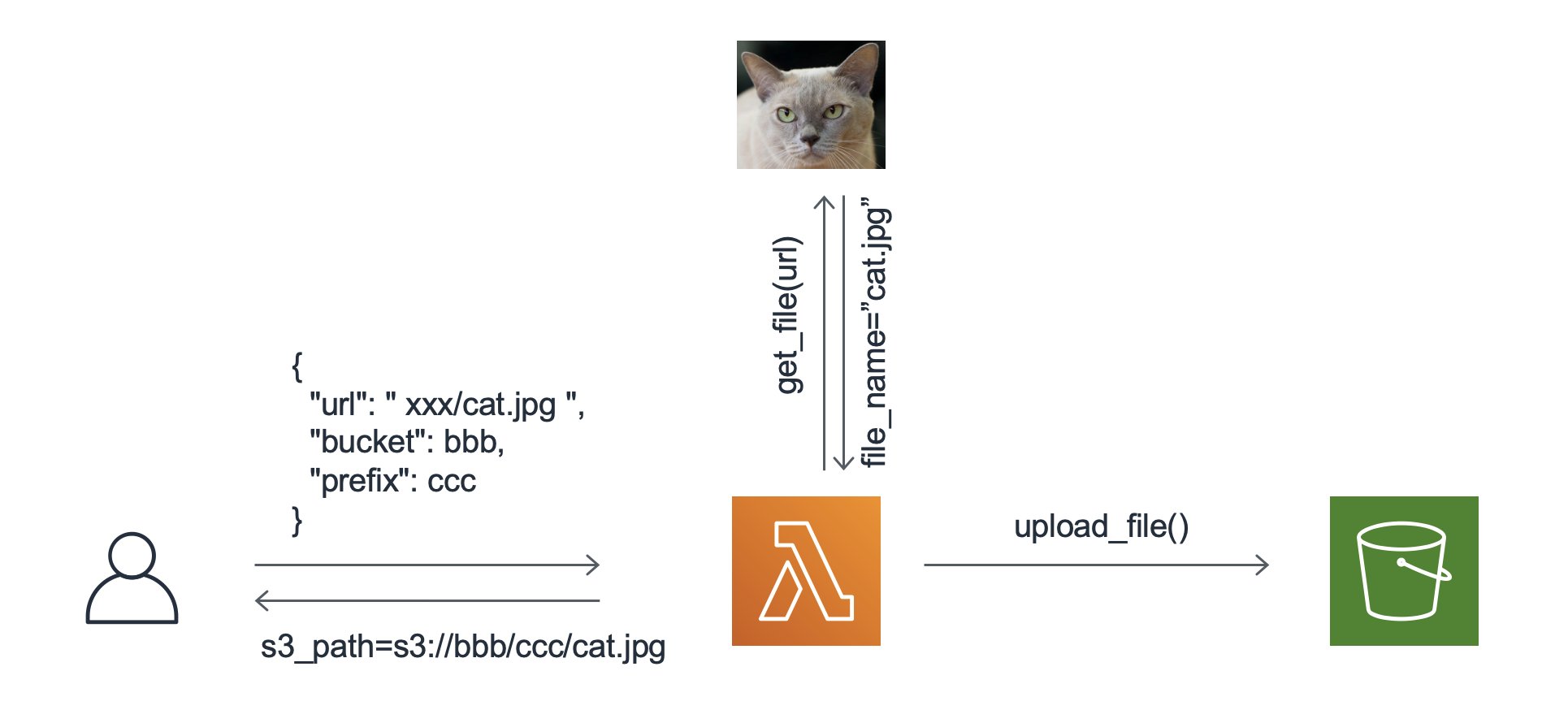
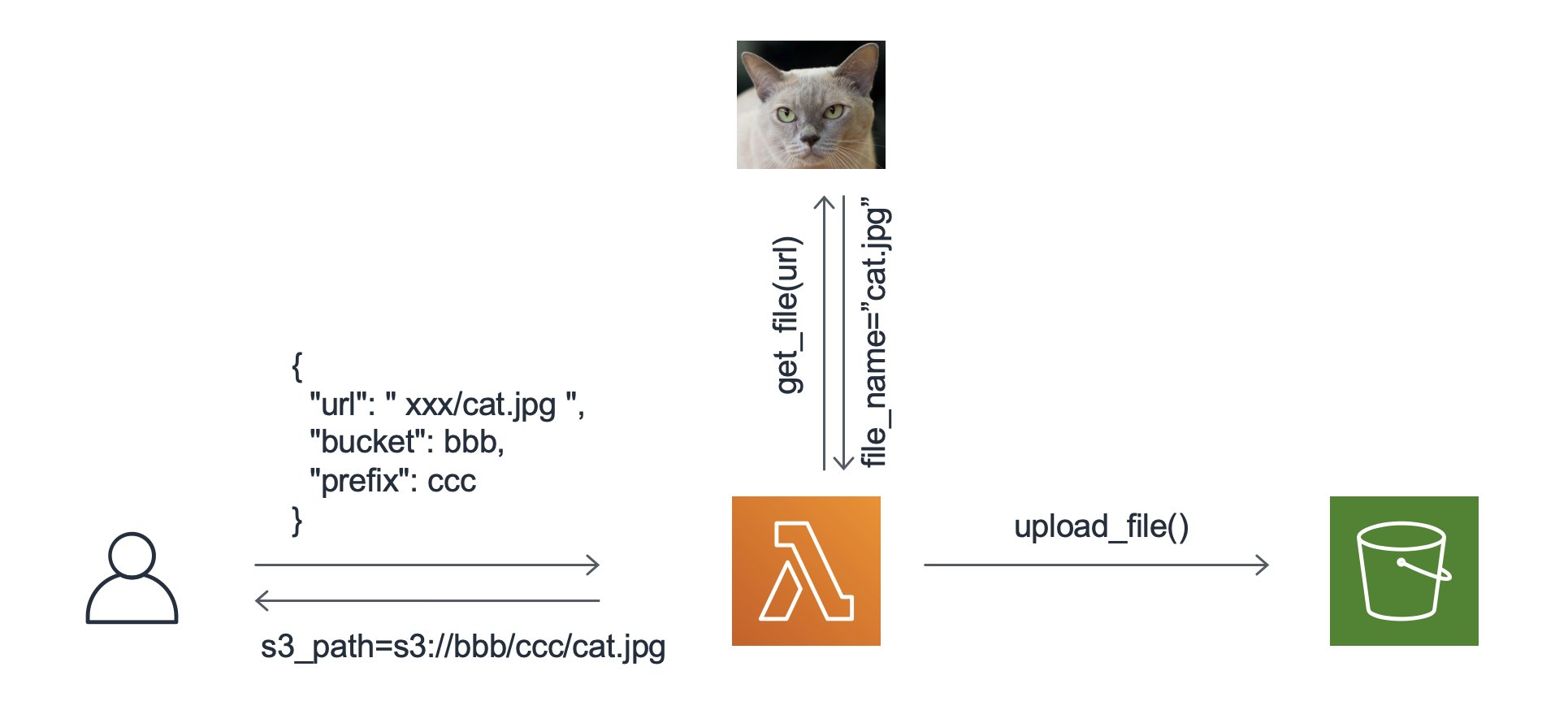
对象存储已经是公有云厂商的标准服务,所有厂商都支持在对象存储服务上提供基于对象的上传,下载等服务。但原生的服务接口通常默认上传下载的数据位置一端为本地,一端为云上。但如果需要上传到对象服务的文件是存在某个通过URL可访问的数据,在AWS上还需要客户自行完成下载之后,再使用cli或者sdk向S3上传。另外,在很多业务场景中,用户需要批量下载互联网资源并上传到S3中。
本文介绍一个基于lambda的实现,可以帮助客户直接指定数据源的URL并自动完成数据的下载和上传过程。如下图所示,用户可以通过设置url,bucket,prefix等参数调用Lambda函数完成网上数据的抓取和S3上传,上传后的文件位置会返回给客户。
AWS Lambda 是一项无服务器计算服务,可运行代码来响应事件并为您自动管理底层计算资源。Lambda 在高可用性计算基础设施上运行代码,用于执行计算资源的所有管理工作。这包括服务器和操作系统维护、容量调配和弹性伸缩、代码和安全补丁部署以及代码监控和日志记录。您只需要提供代码,而无需关心后端计算资源的管理和运维。
在这篇blog中,我们将介绍通过lambda实现URL文件直接上传到S3并通知到客户的具体方法。
第一步 构建docker容器镜像
- 在你的运行环境中安装docker与git, 并确保你有AWS账户可以访问ECR,Lambda等服务。
- 在terminal 中运行:#git clone https://github.com/zhaoanbei/url2s3.git
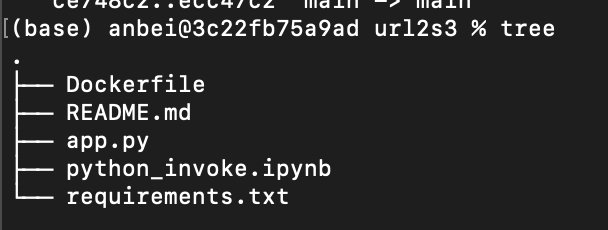
- clone到本地的文件目录如下:
- 查看Dockerfile内容如下:
# python3.8 lambda base image
FROM public.ecr.aws/lambda/python:3.8
# copy requirements.txt to container
COPY requirements.txt ./
# installing dependencies
RUN pip3 install -r requirements.txt
# Copy function code to container
COPY app.py ./
# setting the CMD to your handler file_name.function_name
CMD [ "app.lambda_handler" ]
- py代码如下:其中,get_file用于下载文件,upload_file用于上传文件:
#-*- coding: utf-8 -*-
import json
import urllib.request
import logging
import boto3
from botocore.exceptions import ClientError
import os
import requests
import time
local_path = "/tmp/" #"/mnt/test/tmp"
local_file_name = "temp_file"
local_file = local_path+local_file_name
def urllib_get_file_size(url):
file = urllib.request.urlopen(url)
print("file size to get is: "+str(file.length))
return(int(file.length))
def requests_get_file_size(url):
info = requests.head(url)
print("file size to get is: " +info.headers['Content-Length'])
return(info.headers['Content-Length'])
def get_file(url):
r = requests.get(url)
with open(local_file, 'wb') as f:
f.write(r.content)
def get_dir_available_size(dir):
batcmd = "df -k "+dir
result = os.popen(batcmd)
lines = result.readlines()
#print(batcmd+"output: "+" line 0:"+lines[0])
#print(batcmd+"output: "+" line 1:"+lines[1])
line = lines[1].split()
# make size unit to byte
dir_size = int(line[3])*1024
print("dir available size: "+str(dir_size))
return dir_size
def rm_file(file_path):
os.remove(file_path)
def upload_file(file_name, bucket, object_name=None):
if object_name is None:
object_name = os.path.basename(file_name)
s3_client = boto3.client('s3')
try:
s3_client.upload_file(file_name, bucket, object_name)
except ClientError as e:
logging.error(e)
return False
return True
def lambda_handler(event, context):
url = event['url']
bucket = event['bucket']
prefix = event['prefix']+'/'+url.split('/')[-1]
s3path='s3://'+bucket+'/'+prefix
file_size = urllib_get_file_size(url)
dir_available_size = get_dir_available_size(local_path)
if dir_available_size < file_size:
print("Not enough storage!")
return -1
else:
print("File size is ok")
get_file(url)
upload_file(local_file, bucket, prefix)
time.sleep(1)
rm_file(local_file)
responseObject ={}
responseObject['statusCode'] = 200
responseObject['headers']= {}
responseObject['headers']['Content-Type'] = 'application/json'
responseObject['headers']['s3path'] = s3path
return responseObject
第二步 容器镜像上传到ECR服务
- 按照https://docs.aws.amazon.com/zh_cn/AmazonECR/latest/userguide/repository-create.html创建私有 repository(AWS控制台进入repository, 根据右上角view push demands进行image build与push操作)
第三步 创建Lambda函数
- 进入lambda控制台,选择create function, Container image, 选择之前构建的repository,latest镜像版本。
- 创建完成后,配置对应的Memory, Ephemeral storage与Timeout。这里需要注意的是,如果预期要获取的文件较大,请调整‘Ephemeral storage’的大小到合理的取值(最大为10GB)
