亚马逊AWS官方博客
Redshift 性能调优2 – 经典调整(Classic Resize)
当Redshift集群的整体性能出现瓶颈的时候,用户可以通过调整Redshift集群节点的机型大小、或者添加节点的数量来扩充集群的计算能力。但是用户在调整节点机型的大小或者数量的同时,也需要注意:在某些情况下需要通过弹性调整(Elastic Resize)或者经典调整(Classic Resize)来让数据重新分布,避免数据在各个节点上的分布不均匀而导致各个节点资源使用不均的问题。
弹性调整(Elastic Resize)或者经典调整(Classic Resize)的操作也适用于变更机器实例类型的场景,最常见的,比如将DC2 机型调整为RA3机型。
本篇博客主要将从Redshift的底层设计出发,解读为什么在调整节点的机型或数量之后需要做Resize操作,以及用户案例分享。
Redshift的底层设计
首先,我们先来看一下Redshift的底层设计。
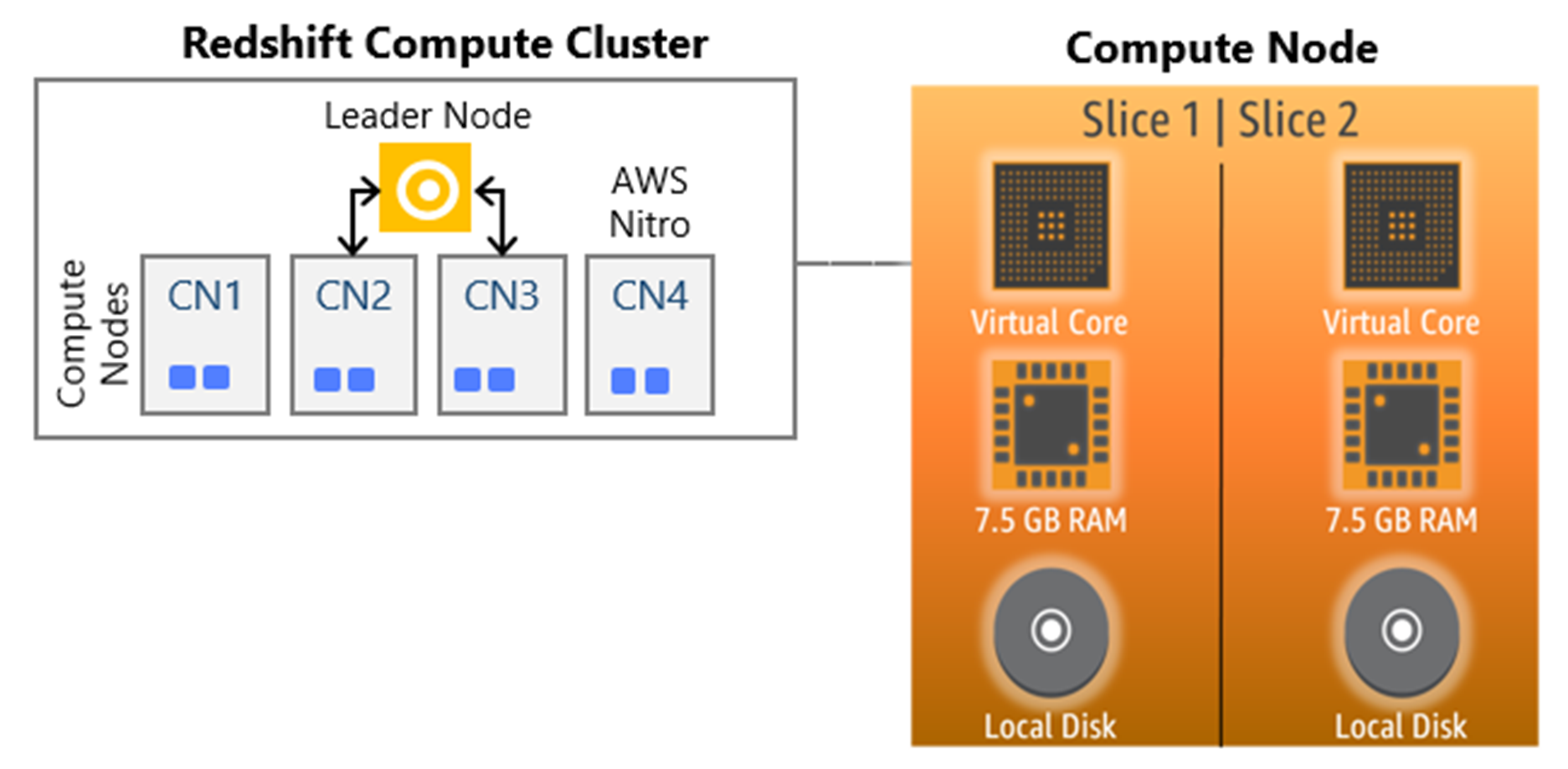 |
如以上的架构设计所示,Amazon Redshift 数据仓库的核心基础设施组件如下:
集群(Cluster):包含一个或多个计算节点(Compute Node)。
领导节点(Leader Node):当集群预置有两个或更多计算节点,则会有一个额外的领导节点(Leader Node)来协调这些计算节点并处理外部通信。用户不需为领导节点付费。领导节点负责作为用户访问集群的入口,存储元数据,编译查询并协调并行 SQL 处理。
计算节点(Compute Node):负责实际的查询执行和数据处理。
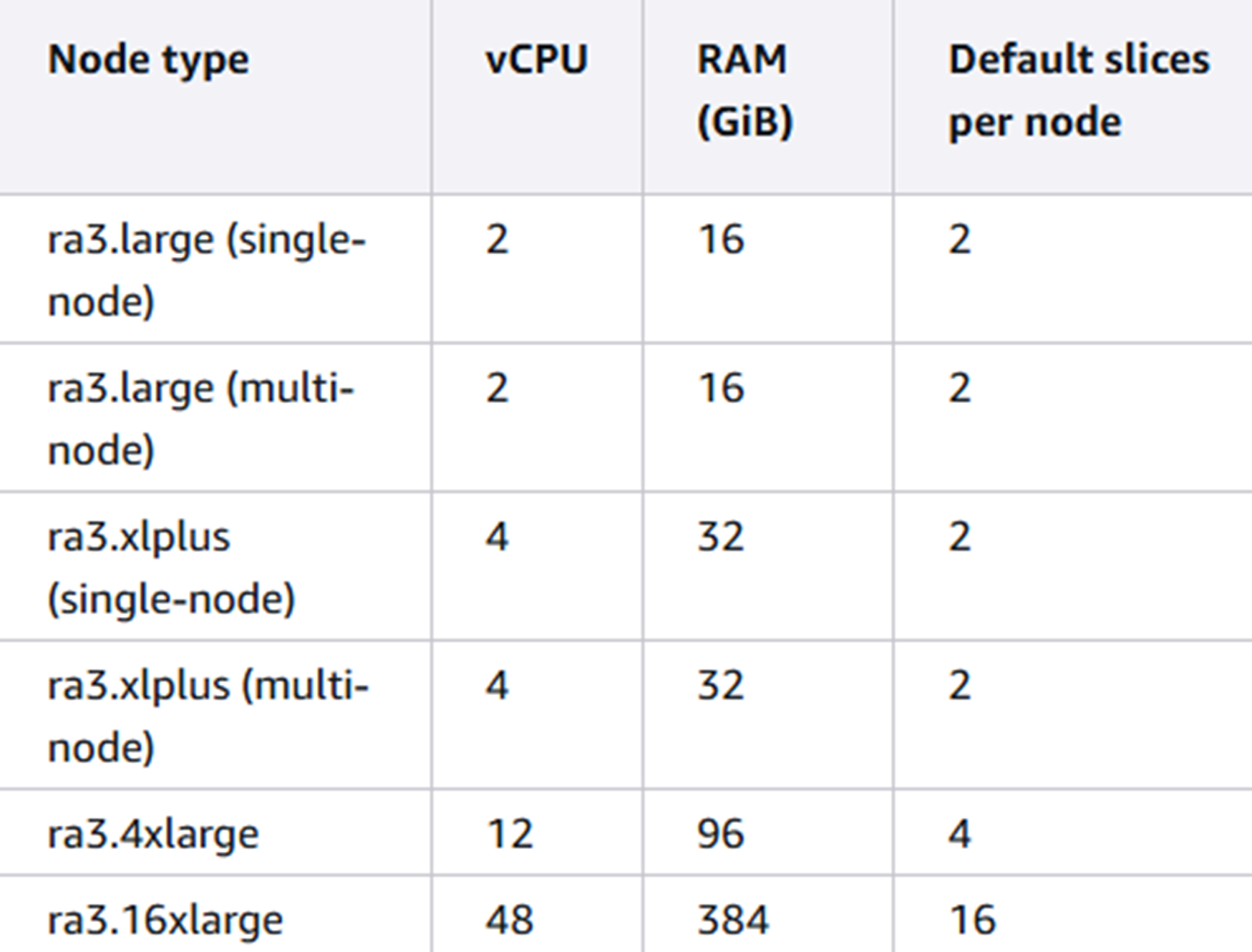
