- Amazon CloudWatch
- Features
- Infrastructure Observability
Infrastructure Observability
Optimize your compute, network, database, and AI workload performance
Overview
Identify issues and root causes, optimize performance, and secure your environment without complex configuration. Visualize relationships between infrastructure and applications using CloudWatch dashboards for containers, networks, databases, and AWS services. Track system health at a glance and eliminate screen switching while maintaining cost efficiency.
See your entire AWS world
Monitor your compute, databases, serverless, storage, network, and more AWS services with out-of-the-box dashboards that eliminate monitoring gaps. Visualize relationships and dependencies across applications and infrastructure with ease. Track performance across services including Amazon EC2, Amazon EKS, Amazon S3, AWS Lambda, Amazon RDS, and Amazon Virtual Private Cloud (VPC), among many more.
Learn more about Infrastructure monitoring documentation
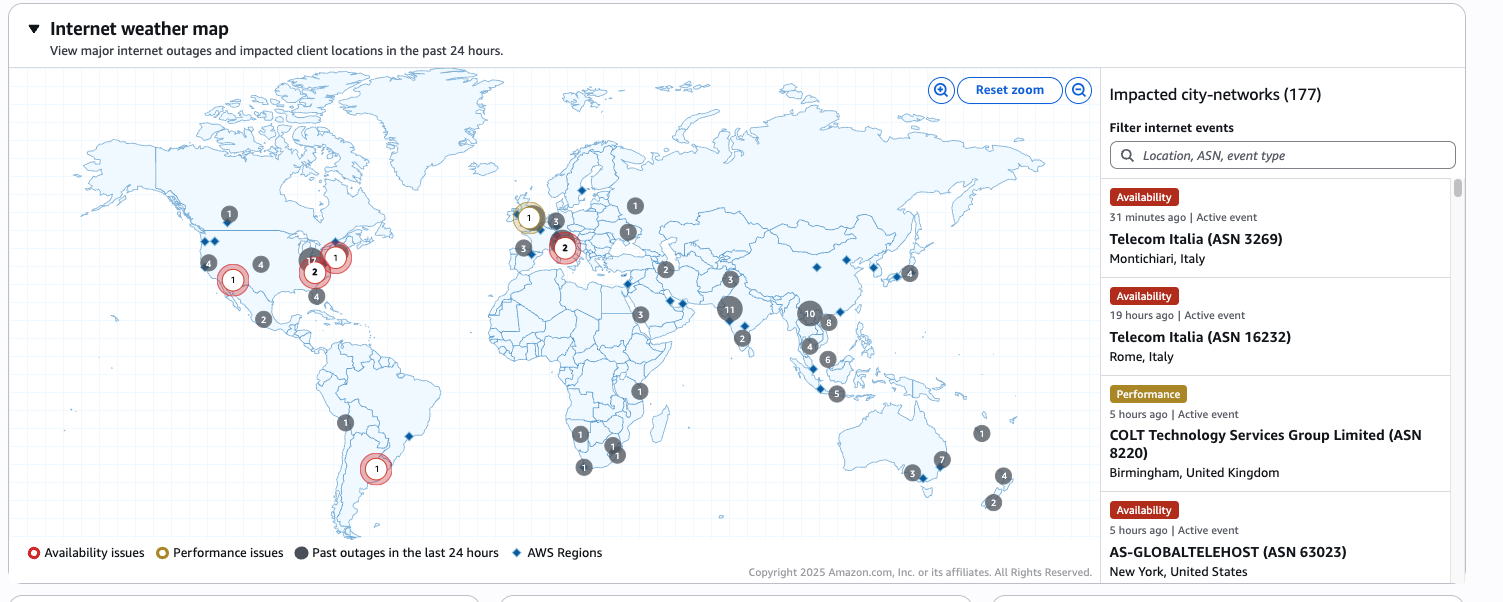
Understand infrastructure health in seconds
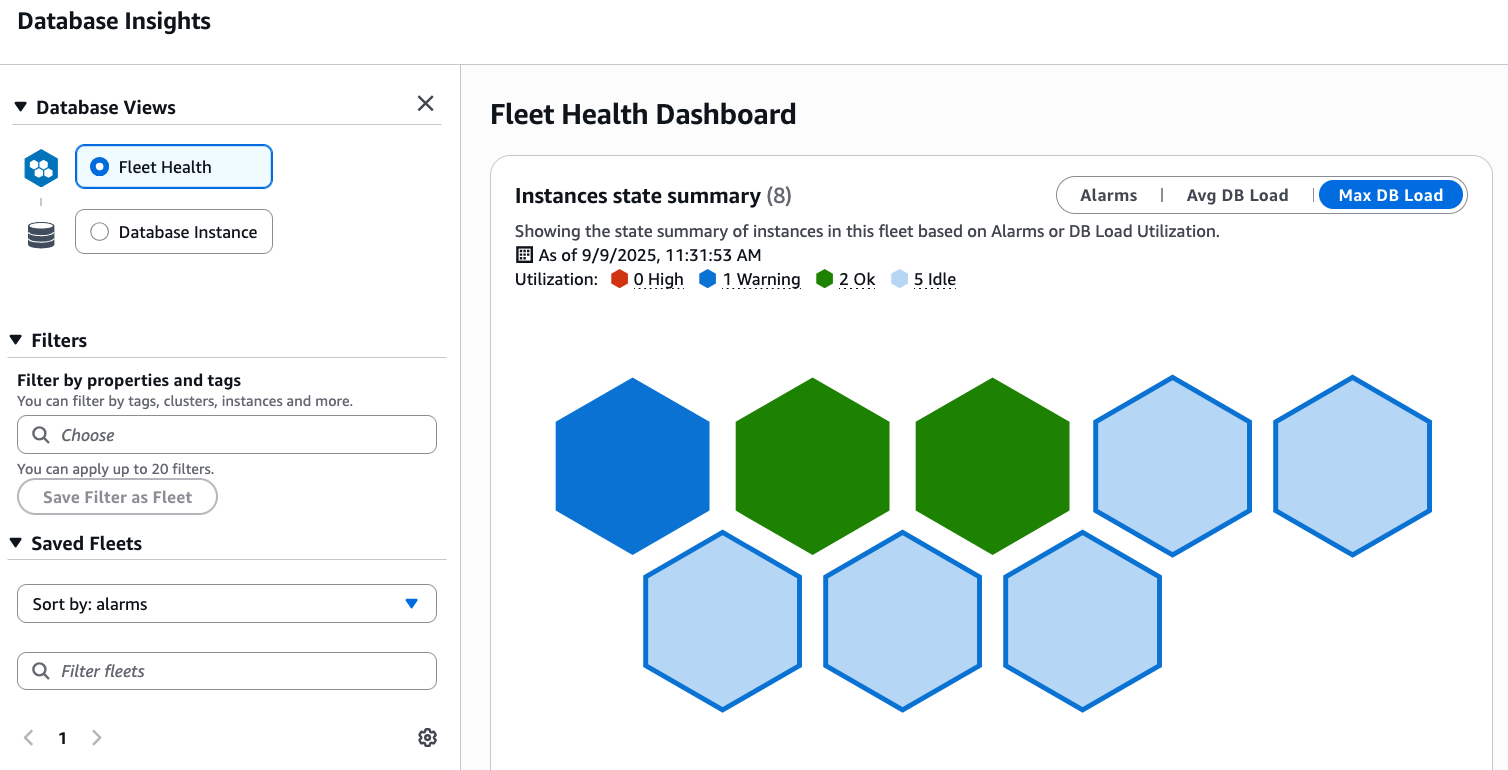
Gain complete visibility into AWS-managed databases with Database Insights, which automatically discovers and collects logs, metrics, and traces from Amazon RDS and Amazon Aurora to troubleshoot performance issues faster. Track container performance with Enhanced Container Insights, providing real-time metrics for Amazon ECS and Amazon EKS at the task and container level. Monitor AWS Lambda functions with Lambda Insights, which automatically collects and aggregates system and diagnostic metrics to identify performance bottlenecks and optimize function execution.
