Blog de Amazon Web Services (AWS)
Simplifica la gestión de clusters Kubernetes usando ACK, kro y Amazon EKS
Por Islam Mahgoub, Arquitecto de Soluciones Senior en AWS; Kumudhan, Consultor DevOps en AWS Professional Services; Markos Kandylis, Consultor DevOps Senior en AWS Professional Services; Ramesh Mathikumar, Consultor Principal dentro de la práctica global de Servicios Financieros y Sébastien, Arquitecto de Soluciones Especialista Senior en AWS.
A medida que las organizaciones amplían su adopción de Kubernetes para un número creciente de casos de uso, también aumenta la cantidad de procesos operativos relacionados con el aprovisionamiento y la operación de los clusters de Kubernetes. El proceso de crear un cluster, configurarlo con los add-ons específicos de la organización y luego administrarlo a lo largo del tiempo es complejo y propenso a errores. Típicamente, estas tareas involucran el uso de una mezcla de pipelines de Infraestructura como Código (IaC) desconectados, manifiestos de Kubernetes y Helm charts, lo que generalmente lleva a tiempos extendidos para la creación de nuevos clusters, mayor sobrecarga operativa para administrar clusters y mayor riesgo de fallas o tiempo de inactividad.
En este blog post, se muestra cómo crear y administrar una flota de clusters de Amazon Elastic Kubernetes Service (Amazon EKS) utilizando Kube Resource Orchestrator (kro), AWS Controllers for Kubernetes (ACK) y Argo CD. Estas herramientas permiten implementar una solución de gestión de clusters basada en GitOps para aumentar la productividad y mejorar la consistencia y estandarización utilizando la API de Kubernetes para operaciones de extremo a extremo.
Descripción general de la solución
ACK es una herramienta que permite administrar recursos de AWS directamente desde Kubernetes utilizando construcciones declarativas YAML familiares – es una colección de custom resource definitions (CRDs) de Kubernetes y custom controllers que trabajan juntos para extender la API de Kubernetes y administrar recursos de AWS. Una vez que se instala un service controller de ACK, un usuario de Kubernetes puede crear un Custom Resource (CR) correspondiente a uno de los recursos expuestos por el controller para crear un recurso de AWS.
En la solución descrita en este blog post, se utilizan controllers de ACK para crear los recursos de AWS necesarios para un cluster de EKS. Al hacer esto, se habilita la gestión de clusters a través de la API de Kubernetes y se elimina la necesidad de usar una herramienta de IaC separada y construir un pipeline separado para este caso de uso. Adicionalmente, este enfoque permite construir un flujo GitOps para la gestión de clusters utilizando herramientas como Argo CD.
Dicho esto, existen varios desafíos involucrados en este enfoque:
- Para crear un cluster de EKS, es necesario aprovisionar varios recursos de AWS, incluyendo una virtual private cloud (VPC), subnets, route tables, NAT gateways, un IAM role para el cluster, un IAM role para los nodos y el cluster de EKS en sí.
- Estos recursos de AWS tienen dependencias entre sí. Por ejemplo, la VPC necesita ser creada antes que las subnets, y los IAM roles del cluster deben ser creados antes que el cluster de EKS en sí. Para tener en cuenta estas dependencias, es necesario aplicar los CRs en un orden específico.
- Adicionalmente, es necesario extraer los campos generados de los CRs y usar esa información como entrada para los CRs dependientes. Por ejemplo, se debe extraer el VPC ID del CR de la VPC y luego proporcionarlo como entrada al CR del Subnet.
Dadas las interdependencias y los requisitos de ordenamiento destacados anteriormente, queda claro que la creación de los recursos de AWS del cluster de EKS mediante la aplicación de los Custom Resources (CRs) correspondientes requiere un enfoque bien orquestado.
kro (que se pronuncia «crow») proporciona una capa de abstracción que maneja todas las dependencias y el ordenamiento de configuración de los recursos, y luego crea y administra los recursos necesarios. El concepto de ResourceGraphDefinition (RGD) de kro proporciona una forma sencilla de crear un Custom Resource Definition (CRD) que encapsula todos los recursos de AWS y Kubernetes requeridos para un cluster completamente funcional (por ejemplo, VPC, Subnets, IAM roles, cluster de EKS, etc.). El RGD permite al controller de kro hacer seguimiento de las dependencias de recursos y aplicar los recursos en consecuencia. Con kro, se puede utilizar Common Expression Language (CEL) para extraer campos generados de los recursos (por ejemplo, vpcID en el caso del CR de VPC) y pasarlos a otros recursos.
