亚马逊AWS官方博客
Amazon SageMaker – 加快机器学习进程
机器学习是许多初创公司和企业的关键技术。尽管经历了数十年的投入和改进,开发、训练和维护机器学习模型的过程仍然繁琐且欠缺通用性。将机器学习技术集成到应用程序中的过程往往需要一个专家团队进行为期数月的调整和修补,而且设置还不一致。企业和开发人员需要一个端到端、开发到生产的机器学习管道。
Amazon SageMaker 简介
Amazon SageMaker 是一种完全托管的端到端机器学习服务,数据科研人员、开发人员和机器学习专家可以快速、大规模地构建、训练和托管机器学习模型。这极大地推进了您所有的机器学习工作,让您能够将机器学习技术迅速融入生产应用程序。
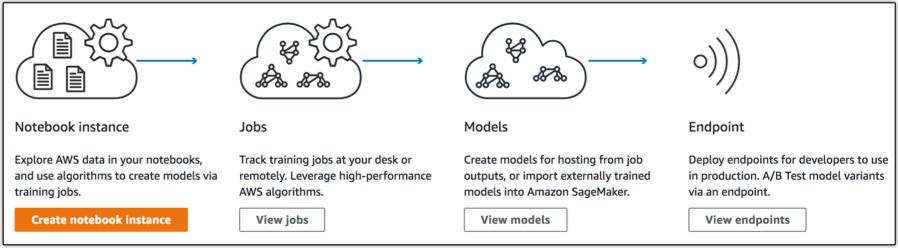
Amazon SageMaker 包含三个主要组件:
- 编写:零设置托管式 Jupyter 笔记本 IDE,可进行数据探索、清理和预处理。您可以在一般实例类型或 GPU 驱动实例上运行上述功能。
- 模型训练:分布式模型构建、训练和验证服务。您可以使用内置的通用监督式和非监督式学习算法和框架,也可以借助 Docker 容器创建自己的训练。训练可以扩展到数十个实例以支持更快的模型构建。从 S3 读取训练数据,并将模型构件存放到 S3。模型构件是数据相关的模型参数,而不是允许您从模型进行推理的代码。这种问题隔离策略简化了将经过 Amazon SageMaker 培训的模型部署到物联网设备等其他平台的过程。
- 模型托管:一种模型托管服务,可通过 HTTPS 终端节点调用模型获取实时推理。这些终端节点能够扩展以支持流量,允许您同时对多个模型进行 A/B 测试。同样,您可以使用内置软件开发工具包构建这些终端节点,也可以利用 Docker 镜像提供自定义配置。
这些组件中的每一个都可以独立使用,这使得使用 Amazon SageMaker 填补现有管道中的空白变得极其简单。也就是说,在端到端管道中使用此服务时,您可以获得一些非常强大的功能。
使用 SageMaker
我打算构建、训练和部署一个基于 Apache MXNet 的图像分类器。我将使用 Gluon 语言、CIFAR-10 数据集和 ResNet V2 模型架构。
使用 Jupyter 笔记本编写

创建笔记本实例时,它会启动一个 ML 计算实例,其中包含深度学习应用中常见的 Anaconda 包和库、一个 5 GB ML 存储卷和几个演示各种算法的示例笔记本。我可以选择配置 VPC 支持来在我的 VPC 中创建一个 ENI,以方便、安全地访问我的资源。
待实例完成预配置后,我就可以打开笔记本开始编写代码了!

模型训练
对于任何类型的 Amazon SageMaker 常见框架训练,您都可以实现类似下面的简单训练接口。为简洁起见,这里省略了实际的模型训练代码:
def train(
channel_input_dirs, hyperparameters, output_data_dir,
model_dir, num_gpus, hosts, current_host):
pass
def save(model):
pass我打算在 Amazon SageMaker 基础设施上的 4 个 ml.p2.xlarge 实例上创建一个分布式训练作业。我已经下载了本地所需的全部数据。
import sagemaker
from sagemaker.mxnet import MXNet
m = MXNet("cifar10.py", role=role,
train_instance_count=4, train_instance_type="ml.p2.xlarge",
hyperparameters={'batch_size': 128, 'epochs': 50,
'learning_rate': 0.1, 'momentum': 0.9})现在,我们构建好了模型训练作业,可以通过下面的调用为其提供数据: m.fit("s3://randall-likes-sagemaker/data/gluon-cifar10")。
导航到作业控制台,可以看到系统正在运行此作业!

托管和实时推理
现在,我的模型已完成训练,可以开始生成预测了!我使用跟以前相同的代码创建和启动一个终端节点。
predictor = m.deploy(initial_instance_count=1, instance_type='ml.c4.xlarge')
调用终端节点的操作十分简单,直接运行: predictor.predict(img_input)!
这就是一个代码不足 100 行的端到端机器学习管道。
下面我们再演练一个示例,了解一下如何只使用 Amazon SageMaker 的模型托管组件。
使用自定义 Docker 容器
Amazon SageMaker 为 Docker 容器定义了一个简单的规范,让您能够轻松编写自定义训练算法或自定义推理容器。
我有一个基于此处所述架构的现有模型,我打算托管此模型进行实时推理。
我创建了一个简单的 Dockerfile 和 flask 应用程序来提供推理。
由于加载模型和生成预测的代码因实际应用而异,此处省略了这些代码。从本质上说,我构建了一个方法来从输入 URL 下载图像,然后将此图像数据传递给 MXNet 模型进行预测。
from flask import Flask, request, jsonify
import predict
app = Flask(__name__)
@app.route('/ping')
def ping():
return ("", 200)
@app.route('/invocations', methods=["POST"])
def invoke():
data = request.get_json(force=True)
return jsonify(predict.download_and_predict(data['url']))
if __name__ == '__main__':
app.run(port=8080)FROM mxnet/python:latest
WORKDIR /app
COPY *.py /app/
COPY models /app/models
RUN pip install -U numpy flask scikit-image
ENTRYPOINT ["python", "app.py"]
EXPOSE 8080我将这个图像推送到 ECR,然后导航到 Amazon SageMaker 中的模型控制台来创建一个新模型。

创建新模型后,我还预配置了一个终端节点。

现在我可以从 AWS Lambda 或任何其他应用程序调用此终端节点了!我设置了一个 Twitter 账户来展示这个模型。您可以通过 Twitter 向 @WhereML 推送一张图片,看看它能否猜出位置!
import boto3
import json
sagemaker = boto3.client('sagemaker-runtime')
data = {'url': 'https://pbs.twimg.com/media/DPwe4kMUMAAWCd_.jpg'}
result = sagemaker.invoke_endpoint(
EndpointName='predict',
Body=json.dumps(data)
)
定价
作为 AWS 免费套餐的一部分,您可以免费开始使用 Amazon SageMaker。在前两个月,您每月可以免费使用:250 小时的 t2.medium 笔记本用量、50 小时的 m4.xlarge 用量和 125 小时的 m4.xlarge 用量。超出免费套餐部分的定价因地区而异,但基于以下要素计费:实例用量 (秒)、存储 (GB) 和传入/传出服务的数据量 (GB)。
Jeff 告诉我,在今年的 re:Invent 大会举办之前,不要撰写“太过重磅”的文章。显然,我没把持住。在 re:Invent 2017 发布的众多美妙产品中,Amazon SageMaker 是我最喜欢的服务。我已经迫不及待想要知道我们的客户能够利用这个令人兴奋的工具套件完成哪些“壮举”了。
– Randall