亚马逊AWS官方博客
强化学习优化消除类游戏关卡设计的实践
关于Magic Tavern
Magic Tavern(中文名“麦吉太文”)是一家全球化的游戏研发与发行公司,成立于2013年,总部位于北京,并在上海和旧金山设有办事处。公司专注于移动休闲游戏的开发,致力于打造适合各年龄段玩家的娱乐体验,旗下多款游戏在全球市场表现优异,常年位列多个国家的畅销榜前列,并多次获得苹果、谷歌等平台的官方推荐。
截至目前,Magic Tavern拥有超过亿级的总用户和千万级的日活跃玩家,员工规模约400余人,团队成员包括来自清华、纽约大学、新加坡国立大学、Google、EA等知名机构的资深游戏开发人才。其代表作品包括《Matchington Mansion》《Project Makeover》《Modern Community》等。
前言
消除类游戏作为休闲游戏品类中的常青树,具有非常广阔的市场空间和玩家群体。目前,消除类游戏的玩法逐渐从以闯关刷分导向发展到结合任务、剧情的收集导向。无论是哪种玩法,都要求游戏开发商对于关卡的设计和难度评估具有快速和准确的结果,尤其是对于收集导向型的消除类游戏,其主线剧情任务的通关高度依赖于关卡更新迭代。如何快速准确的得到关卡的难度值,从而优化关卡排布,对于游戏长期运营和优化玩家体验具有重要意义。
一般来说,游戏的新关卡上线之前,会首先经过内部一系列的机测和策划内部交叉测试流程,再根据统计数据确定关卡的难度估计。但由于测试规模和样本量的限制,偶尔会出现新关卡上线后与预期难度偏差过大的情况,一定程度上会影响真实玩家体验。这时就需要召回关卡重做,或更正难度后重新排布关卡分布。内部测试流程需要消耗大量人力且难度评估不一定准确,如果有更好的自动化测试方法,将能大幅度提高新关卡的生产效率。
消除类游戏关卡中的关键元素
消除类游戏的关卡一般会设定有通关元素、限制条件、道具、奖励等。通关元素指通关所需要消除或收集的元素,一般会在棋盘上表示为障碍物、特殊物品等。限制条件指达成通关条件前的操作约束,比如可操作步数、倒计时、不可消除障碍等。道具指除了基本操作之外,通过额外购买或活动赠送获取的强力物品,一般能够影响关卡平衡性,降低通关难度。但这些道具物品的获取一般通过充值,对于难度预测的影响不大。奖励指通过凑成特殊消除范式获得的奖励元素,比如炸弹、火箭等,这些奖励元素能够在棋盘上消除特定范围内的普通元素,组合应用奖励元素具有更大的威力。奖励使用技巧体现了玩家水平,并且是难度预测中的一个重要部分。
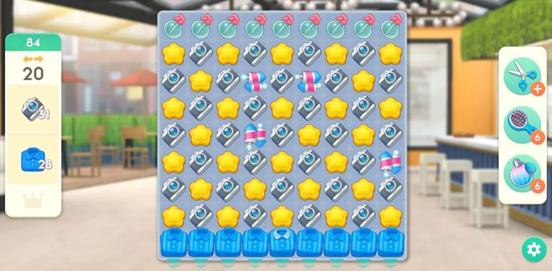 |
上图是Magic Tavern的消除类游戏《Project Makeover》的第84关截图,可以看到图中具有非常多的元素。此关的通关元素显示在左侧,需要收集31个相机和28件衬衫。限制条件是20步。道具如右侧显示,目前此玩家具有6个梳子道具和6个香水道具,这些道具的使用与关卡设计无关,充值即可获得。奖励在棋盘上显示为火箭,不同方向的火箭可以消除对应一行或一列的所有元素,火箭可以通过消除一行或一列4个相同元素获取。
强化学习如何应用于消除类游戏
强化学习的核心组成元素是Agent、Environment,通过Agent与Environment的交互(Action),获取奖励(Reward)和新的状态(State)。
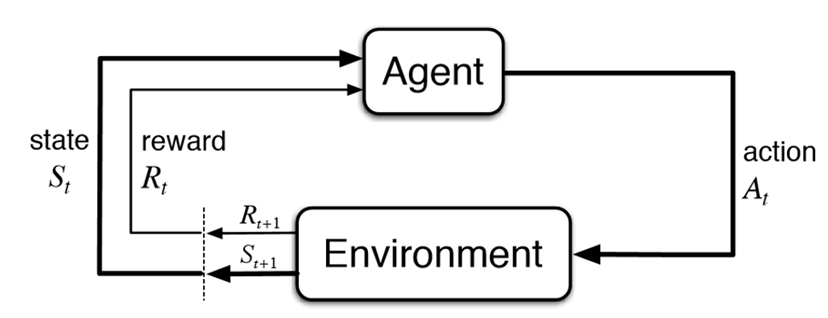 |
在消除类游戏的通关过程中,Agent是自行游玩的主体,扮演玩家。研发人员需要给出具体的动作空间,一般是棋盘上可以造成消除的所有有效动作。当Agent进行了一步操作,游戏后端计算此操作对通关元素、限制条件、奖励的影响,并返回当前状态和奖励值给Agent。Agent反复执行动作,直到达成通关条件或限制条件用尽游戏结束,记录获取的奖励值。循环往复进行训练,Agent便会向着获取最大奖励值的方向学习,即为学会了游玩游戏的逻辑。
