亚马逊AWS官方博客
基于 Amazon EKS 采用 KubeBlocks 轻松拉起向量数据库 Qdrant
前言
生成式人工智能(Generative AI)的热潮引发了广泛的兴趣,也将向量数据库(Vector Database)市场推向了风口浪尖,众多向量数据库产品开始崭露头角,走入了公众的视野。
根据 IDC 的预测,到 2025 年,超过 80% 的业务数据将呈现非结构化形式,以文本、图像、音频、视频或其他格式存储。然而,处理大规模的非结构化数据存储和查询面临着极大的挑战。
在生成式 AI 和深度学习领域,通常的做法是将非结构化数据转换为向量形式进行存储,并利用向量相似性搜索技术来进行语义相关性检索。而快速存储、索引和搜索嵌入向量(Embedding)正是向量数据库的核心功能。
那么,什么是嵌入向量(Embedding)呢?简单来说,嵌入向量是由浮点数构成的向量表征。两个向量之间的距离表示它们的相关性,距离越接近表示相关性越高,距离越远表示相关性越低。如果两个嵌入向量相似,那就意味着它们代表的原始数据也是相似的。这一点与传统的关键词搜索有很大不同。
但是向量数据库作为有状态的数据库产品,管理起来是复杂的,如果要在生产环境使用,也会面临跟传统的 OLTP 和 OLAP 数据库一样的问题,比如数据安全、高可用、垂直/水平扩展性、监控告警、备份恢复等等。用户更关注大模型和向量数据库给业务带来的价值,而不是花费大量精力在管理大模型和向量数据库上,并且向量数据库作为比较新的一类产品,很多用户缺乏相关的领域知识,也给大模型+向量数据库技术栈的落地带来了非常大的挑战。
实际上,这些挑战是普遍的,任何一款带状态的数据类产品都存在这些问题,为了解决这些问题,云猿生开发的 KubeBlocks 对有状态服务进行了统一抽象,基于 k8s 的声明式 API,实现了用一个 operator,一套 API 管理用户的各种数据库,极大的简化了管理负担。KubeBlocks 构建于 k8s 之上,支持在 Amazon EKS 上部署。
EKS 是 AWS 提供的托管式 k8s 服务,它能够让我们轻松地在 AWS 上运行、扩展和管理 Kubernetes 集群,无须担心节点的部署、升级和维护,EKS 本身也是多可用区高可用部署,确保了集群在节点或可用区故障的情况下仍然可用。另外借助于 AWS 强大的资源池,我们可以在业务高峰和低谷时按需加减节点,充分保证了弹性和扩展性。
本文主要探讨基于 Amazon EKS,使用 KubeBlocks 轻松部署和管理目前非常流行的向量数据库 Qdrant。在 KubeBlocks 提供的向量数据库和 LLM 等 AIGC 基础设施之上,用户可以专注于构建自己的 AI 应用,极大的降低了应用开发者的负担,比如我们就仅仅用了 10 天时间开发的 AI 知识库应用 KubeChat,大家可以在线体验 chat.kubeblocks.io。
架构说明
KubeBlocks
