Blog de Amazon Web Services (AWS)
Entender los patrones de resiliencia y las consideraciones claves para arquitecturar eficientemente en la nube
En el caso de Example Corp, poseen diversas aplicaciones con distintos niveles de criticidad, cada una con necesidades distintas en cuanto a resiliencia, complejidad y costos. Ante múltiples opciones para arquitecturar sus cargas de trabajo, surge la pregunta: ¿Cuál opción se adapta mejor a sus necesidades? ¿Qué consideraciones son fundamentales al elegir los patrones más apropiados para sus aplicaciones?
Para ayudar a responder estas preguntas, discutiremos los cinco patrones de resiliencia en la Figura 1 y los factores a considerar al implementarlos: 1) complejidad del diseño, 2) costo de implementación, 3) esfuerzo operativo, 4) esfuerzo de seguridad y 5) impacto ambiental. Estos aspectos permitirán alcanzar distintos niveles de resiliencia y tomar decisiones sobre la arquitectura más apropiada para sus necesidades. Nuestro objetivo es proporcionar un enfoque de alto nivel para estructurar conversaciones sobre las decisiones asociadas con cada uno de estos patrones. Para una exploración más profunda de cada patrón, consulte la sección de Lecturas Adicionales al final de esta publicación.
Nota: Estos patrones no son mutuamente excluyentes; puede decidir implementar una combinación de uno o más patrones.
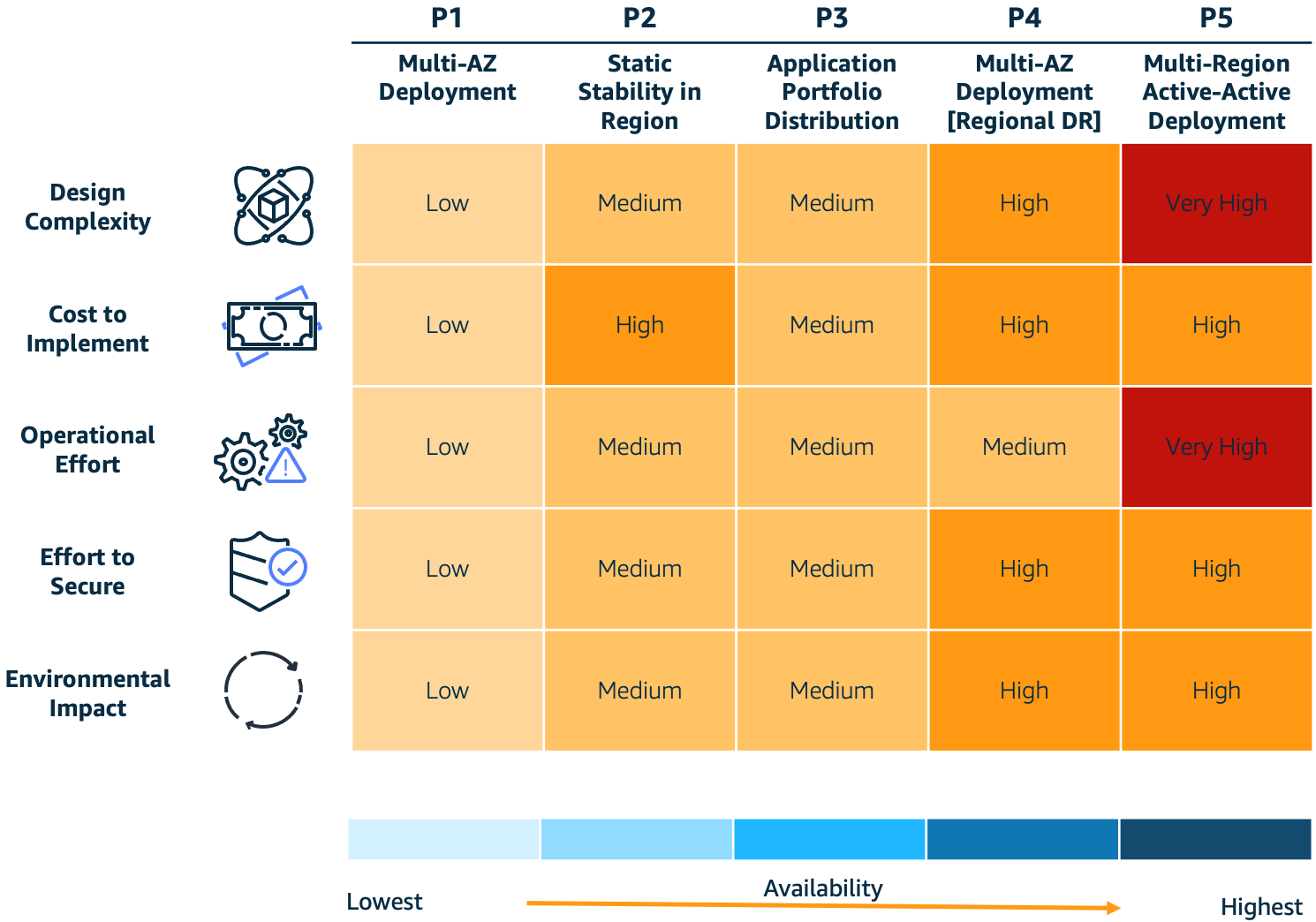 Figura 1. Patrones de resiliencia y compromisos
Figura 1. Patrones de resiliencia y compromisos
¿Qué es la resiliencia? ¿Por qué es importante?
