Amazon SageMaker HyperPod 功能
在数千个人工智能加速器上扩展和加速生成式人工智能模型的开发
无检查点训练
Amazon SageMaker HyperPod 上的无检查点训练能够在几分钟内从基础设施故障中自动恢复,无需人工干预。它缓解了因故障恢复而需要进行的作业级别的检查点重启的情况,这种重启方式需要暂停整个集群、修复问题并从保存的检查点中恢复。无检查点训练在出现故障的情况下仍能保持训练的顺利进行,因为 SageMaker HyperPod 会自动更换故障组件,并通过在运行正常的人工智能加速器之间使用模型和优化器状态的点对点传输来恢复训练。它能够在拥有数千个人工智能加速器的集群上实现超过 95% 的训练吞吐量。 通过无检查点训练,节省数百万的计算成本,将训练规模扩展至数千个人工智能加速器,并能更快地将模型投入生产。
弹性训练
在 Amazon SageMaker HyperPod 上进行的弹性训练会根据计算资源的可用性自动扩展训练作业,每周可节省以往用于重新配置训练作业的数小时工程时间。对于人工智能加速器的需求会随着推理工作负载随流量模式的变化而不断波动,随着已完成实验的发布资源,以及新的训练作业调整工作负载优先级而发生变化。SageMaker HyperPod 能够动态扩展正在运行的训练作业,以吸纳闲置的人工智能加速器,从而最大限度地提高基础设施利用率。当推理或评估等优先级较高的工作负载需要资源时,训练会相应缩减规模,以使用较少的资源继续进行,而不至于完全停止,从而根据通过任务治理策略所设定的优先级来提供所需的容量。弹性训练能够帮助您加快人工智能模型的开发进程,同时还能减少因计算资源未充分利用而导致的成本超支问题。
任务治理
灵活的训练计划
Amazon SageMaker HyperPod 竞价型实例
借助 SageMaker HyperPod 上的竞价型实例,您能够以显著降低的成本访问计算容量。竞价型实例非常适合批量推理作业等容错工作负载。价格因区域和实例类型而异,与 SageMaker HyperPod 按需定价相比,通常提供高达 90% 的折扣。竞价型实例的价格由 Amazon EC2 设置,并根据竞价型实例容量的长期供求趋势逐步调整。您将支付实例运行期间生效的竞价价格,无需预先承诺。要详细了解预估的竞价型实例价格和实例可用性,请访问 EC2 竞价型实例定价页面。请注意,只有同样支持 HyperPod 的实例才能在 HyperPod 上竞价使用。
