AWS Compute Blog
Creating a single-table design with Amazon DynamoDB
Amazon DynamoDB is a highly performant NoSQL database that provides data storage for many serverless applications. Unlike traditional SQL databases, it does not use table joins and other relational database constructs. However, you can model many common relational designs in a single DynamoDB table but the process is different using a NoSQL approach.
This blog post uses the Alleycat racing application to explain the benefits of a single-table DynamoDB table. It also shows how to approach modeling data access requirements in a DynamoDB table. Alleycat is a home fitness system that allows users to compete in an intense series of 5-minute virtual bicycle races. Up to 1,000 racers at a time take the saddle and push the limits of cadence and resistance to set personal records and rank on virtual leaderboards.
Alleycat requirements
In the Alleycat example, the application offers a number of exercise classes. Each class has multiple races, and there are multiple racers in each race. The system logs the output for each racer per second of the race. An entity-relationship diagram in a traditional relational database shows how you could use normalized tables and relationships to store this data:

In a relational database, often each table has a key that relates to a foreign key in another table. By joining multiple tables, you can query related tables and return the results in a single table view. While this is flexible and convenient, it’s also computationally expensive and difficult to scale horizontally.
Many serverless architectures are built for scale and the relational database paradigm often does not scale as efficiently as a workload demands. DynamoDB scales to almost any level of traffic but one of the tradeoffs is the lack of joins. Fortunately, it offers alternative ways to model the data to meet Alleycat’s requirements.
DynamoDB terminology and concepts
Unlike traditional databases, there is no limit to how much data can be stored in a DynamoDB table. The service is also designed to provide predictable performance at any scale, so you can expect similar query latency regardless of the level of traffic.
The most important operational aspect of running DynamoDB in production is setting and managing throughput. There is a provisioned mode, where you set the throughput, and on-demand, which is managed by the service. In the provisioned mode, you can also use automatic scaling to let the service set the throughput between lower and upper limits you define.
The choice here is determined by the traffic patterns in your workload. For applications with predictable traffic with gradual changes, provisioned mode is the better choice and is more cost effective. If traffic patterns are unknown or you prefer to have capacity managed automatically, choose on-demand. To learn more about the capacity modes, visit the documentation page.
Within each table, you must have a partition key, which is a string, numeric, or binary value. This key is a hash value used to locate items in constant time regardless of table size. It is conceptually different to an ID or primary key field in a SQL-based database and does not relate to data in other tables. When there is only a partition key, these values must be unique across items in a table.
Each table can optionally have a sort key. This allows you to search and sort within items that match a given primary key. While you must search on exact single values in the partition key, you can pattern search on sort keys. It’s common to use a numeric sort key with timestamps to find items within a date range, or use string search operators to find data in hierarchical relationships.
With only partition key and sort keys, this limits the possible types of query without duplicating data in a table. To solve this issue, DynamoDB also offers two types of indexes:
- Local secondary indexes (LSIs): these must be created at the same time the table is created and effectively enable another sort key using the same partition key.
- Global secondary indexes (GSIs): create and delete these at any time, and optionally use a different partition key from the existing table.
There are other important differences between the two index types:
| LSI |
GSI |
|
| Create | At table creation | Anytime |
| Delete | At table deletion | Anytime |
| Size | Up to 10 GB per partition | Unlimited |
| Throughput | Shared with table | Separate throughput |
| Key type | Primary key only or composite key (partition key and sort key) | Composite key only |
| Consistency model | Both eventual and strong consistency | Eventual consistency only |
Determining data access requirements
Relational database design focuses on the normalization process without regard to data access patterns. However, designing NoSQL data schemas starts with the list of questions the application must answer. It’s important to develop a list of data access patterns before building the schema, since NoSQL databases offer less dynamic query flexibility than their SQL equivalents.
To determine data access patterns in new applications, user stories and use-cases can help identify the types of query. If you are migrating an existing application, use the query logs to identify the typical queries used. In the Alleycat example, the frontend application has the following queries:
- Get the results for each race by racer ID.
- Get a list of races by class ID.
- Get the best performance by racer for a class ID.
- Get the list of top scores by race ID.
- Get the second-by-second performance by racer for all races.
While it’s possible to implement the design with multiple DynamoDB tables, it’s unnecessary and inefficient. A key goal in querying DynamoDB data is to retrieve all the required data in a single query request. This is one of the more difficult conceptual ideas when working with NoSQL databases but the single-table design can help simplify data management and maximize query throughput.
Modeling many-to-many relationships with DynamoDB
In traditional SQL, a many-to-many relationship is classically represented with three tables. In the earlier diagram for the Alleycat application, these tables are racers, raceResults, and races. Populated with sample data, the tables look like this:

In DynamoDB, the adjacency list design pattern enables you to combine multiple SQL-type tables into a single NoSQL table. It has multiple uses but in this case can model many-to-many relationships. To do this, the partition key contains both types of item – races and racers. The key value contains the type of data expected in the item (for example, “race-1” or “racer-2”):

With this table design, you can query by racer ID or by race ID. For a single race, you can query by partition key to return all results for a single race, or use the sort key to limit by a single racer or for the overall results. For per racer results, the second-by-second data is stored in a nested JSON structure.
To allow sorting by output to create leaderboard results, the output value must be a sort key. However, the sort key cannot be updated once it is set. Using the main sort key, the application would only be able to write a final race result per racer to query and sort on this data.
To resolve this problem, use an index. The index can use a separate sort key where the value can be updated. This allows Alleycat to store the latest results in this field, and then for queries to sort by output to create a leaderboard.
The preceding table does not represent the races table in the normalized view, so you cannot query by class ID to retrieve a list of races. Depending on your design, you can solve this by adding a second index to the table to enable querying by class ID and returning a list of partition keys (race IDs). However, you can also overload GSIs to contain multiple types of value.
The AlleyCat application uses both an LSI and GSI to accommodate all the data access patterns. This table shows how this is modeled, although the results attribute names are shorter in the application:
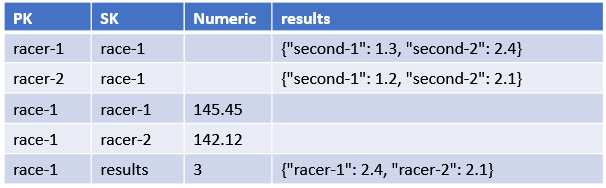
- Main composite key: PK and SK.
- Local secondary index: Partition key is PK and sort key is Numeric.
- Global secondary index: Partition key is SK and sort key is Numeric.
Reviewing the data access patterns for Alleycat
Before creating the DynamoDB table, test the proposed schema against the list of data access patterns. In this section, I review Alleycat’s list of queries to ensure that each is supported by the table schema. I use the Item explorer feature to run queries against a test table, after running the Alleycat simulator for multiple races.
1. Get the results for each race by racer ID
Use the table’s partition key, searching for PK = racer ID. This returns a list of all races (PK) for a given racer. See the updateRaceResults function for an example of how this is used:

2. Get a list of races by class ID
Use the local secondary index, searching for partition key = class ID. This results in a list of races (PK) for a given class ID. See the getRaces function code for an example of this query:

3. Get the best performance by racer for a class ID.
Use the table’s partition key, searching for PK = class ID. This returns a list of racers and their best outputs for the given class ID. See the getLeaderboard function code for an example of this query:

4. Get the list of top scores by race ID.
Use the global secondary index, searching for PK = race ID, sorting by the GSI sort key (descending) to rank the results. This returns a sorted list of results for a race. See the updateRaceResults function for an example of how this is used:

5. Get the second-by-second performance by racer for all races.
Use the main table index, searching for PK = racer ID. Optionally use the sort key to restrict to a single race. This returns items with second-by-second performance stored in a nested JSON attribute. See the loadRealtimeHistory function for an example of how this is used:
Optimizing items and capacity
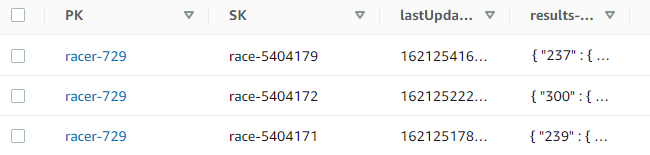
In the Alleycat application, races are only 5 minutes long so the results attribute only contains 300 separate data points (once per second). By using a nested JSON structure in the items, the schema flattens data that otherwise would use 300 rows in the earlier SQL-based design.
The maximum item size in DynamoDB is 400 KB, which includes attribute names. If you have many more data points, you may reach this limit. To work around this, split the data across multiple items and provide the item order in the sort key. This way, when your application retrieves the items, it can reassemble the attributes to create the original dataset.
For example, if races in Alleycat were an hour long, there would be 3,600 data points. These may be stored in six rows containing 600 second-by-second results each:

Additionally, to maximize the storage per row, choose short attribute names. You can also compress data in attributes by storing as GZIP output instead of raw JSON, and using a binary data type for the attribute. This increases processing for the producing and consuming applications, which must compress and decompress the items. However, it can significantly increase the amount of data stored per row.
To learn more, read Best practices for storing large items and attributes.
Conclusion
This post looks at implementing common relational database patterns using DynamoDB. Instead of using multiple tables, the single-table design pattern can use adjacency lists to provide many-to-many relational functionality.
Using the Alleycat example, I show how to list the data access patterns required by an application, and then model the data using composite keys and indexes to return the relevant data using single queries. Finally, I show how to optimize items and capacity for workloads storing large amounts of data.
For more serverless learning resources, visit Serverless Land.