Amazon SageMaker for MLOps
Deliver high-performance production ML models quickly at scale
Why Amazon SageMaker MLOps

How it works
Benefits of SageMaker MLOps
-
Create repeatable training workflows to accelerate model development
-
Catalogue ML artifacts centrally for model reproducibility and governance
-
Integrate ML workflows with CI/CD pipelines for faster time to production
-
Continuously monitor data and models in production to maintain quality
Accelerate model development
Provision standardized data science environments
Standardizing ML development environments increases data scientist productivity and ultimately the pace of innovation by making it easy to launch new projects, rotate data scientists across projects, and implement ML best practices. Amazon SageMaker Projects offers templates to quickly provision standardized data scientist environments with well-tested and up-to-date tools and libraries, source control repositories, boilerplate code, and CI/CD pipelines.
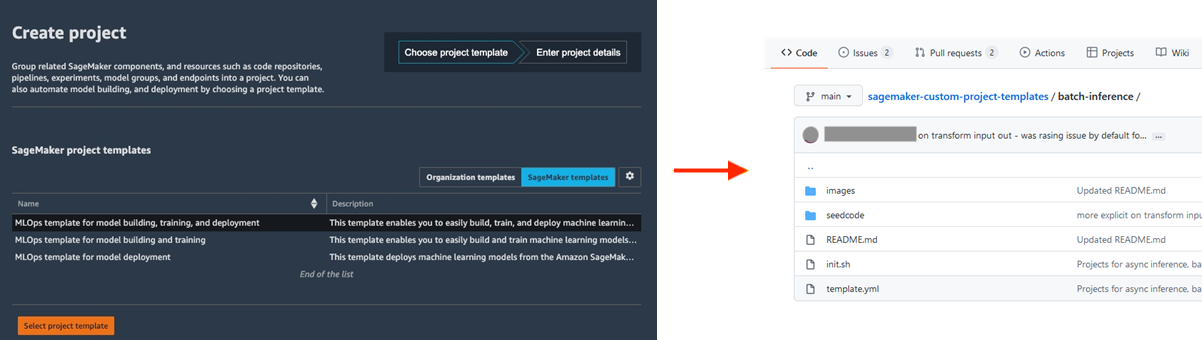
Collaborate using MLflow during ML experimentation
ML model building is an iterative process, involving the training of hundreds of models to find the best algorithm, architecture, and parameters for optimal model accuracy. MLflow enables you to track the inputs and outputs across these training iterations, improving repeatability of trials and fostering collaboration among data scientists. With fully managed MLflow capabilities, you can create MLflow Tracking Servers for each team, facilitating efficient collaboration during ML experimentation.
Amazon SageMaker with MLflow manages the end-to-end machine learning lifecycle, streamlining efficient model training, tracking experiments, and reproducibility across different frameworks and environments. It offers a single interface where you can visualize in-progress training jobs, share experiments with colleagues, and register models directly from an experiment.