节点切片(Node slices):切片本质上是每个计算节点内的虚拟处理器。它们被分配相等数量的内存、计算配额和磁盘空间用于工作。每个节点的切片数由集群的节点大小决定。
 |
案例分享
我们知道不同类型节点所支持的切片数量不同。而调整节点类型,或者添加、删除节点的操作本身不会改变节点切片的总数量,因此这些操作就可能导致切片在每个节点上的数据分布不均匀。
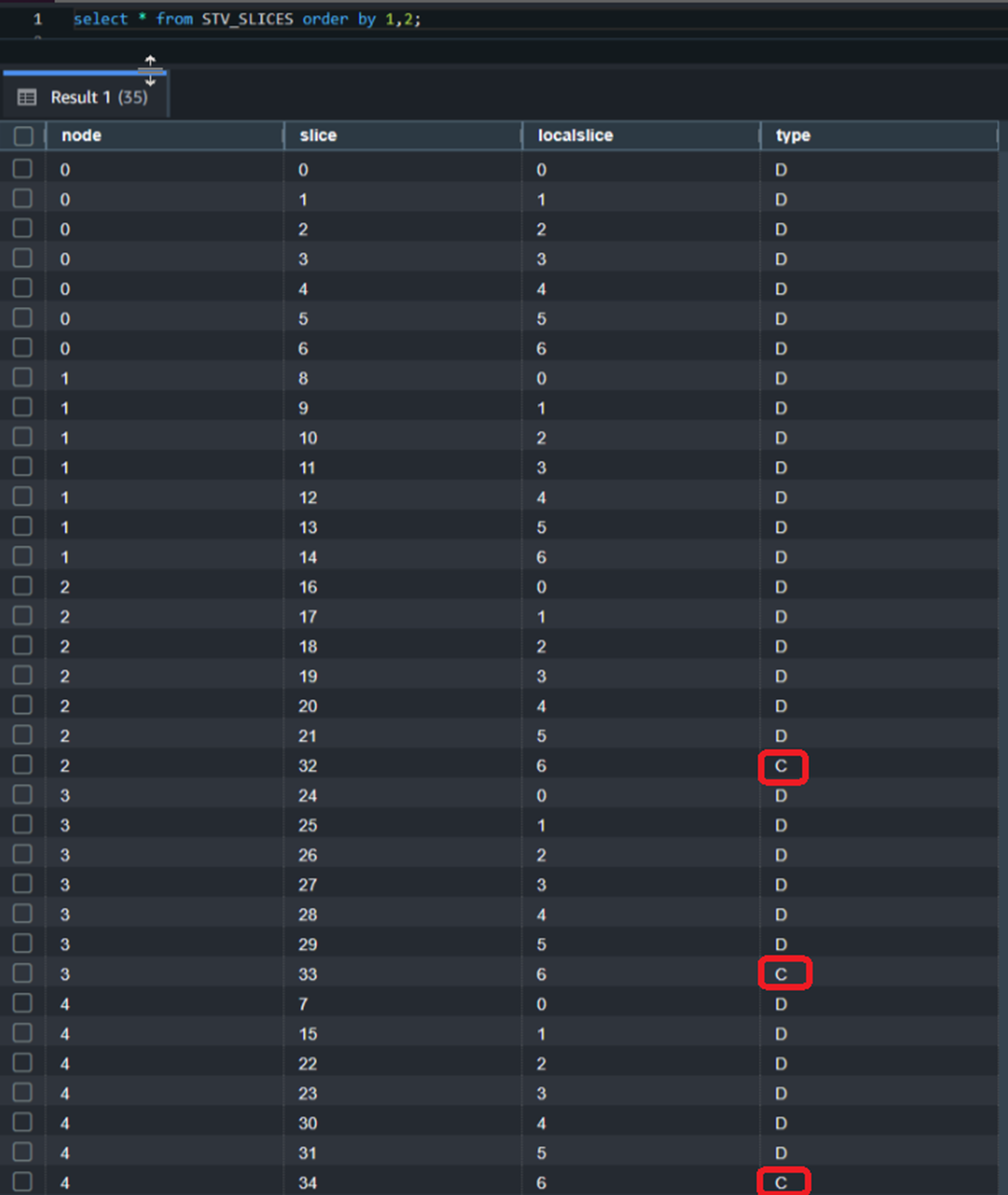
例如,在下面的示例中,将一个原本是4个ra3.4xlarge的集群(32个切片)添加一个节点成为5个ra3.4xlarge之后会出现切片在节点上分布不均匀(32个切片无法在5个节点上被平均分)。
通过查询STV_SLICES系统表可以看到当前的集群一共有5个节点,每个节点上有7个切片。但是在节点3、4、5上各有一个Compute类型的切片。可以看到Data类型的切片在每个节点的数量是不同的。
 |
