- Amazon SageMaker AI
- Amazon SageMaker HyperPod
- Características
Características de Amazon SageMaker HyperPod
Escale y acelere el desarrollo de los modelos de IA generativa en miles de aceleradores de IA
Entrenamiento sin puntos de control
El entrenamiento sin puntos de control en Amazon SageMaker HyperPod permite la recuperación automática de fallos de infraestructura en cuestión de minutos sin intervención manual. Reduce la necesidad de un reinicio a nivel de trabajo basado en puntos de control para la recuperación de errores, lo que requiere pausar todo el clúster, corregir los problemas y recuperarse de un punto de control guardado. El entrenamiento sin puntos de control mantiene el progreso del entrenamiento a pesar de los errores, ya que SageMaker HyperPod intercambia de manera automática los componentes defectuosos y recupera el entrenamiento mediante la transferencia entre pares de los estados del modelo y el optimizador desde aceleradores de IA en buen estado. Permite más del 95 % de los entrenamientos en clústeres con miles de aceleradores de IA. Con el entrenamiento sin puntos de control, ahorre millones en costos de computación, escale el entrenamiento a miles de aceleradores de IA y lleve sus modelos a la fase de producción más rápido.
Entrenamiento elástico
El entrenamiento elástico en Amazon SageMaker HyperPod escala de manera automática los trabajos de entrenamiento en función de la disponibilidad de los recursos de computación, lo que supone ahorrar horas de ingeniería por semana que antes se dedicaban a reconfigurar los trabajos de entrenamiento. La demanda de aceleradores de IA fluctúa constantemente a medida que las cargas de trabajo de inferencia escalan con los patrones de tráfico, los experimentos completados liberan recursos y los nuevos trabajos de entrenamiento cambian las prioridades de la carga de trabajo. SageMaker HyperPod amplía de forma dinámica los trabajos de entrenamiento en ejecución para absorber los aceleradores de IA inactivos y maximizar la utilización de la infraestructura. Cuando las cargas de trabajo de mayor prioridad, como la inferencia o la evaluación, necesitan recursos, la de entrenamiento se desescala verticalmente para continuar con menos recursos sin detenerse por completo, lo que brinda la capacidad requerida en función de las prioridades establecidas a través de las políticas de gobernanza de tareas. El entrenamiento elástico le ayuda a acelerar el desarrollo de modelos de IA y, al mismo tiempo, a reducir los sobrecostos derivados de la computación infrautilizada.
Gobernanza de tareas
Planes de entrenamiento flexibles
Instancias de spot de Amazon SageMaker HyperPod
Las instancias de spot de SageMaker HyperPod le permiten acceder a capacidad de computación con costos significativamente reducidos. Las instancias de spot son ideales para cargas de trabajo tolerantes a errores, como los trabajos de inferencia por lotes. Los precios varían según la región y el tipo de instancia y, por lo general, ofrecen un descuento de hasta el 90% en comparación con los precios de SageMaker HyperPod bajo demanda. Amazon EC2 define los precios de las instancias de spot y estos se ajustan gradualmente en función de las tendencias a largo plazo de la oferta y la demanda de capacidad de este tipo de instancia. Usted paga el precio de spot que esté en vigor durante el período de ejecución de sus instancias, sin necesidad de ningún compromiso por adelantado. Para obtener más información sobre los precios estimados de las instancias de spot y la disponibilidad de las instancias, visite la página de precios de las instancias de spot de EC2. Tenga en cuenta que solo las instancias que también son compatibles con HyperPod están disponibles para el uso de spot en HyperPod.
Recetas optimizadas para personalizar modelos
Con las recetas de SageMaker HyperPod, los científicos de datos y desarrolladores de todos los niveles de habilidad se benefician de un rendimiento de vanguardia y pueden empezar a entrenar y ajustar con rapidez los modelos fundacionales disponibles al público, incluidos los modelos Llama, Mixtral, Mistral y DeepSeek. Además, puede personalizar los modelos de Amazon Nova, incluidos Nova Micro, Nova Lite y Nova Pro, mediante un conjunto de técnicas que incluyen ajuste fino supervisado (SFT), destilación del conocimiento, optimización de preferencias directas (DPO), optimización de políticas próximas y entrenamiento previo continuo, con soporte para opciones de entrenamiento eficiente en parámetros como de entrenamiento del modelo completo en SFT, destilación y DPO. Cada receta incluye una pila de entrenamiento que AWS ha probado, lo que le ahorra semanas de tedioso trabajo de prueba de diferentes configuraciones de modelos. Puede cambiar entre instancias basadas en GPU e instancias basadas en AWS Trainium con un cambio de receta de una línea, y habilitar los puntos de control automatizados del modelo para mejorar la resiliencia del entrenamiento y ejecutar cargas de trabajo en producción en SageMaker HyperPod.
