亚马逊AWS官方博客
使用Logstash在线迁移 Amazon OpenSearch Service
Amazon OpenSearch Service(以下简称 OpenSearch) 旨在帮助用户在AWS中轻松部署、运行和扩展 OpenSearch 集群。它支持多种使用场景,包括日志分析、向量引擎、网站搜索等,同时提供强大的可视化工具和集成能力。它的高扩展性、安全性、稳定性和机器学习支持能力,使得越来越多客户将其作为云上OpenSearch部署的首选,并催生了许多从自建ElasticSearch到托管OpenSearch的需求。
然而,ElasticSearch/OpenSearch虽然支持快照还原的方式来迁移集群,但由于本身没有binlog/changelog之类的机制,在线迁移难度较大。本文介绍了一种基于Logstash实现OpenSearch/ElasticSearch集群在线迁移的方案,该方案可以实现较低停机时间的数据迁移。
常见迁移方案
在迁移OpenSearch过程中,我们需要保证数据的一致性和业务的连续性,同时尽可能减少停机时间。因而在选择迁移方案时,我们需要综合考虑以下几个因素:
- 基础架构复杂度:迁移方案所需的基础设施和组件复杂程度
- 业务改造量:业务系统需要进行的代码修改量
- 业务停机时间:迁移过程中业务不可用的时间
- 迁移成本:包括人力成本、基础设施成本等
以下是几种常见的OpenSearch迁移方案的对比:
快照还原
快照还原是最基本的迁移方式,适用于可接受较长停机时间的场景。其优点是操作简单,速度快,不需要额外组件,且数据一致性高。快照还原的步骤可以参考AWS官方文档[1]. 同时,快照还原也是下述若干方案中最常用来进行基础数据离线迁移的方法。
需要注意的是,快照是向前兼容的,即只能接受将低版本集群快照恢复到高版本目标环境,同时OpenSearch也不再接受使用ElasticSearch 7.12以后版本的快照进行恢复,具体可参见版本兼容矩阵。
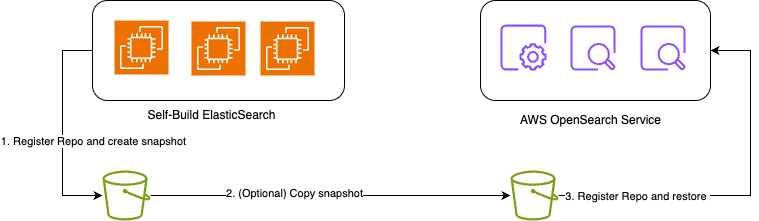 |
Figure 1
客户端双写
如果业务(客户端)可以进行双写改造,即同一个请求同时发往源和目标集群,那对底层就几乎没有什么改造工作。
它特别适用于如下基础架构:客户端→ Amazon Kinesis Data Stream → Amazon Kinesis Firehose → OpenSearch; 此时可以通过添加两个Firehose[2]传输来分别指向源与目标集群来达到双写目的。
它停机时间短,且数据一致性高; 但若业务没有通过类似如上管道流向OpenSearch,或者需要较好地支持删除操作,直接在客户端上进行双写架构的改造的工作量就较大。