El siguiente diagrama muestra la arquitectura de la solución:
- Los controllers de ACK se utilizan para crear los recursos de AWS.
- kro orquesta la creación y las dependencias de los recursos de ACK.
- Argo CD se utiliza como controller de GitOps para configurar el cluster de administración, aprovisionar los clusters de carga de trabajo y los add-ons correspondientes.
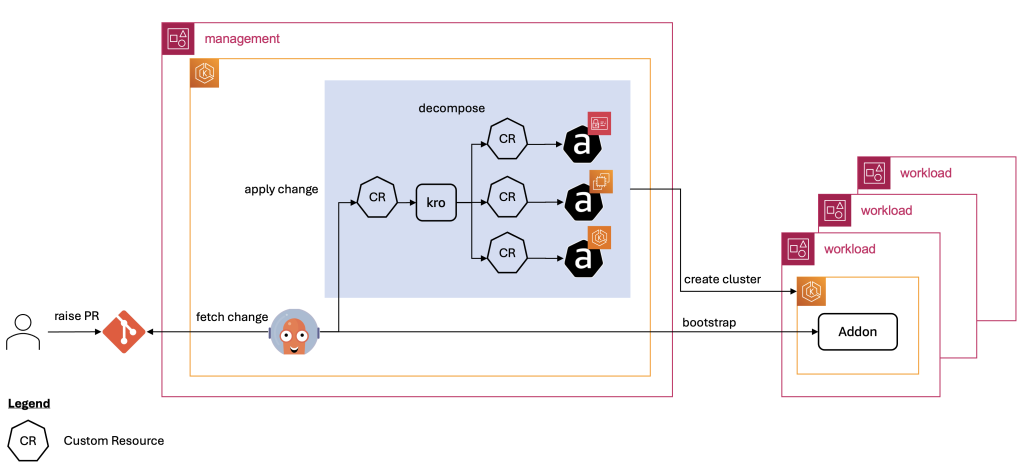
En esta solución, se utilizan Amazon EKS Capabilities que proporcionan una experiencia completamente administrada para ACK, kro y Argo CD. Esto elimina la necesidad de instalación, mantenimiento y escalamiento de estas herramientas.
En las siguientes secciones, se explican las partes clave de la solución.
Creación de ResourceGraphDefinitions que encapsulan recursos de AWS para crear clusters de EKS
El CRD ResourceGraphDefinition es un bloque de construcción fundamental en kro. Proporciona una forma de definir, organizar y administrar conjuntos interconectados de recursos de Kubernetes como una unidad única y reutilizable. kro utiliza una sintaxis legible, amigable y compatible con OpenAPI para definir RGDs. En la parte superior, se tiene la sección schema que especifica la interfaz del nuevo CRD definido por el RGD. Luego, se tiene la sección resources que especifica los recursos que deben ser aplicados por kro cuando se crea una instancia de ese RGD en el cluster.
Veamos el RGD para un cluster de EKS para entender mejor el concepto.
apiVersion: kro.run/v1alpha1
kind: ResourceGraphDefinition
metadata:
name: eksclusterbasic.kro.run
spec:
schema:
apiVersion: v1alpha1
kind: EksClusterBasic
spec:
name: string
region: string
k8sVersion: string
network:
... (removed for brevity)
resources:
- id: clusterRole
... (removed for brevity)
- id: nodeRole
...
- id: ekscluster
template:
apiVersion: eks.services.k8s.aws/v1alpha1
kind: Cluster
metadata:
namespace: "${schema.spec.name}"
name: "${schema.spec.name}"
spec:
name: "${schema.spec.name}"
roleARN: "${clusterRole.status.ackResourceMetadata.arn}"
version: "${schema.spec.k8sVersion}"
accessConfig:
...
computeConfig:
nodeRoleARN: ${nodeRole.status.ackResourceMetadata.arn}
...
... Para más detalles sobre esta sintaxis, consultar Simple Schema en la documentación de kro.