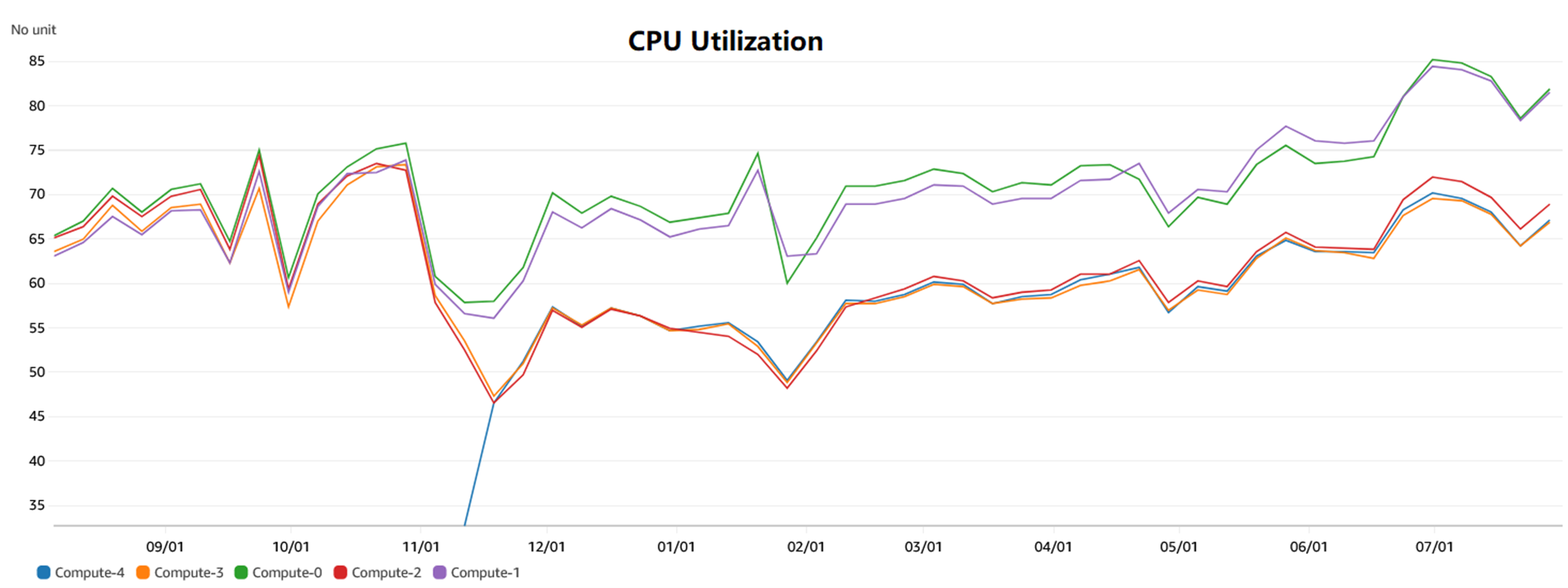
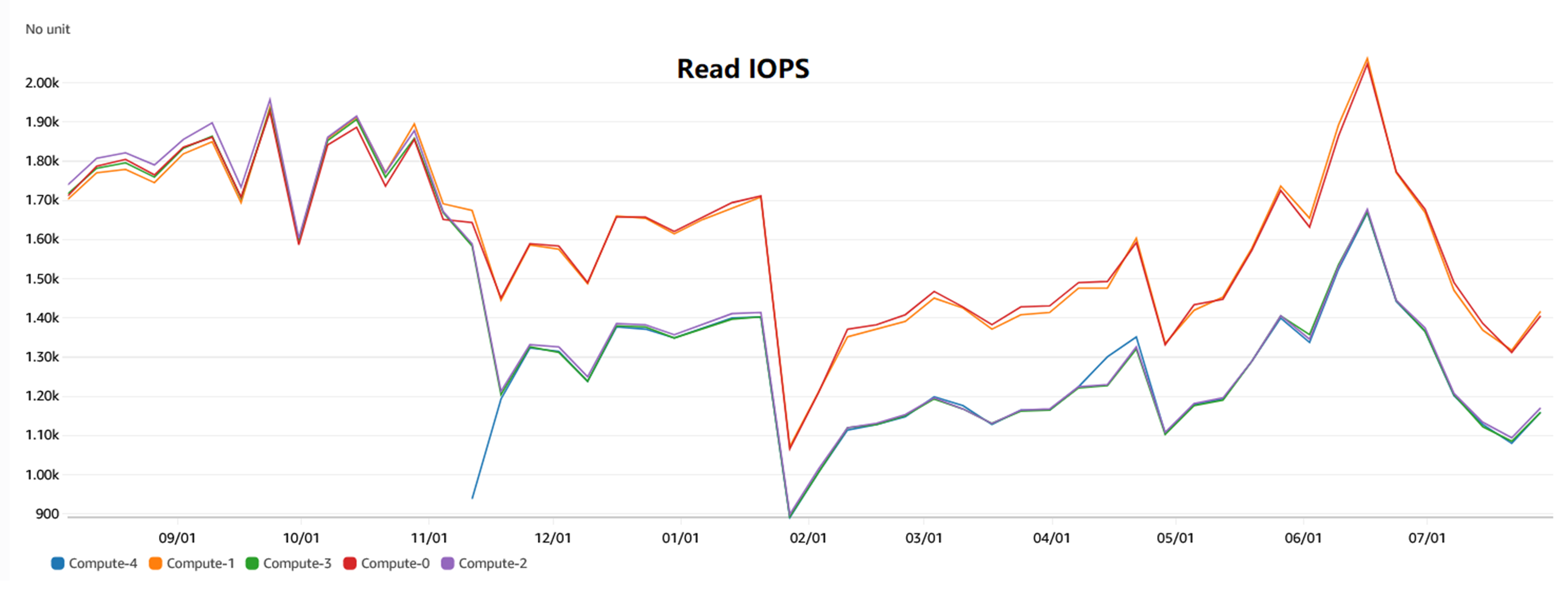
从CloudWatch CPU Utilization% 可以看到由于切片在节点上的分布不均匀而导致的资源使用不均匀。
 |
 |
为了解决以上的问题,需要做经典调整(Classic Resize)来调整切片的总数量和在各个节点上的分布。
注意:调整大小(Resize)操作有两种类型 – 弹性调整(Elastic Resize)和经典调整(Classic Resize)。两者最需要注意的区别是:弹性调整(Elastic Resize)操作不会改变切片总数量;而经典调整Classic Resize)操作会根据集群最新的节点类型和数量调整切片总数量。
经典调整(Classic Resize)