Kubernetes 已成为容器编排事实上的标准,通过 Deployment+ReplicaSet,很好的支持了无状态应用的管理,可以方便的进行水平/垂直扩缩容、升降级发布等。但是相比无状态应用,有状态应用要复杂得多,尽管 StatefulSet 提供了稳定的持久存储和唯一的网络标识符,但这些能力对于复杂的有状态应用来说还远远不够,比如有状态应用内不同节点的服务能力一般是不同的,service selector 需要选择到正确的服务节点,并且和后端 pod 保持动态一致。另外比如水平缩容时,一般都要指定缩容哪个节点,而不是缩 StatefulSet 索引最大的节点。这些问题都是在 k8s 上管理有状态工作负载面临的挑战。
为了解决有状态应用在 k8s 上的这些问题,KubeBlocks 引入了 ReplicatedStateMachine,主要提供以下功能:
- 基于角色的更新顺序,减少了因升级版本、扩展和重启而导致的停机时间。
- 维护数据复制的状态并自动修复复制错误或延迟。
KubeBlocks 具有如下优势:
- 提供生产级性能、弹性、可扩展性和可观察性。
- 简化 day-2 运维操作,例如升级、扩容、监控、备份和恢复。
- 包含一个强大且直观的命令行工具。在几分钟内建立一个全栈、生产就绪的数据基础设施。
 |
凭借这些优势,对新出现的数据库,KubeBlocks 能够快速接入,只需要定义 ClusterDefinition、ClusterVersion 等几个 CR,配置一些运维脚本、参数和监控面板,就可以快速的在 KubeBlocks 拉起一个数据库集群,并且自动支持垂直/水平扩缩容、升降级、备份恢复等能力。
KubeBlocks 作为控制平面,支持多副本部署,一个副本挂掉后,其他副本可以自动切换继续服务,提供了极高的可用性。另外 KubeBlocks 控制平面和数据平面严格分离,即便把控制平面完全停掉,也只会影响创建/删除集群、升降级、扩缩容等运维操作,而不会影响数据平面的业务流量。
以向量数据库为例,在 LLM 大型语言模型的浪潮中,涌现出了很多相关产品,比如 Qdrant、Milvus、Weaviate 等,我们可以快速在 KubeBlocks 上构建 LLM 和向量数据库等 AIGC 基础设施。
Qdrant
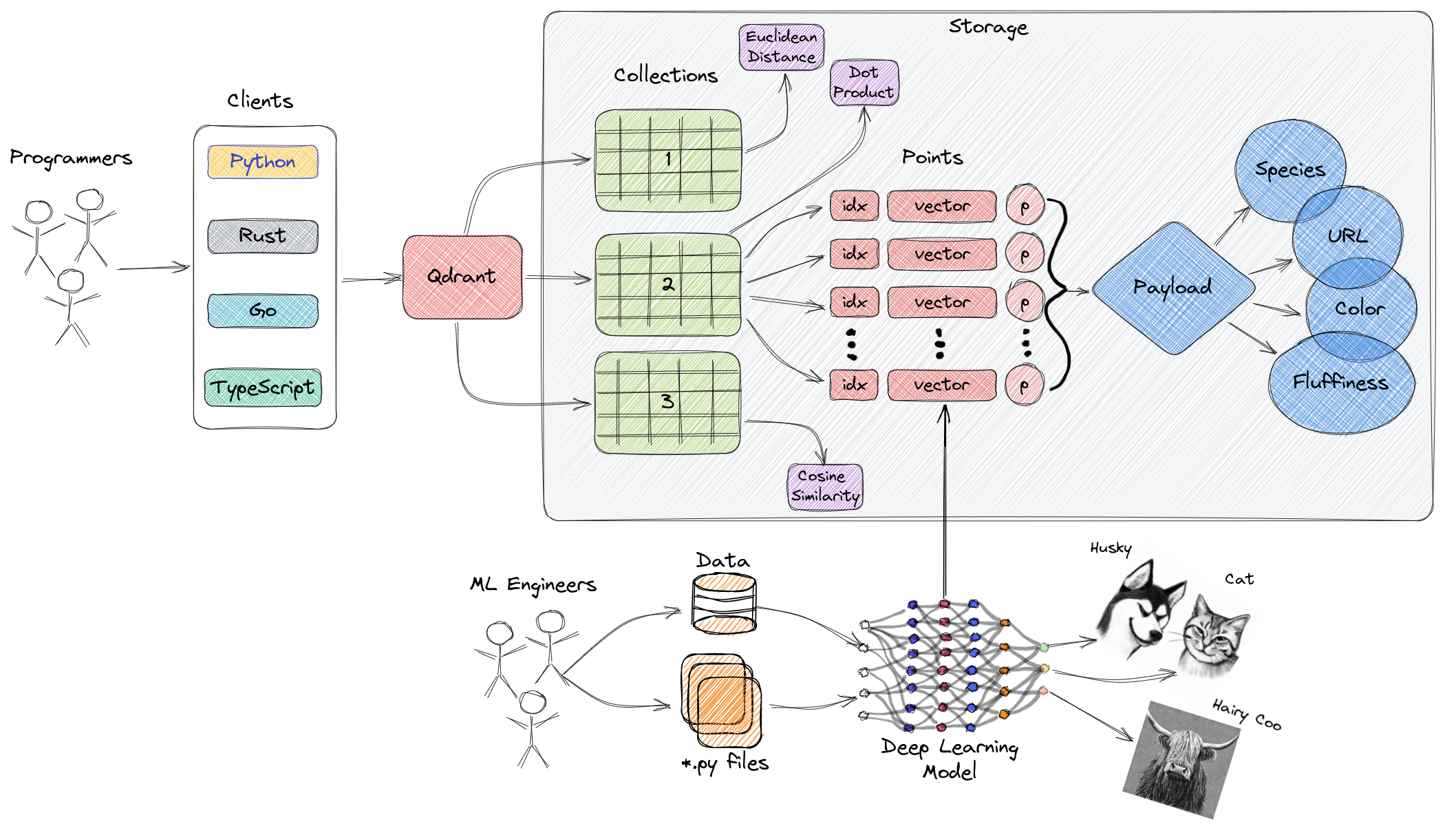
Qdrant 是一款开源向量数据库,用 Rust 开发,专门用于存储和检索大规模向量数据。它提供了快速的向量相似性搜索和高性能的向量索引功能,支持多种相似性度量和灵活的查询语法,整体架构如下:
 |
{kind=link}
在向量索引上,Qdrant 支持 HNSW(Hierarchical Navigable Small World)索引,可以快速的进行向量相似度搜索,Qdrant 还支持全文索引,可以根据关键字查询向量的关联的原始数据。在向量相似性度量上,支持 L2 欧氏距离、点积、余弦距离等算法。这些算法都是 collection 级别可配置的,非常灵活,可以根据业务特性选择合适的算法。
除了存储向量,向量数据库一般还支持存储向量对应的原始数据,比如文档,图片,语音,视频等,所以整体存储规模会比较大,对数据库读写性能要求很高,但是对一致性要求不高,Qdrant 可以对单个查询指定一致性要求,比如对于读,有以下级别:
- all,查询所有副本,返回所有副本上都有的数据。
- majority,查询所有副本,返回在大多数副本上都有的数据。
- quorum,随机查询多数副本,返回在这些副本上都有的数据。
- 1/2/3 等,查询指定数量的副本,返回在这些副本上都有的数据。