Una de las capacidades de kro es componer cualquier recurso de Kubernetes que pueda ser admitido en el cluster dentro de un RGD. Esto incluye incorporar instancias de otros RGDs existentes, lo que permite crear una jerarquía de RGDs.
Los clusters de EKS requieren una VPC y otros recursos de red como su infraestructura de alojamiento. Existen dos escenarios comunes: crear un cluster de EKS en una VPC existente o crear un cluster de EKS junto con la VPC que lo aloja.
Para soportar estos dos escenarios, se crean tres RGDs separados – uno para los recursos de red (VPC, Subnets, etc.) llamado Vpc, uno para el cluster de EKS en sí llamado EksClusterBasic, y finalmente un RGD general llamado EksCluster que se compone de instancias de los RGDs Vpc y EksClusterBasic. El RGD EksCluster se utiliza para crear el cluster de EKS en los dos escenarios — sus recursos compuestos se renderizan opcionalmente usando includeWhen basado en los valores de los campos de entrada:
- Si el usuario establece el campo de entrada
vpc.createentrue, solo se renderizan los recursosvpc(de tipoVpc) yeksWithVpc(de tipoEksClusterBasic). Los campos de entrada del recursoeksWithVpcse llenan a partir del campo de status del recursovpc. - Si el usuario establece el campo de entrada
vpc.createenfalse, solo se renderiza el recursoeksExistingVpc(de tipoEksClusterBasic). Los campos de entrada del recursoeksExistingVpc(por ejemplo, VPC ID, Subnets ID, etc.) se llenan a partir de los campos de entrada de la instancia del RGD.
El siguiente diagrama muestra la estructura de los RGDs:
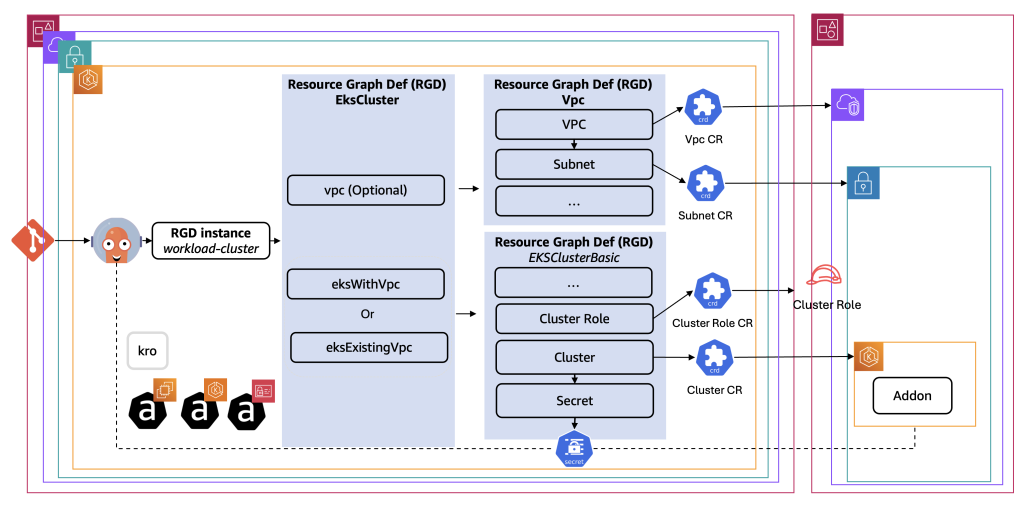
A continuación se muestra un extracto simplificado del manifiesto del RGD EksCluster (el RGD principal):
apiVersion: kro.run/v1alpha1
kind: ResourceGraphDefinition
metadata:
name: ekscluster.kro.run
annotations:
spec:
schema:
apiVersion: v1alpha1
kind: EksCluster
spec:
name: string
region: string | default="us-west-2"
k8sVersion: string | default="1.32"
...
vpc:
create: boolean | default=true
...
resources:
- id: vpc
includeWhen:
- ${schema.spec.vpc.create}
template:
apiVersion: kro.run/v1alpha1
kind: Vpc
metadata:
name: ${schema.spec.name}
namespace: ${schema.spec.name}
...