Watch the Database Insights interactive demo
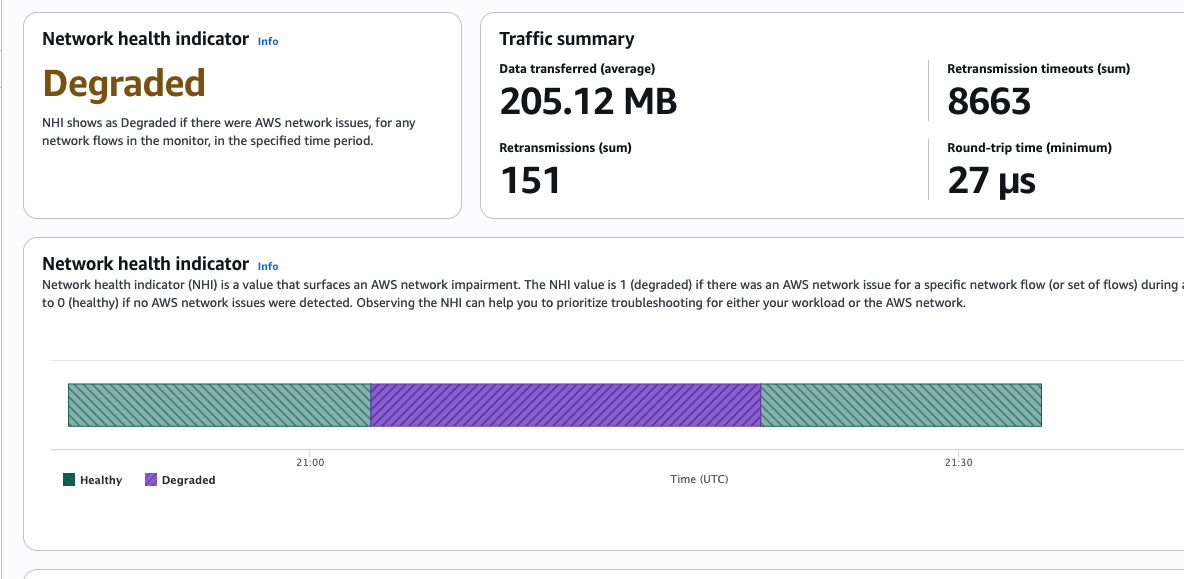
Stop guessing, start fixing network issues
Identify root causes faster with network flow analysis. Visualize traffic patterns across your Amazon VPC, Amazon EC2, Amazon EKS, and AWS Lambda functions to pinpoint connectivity issues and performance bottlenecks. Analyze network dependencies in real time to isolate impacted components quickly, reducing mean time to resolution without switching between tools.
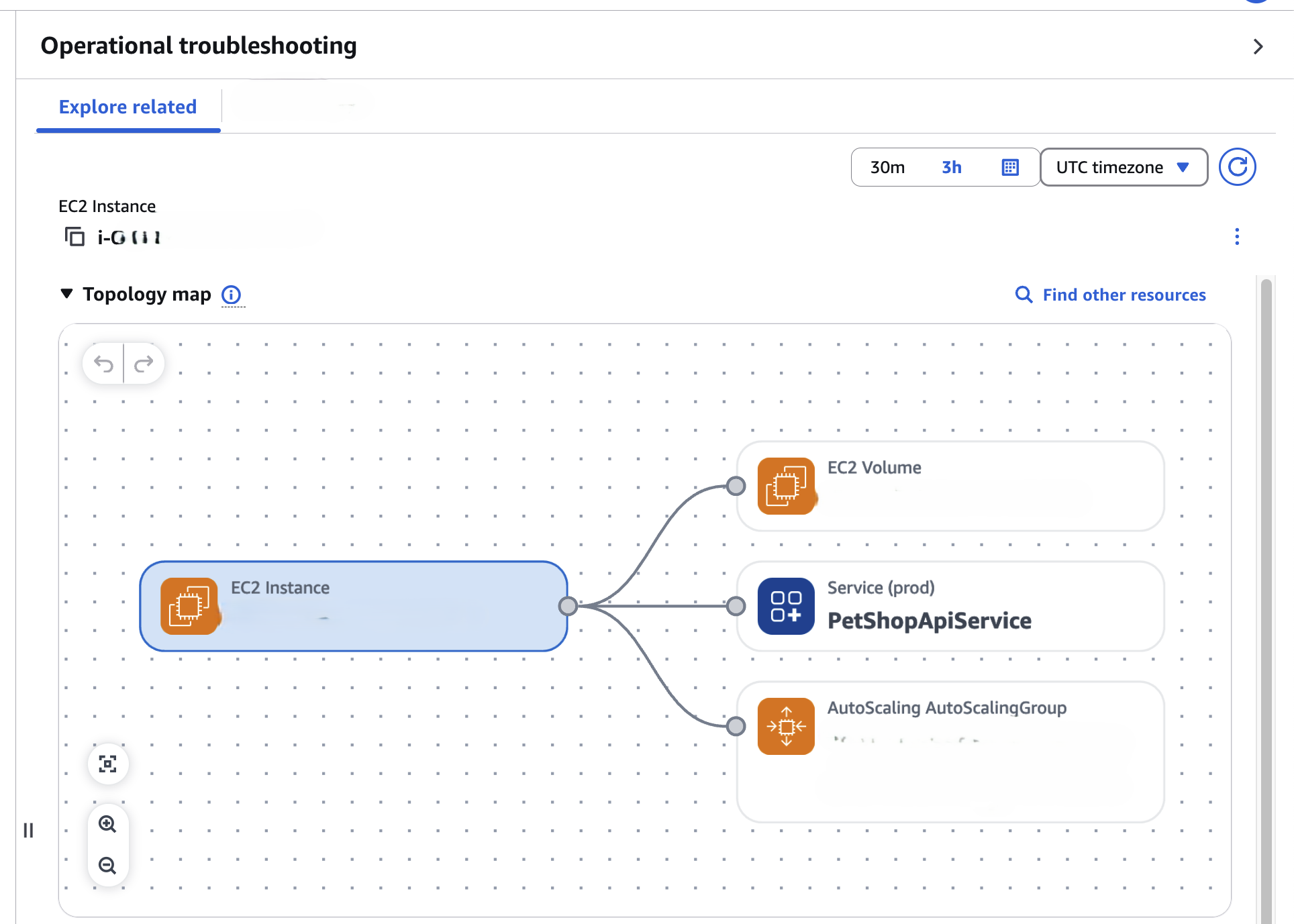
Scale smart and perform better
Optimize infrastructure performance by analyzing CloudWatch metrics for CPU, memory, and network utilization. Right-size EC2 instances, RDS databases, and EKS clusters automatically to maintain peak performance while reducing unnecessary expense.
Featured Services and Solutions
Customers
EA Reduces Mean-time-to-detect Internet Issues Using Amazon CloudWatch
"EA Sports partnered with AWS to beta test Amazon CloudWatch Internet Monitor to help address several of EA Sports’ core priorities. One of these priorities was to reduce their mean-time-to-detect internet issues by accurately, and with confidence, identifying user drops caused by internet connectivity issues. They also wanted to detect whether application performance issues were due to internet fluctuations or the AWS network, and to understand the impact to the game stack. Finally, it was important to them to dissect specific traffic paths that ingress globally to EA games, to help them understand where and how users connect to them. Anomaly detection for user impact has typically taken a lot of time, and diagnosing issues often."
Peter Vido, Network Architect, Electronic Arts (EA)
SnapLogic accelerates scale and performance using AWS Observability
As a leading enterprise integration platform (iPaaS), SnapLogic gains a unified view of its cloud-native operations through Amazon CloudWatch. Using CloudWatch Container Insights, SnapLogic achieves real-time monitoring and automated scaling across its infrastructure.
SnapLogic's AI solution, SnapGPT, streamlines development workflows while ensuring seamless scalability. By leveraging Amazon Bedrock, SnapLogic transformed a European enterprise's contract analysis process, reducing mismatch resolution time to just 24 hours—preventing millions in potential revenue losses.
Optimizing Costs and Promoting Innovation Using Amazon CloudWatch with Wix
Learn how software company Wix is taking an innovative approach to financial engineering using Amazon CloudWatch.
Read the case study