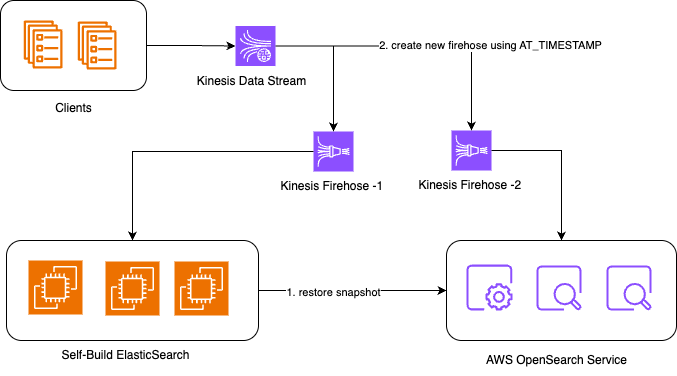 |
Figure 2
Reindex
OpenSearch 1.0或Elasticsearch 6.7及以上版本支持Remote reindex[3]操作,可用于跨集群index迁移。具体的操作步骤可参考如下:
- 迁移元数据(在目标集群上创建相同或符合新版本要求的index)
- 记当前时间A,执行reindex,将update_timestamp <= A的数据迁移到目标集群
- 记当前时间B,执行reindex,将update_timestamp > A, <=B的数据迁移到目标集群
- 执行若干轮使得两个集群的数据差异减小到可在业务容忍的停机窗口内完成迁移的程度
- 停止业务写入
- 记当前时间Y,执行reindex,将update_timestamp > X, <=Y的数据迁移到目标集群
- 切换业务endpoint到新集群,恢复写
它的优点是不需要额外组件,操作也相对简单;缺点是需要文档中有时间戳字段,不支持删除操作的同步,也有一定的停机时间。
对于无法使用快照还原进行基础数据迁移,且数据量较少时,我们也经常将reindex作为离线数据迁移的方法。
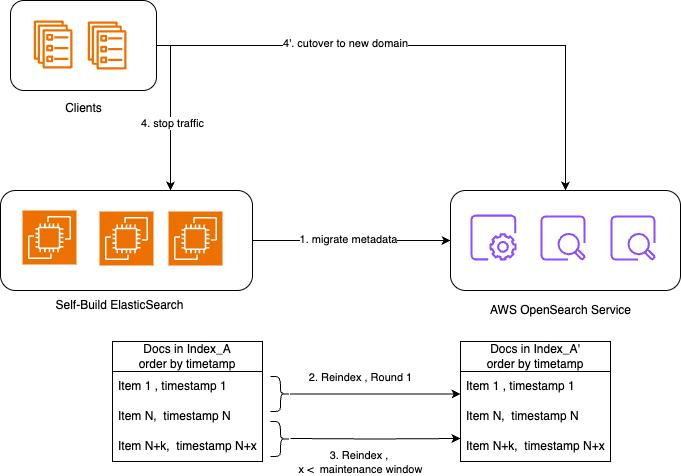 |
Figure 3
Alias/别名
对于类似日志的场景(写多读少)来说,业务研发往往能接受弃用或暂时不使用老数据。此时,则可以通过如下步骤,利用OpenSearch Alias机制[4]来实现迁移:
- 在目标集群下创建index,重命名时添加后缀(例如_v2)
- 业务停写,将endpoint修改为目标集群,并将数据写入到INDEX_NAME_v2下
- 使用快照还原或reindex,将源集群的index迁移到目标集群,使用INDEX_NAME_v1
- 在目标集群下配置索引Alias/别名,使用INDEX_NAME关联INDEX_NAME_v1和INDEX_NAME_v2
这是一个取巧的办法,它是优先保障新数据的写入,而牺牲掉老数据的可读性。
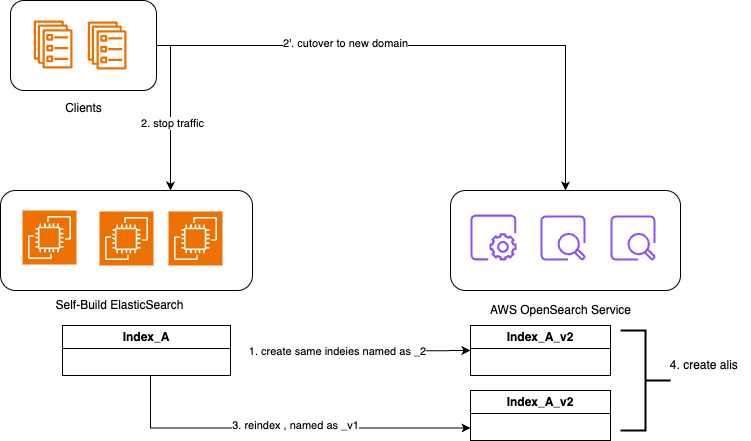 |
Figure 4
数据重放
OpenSearch官方还提供了一个方案[5],可用于捕获流量,一部分流入源端,另一部份在目标端重放,从而实现了类似业务双写的效果,适用于无法进行业务改造来实现双写,但是希望数据保证较高一致性的场景。但是该方案配置复杂,且涉及组件较多。
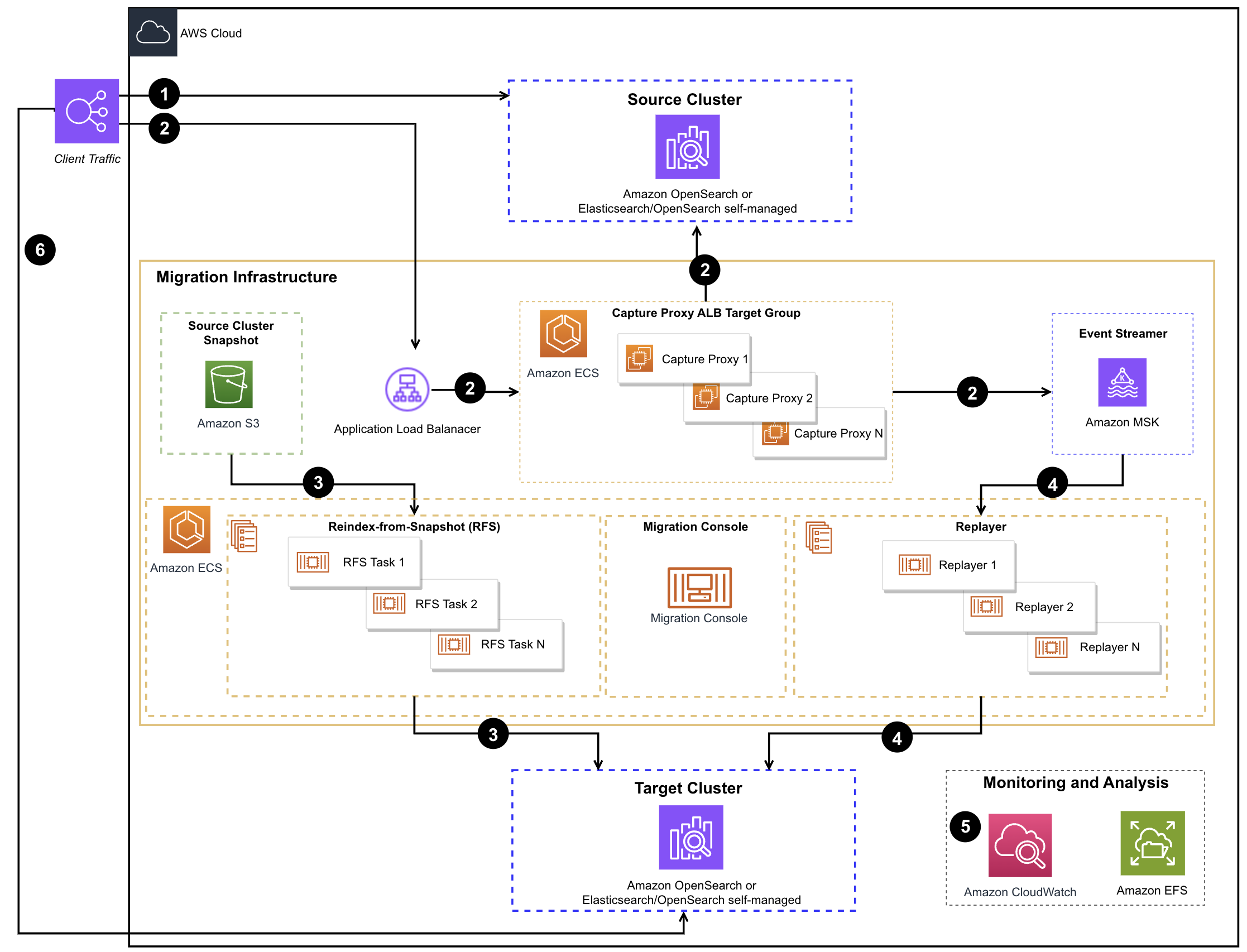 |
Figure 5
部署该方案的步骤较多,但可总结为如下几个主要步骤,具体需参考详细的方案文档:
- 使用AWS CloudFormation部署cdk-tookit环境
- 使用cdk-toolkit,创建方案所需资源,包括Amazon MSK,AmazonECS,AWS ALB等资源
- 进入cdk console, 验证结果
当完成以上环境配置后,在执行实际迁移时就可基本在cdk console中完成:
- 停止业务写入,使用cdk console创建快照 (console snapshot create) ,无需等待快照完成,即可进入下一步
- 切换业务endpoint到proxy url,恢复业务写入,此时数据会暂存在Amazon MSK 中
- 使用cdk console 迁移元数据 (console metadata migrate)
- 确认快照完成,使用cdk console 执行全量迁移 (console backfill start)
- 确认全量同步完成,使用cdk console 执行增量迁移 (console replay start)
- 确认数据几乎追平,再次停止业务写入,同时确认kafka lag为0 且源宿数据一致, 切换业务endpoint到目标端,恢复写入
在简述若干OpenSearch迁移方案之后,我们不难发现,要在保持较低的基础设施复杂度和实施复杂度的同时,尽可能降低业务停机时间是非常困难的。而本文将重点介绍使用Logstash进行OpenSearch在线迁移的方案,该方案在保持基础架构复杂度适中,业务改造量低的同时实现较低的业务停机时间,成本也在可接受范围内。
使用Logstash进行在线迁移
作为OpenSearch社区官方支持的工具,Logstash[6]天然具备快速查询数据、过滤、定时执行等能力,让它更适合作为迁移工具。虽然进行实时迁移时还是依赖timestamp相关字段,但其灵活性和可配置性使其成为一个很好的选择。
Logstash迁移架构
使用Logstash进行迁移主要涉及以下组件:
- 源OpenSearch/ElasticSearch集群
- 目标OpenSearch/ElasticSearch集群
- Logstash服务器,包括input, filter, output几个组件
- 迁移控制脚本 (Control Script)
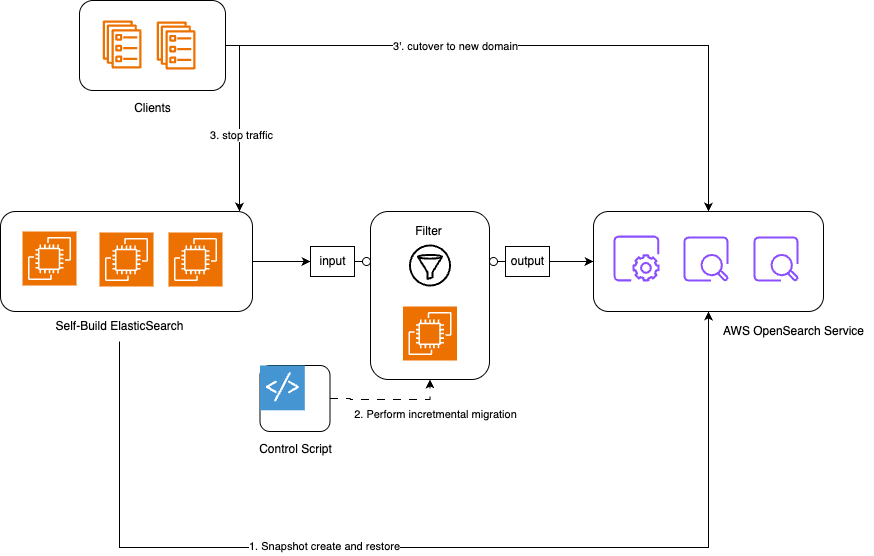 |
Figure 6
其中,控制脚本使得运维人员能较为便捷地使用Logstash,它具备如下几个核心能力:
- 自动确定迁移起始时间
- 优先使用源集群快照的开始时间作为增量迁移的起始点
- 如果没有快照,则使用目标集群最新数据的时间戳
- 如果目标集群没有数据,则使用源集群最早数据的时间戳
- 根据源集群和当前处理点的时间差,动态调整批次大小