- id: eksWithVpc
includeWhen:
- ${schema.spec.vpc.create}
template:
apiVersion: kro.run/v1alpha1
kind: EksClusterBasic
metadata:
name: ${schema.spec.name}
namespace: ${schema.spec.name}
spec:
...
network:
vpcID: "${vpc.status.vpcID}"
subnets:
controlplane:
subnet1ID: "${vpc.status.privateSubnet1ID}"
subnet2ID: "${vpc.status.privateSubnet2ID}"
workers:
subnet1ID: "${vpc.status.privateSubnet1ID}"
subnet2ID: "${vpc.status.privateSubnet2ID}"
...
- id: eksExistingVpc
includeWhen:
- ${!schema.spec.vpc.create}
template:
apiVersion: kro.run/v1alpha1
kind: EksClusterBasic
metadata:
name: ${schema.spec.name}
namespace: ${schema.spec.name}
spec:
...
network:
vpcID: "${schema.spec.vpc.vpcId}"
subnets:
controlplane:
subnet1ID: "${schema.spec.vpc.privateSubnet1Id}"
subnet2ID: "${schema.spec.vpc.privateSubnet2Id}"
workers:
subnet1ID: "${schema.spec.vpc.privateSubnet1Id}"
subnet2ID: "${schema.spec.vpc.privateSubnet2Id}"
...Uso de expresiones CEL para extraer campos generados
Dentro del RGD, se utilizan expresiones de Common Expression Language (CEL) para extraer los valores de los campos generados de un Custom Resource (CR) y alimentarlos como entrada a otro CR dependiente.
El siguiente fragmento de manifiesto demuestra cómo se utilizan las expresiones CEL dentro del RGD. En este ejemplo, se usa una expresión CEL para extraer el VPC ID del CR de la VPC, y luego ese valor se alimenta como entrada al CR del InternetGateway.
Las expresiones CEL en kro también sirven para derivar dependencias de recursos. La expresión CEL proporcionada en este ejemplo indica que el CR del InternetGateway depende del recurso VPC, lo que lleva al controller de kro a crear el orden topológico en consecuencia, es decir, el recurso VPC se creará primero y su ID estará disponible para el recurso dependiente InternetGateway.
- id: vpc
... (removed for brevity)
- id: internetGateway
template:
apiVersion: ec2.services.k8s.aws/v1alpha1
kind: InternetGateway
metadata:
namespace: ${schema.spec.name}
name: ${schema.spec.name}-igw
annotations:
services.k8s.aws/region: ${schema.spec.region}
spec:
vpc: ${vpc.status.vpcID}
... (removed for brevity)Creación de recursos de AWS entre cuentas usando ACK
AWS recomienda utilizar una estrategia multi-cuenta y AWS Organizations para ayudar a aislar y administrar las aplicaciones y datos del negocio. Por lo tanto, es importante tener la capacidad de configurar los controllers de ACK en el cluster/cuenta de administración, para que puedan crear los recursos del cluster de carga de trabajo en una cuenta diferente (cuenta de carga de trabajo). Para lograr esto, se aprovechan los IAM Role Selectors que utilizan un CRD de alcance de cluster para mapear dinámicamente IAM roles a namespaces y recursos usando label selectors de Kubernetes.
El siguiente diagrama ilustra cómo funciona ACK entre cuentas. Los pasos clave son los siguientes:
- Se crea un CR de ACK en un namespace específico. El controller de ACK que monitorea los CRs correspondientes detecta el nuevo CR.
- El controller de ACK identifica el IAM role que corresponde al namespace donde reside el CR de ACK, basándose en los CRs de IAMRoleSelector aplicados.
- El controller de ACK asume el IAM role identificado, que puede estar en una cuenta de AWS diferente.
- Con el IAM role asumido, el controller de ACK puede ahora llamar a la API de AWS para crear el recurso en la cuenta de carga de trabajo.