经典调整(Classic Resize)通过在后台创建一个全新的集群并迁移数据来实现。
假设,如下图示例中,将一个有2个dc2.8xlarge节点的集群(32个切片)通过经典调整(Classic Resize)操作调整成5个ra3.4xlarge节点的集群(20个切片)。
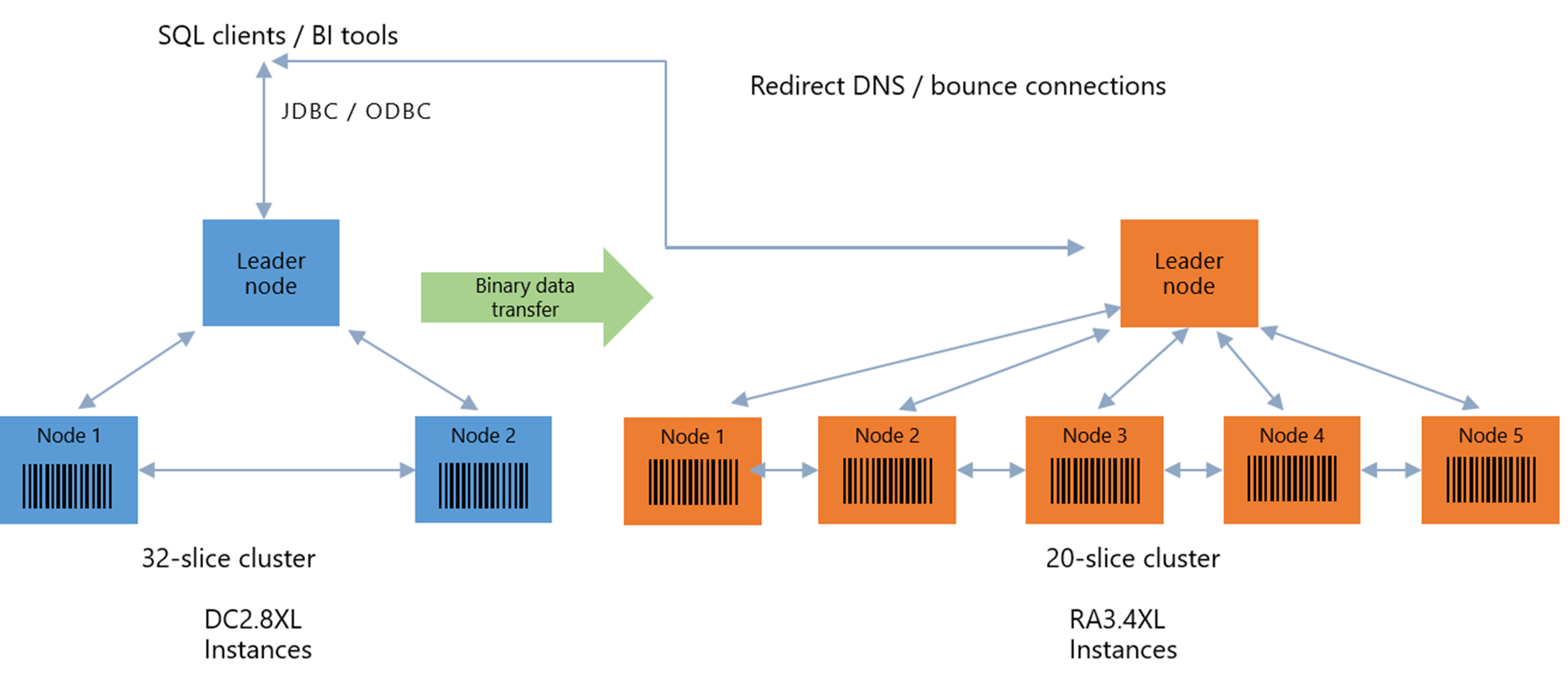 |
此过程的主要的过程如下:
阶段I:
1.将源集群的metadata复制到新集群,在这个阶段源集群是read-only模式;
2.上述步骤完成之后,集群将变成Available,并将以KEY分布(diststyle = KEY)的所有表都临时调整为EVEN(diststyle = EVEN)。
阶段II:
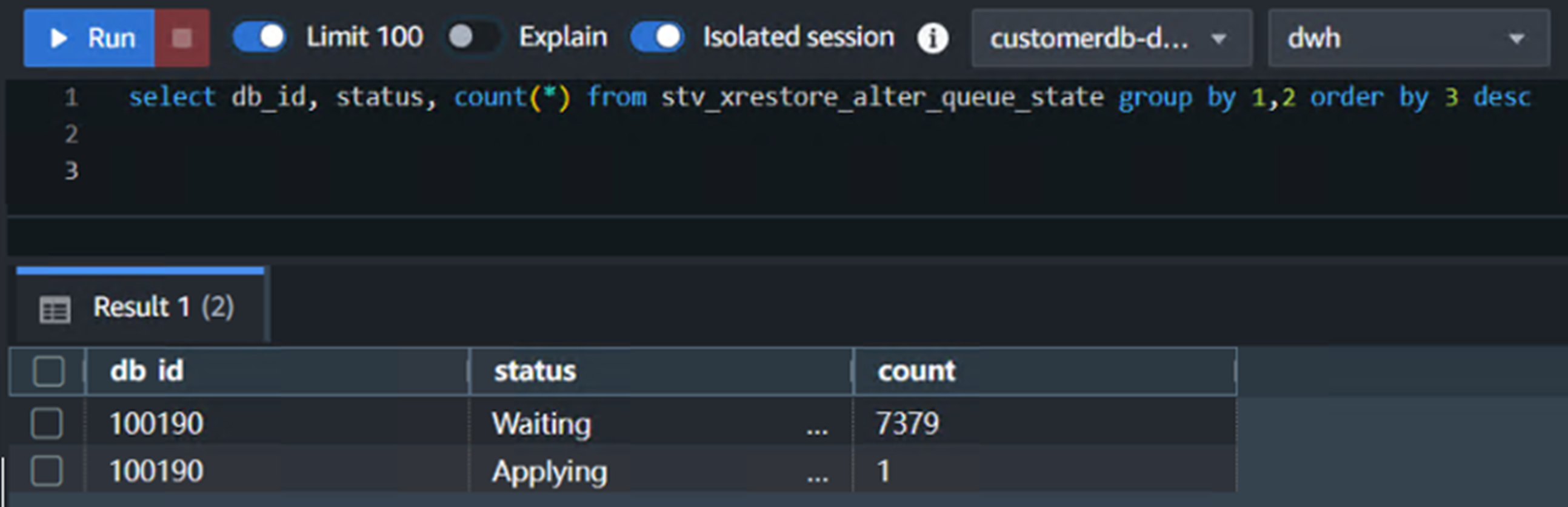