对于写,可以在 collection 层面配置副本数 replication_factor 以及最小写成功副本数 write_consistency_factor:
也可以在查询层面指定写顺序,比如:
- weak,可以任意写入,没有顺序要求,性能最好。
- medium,通过动态选出的 leader 执行写入操作,如果 leader 故障,切换到新的 leader 提供服务,性能中等。
- strong,通过固定的 leader 执行写入操作,提供最强的顺序一致性保证,但假如 leader 挂了,服务就不可用了,性能一般。
对顺序性要求高的应用,推荐使用 medium 或 strong 级别。
Qdrant 架构简单,组件很少,既可以单机 standalone 部署,用来开发测试,也可以以集群模式部署,用于生产环境。并且支持水平扩缩容,动态加减节点,轻松应对业务流量增减。
ClusterDefinition
KubeBlocks 构建在 k8s 之上,通过对各种数据类产品进行抽象,用一套 API 覆盖了 OLTP、OLAP、NoSQL、流式数据库等多种类型数据库,并且只有一个 operator,极大地降低了 k8s 之上管理有状态负载的复杂度,为用户提供了统一的交互。
新引擎接入 KubeBlocks 也非常简单,基本不用写任何代码,只需要根据 KubeBlocks 的 API,在 yaml 中定义清楚引擎的各种特性,即可具备完整的生命周期管理能力。
以 Qdrant 为例,引擎特性定义参见:https://github.com/apecloud/kubeblocks-addons/blob/main/addons/qdrant/templates/clusterdefinition.yaml。
其中包括对外提供服务的访问方式、监控指标采集方式、可用性探测方式等跟引擎密切相关的内容。
ClusterVersion
引擎特性一般定义了相对静态的信息,但是对于不同版本,我们还需要定义引擎版本,比如 mysql 5.6、5.7、8.0 等,每个版本的 binary,参数等可能会有不同。
在 KubeBlocks 中定义版本也非常简单,每个版本对应一个 ClusterVersion 对象,比如 Qdrant 我们就定义了一个版本,具体请参考:https://github.com/apecloud/kubeblocks-addons/blob/main/addons/qdrant/templates/clusterversion.yaml。
操作说明
有了 ClusterDefinition 和 ClusterVersion,接下来我们看下怎么创建 Qdrant 向量数据库,并对其进行操作。
安装 eksctl
eksctl 是一个简单的命令行工具,用于在 Amazon EKS 上创建和管理 Kubernetes 集群。eksctl 提供了为 Amazon EKS 创建包含节点的新集群的最快、最简单的方法。eksctl 的安装具体安装步骤请参考:https://eksctl.io/installation/。
创建 EKS 集群
请注意为替换 my-cluster 为实际的集群名,region-code 为实际的区域名:
只需要这一个命令就可以创建 EKS 集群,eksctl 也支持指定节点数量,AMI 镜像 Id,node group 配置等。执行这个命令后,eksctl 实际上会启动一个 CloudFormation 任务执行各种资源的创建,践行了 IaC 的理念。
安装 kbcli
执行以下命令,安装最新版本的 kbcli:
安装 KubeBlocks
kbcli 安装完毕后,执行以下命令,安装对应版本的 KubeBlocks:
KubeBlocks 安装完毕后,需要启用 qdrant addon:
创建
执行以下命令,创建单节点 Qdrant 集群:
如果数据量比较大,也可以设置 replicas 参数,创建多节点 Qdrant 集群:
等待集群创建完成。
连接
Qdrant 提供 http 和 grpc 两种协议供客户端访问,端口分别为 6333 和 6334。根据客户端在哪里,我们有几种连接方案。
注:请先在 AWS 上安装 aws loadbalancer controller。
- 如果客户端在 k8s 集群内,那么可以直接用
kbcli cluster describe qdrant获取集群的 ClusterIP 连接地址或者对应 k8s 集群内域名。 - 如果客户端在 k8s 集群外,但是和 Server 在同一个 VPC 中,那么可以执行命令
kbcli cluster expose qdrant --enable=true --type=vpc,为数据库集群获取一个 VPC LB 地址。 - 如果客户端在 VPC 之外,那么可以执行命令
kbcli cluster expose qdrant --enable=true --type=internet,为数据库集群开放一个公网可达的地址。
测试
向 Qdrant 集群中插入数据,首先需要创建一个 Collection,命名为 test_collection,向量维度为 4,采用 Cosine 余弦距离计算相似度:
返回结果:
执行以下命令,查看刚创建的 collection 的信息:
返回结果:
然后我们往 collection 里插入一些数据:
返回结果:
接下来测试一下搜索刚刚插入的数据,比如搜索跟向量[0.2,0.1,0.9,0.7]相似的数据:
返回结果:
搜索时,还可以添加额外的元数据过滤条件,比如在 city 等于 London 的点中,查找跟向量[0.2,0.1,0.9,0.7]相似的数据:
返回结果:
扩容
如果创建集群选择的是单节点,后来发现容量不够,需要扩容,KB 也是支持的,可以垂直扩容,也可以水平扩容。
我们先看垂直扩容,即增加 cpu 和 memory 资源,执行以下命令:
如果垂直扩容已经到了机器上线,我们还可以水平扩容增加节点,比如从单节点,扩容到 3 节点,执行以下命令:
磁盘扩容
如果磁盘空间不足了,可以通过 kbcli 对磁盘进行扩容:
启停
对于开发测试环境的集群,有时候不用了,希望能暂时释放计算资源,但是保留存储,可以通过如下命令,停止集群的所有 pod:
当有需要时,可以执行如下命令,重新启动集群:
KubeBlocks Cloud
除了用 kbcli 在命令行中管理数据库,用户也可以使用 KubeBlocks Cloud,在网页上操作数据库,具体可以访问 https://console.apecloud.cn/。