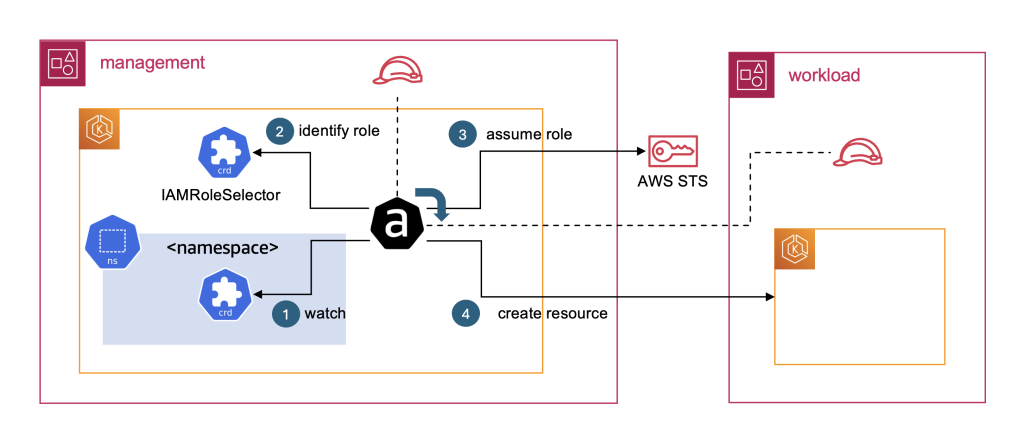
Para utilizar este mecanismo para crear un cluster de carga de trabajo entre cuentas, se crea un namespace para el cluster de carga de trabajo en el cluster de administración (aquí es donde se crean todos los recursos de ACK relacionados con el cluster). Se crea un IAMRoleSelector que mapea el namespace al IAM role que se utiliza para crear los recursos del cluster. Este IAM role existe en la cuenta destino, donde se crea el cluster de carga de trabajo.
El siguiente fragmento muestra la estructura del CR IAMRoleSelector:
apiVersion: services.k8s.aws/v1alpha1 kind: IAMRoleSelector metadata: name: workload-cluster1-namespace-config spec: arn: arn:aws:iam::112234567890:role/ack namespaceSelector: names: - workload-cluster1
Basándose en la configuración anterior, los controllers de ACK asumen el IAM role arn:aws:iam::112234567890:role/ack para sincronizar los recursos de ACK en el namespace workload-cluster1.
El IAM role asociado con los controllers de ACK en el cluster de administración debe tener los permisos necesarios para asumir los IAM roles en las diversas cuentas de carga de trabajo. Adicionalmente, las trust policies de los IAM roles en las cuentas de carga de trabajo deben estar configuradas para permitir que el IAM role de la cuenta de administración los asuma.
Configuración inicial del cluster de carga de trabajo con add-ons
Con Argo CD, se puede utilizar el controller de ApplicationSets para habilitar mayor flexibilidad y automatización en la gestión de aplicaciones de Argo CD. El controller de ApplicationSets permite a los usuarios utilizar un único manifiesto de Kubernetes para apuntar a múltiples clusters de Kubernetes con Argo CD. Esto simplifica el proceso de deploy de aplicaciones de Argo CD a través de varios clusters, simplificando la gestión de entornos complejos multi-cluster.
Para instalar add-ons en los clusters de carga de trabajo, se aplica un recurso ApplicationSet de Argo CD para cada add-on. El ApplicationSet utiliza el Cluster Generator para generar dinámicamente Applications de Argo CD para el deploy del add-on a través de los diversos clusters de carga de trabajo.
Para que el Cluster Generator cree una Application para un add-on dado que apunte a un cluster de carga de trabajo, es necesario registrar el cluster de carga de trabajo como un cluster remoto en Argo CD ejecutándose en el cluster de administración. Esta actividad involucra la creación de un Secret con los detalles del cluster de carga de trabajo como se describe en la documentación de EKS capabilities.
En esta solución, el Secret se crea como parte del recurso RGD EksClusterBasic. El campo server se llena con el ARN del cluster de carga de trabajo.
- id: argocdSecret
template:
apiVersion: v1
kind: Secret
metadata:
name: "${schema.spec.name}"
namespace: argocd
labels:
... (removed for brevity)
annotations:
... (removed for brevity)
type: Opaque
stringData:
name: "${schema.spec.name}"
server: "${ekscluster.status.ackResourceMetadata.arn}"
project: "default"El IAM role asumido por el controller de Argo CD necesita tener acceso al cluster de carga de trabajo. El enfoque recomendado es utilizar EKS access entries para asociar un conjunto de permisos de Kubernetes con la identidad IAM. En esta solución, se incluye el EKS access entry requerido en el recurso RGD EksClusterBasic.