El Marco AWS Well-Architected define la resiliencia como «la capacidad para recuperarse cuando se encuentra bajo carga (más solicitudes de servicio), ataques (ya sea accidentalmente a través de un error, o deliberadamente a través de intención) y fallas de cualquier componente de los componentes de la carga de trabajo».
Para satisfacer los requisitos de resiliencia de su empresa, considere los siguientes factores fundamentales al diseñar sus cargas de trabajo:
- Complejidad del diseño: Un aumento en la complejidad del sistema generalmente aumenta los comportamientos emergentes de ese sistema. Cada componente individual de la carga de trabajo debe ser resiliente, eliminando así puntos únicos de falla en personas, procesos y elementos tecnológicos. Los clientes deben sopesar sus necesidades de resiliencia y decidir si el aumento de la complejidad del sistema es eficaz, o si mantener la simplicidad y utilizar un plan de recuperación de desastres (DR) es más apropiado.
- Costo de implementación: Los costos tienden a aumentar significativamente al implementar una mayor resiliencia debido a la introducción de nuevos componentes de software e infraestructura. Es crucial que estos costos se equilibren con posibles pérdidas futuras.
- Esfuerzo operativo: Desplegar y mantener sistemas altamente resilientes demanda procesos operativos complejos y habilidades técnicas avanzadas. Por ejemplo, los clientes podrían necesitar mejorar sus procesos operativos utilizando el enfoque de Revisión de Preparación Operativa (ORR). Antes de decidir implementar una mayor resiliencia, evalúe su capacidad operativa para confirmar que cuenta con el nivel requerido de madurez en procesos y conjuntos de habilidades.
- Esfuerzo de seguridad: La complejidad de seguridad está menos directamente correlacionada con la resiliencia. Sin embargo, generalmente hay más componentes para asegurar en sistemas altamente resilientes. Emplear las mejores prácticas de seguridad para implementaciones en la nube puede lograr objetivos de seguridad sin agregar una complejidad significativa, incluso con una mayor huella de implementación.
- Impacto ambiental: Un aumento en la implementación puede generar una mayor huella de carbono en sistemas resilientes debido al incremento en el consumo de recursos en la nube. No obstante, se pueden utilizar patrones como la computación aproximada y la deliberada ralentización de los tiempos de respuesta para reducir este consumo. El Pilar de Sostenibilidad de AWS Well-Architected describe estos patrones y proporciona orientación sobre las mejores prácticas de sostenibilidad.
Patrón 1 (P1): Multi-AZ
P1 es un patrón de arquitectura basado en la nube (Figura 2) que introduce Zonas de Disponibilidad (AZs, por sus siglas en inglés) en su arquitectura para aumentar la resiliencia de su sistema. El patrón P1 utiliza una arquitectura Multi-AZ donde las aplicaciones operan en múltiples AZs dentro de una sola Región de AWS. Esto permite que su aplicación soporte impactos a nivel de AZ.
Como se muestra en la Figura 2, Example Corp despliega sus aplicaciones internas para empleados utilizando el patrón P1. Estas aplicaciones tienen un bajo impacto comercial y, por lo tanto, tienen requisitos más bajos de resiliencia.
Example Corp despliega sus aplicaciones de bajo impacto comercial como una única instancia de Amazon Elastic Compute Cloud (Amazon EC2) administrada por un grupo de Auto Scaling. Amazon EC2 utiliza controles de salud para detectar automáticamente fallas. Si una AZ falla, Amazon EC2 solicita a un grupo de Auto Scaling de Amazon EC2 que recreen su aplicación en otra AZ no afectada.

