#!/usr/bin/env python3
"""
Spark Event Log Shuffle Analyzer
Analyzes Spark event logs from S3 to extract shuffle read/write metrics.
"""
import argparse
import json
import boto3
import csv
import threading
import logging
from concurrent.futures import ThreadPoolExecutor
from collections import defaultdict
def setup_logging():
"""Setup logging configuration."""
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(filename)s:%(lineno)d - %(message)s',
datefmt='%Y-%m-%d %H:%M:%S'
)
return logging.getLogger(__name__)
def parse_args():
parser = argparse.ArgumentParser(
description="Analyze Spark event logs for shuffle metrics",
formatter_class=argparse.RawDescriptionHelpFormatter,
epilog="""
Example:
python analyze_spark_shuffle.py \\
--event-log-base-path s3://xxxxx/spark-event-log/ \\
--application-id 00g1m3ocn5clib09 \\
--job-ids 00g1obkrn61ab00b,00g1obkrn61ab00c \\
--threads 4 \\
--output results.csv
"""
)
parser.add_argument(
"--event-log-base-path",
required=True,
help="Base S3 path for event logs (e.g., s3://bucket/spark-event-log/)"
)
parser.add_argument(
"--application-id",
required=True,
help="Spark application ID"
)
parser.add_argument(
"--job-ids",
required=True,
help="Comma-separated list of Spark job IDs"
)
parser.add_argument(
"--threads",
type=int,
default=10,
help="Number of threads for parallel processing (default: 4)"
)
parser.add_argument(
"--output",
help="Output CSV file path (default: {application_id}_shuffle.csv)"
)
return parser.parse_args()
def list_s3_files(s3_path):
"""List files in S3 path, excluding appstatus files."""
s3 = boto3.client('s3')
if not s3_path.startswith('s3://'):
raise ValueError("S3 path must start with s3://")
path_parts = s3_path[5:].split('/', 1)
bucket = path_parts[0]
prefix = path_parts[1] if len(path_parts) > 1 else ""
files = []
paginator = s3.get_paginator('list_objects_v2')
for page in paginator.paginate(Bucket=bucket, Prefix=prefix):
if 'Contents' in page:
for obj in page['Contents']:
key = obj['Key']
filename = key.split('/')[-1]
if not filename.startswith('appstatus'):
files.append(f"s3://{bucket}/{key}")
return files
def read_s3_file(s3_path):
"""Read content from S3 file."""
s3 = boto3.client('s3')
path_parts = s3_path[5:].split('/', 1)
bucket = path_parts[0]
key = path_parts[1]
response = s3.get_object(Bucket=bucket, Key=key)
return response['Body'].read().decode('utf-8')
def parse_event_log(content):
"""Parse event log content and extract shuffle metrics."""
shuffle_read_bytes = 0
shuffle_write_bytes = 0
shuffle_read_records = 0
shuffle_write_records = 0
for line in content.strip().split('\n'):
if not line.strip():
continue
try:
event = json.loads(line)
event_type = event.get('Event')
if event_type == 'SparkListenerTaskEnd':
task_metrics = event.get('Task Metrics', {})
# Shuffle read metrics
shuffle_read = task_metrics.get('Shuffle Read Metrics', {})
if shuffle_read:
remote_bytes = shuffle_read.get('Remote Bytes Read', 0)
local_bytes = shuffle_read.get('Local Bytes Read', 0)
shuffle_read_bytes += remote_bytes + local_bytes
shuffle_read_records += shuffle_read.get('Total Records Read', 0)
# Shuffle write metrics
shuffle_write = task_metrics.get('Shuffle Write Metrics', {})
if shuffle_write:
shuffle_write_bytes += shuffle_write.get('Shuffle Bytes Written', 0)
shuffle_write_records += shuffle_write.get('Shuffle Records Written', 0)
except json.JSONDecodeError:
continue
return {
'shuffle_read_bytes': shuffle_read_bytes,
'shuffle_write_bytes': shuffle_write_bytes,
'shuffle_read_records': shuffle_read_records,
'shuffle_write_records': shuffle_write_records
}
def process_job(application_id, job_id, event_log_base_path, logger):
"""Process a single job and return metrics."""
try:
event_log_path = f"{event_log_base_path.rstrip('/')}/applications/{application_id}/jobs/{job_id}/sparklogs/eventlog_v2_{job_id}/"
logger.info(f"Processing job {job_id}...")