- id: accessEntry
template:
apiVersion: eks.services.k8s.aws/v1alpha1
kind: AccessEntry
metadata:
namespace: "${schema.spec.name}"
name: "${schema.spec.name}-access-entry"
... (removed for brevity)
spec:
clusterName: "${schema.spec.name}"
accessPolicies:
- accessScope:
type: "cluster"
policyARN: "arn:aws:eks::aws:cluster-access-policy/AmazonEKSClusterAdminPolicy"
principalARN: "arn:aws:iam::${schema.spec.managementAccountId}:role/hub-cluster-argocd-controller"
type: STANDARDOtorgamiento de permisos IAM a los add-ons
Algunos add-ons, como el External Secrets Operator, requieren permisos IAM específicos para funcionar correctamente. Para otorgar esos permisos utilizando EKS Pod Identity (el mecanismo recomendado para otorgar permisos IAM a un pod), es necesario crear una IAM policy, un IAM role y una asociación entre el ServiceAccount del add-on y el IAM role. En esta solución, se utilizan los controllers de ACK para crear los recursos mencionados.
La configuración de IAM debe completarse antes de que se instale el add-on, de lo contrario los pods del add-on pueden fallar. Una forma de lograr esto es incluir los recursos de EKS Pod Identity de los add-ons en el recurso RGD EksClusterBasic.
Integrando todo
Revisemos la arquitectura de la solución y recorramos los pasos involucrados en la creación de un cluster de carga de trabajo.
Paso 1: El desarrollador crea un pull request (PR) con el manifiesto del cluster de carga de trabajo (instancia del RGD), especificando el nombre del cluster, la versión de Kubernetes, los add-ons requeridos y otros detalles relevantes.
Paso 2-3: Argo CD obtiene la instancia del RGD del cluster y la aplica al cluster de administración.
Paso 4: El controller de kro descompone la instancia del RGD del cluster en recursos individuales de ACK (custom resources) y los aplica al cluster de administración en el orden correcto. Esto incluye la creación de un Secret con los detalles del cluster que Argo CD espera para poder sincronizar en el cluster de carga de trabajo destino.
Paso 5: El controller de ACK luego asume un role en la cuenta de carga de trabajo y crea los recursos de AWS correspondientes (por ejemplo, cluster de EKS, VPC, IAM roles).
Paso 6: Los ApplicationSets de Argo CD generan Applications de Argo CD para cada add-on habilitado para el cluster. Estas Applications se utilizan luego para instalar los add-ons requeridos en el cluster de carga de trabajo.
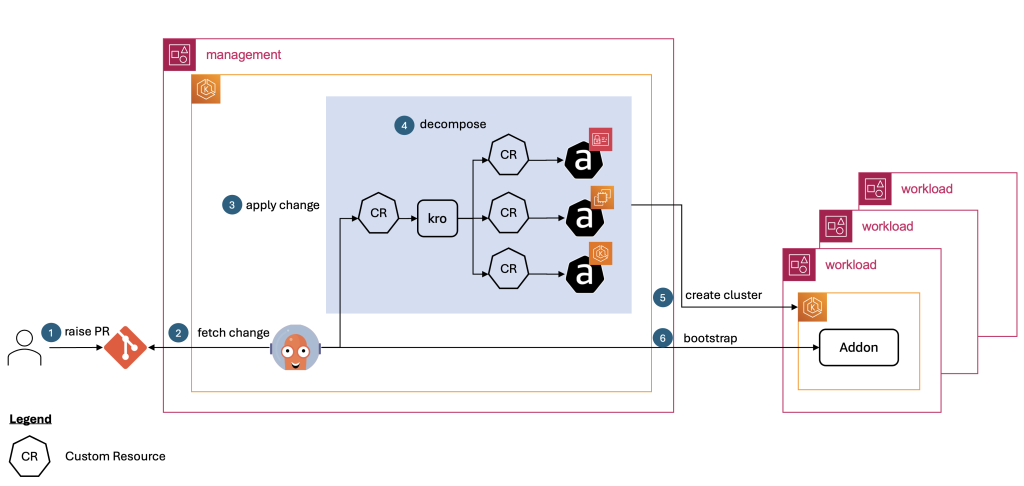
Código fuente
La implementación de la solución descrita en este blog post está disponible en este repositorio. Seguir los pasos en el archivo README para experimentar con la solución en un entorno propio.