- 使用checkpoint机制保存进度,自动记录每批次进度,脚本异常重启也可以实现断点续传
- 实时监控迁移进度,当差距较小时提醒用户切换,并自动完成最后一个批次的处理
控制脚本主要技术实现
OpenSearchMigrationHelper 类
- 管理与OpenSearch集群的连接
- 执行集群健康检查
- 查询时间戳数据
- 管理快照信息
LogStashHelper 类
- 管理Logstash进程
- 生成动态配置文件
- 执行增量同步
- 实现重试机制
OpenSearchMigrationWorkflowHelper 类
- 协调整个迁移流程
- 处理用户交互
安装与配置
- Logstash安装步骤
- 准备一台Amazon EC2实例,建议至少4核8G内存
- 安装Java环境(建议Java 11及其以上版本)
- 下载并安装Logstash . (建议使用7.10版本,以同时兼容ElasticSearch和OpenSearch )
- 迁移控制脚本安装与配置
- 编辑脚本py中相关配置
- 如果源或目标集群使用特殊认证方式,可编辑py,引入auth相关参数,例如
使用迁移控制脚本实施迁移
- 准备工作
- 将源集群的索引等元数据迁移到目标集群
- (可选)在源集群注册快照库并创建快照, 并将快照还原到目标集群,作为基础数据
- 增量迁移
- 执行迁移脚本 (python main.py)
- 确认脚本使用的迁移起始时间,输入y开始执行迁移
- 持续监控迁移进度,直到两个集群的数据差异减小到可接受范围
- 切换操作
- 停止业务写入
- 在迁移脚本中输入回车,执行最后一批数据同步
- 切换业务客户端的endpoint,指向新集群
- 恢复业务写入
迁移注意事项
在使用Logstash进行OpenSearch迁移时,需要注意以下几点:
- Logstash每批次使用基于相同的timestamp字段的查询条件来获取数据,若不同索引使用不同的timestamp字段,则需要拆分成多个具体迁移任务,并在Logstash模板和py中配置对应的源端index信息
- 索引结构兼容性: 需确保源集群和目标集群的索引结构兼容; 如果有字段类型变更,需要在Logstash的filter部分进行转换
- 网络连接: Logstash服务器需要能够同时访问源集群和目标集群; 对于AWS托管的OpenSearch服务,需要确保网络策略允许Logstash访问
- 资源需求: Logstash处理大量数据需要足够的内存和CPU资源, 建议根据数据量调整Logstash的JVM堆大小
- 监控与故障处理: 定期检查迁移日志和进度,以确保及时观察到切换指征; 如果迁移过程中断,可以通过进度文件恢复