Figura 2. Patrón de despliegue Multi-AZ (P1)
Desiciones de costos/beneficios a considerar
P1 es bajo en varias categorías y mitiga una interrupción en la AZ que aloja la aplicación, pero esto se hace a expensas de la recuperación de la aplicación. Si una AZ está fuera de servicio, interrumpirá el acceso de los usuarios finales a la aplicación mientras se vuelven a aprovisionar los nuevos recursos en una nueva AZ. Esto se conoce como comportamiento bimodal.
Patrón 2 (P2): Multi-AZ con estabilidad estática
El P2 utiliza múltiples instancias en múltiples Zonas de Disponibilidad (AZs) dentro de una Región para aumentar la resilencia. El patrón utiliza estabilidad estática para prevenir comportamientos bimodales. Los sistemas estáticamente estables permanecen estables y operan en un modo, independientemente de los cambios en su entorno operativo. Un beneficio clave de un sistema estáticamente estable en AWS es que reduce la complejidad de la recuperación durante una interrupción gracias a la capacidad de recursos preaprovisionados. Cualquier recurso necesario para mantener las operaciones durante una interrupción, como la pérdida de recursos en una AZ, ya existe y los planos de control de servicios de AWS no necesitan estar disponibles para que la recuperación sea exitosa. Para obtener más información sobre la estabilidad estática, los planos de datos y los planos de control, lea el artículo de la biblioteca del constructor «Estabilidad estática utilizando Zonas de Disponibilidad».
Como se muestra en la Figura 3, Example Corp tiene un sitio web orientado al cliente que tiene una menor tolerancia al tiempo de inactividad. Cada vez que el sitio web está inactivo, podría resultar en pérdida de ingresos. Por esta razón, el sitio web requiere dos instancias de EC2 que están provisionadas dentro de dos AZs. Utilizando verificaciones de salud, cuando la AZ se ve afectada, el sitio web continúa operando ya que el Balanceador de Carga Elástico desvía el tráfico lejos de la AZ afectada. Para obtener más información sobre el uso de verificaciones de salud, consulte el artículo «Implementación de verificaciones de salud» en la Biblioteca del Constructor de Amazon.

Figura 3. Patrón Multi-AZ con estabilidad estática (P2)
Desiciones de costos/beneficios a considerar
El P2 mitiga una interrupción de la AZ sin tiempo de inactividad para los clientes de la aplicación, pero debe sopesarse con respecto a las preocupaciones de costos. El P1 es menos costoso desde la perspectiva de costos de infraestructura, ya que provisiona menos capacidad de cómputo y depende del lanzamiento de nuevas instancias en caso de una falla. Sin embargo, el comportamiento bimodal del P1 puede afectar a sus clientes durante eventos a gran escala.
Implementar el P2 requiere que su aplicación admita operaciones distribuidas entre múltiples instancias. Si su aplicación puede admitir este patrón, puede implementar su carga de trabajo en todas las AZs disponibles (generalmente 3 o más) en la Región. Esto reducirá los costos asociados con la sobreaprovisionamiento porque solo tendrá que provisionar el 150% de su capacidad en tres AZs en comparación con el 200% en dos AZs (como se mencionó en nuestro ejemplo anterior).
Patrón 3 (P3): Distribución del portafolio de aplicaciones
El P3 utiliza un patrón Multi-Región para aumentar la resilencia funcional, como se muestra en la Figura 4. Distribuye diferentes aplicaciones críticas en múltiples Regiones.
Example Corp proporciona servicios bancarios, como verificaciones de saldo, a consumidores en múltiples canales digitales. Estos servicios están disponibles para los consumidores a través de una aplicación móvil, un centro de contacto y aplicaciones basadas en web. Cada canal digital se implementa en una Región separada, lo que mitiga una interrupción del servicio regional.
Por ejemplo, una Región con la aplicación móvil de los clientes puede tener una interrupción que hace que la aplicación móvil no esté disponible, pero los clientes aún pueden acceder a los servicios bancarios a través de la banca en línea implementada en una Región alternativa. Las interrupciones del servicio regional son raras, pero implementar un patrón como este asegura que sus usuarios retengan acceso a servicios críticos para el negocio durante interrupciones.