Conclusión
En este blog post, se ha mostrado cómo kro, combinado con controllers de infraestructura como ACK y Argo CD, permite estandarizar el aprovisionamiento y la configuración inicial de clusters a través de una única API de Kubernetes, e implementar una solución de gestión de clusters basada en GitOps. Esto elimina la necesidad de usar una mezcla de pipelines de Infraestructura como Código (IaC) y la API de Kubernetes para ese propósito.
Se explicaron varias características clave de kro que fueron fundamentales en esta implementación:
- Proporcionar un schema simple para crear nuevos custom resources (CRs).
- Permitir la gestión de dependencias entre recursos.
- Soportar expresiones basadas en Common Expression Language (CEL) para condiciones y para pasar valores de un recurso a otro.
Estas capacidades de kro permiten un enfoque más simplificado y mantenible para gestionar el aprovisionamiento y la configuración inicial de clusters de Kubernetes, en comparación con depender de una combinación de pipelines de IaC e interacciones directas con la API de Kubernetes. También se ha demostrado la capacidad de ACK para operar entre cuentas, y cómo esto habilita una estrategia multi-cuenta para clusters de Kubernetes.
Es importante notar que el proyecto kro está en desarrollo activo y aún no está destinado para uso en producción. El CRD ResourceGraphDefinition (RGD) y otras APIs utilizadas en este proyecto aún no están consolidadas y están sujetas a cambios.
Este artículo fue traducido del Blog de AWS en Inglés.
Acerca de los Autores
 |
Islam Mahgoub es un Arquitecto de Soluciones Senior en AWS con más de 15 años de experiencia en arquitectura de aplicaciones, integración y tecnología. En AWS, ayuda a los clientes a construir nuevas soluciones centradas en la nube y a modernizar sus aplicaciones heredadas utilizando servicios de AWS. Fuera del trabajo, a Islam le gusta caminar, ver películas y escuchar música. |
 |
Kumudhan es un Consultor DevOps en AWS Professional Services, con sede en Suiza. Le apasiona ayudar a los clientes a adoptar procesos y servicios que aumenten su eficiencia con la nube de AWS. Cuando no está trabajando, le gusta viajar, jugar cricket y disfrutar de la música. |
 |
Markos Kandylis fue Consultor DevOps Senior en AWS Professional Services. Disfruta construir automatización y plataformas cloud-native que ayudan a los clientes a modernizar y operar entornos escalables, con un fuerte enfoque en Amazon EKS y Kubernetes. Sus intereses incluyen DevOps, GitOps, infraestructura como código, tecnologías de código abierto y automatización de plataformas.
|
 |
Ramesh Mathikumar es Consultor Principal dentro de la práctica global de Servicios Financieros. Ha trabajado con clientes del sector financiero durante los últimos 25 años. En AWS, ayuda a los clientes a tener éxito en su adopción de la nube implementando tecnologías de AWS en el día a día. |
 |
Sébastien es un Arquitecto de Soluciones Especialista Senior en AWS, donde ha impulsado el éxito de los clientes desde 2019. Aporta una profunda experiencia en soluciones de contenedores en AWS y tecnologías cloud-native, con un enfoque particular en Kubernetes, sistemas de IA/ML y arquitecturas distribuidas a gran escala. A lo largo de su trayectoria, Sébastien ha colaborado con organizaciones de diversos sectores en EMEA y Francia, ayudándolas a adoptar tecnologías de contenedores e implementar mejores prácticas para infraestructuras modernas en la nube. |
Traductor
 |
Jhon Guzmán es Senior Geo Specialist Solutions Architect en AWS, parte del equipo WWSO cubriendo el Norte de Latinoamérica y México. Aporta amplia experiencia en soluciones de contenedores AWS y tecnologías cloud-native, con enfoque particular en modernización de aplicaciones con Kubernetes e ingeniería de plataformas. Con más de 20 años de experiencia en soluciones empresariales de TI, Jhon ha ayudado a clientes y socios en Latinoamérica a adoptar arquitecturas cloud modernas. |