用于自定义模型的优化方案
使用 SageMaker HyperPod 方案,各种技能水平的数据科学家和开发人员都能从最先进的性能中获益,并且可以快速开始训练和微调公开可用的基础模型,包括 Llama、Mixtral、Mistral 和 DeepSeek 模型。此外,您还可以利用一系列技术对 Amazon Nova 模型(包括 Nova Micro、Nova Lite 和 Nova Pro)进行定制,这些技术包括监督式微调(SFT)、知识蒸馏、直接偏好优化(DPO)、近端策略优化以及持续预训练,并支持在 SFT、蒸馏和 DPO 过程中选择参数高效或完整模型训练方式。每个配方都包含一个已经过 AWS 测试的训练堆栈,从而为您节省数周繁琐的测试工作,无需反复测试不同的模型配置。您可以进行单行配方更改,以便在基于 GPU 的实例和基于 AWS Trainium 的实例之间切换,还可以启用自动模型检查点以便提高训练弹性,并在 SageMaker HyperPod 上的生产环境中运行工作负载。
Amazon Nova Forge 是一项业界首创的计划,能够让各个组织以极其轻松、经济高效的方式,使用 Nova 来构建自己的前沿模型。从 Nova 模型的中间检查点获取信息和进行训练,在训练期间将 Amazon 的精选数据集与专有数据混合在一起,并使用 SageMaker HyperPod 配方来训练您自己的模型。借助 Nova Forge,您可以利用自身企业的数据来解锁针对特定应用场景的智能分析结果,并实现任务的性能优化和成本降低。
高性能分布式训练
高级可观测性和实验工具
SageMaker HyperPod 的可观测性功能提供了预配置在 Amazon Managed Grafana 中的统一控制面板,其监测数据会自动发布到 Amazon Managed Prometheus 工作区中。您可以在一个视图中查看实时性能指标、资源使用情况和集群运行状况,从而使各个团队能够迅速发现瓶颈、避免代价高昂的延误,并优化计算资源。SageMaker HyperPod 还与 Amazon CloudWatch Container Insights 相集成,以便您更深入地了解集群的性能、运行状况和使用情况。SageMaker 中的托管式 TensorBoard 通过可视化模型架构来识别和修复整合问题,从而帮助您缩短开发时间。SageMaker 中的托管式 MLflow 可帮助您高效地大规模管理实验。
