间; | 10 (秒) |
| MaxErrorRetry | 遇到返回服务器错误的最大重试次数; | 10 |
| UseResultsetStreaming | 指定连接器是否使用Stream API来获取结果集:
1 – 使用Stream API获取结果集; 0 – 使用分页逻辑来获取结果集; |
1 – 使用StreamAPI 来获取结果集 |
| StreamingEndpointOverride | 当属性参数UseResultsetStreaming设置为1时,需要通过此参数设置对应的 Athena Stream服务端点。 | Athena连接端点对应的444端口 |
5 总结
Athena的JDBC驱动默认使用了指数减退法轮询Athena查询引擎输出到S3的结果,在通过JDBC访问Athena的过程中,对于时效性比较强的应用可以通过修改相应的参数来提高查询的效率,不过在增加查询效率的同时,会同样增加API的调用费用,所以需要根据场景综合考虑。另外,在中国区通过JDBC连接Athena查询需要通过EndpointOverride显式指定区域终端节点,才能成功连接。
6 参考链接
https://docs.aws.amazon.com/athena/latest/ug/connect-with-jdbc.html
https://docs.aws.amazon.com/athena/latest/ug/language-reference.html
https://www.sql-workbench.eu/downloads.html
https://catalog.data.gov/dataset/traffic-collision-data-from-2010-to-present