Amazon Nova Forge es un programa único en su especie que ofrece a las organizaciones la forma más fácil y rentable de crear sus propios modelos de frontera con Nova. Acceda a los puntos de control intermedios de los modelos Nova y entrénelos desde ellos, combine conjuntos de datos seleccionados por Amazon con datos patentados durante el entrenamiento y utilice las recetas de SageMaker HyperPod para entrenar sus propios modelos. Con Nova Forge, puede usar sus propios datos empresariales para desbloquear mejoras de inteligencia y precio-rendimiento específicas para cada caso de uso para sus tareas.
Entrenamiento distribuido de alto rendimiento
Herramientas avanzadas de observabilidad y experimentación
La observabilidad de SageMaker HyperPod proporciona un panel unificado preconfigurado en Amazon Managed Grafana; los datos de supervisión se publican automáticamente en un espacio de trabajo de Prometheus administrado por Amazon. Puede ver las métricas de rendimiento en tiempo real, el uso de los recursos y el estado de los clústeres en una sola vista, lo que permite a los equipos detectar con rapidez los cuellos de botella, evitar demoras costosas y optimizar los recursos de computación. SageMaker HyperPod también está integrado con Información de contenedores de Amazon CloudWatch, que proporciona información más detallada sobre el rendimiento, el estado y el uso de los clústeres. TensorBoard administrado en SageMaker ayuda a ahorrar tiempo de desarrollo, ya que le permite visualizar la arquitectura del modelo para identificar y solucionar problemas de convergencia. MLflow administrado en SageMaker le permite administrar los experimentos a escala de manera eficiente.
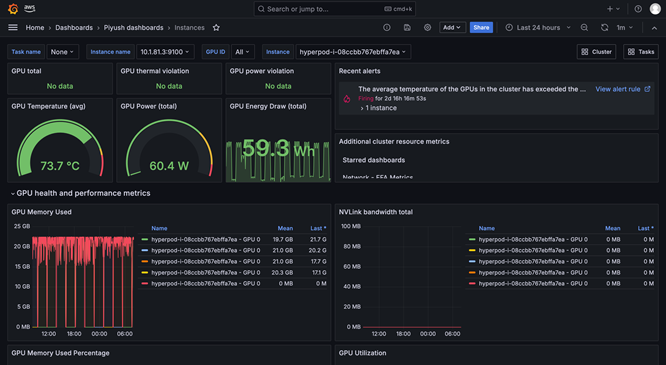
Programación y orquestación de la carga de trabajo
Comprobación de estado y reparación automáticas del estado del clúster
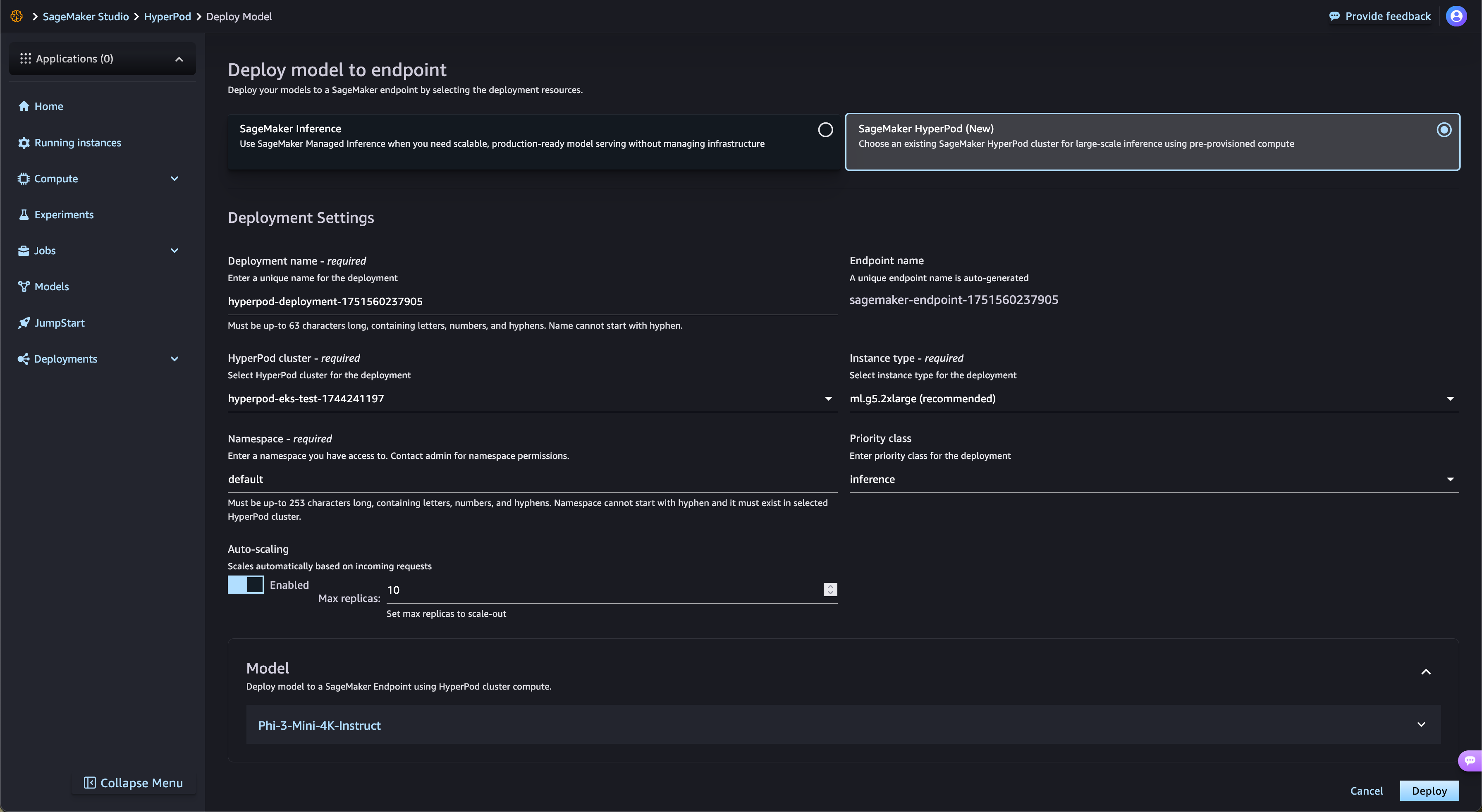
Acelere las implementaciones de modelos de peso abierto desde SageMaker Jumpstart
SageMaker HyperPod agiliza automáticamente la implementación de modelos fundacionales de peso abierto de SageMaker JumpStart y de modelos refinados de Amazon S3 y Amazon FSx. SageMaker HyperPod aprovisiona automáticamente la infraestructura requerida y configura los puntos de enlace, lo que elimina el aprovisionamiento manual. Gracias a la gobernanza de tareas de SageMaker HyperPod, el tráfico de los puntos de enlace se supervisa de forma continua y los recursos de computación se ajustan dinámicamente, mientras que al mismo tiempo se publican métricas de rendimiento completas en el panel de observabilidad para su supervisión y optimización en tiempo real.