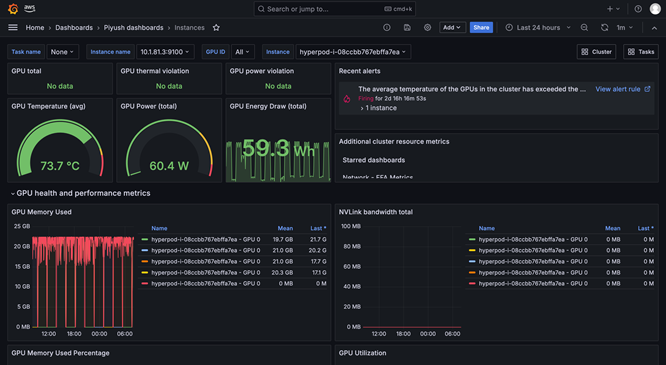
工作负载调度和编排
自动集群运行状况检查和修复
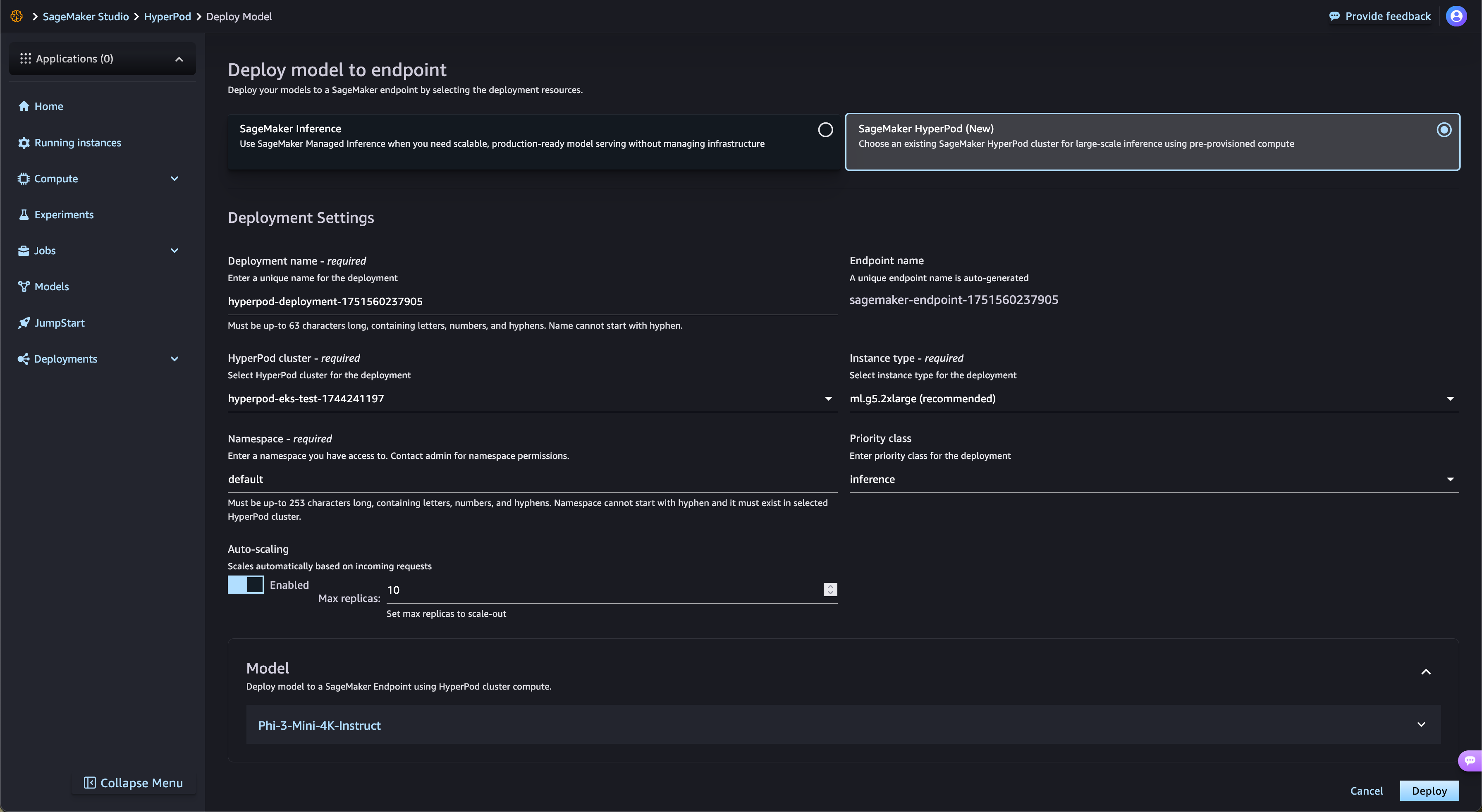
加速从 SageMaker Jumpstart 部署开源权重模型
SageMaker HyperPod 自动以经过简化的方式部署来自 SageMaker JumpStart 的开源权重基础模型以及来自 Amazon S3 和 Amazon FSx 的经过微调的模型。SageMaker HyperPod 可自动预置所需的基础设施并设置端点,从而省去了手动预置的步骤。借助 SageMaker HyperPod 任务治理功能,端点流量将得到持续监控,并能动态调整计算资源,同时还会将全面的性能指标发布到可观测性控制面板上,以便进行实时监控和优化。
托管分层检查点
SageMaker HyperPod 托管分层检查点使用 CPU 内存来存储频繁的检查点以实现快速恢复,同时定期将数据保存到 Amazon Simple Storage Service(Amazon S3)以实现长期持久性。这种混合方法可以最大限度地减少训练损失,并显著缩短故障后恢复训练的时间。客户可以在内存和永久存储层上配置检查点频率和保留策略。通过经常存储在内存中,客户可以快速恢复,同时最大限度地降低存储成本。通过与 PyTorch 的分布式检查点(DCP)集成,客户只需几行代码即可轻松实施检查点,同时获得内存存储的性能优势。
通过 GPU 分区实现资源的最大化利用
SageMaker HyperPod 使管理员能够将 GPU 资源划分成更小且独立的计算单元,从而最大限度地提高 GPU 的利用率。您可以在单个 GPU 上运行各种生成式人工智能任务,而无需将完整的 GPU 专门用于那些仅需要少量资源的任务。通过实时性能指标以及各 GPU 分区间的资源使用情况监测,您可以清晰了解任务是如何使用计算资源的。这种优化的分配方式和简化的设置能够加快生成式人工智能的开发进程,提高 GPU 的利用率,并在各任务中大规模实现高效的 GPU 资源使用率。
找到今天要查找的内容了吗?
请提供您的意见,以便我们改进网页内容的质量