1.Restore Distkey Table:将阶段I中被临时调整为EVEN分布的所有表再重新调整回KEY分布。此过程是单线程运行,如果需要调整的表很多很大,那么这个过程会花很长的时间。
监控:使用以下脚本来监控此过程的进度:
 |
加速:可以手动、并行的执行 ALTER TABLE tablename ALTER DISTSTYLE KEY DISTKEY keyname 语句来加速将分布方式从 EVEN显式更改为 KEY的过程。
2. Rebalance Disteven Table:数据迁移(从源集群到新集群)。
此过程是以Redshift 低优先级的进程中进行,并且不能进行人为的手动干预。
可以使用以下脚本监控进度:
整个过程结束之后,可以使用以下脚本查询整体Classic Resize的执行时长:
以上的脚本运行结果如下图,可以清晰地看到Restore Distkey Table和Rebalance Disteven Table的开始、结束时间。
 |
通过查询STV_SLICES系统表可以看到当前的集群的5个节点上各有4个切片,切片总数量已经由原来的32个调整到了20个,并且所有的切片类型都是D(Data)。
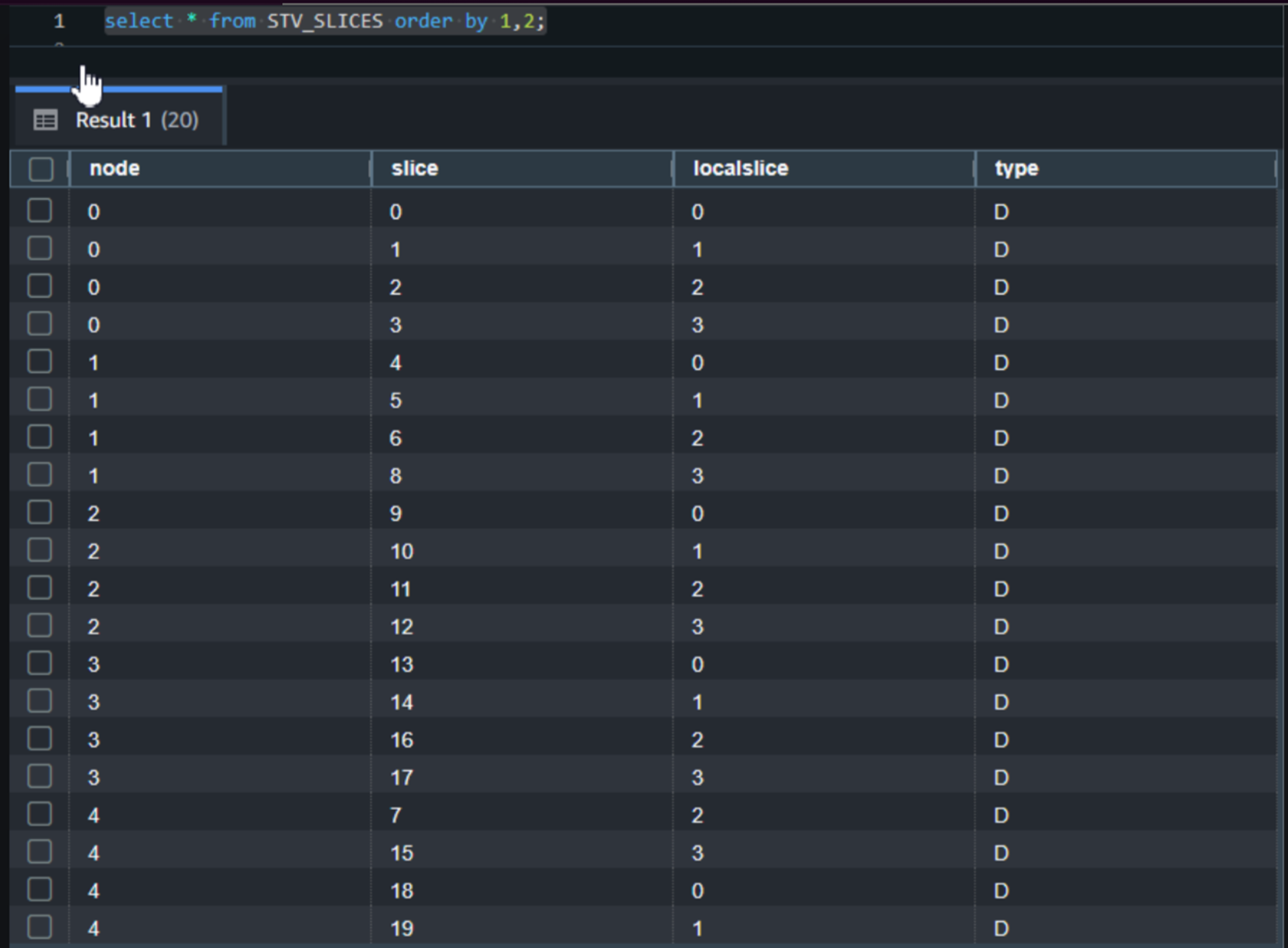 |
在CloudWatch中验证各个节点性能的关键指标。
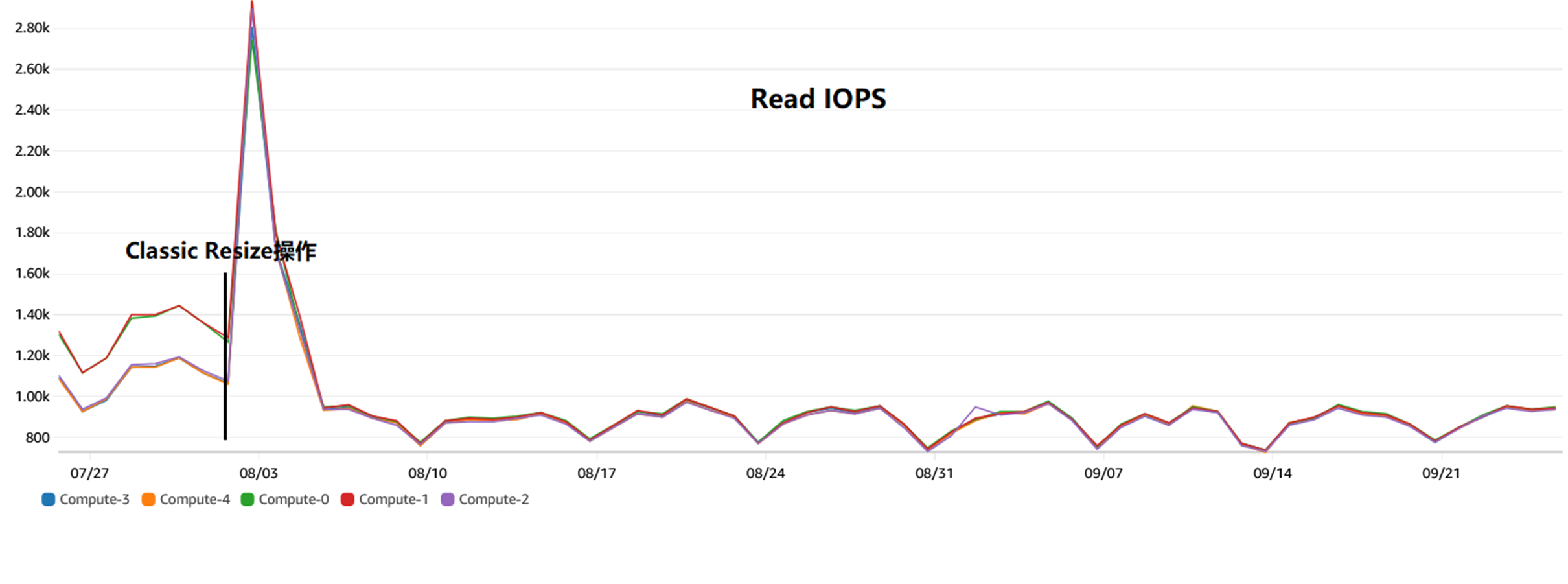
首先,在Classic Resize 操作之后,数据在各个节点上分布均匀。
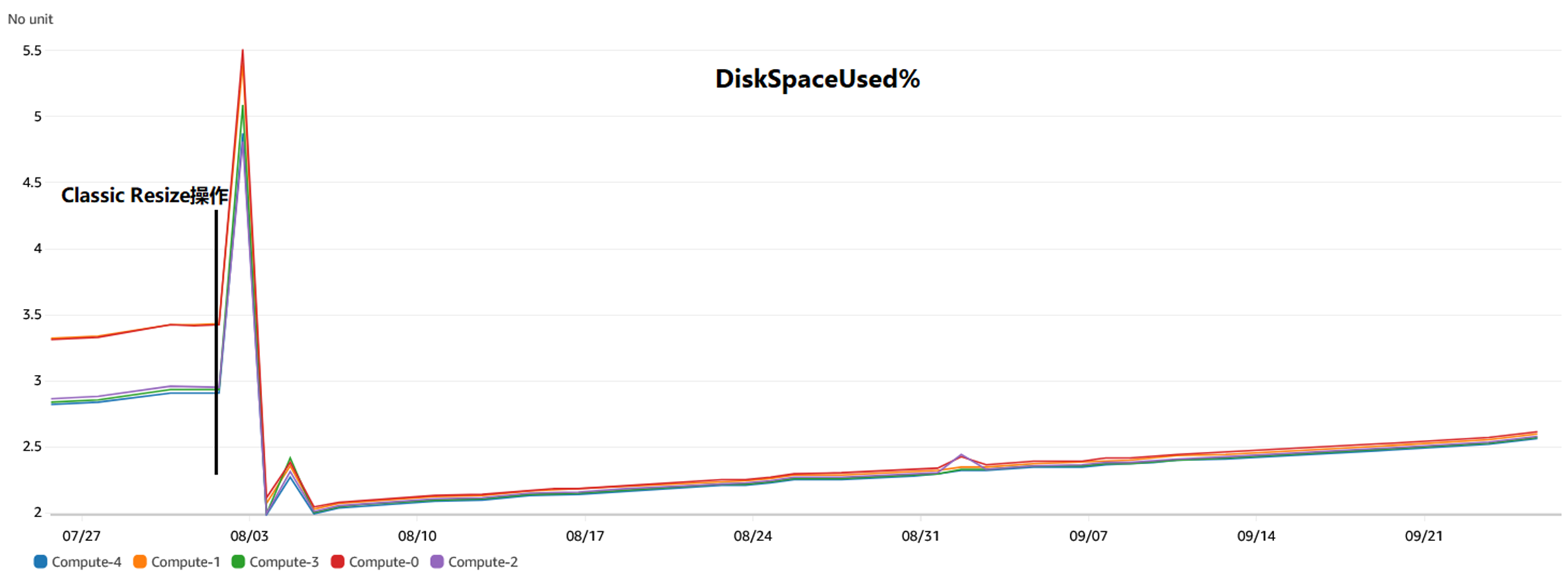 |
并且,在Classic Resize 操作之后,各个节点上的资源使用均匀。
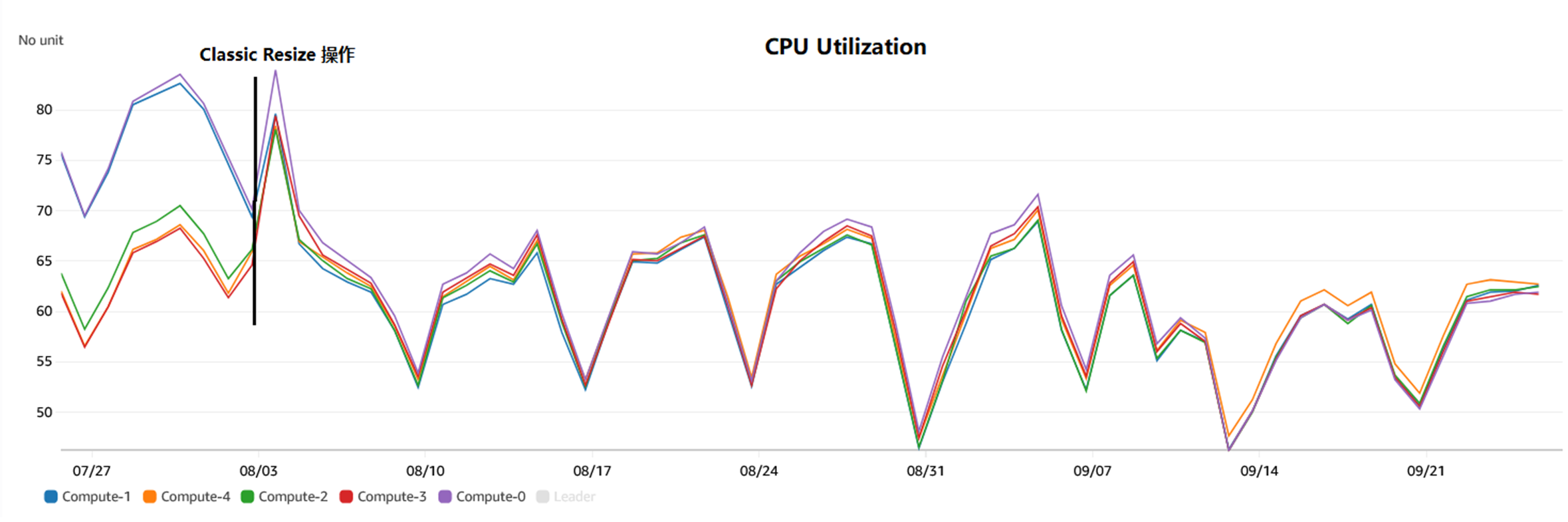 |
 |
结束语
本篇博客介绍了经典调整(Classic Resize)的概述信息,包括使用的场景、具体的过程、监控手段以及案例分享。还请注意在调整节点类型,或者添加、删除节点之后进行评估,必要的时候进行经典调整(Classic Resize)的操作以获取更优化的集群性能。
参考链接
https://docs.aws.amazon.com/redshift/latest/dg/c_high_level_system_architecture.html
https://docs.aws.amazon.com/redshift/latest/mgmt/working-with-clusters.html
https://docs.aws.amazon.com/redshift/latest/mgmt/resizing-cluster.html
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