Puntos de control administrados por niveles
Los puntos de control administrados por niveles de SageMaker HyperPod utilizan la memoria de la CPU para almacenar los puntos de control frecuentes para una recuperación rápida y, al mismo tiempo, conservar los datos de forma periódica en Amazon Simple Storage Service (Amazon S3) para tener una mayor durabilidad a largo plazo. Este enfoque híbrido minimiza la pérdida de entrenamiento y reduce significativamente el tiempo necesario para reanudar después de un error. Los clientes pueden configurar políticas de retención y frecuencia de puntos de control en los niveles de almacenamiento persistente y en memoria. Al almacenar con frecuencia en la memoria, los clientes pueden recuperarse con rapidez y, al mismo tiempo, minimizar los costos de almacenamiento. Al integrarse con el punto de control distribuido (DCP) de PyTorch, los clientes pueden implementar fácilmente los puntos de control con solo unas pocas líneas de código y, al mismo tiempo, obtener los beneficios de rendimiento del almacenamiento en memoria.
Maximice la utilización de los recursos con el particionado de GPU
SageMaker HyperPod permite a los administradores dividir los recursos de la GPU en unidades de computación más pequeñas y aisladas para maximizar la utilización de la GPU. Puede ejecutar diversas tareas de IA generativa en una sola GPU en lugar de dedicar GPU completas a tareas que solo necesitan una fracción de los recursos. Con las métricas de rendimiento en tiempo real y la supervisión del uso de los recursos en las particiones de la GPU, obtendrá visibilidad sobre cómo las tareas utilizan los recursos de computación. Esta asignación optimizada y la configuración simplificada aceleran el desarrollo de la IA generativa, mejoran la utilización de la GPU y brindan un uso eficaz de los recursos de la GPU en todas las tareas a escala.
¿Ha encontrado lo que buscaba hoy?
Ayúdenos a mejorar la calidad del contenido de nuestras páginas compartiendo sus comentarios