files = list_s3_files(event_log_path)
total_shuffle_read_bytes = 0
total_shuffle_write_bytes = 0
total_shuffle_read_records = 0
total_shuffle_write_records = 0
for file_path in files:
content = read_s3_file(file_path)
metrics = parse_event_log(content)
total_shuffle_read_bytes += metrics['shuffle_read_bytes']
total_shuffle_write_bytes += metrics['shuffle_write_bytes']
total_shuffle_read_records += metrics['shuffle_read_records']
total_shuffle_write_records += metrics['shuffle_write_records']
return {
'application_id': application_id,
'job_id': job_id,
'shuffle_read_bytes': total_shuffle_read_bytes,
'shuffle_write_bytes': total_shuffle_write_bytes,
'shuffle_read_records': total_shuffle_read_records,
'shuffle_write_records': total_shuffle_write_records,
'shuffle_total_bytes': total_shuffle_read_bytes + total_shuffle_write_bytes,
'shuffle_total_records': total_shuffle_read_records + total_shuffle_write_records
}
except Exception as e:
logger.error(f"Error processing job {job_id}: {e}")
return {
'application_id': application_id,
'job_id': job_id,
'shuffle_read_bytes': 0,
'shuffle_write_bytes': 0,
'shuffle_read_records': 0,
'shuffle_write_records': 0,
'shuffle_total_bytes': 0,
'shuffle_total_records': 0
}
def main():
logger = setup_logging()
args = parse_args()
# Set default output filename if not provided
if not args.output:
args.output = f"{args.application_id}_shuffle.csv"
job_ids = [job_id.strip() for job_id in args.job_ids.split(',')]
logger.info(f"Processing {len(job_ids)} jobs with {args.threads} threads...")
results = []
with ThreadPoolExecutor(max_workers=args.threads) as executor:
futures = [
executor.submit(process_job, args.application_id, job_id, args.event_log_base_path, logger)
for job_id in job_ids
]
for future in futures:
results.append(future.result())
# Write to CSV
fieldnames = [
'application_id', 'job_id', 'shuffle_read_bytes', 'shuffle_write_bytes',
'shuffle_read_records', 'shuffle_write_records', 'shuffle_total_bytes', 'shuffle_total_records'
]
with open(args.output, 'w', newline='') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(results)
logger.info(f"Results written to {args.output}")
# Log summary
logger.info("Summary:")
for result in results:
logger.info(f"Job {result['job_id']}: "
f"Read {result['shuffle_read_bytes']:,} bytes, "
f"Write {result['shuffle_write_bytes']:,} bytes, "
f"Total {result['shuffle_total_bytes']:,} bytes")
if __name__ == "__main__":
main()
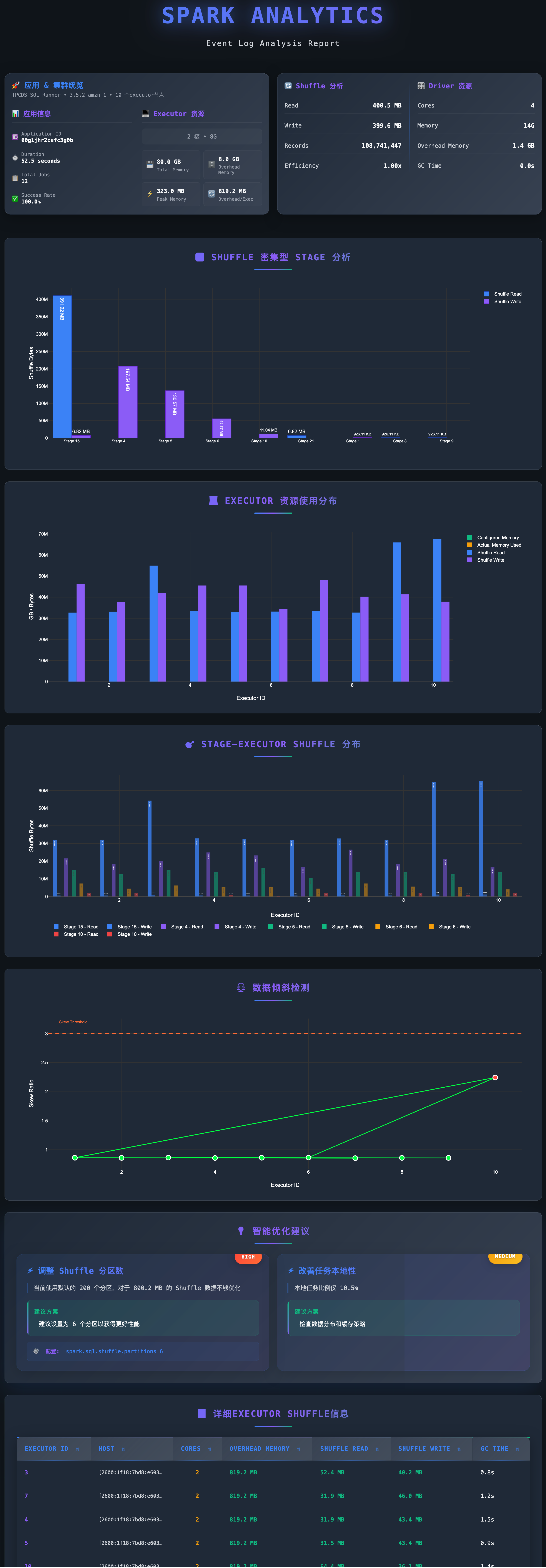
# 上边代码保存为analyze_spark_shuffle.py
# --application-id 是emr serverless的application id, --job-ids 是applicaiton中的job id,可以指定多个,多个可以并行解析
uv run python analyze_spark_shuffle.py \