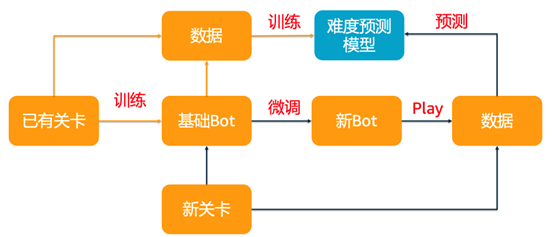
难度预测
通过强化学习训练Agent,我们拥有了测试关卡的玩家主体。接下来,我们还需要收集Agent游玩关卡时的特征数据,如获取的奖励值、是否通关,通关时剩余限制条件等。通过这些特征数据,结合历史关卡的准确难度值,拟合一个机器学习模型,用于新关卡的难度预测。整体流程是:当新关卡需要测试难度时,首先使用强化学习模型微调Agent,再游玩新的关卡得到这些特征数据,然后通过历史难度预测模型推理得到新关卡的难度。
 |
与现有关卡设计流程的结合
到目前,我们理清了使用强化学习进行关卡难度预测的核心算法和工作流程。接下来,为了在实际的关卡设计中应用难度预测的流程,我们还需要进行一些工程化的工作。
并行训练推理
一般来说,策划组产出新关卡数量每批次为十几关甚至几十关,每一关还有不同的初始状态和掉落次序,因此在强化学习训练时需要进行并行化来提高难度预测速度。
强化学习Agent的训练是重计算任务,需要高CPU计算资源。在Agent与游戏后端服务器通信时,每个Agent占用一个CPU核心,以c7i.4xlarge类型的EC2实例为例,每台实例具有16核,可以同时运行16个Agent。同时,需要关注游戏后端服务器的压力状况,资源不足时要及时扩容。当使用Agent获取到足够多的特征数据时,需要拟合MLP模型。此类模型使用GPU训练能有效提升训练速度。
并行训练可以使用Ray框架来部署,Ray框架专门用于分布式训练和模型微调。它能够让用户轻松地将模型训练代码从单机扩展到云端的多机器集群,极大简化了分布式计算的复杂性。此外Ray还支持kubernetes,能够轻松在EKS上部署。
模型管理
在整个工作流程中,有基于历史关卡训练的基准Agent模型,也有新关卡时微调的新Agent模型。随着关卡设计的增多,模型数量也会随之变大。我们需要一套模型管理系统来存储和管理这些模型,考虑到这些模型都有各自的生命周期,一般使用过的模型短期内不会再进行访问,将这些模型保存在S3并启用生命周期是具有性价比的选择。
回放系统
在Agent训练时,为了最大程度提升训练速度,我们建议客户封装无头游戏客户端。无头游戏客户端中不包含游戏前端,仅通过API交互,这样就避免每次动作后发生的前端动画造成的时延。然而,在测试过程中,我们有时希望能看到Agent的游玩过程。这部分有两个选择:一是使用包含前端的有头客户端测试,这样能够看到Agent的动作过程,缺点是使用有头客户端的交互过程存在动画,会导致耗时增加;二是通过Agent的操作日志,结合客户自己的回放系统,定向回放想要监控的关卡,缺点是需要进行操作日志和回放系统的步骤转译,且需要客户侧有回放机制。如下图所示,为Magic Tavern使用回放系统监控Agent的行为记录。
 |
基于以上三点工程化需求,亚马逊云科技游戏行业解决方案团队设计了GameAIbot的解决方案,整体架构可参考如下架构图。
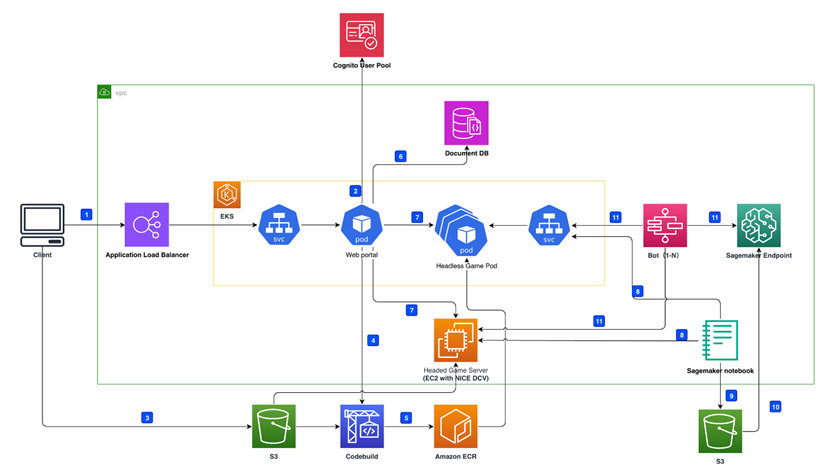 |
总结
消除类游戏的关卡难度预测是指导关卡排布,从而决定玩家体验的重要因素。传统基于人工的测试方法偶发预测难度失准,测试不够充分等问题。Magic Tavern的消除类游戏需要通关关卡来获取金币和素材来支持主线任务进行,尤其需要高质量和快速的关卡更新,基于强化学习的难度预测方式能够解放策划组人员的繁重测试任务,提高关卡设计效率,进而优化玩家的游戏体验。