Figura 4. Patrón de distribución del portafolio de aplicaciones (P3)
Desiciones de costos/beneficios a considerar
El P3 mitiga la posibilidad de que una interrupción del servicio regional afecte a una multitud de sistemas al mismo tiempo. Operar un portafolio de aplicaciones que abarque múltiples Regiones requiere una planificación y gestión operativa significativa. Los elementos funcionales aislados pueden depender de sistemas comunes y fuentes de datos que se implementan en una sola Región. Por lo tanto, los eventos a nivel de Región aún pueden causar interrupciones, pero el área de impacto debería ser menor.
Patrón 4 (P4): Implementación Multi-AZ (DR multi-Región)
Example Corp opera varios servicios críticos para el negocio que tienen una tolerancia muy baja para las interrupciones, como la capacidad para que los consumidores realicen pagos bancarios. Example Corp revisó los cuatro patrones comunes para la recuperación ante desastres (según lo definido en la Recuperación de Cargas de Trabajo en AWS: Recuperación en la Nube) y decidió utilizar los siguientes subpatrones para sus aplicaciones multi-Región:
- Piloto encendido (Pilot Light) – Este patrón funciona para aplicaciones que requieren un RTO/RPO de 10 segundos. Los datos se replican activamente y la infraestructura de la aplicación se preaprovisiona en la Región de recuperación ante desastres. La optimización de costos es un factor clave aquí, ya que la infraestructura de la aplicación se mantiene apagada y solo se enciende durante el evento de restauración.
- Standby en caliente (Warm Standby) – Este patrón mejora significativamente los tiempos de restauración en comparación con el piloto encendido al mantener sus aplicaciones en funcionamiento en la Región de recuperación ante desastres, pero con una capacidad reducida. La infraestructura de la aplicación se ampliará durante un evento de recuperación ante desastres, pero esto generalmente se puede automatizar con un esfuerzo manual mínimo. Este patrón puede lograr un RTO/RPO de minutos si se implementa correctamente.
Desiciones de costos/beneficios a considerar
El P4 mitiga una interrupción en el servicio regional mientras reduce los costos de mitigación. Los patrones de recuperación ante desastres regionales aumentan la complejidad de implementación, ya que los cambios en la infraestructura deben sincronizarse entre Regiones. También es significativamente más complejo probar la resistencia e incluir la simulación de interrupciones region. Utilizar Infraestructura como Código para automatizar despliegues puede ayudar a aliviar estos problemas.
Patrón 5 (P5): Multi-Region active-active
Las aplicaciones centrales de banca y gestión de relaciones con el cliente de Example Corp no toleran interrupciones. Utilizan el patrón P5 para desplegar estas aplicaciones porque tiene un Tiempo de Recuperación Objetivo (RTO) en tiempo real y un Objetivo de Punto de Recuperación (RPO) de pérdida de datos cercana a cero. Ejecutan su carga de trabajo simultáneamente en múltiples regiones, lo que les permite atender el tráfico desde todas las regiones simultáneamente. Este patrón no solo mitiga las interrupciones regionales, sino que también cumple con sus requisitos de tolerancia cero (Figura 5).

Figura 5. Patrón multi-Region active-active (P5)
Desiciones de costos/beneficios a considerar
El P5 mitiga la interrupción de un servicio regional e invierte costos adicionales y complejidad para lograr un RTO cercano a cero. Las implementaciones multi-activas suelen ser mas complejas, ya que incluyen múltiples aplicaciones que colaboran para brindar los servicios comerciales necesarios. Si implementa este patrón, debe considerar que está introduciendo una replicación asincrónica de datos entre regiones y el impacto que esto tiene en la consistencia de los datos.
Operar este patrón requiere un nivel muy alto de madurez del proceso, por lo que recomendamos a los clientes avanzar gradualmente hacia este patrón comenzando con los patrones de implementación descritos anteriormente.
Conclusión
En esta publicación del blog, presentamos cinco patrones de resiliencia y las desiciones de costos/beneficios a considerar al implementarlos. En un esfuerzo por ayudarlo a encontrar la arquitectura más eficiente para su caso de uso, demostramos cómo Example Corp evaluó estas opciones y cómo las aplicaron a sus necesidades comerciales.
Lecturas adicionales
Este artículo se tradujo del Blog Post de AWS en Inglés.
Acerca de lo autor
 Haresh Nandwani es Senior Solutions Architect
Haresh Nandwani es Senior Solutions Architect
 Lewis Taylor es Solution Architect
Lewis Taylor es Solution Architect
 Bonnie McClure es editora especialista en creación de contenido accesible
Bonnie McClure es editora especialista en creación de contenido accesible