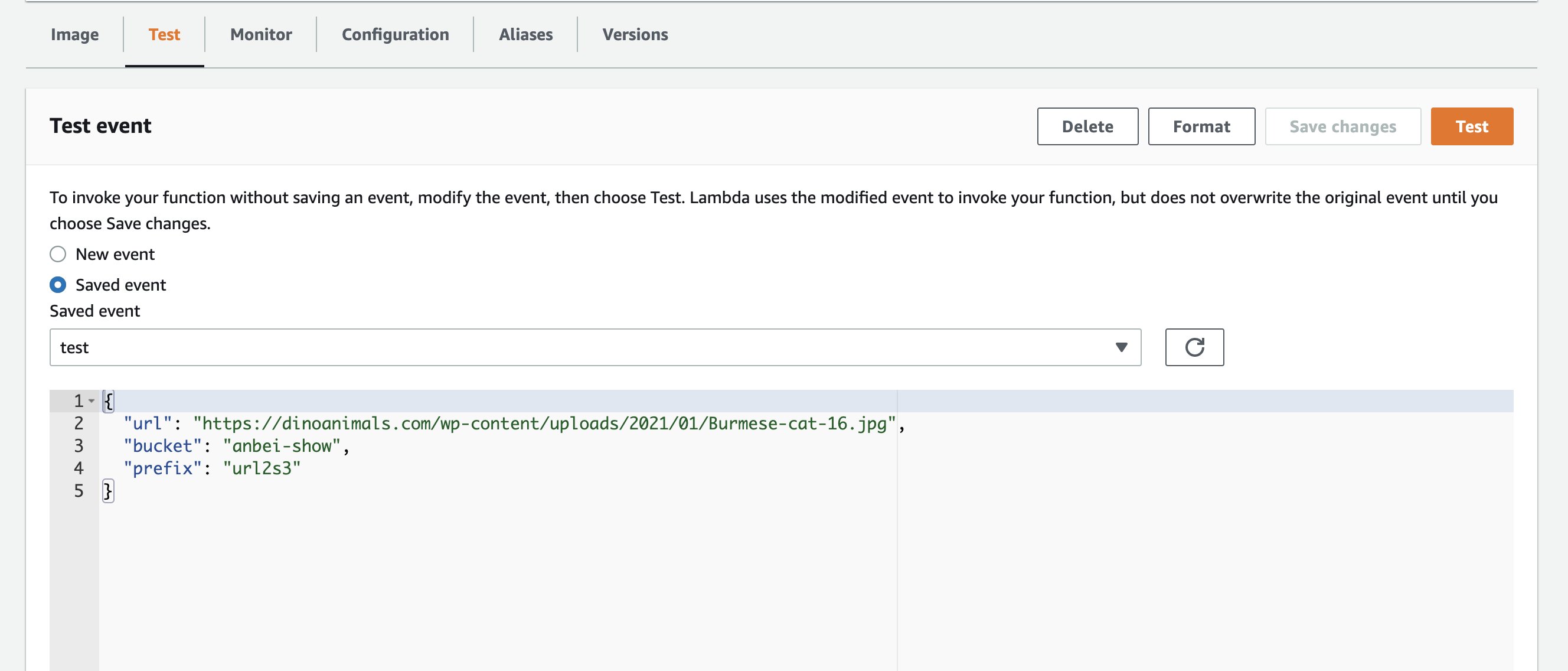
- 在Test下编辑测试事件,点击右上角save changes, Test。测试过程中可以通过Lambda的控制台结合CloudWatch的日志组进行过程的跟踪和分析。
第四步 本地触发Lambda函数
通过git代码仓库中的python_invoke.ipynb,可以实现对应的lambda调用。有关boto3可参考:https://boto3.amazonaws.com/v1/documentation/api/latest/index.html
以下是python_invoke.ipynb的具体实现,可以返回已保存的文件在S3中的位置:
import boto3
import json
import logging
cn = boto3.session.Session(profile_name='cn')
lambda_client = cn.client('lambda')
para = {
"url": "https://dinoanimals.com/wp-content/uploads/2021/01/Burmese-cat-16.jpg",
"bucket": "anbei-show",
"prefix": "url2s3"
}
class LambdaWrapper:
def __init__(self, lambda_client):
self.lambda_client = lambda_client
def invoke_function(self, function_name, function_params, get_log=False):
response = self.lambda_client.invoke(
FunctionName=function_name,
Payload=json.dumps(function_params),
LogType='Tail' if get_log else 'None')
logging.info("Invoked function %s.", function_name)
return json.loads(response['Payload'].read().decode("utf-8"))
response = LambdaWrapper(lambda_client).invoke_function('url2s3',para)
s3path = response['headers']['s3path']
通过本工具,用户可以自动完成针对特定URL文件的自动S3上传。后续会继续改进本工具,以期实现批量数据的自动同步和异步上传等功能。
本篇作者