--event-log-base-path s3://xxxxx/spark-event-log/ \
--application-id xxxxx \
--job-ids xxxx,xxxx \
--threads 5
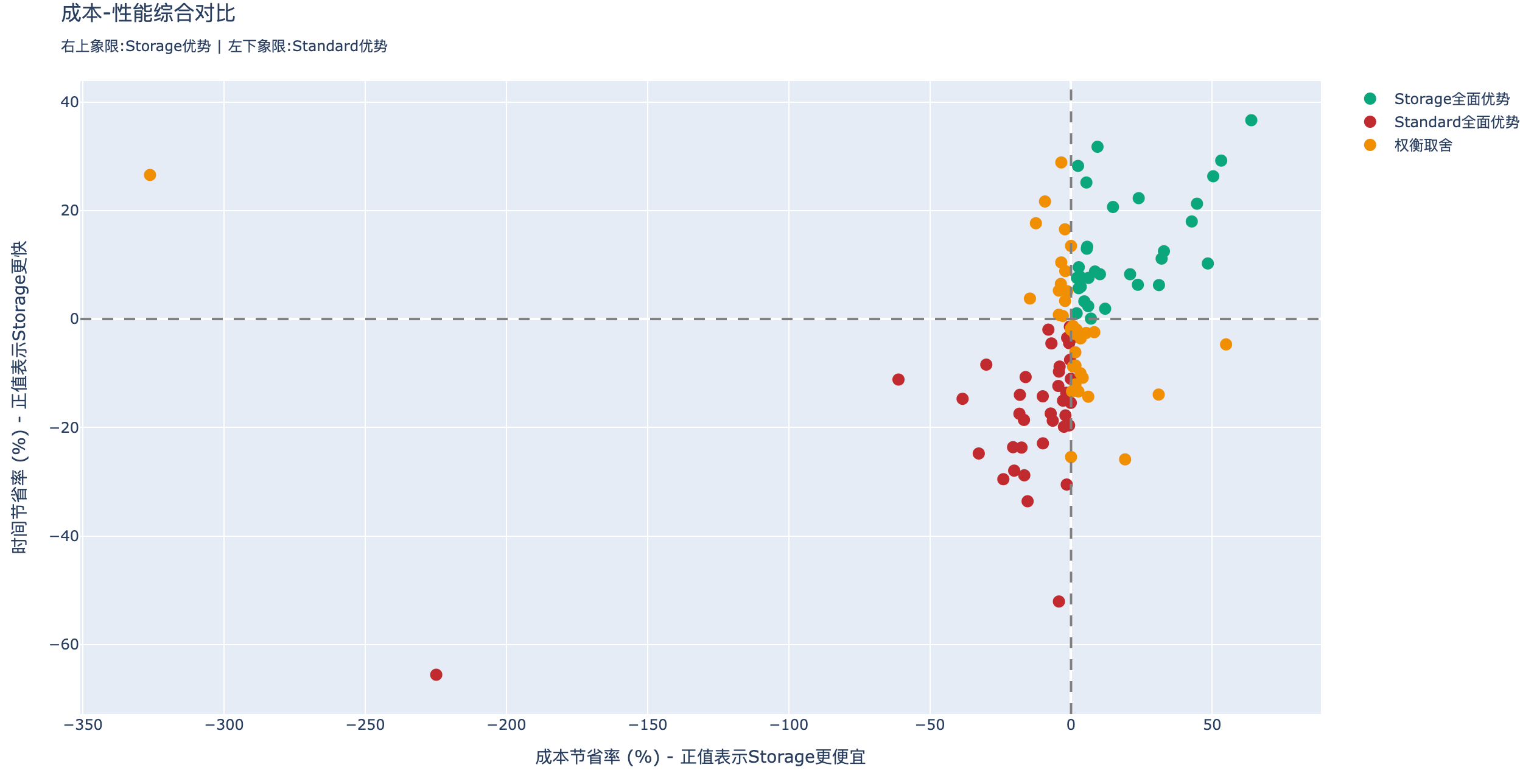
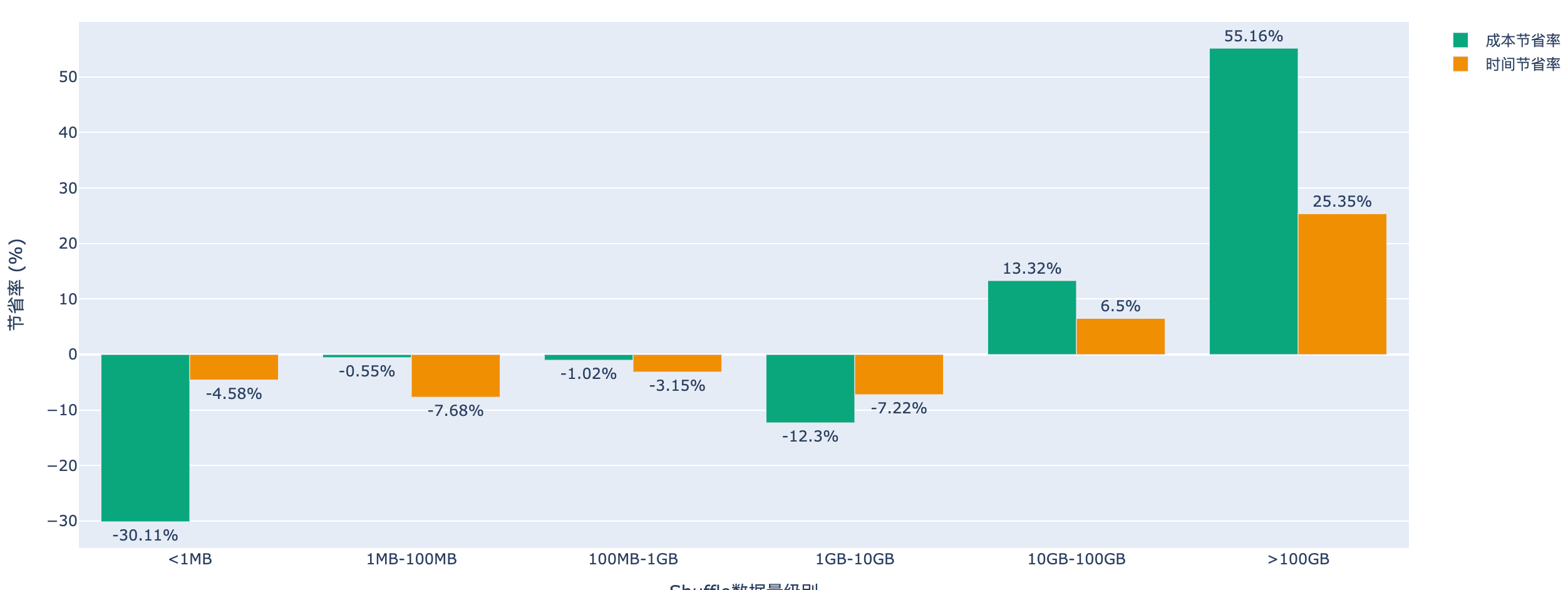
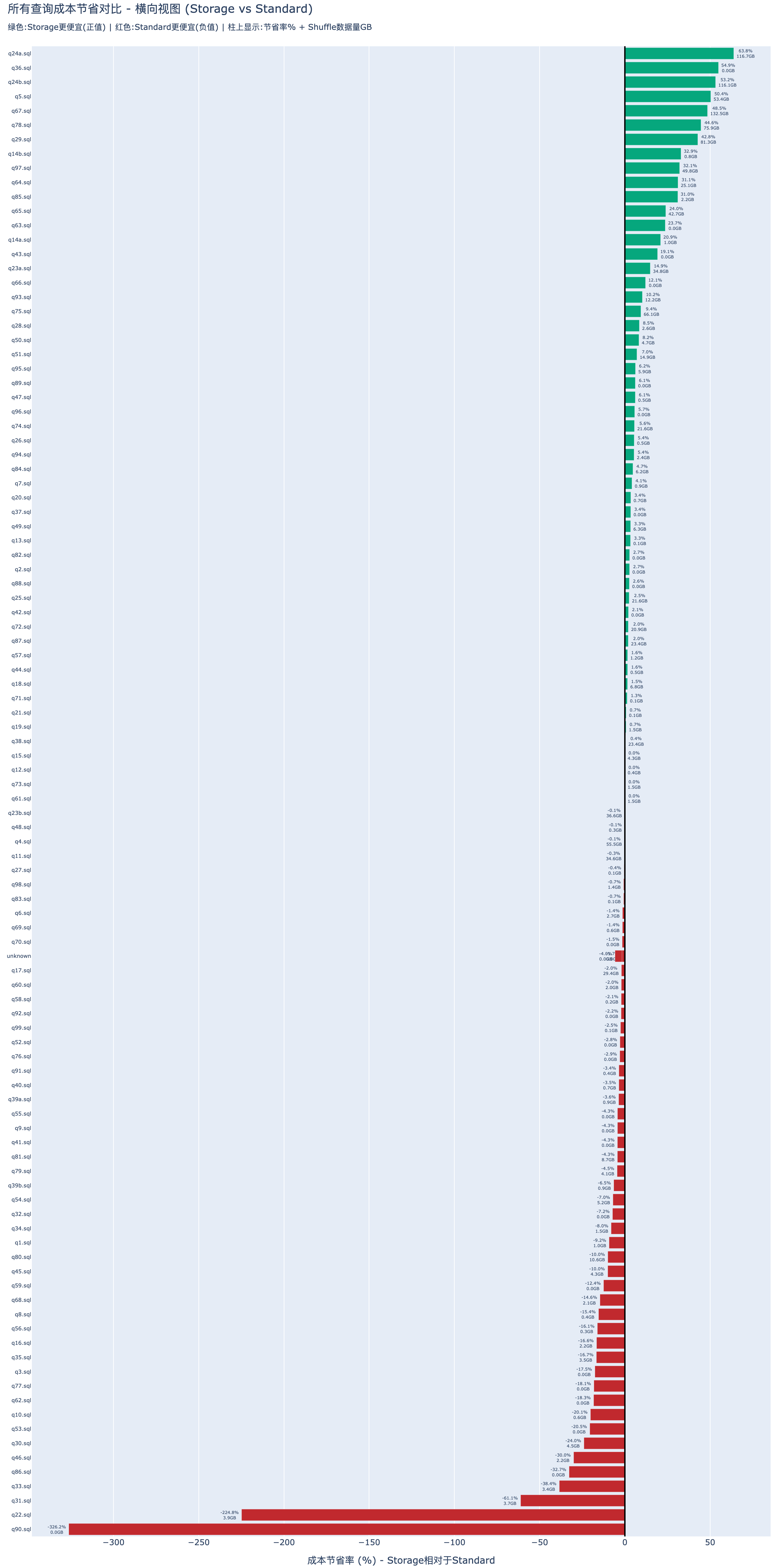
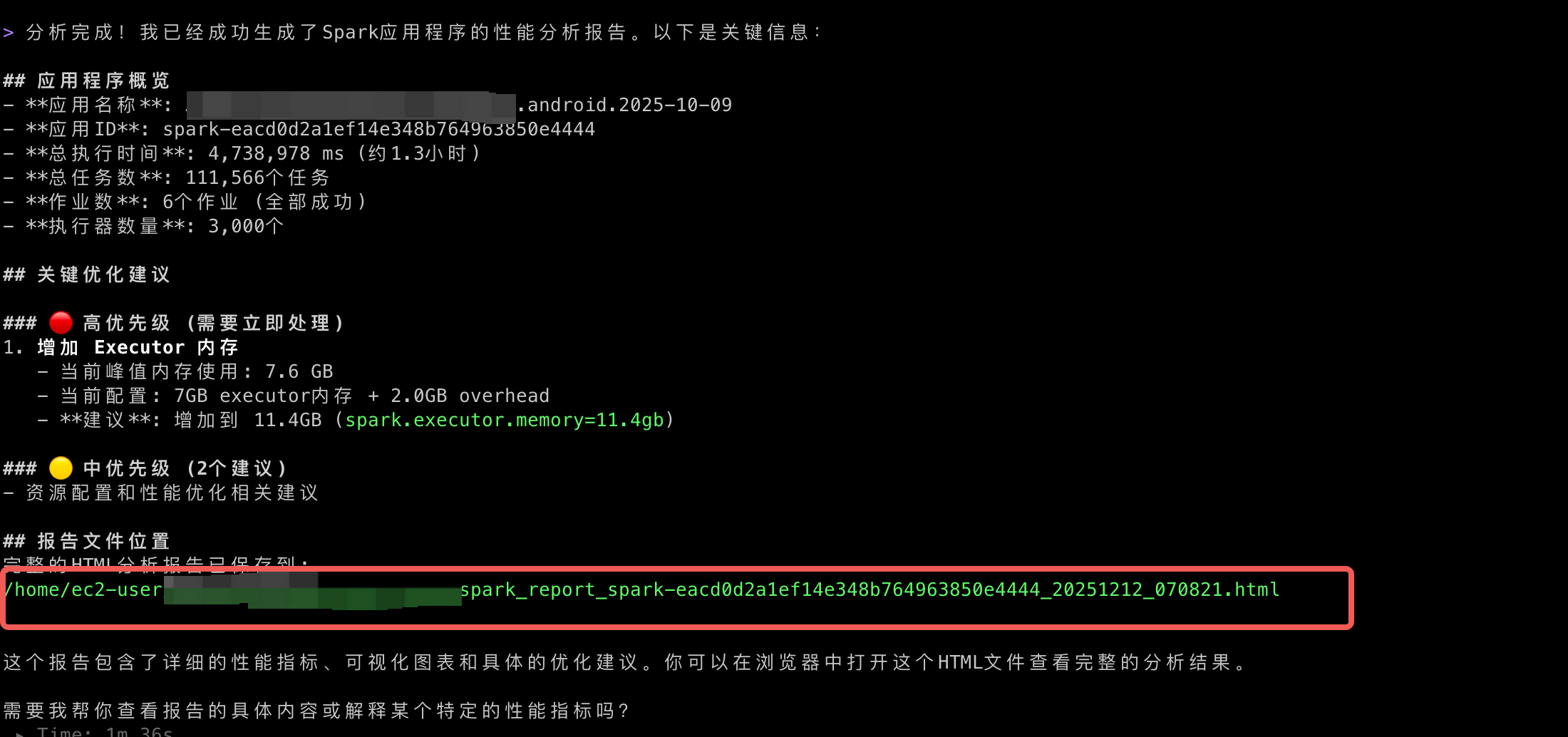
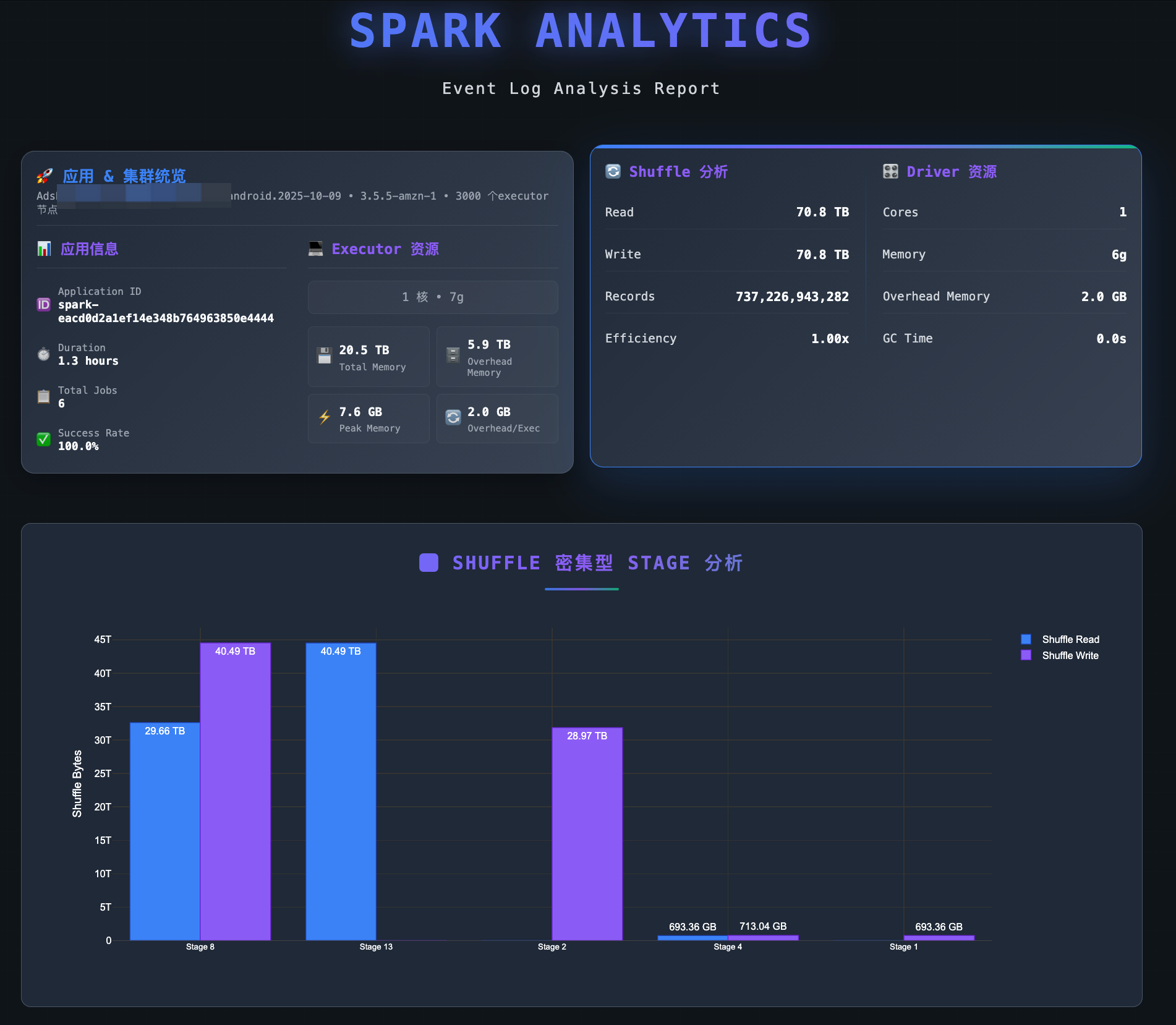
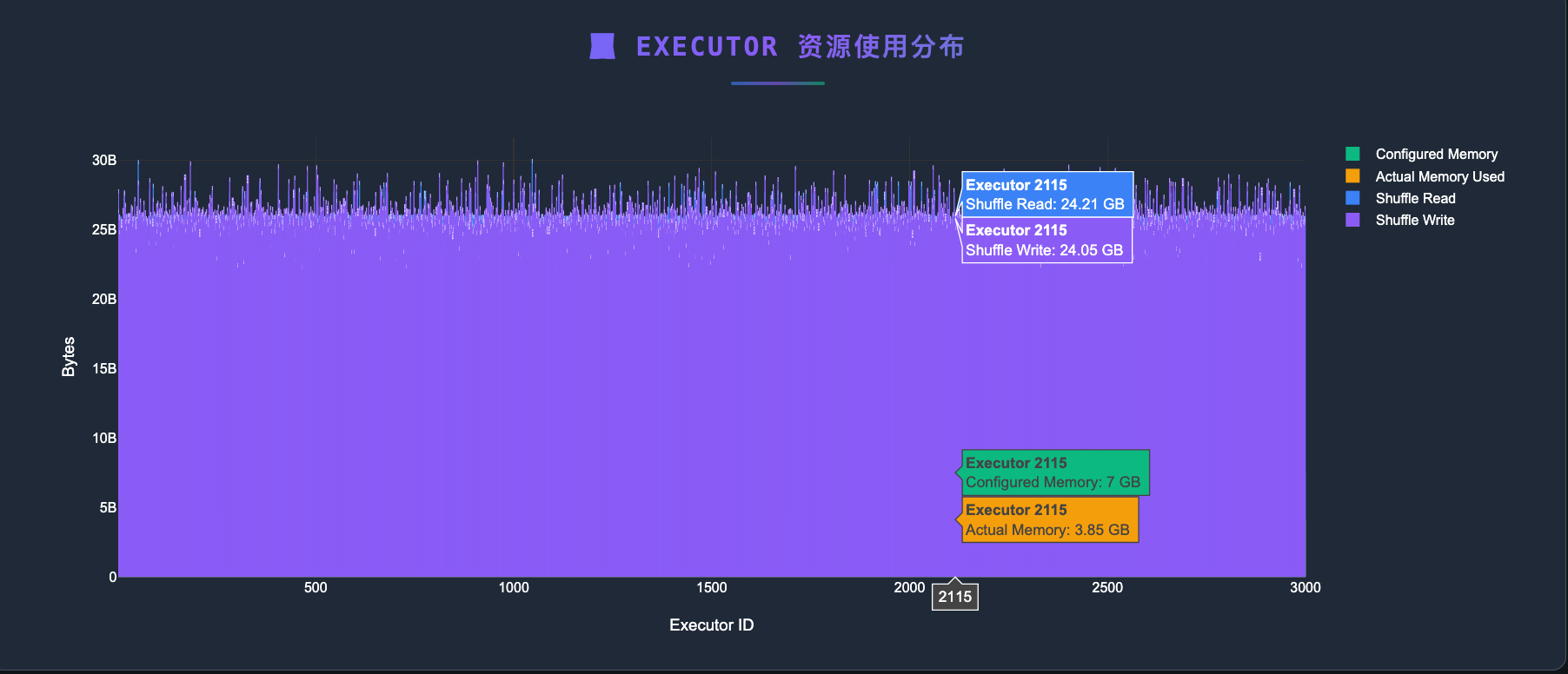
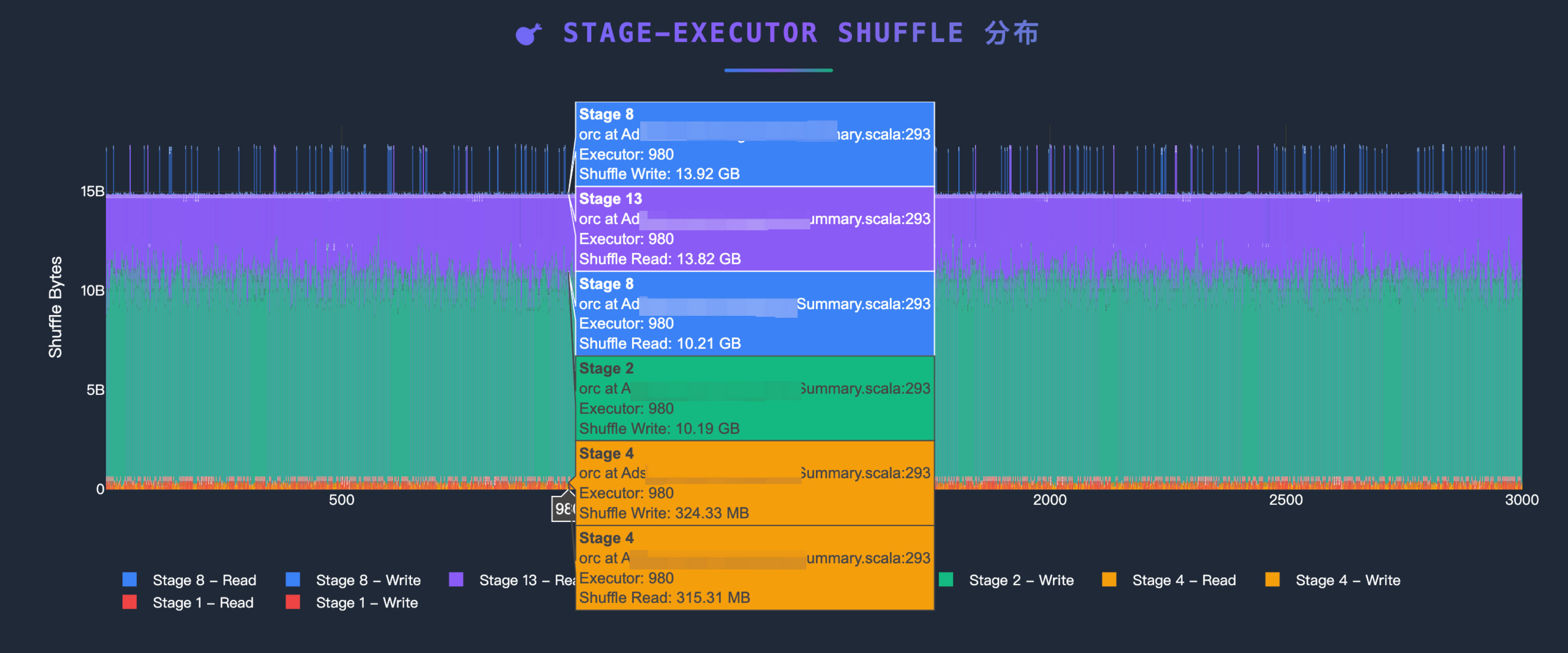
有了作业的Shuffle数据,就可以根据数据结合上文的分析判断,当前作业是否适合迁移到EMR Serverless.