Automate GenAI model customization workflows
With Amazon SageMaker Pipelines you can automate the end-to-end ML workflow of data processing, model training, fine-tuning, evaluation, and deployment. Build your own model or customize a foundation model from SageMaker Jumpstart with a few clicks in the Pipelines visual editor. You can configure SageMaker Pipelines to run automatically at regular intervals or when certain events are triggered (e.g. new training data in S3)
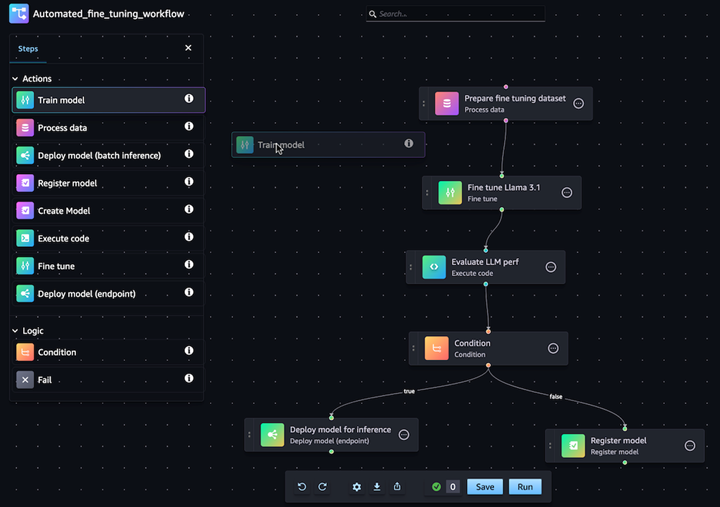
Easily deploy and manage models in production
Quickly reproduce your models for troubleshooting
Often, you need to reproduce models in production to troubleshoot model behavior and determine the root cause. To help with this, Amazon SageMaker logs every step of your workflow, creating an audit trail of model artifacts, such as training data, configuration settings, model parameters, and learning gradients. Using lineage tracking, you can recreate models to debug potential issues.
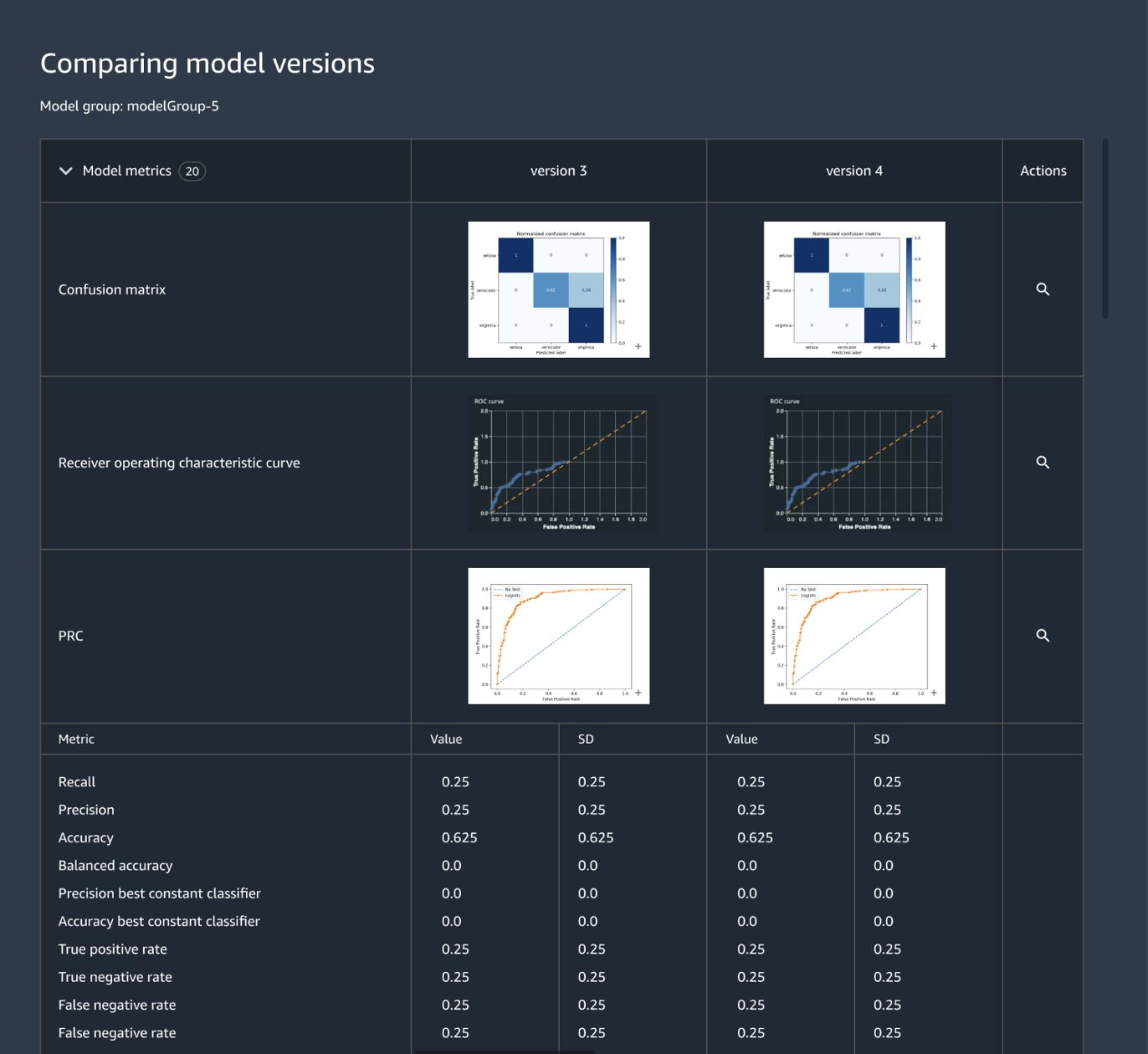
Centrally track and manage model versions
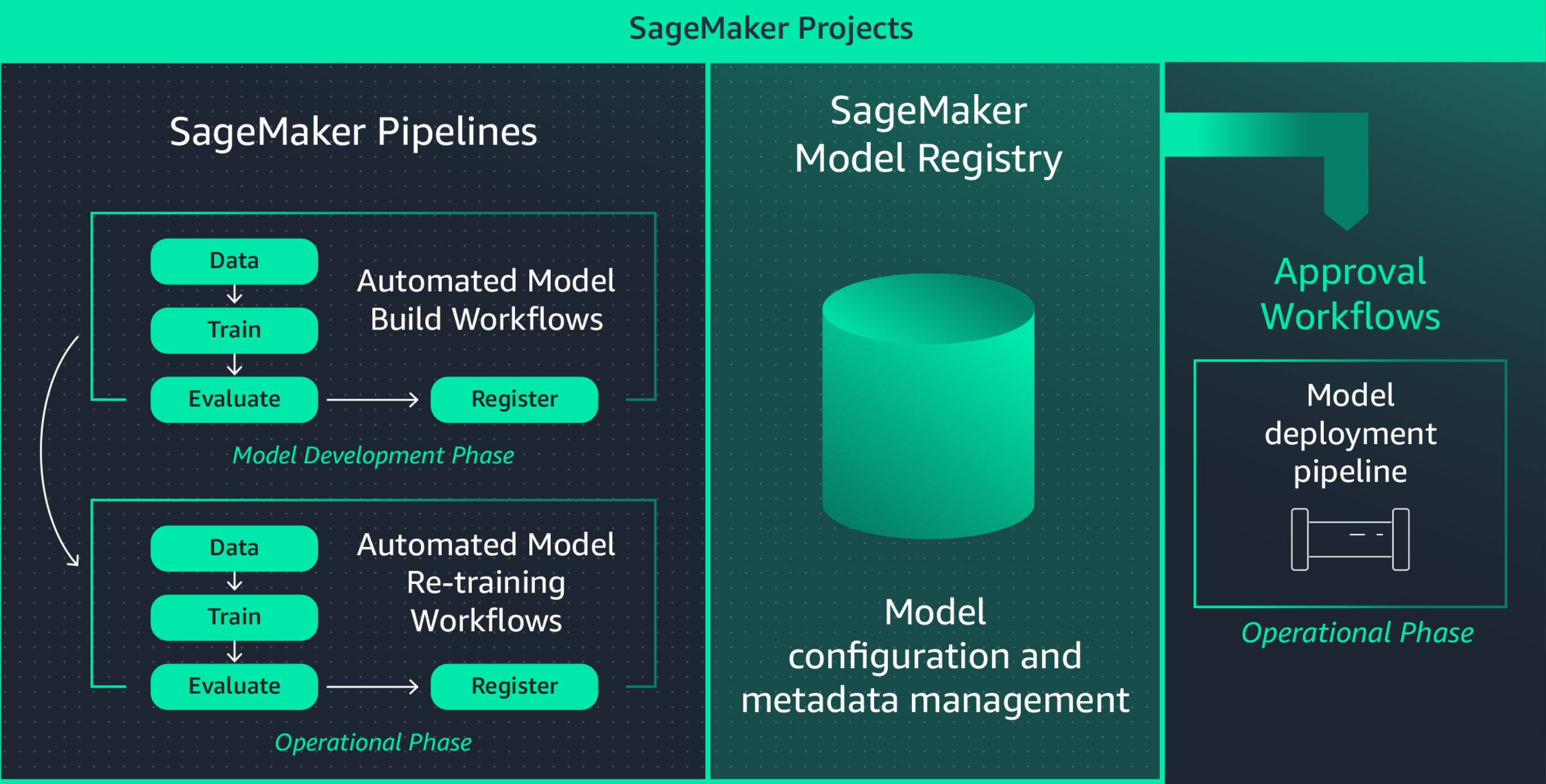
Building an ML application involves developing models, data pipelines, training pipelines, and validation tests. Using Amazon SageMaker Model Registry, you can track model versions, their metadata such as use case grouping, and model performance metrics baselines in a central repository where it is easy to choose the right model for deployment based on your business requirements. In addition, SageMaker Model Registry automatically logs approval workflows for audit and compliance.