- 数据验证: 迁移完成后,建议进行数据验证,确保数据一致性,例如可以通过比较源集群和目标集群的文档数量和最新时间戳进行初步验证
总结
本文深入分析了六种主流OpenSearch迁移方案,通过多维度对比帮助企业选择最适合的迁移策略:
| 方案名称 | 基础架构复杂度 | 迁移成本 | 业务改造量 | 业务停机时间 | 版本兼容要求 |
| 快照还原 | 低 | 低 | 低 | 长 | 高 |
| 客户端双写 | 中 | 中 | 高 | 短 | 低 |
| Reindex | 低 | 中 | 低 | 中 | 低 |
| Alias | 低 | 低 | 中 | 中 | 低 |
| 数据重放 | 高 | 高 | 低 | 短 | 中 |
| Logstash | 中 | 中 | 低 | 短 | 中 |
在平衡运维复杂度与业务连续性的需求下,本文重点推荐了基于Logstash的在线迁移方案。该方案在众多迁移策略中脱颖而出,通过科学的迁移规划和充分的预演测试,Logstash方案能够实现OpenSearch/Elasticsearch集群的无缝平滑迁移,将业务影响降至最低,为企业数字化转型提供可靠的技术保障。
参考文档
- [1] https://docs.aws.amazon.com/opensearch-service/latest/developerguide/managedomains-snapshots.html
- [2] https://docs.aws.amazon.com/firehose/latest/dev/writing-with-kinesis-streams.html
- [3] https://docs.aws.amazon.com/opensearch-service/latest/developerguide/remote-reindex.html
- [4] https://docs.opensearch.org/latest/im-plugin/index-alias/
- [5] https://docs.opensearch.org/latest/migration-assistant/architecture/
- [6] https://docs.opensearch.org.cn/docs/latest/tools/logstash/index/
- [7] https://github.com/dan12315/opensearch_migration
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心: 云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