Define ML infrastructure through code
Orchestrating infrastructure through declarative configuration files, commonly referred to as “infrastructure-as-code,” is a popular approach to provisioning ML infrastructure and implementing solution architecture exactly as specified by CI/CD pipelines or deployment tools. Using Amazon SageMaker Projects, you can write infrastructure-as-code using pre-built templates files.
Automate integration and deployment (CI/CD) workflows
ML development workflows should integrate with integration and deployment workflows to rapidly deliver new models for production applications. Amazon SageMaker Projects brings CI/CD practices to ML, such as maintaining parity between development and production environments, source and version control, A/B testing, and end-to-end automation. As a result, you put a model to production as soon as it is approved and increase agility.
In addition, Amazon SageMaker offers built-in safeguards to help you maintain endpoint availability and minimize deployment risk. SageMaker takes care of setting up and orchestrating deployment best practices such as Blue/Green deployments to maximize availability and integrates them with endpoint update mechanisms, such as auto rollback mechanisms, to help you automatically identify issues early and take corrective action before they significantly impact production.
Continuously retrain models to maintain prediction quality
Once a model is in production, you need to monitor its performance by configuring alerts so an on-call data scientist can troubleshoot the issue and trigger retraining. Amazon SageMaker Model Monitor helps you maintain quality by detecting model drift and concept drift in real time and sending you alerts so you can take immediate action. SageMaker Model Monitor constantly monitors model performance characteristics such as accuracy, which measures the number of correct predictions compared to the total number of predictions, so you can address anomalies. SageMaker Model Monitor is integrated with SageMaker Clarify to improve visibility into potential bias.
Optimize model deployment for performance and cost
Amazon SageMaker makes it easy to deploy ML models for inference at high performance and low cost for any use case. It provides a broad selection of ML infrastructure and model deployment options to meet all your ML inference needs.

Resources for SageMaker MLOps
What's new
Launch Amazon SageMaker Autopilot experiments from Amazon SageMaker Pipelines to easily automate MLOps workflows
11/30/2022
Amazon SageMaker Pipelines now supports the testing of machine learning workflows in your local environment
08/17/2022
Amazon SageMaker Pipelines now supports sharing of pipeline entities across accounts
08/09/2022
MLOps Workload Orchestrator adds support for Amazon SageMaker Model Explainability and Model Bias Monitoring
02/02/2022