Artificial Intelligence
Detect NLP data drift using custom Amazon SageMaker Model Monitor
Natural language understanding is applied in a wide range of use cases, from chatbots and virtual assistants, to machine translation and text summarization. To ensure that these applications are running at an expected level of performance, it’s important that data in the training and production environments is from the same distribution. When the data that is used for inference (production data) differs from the data used during model training, we encounter a phenomenon known as data drift. When data drift occurs, the model is no longer relevant to the data in production and likely performs worse than expected. It’s important to continuously monitor the inference data and compare it to the data used during training.
You can use Amazon SageMaker to quickly build, train, and deploy machine learning (ML) models at any scale. As a proactive measure against model degradation, you can use Amazon SageMaker Model Monitor to continuously monitor the quality of your ML models in real time. With Model Monitor, you can also configure alerts to notify and trigger actions if any drift in model performance is observed. Early and proactive detection of these deviations enables you to take corrective actions, such as collecting new ground truth training data, retraining models, and auditing upstream systems, without having to manually monitor models or build additional tooling.
Model Monitor offers four different types of monitoring capabilities to detect and mitigate model drift in real time:
- Data quality – Helps detect change in data schemas and statistical properties of independent variables and alerts when a drift is detected.
- Model quality – For monitoring model performance characteristics such as accuracy or precision in real time, Model Monitor allows you to ingest the ground truth labels collected from your applications. Model Monitor automatically merges the ground truth information with prediction data to compute the model performance metrics.
- Model bias –Model Monitor is integrated with Amazon SageMaker Clarify to improve visibility into potential bias. Although your initial data or model may not be biased, changes in the world may cause bias to develop over time in a model that has already been trained.
- Model explainability – Drift detection alerts you when a change occurs in the relative importance of feature attributions.
In this post, we discuss the types of data quality drift that are applicable to text data. We also present an approach to detecting data drift in text data using Model Monitor.
Data drift in NLP
Data drift can be classified into three categories depending on whether the distribution shift is happening on the input or on the output side, or whether the relationship between the input and the output has changed.
Covariate shift
In a covariate shift, the distribution of inputs changes over time, but the conditional distribution P(y|x) doesn’t change. This type of drift is called covariate shift because the problem arises due to a shift in the distribution of the covariates (features). For example, in an email spam classification model, distribution of training data (email corpora) may diverge from the distribution of data during scoring.
Label shift
While covariate shift focuses on changes in the feature distribution, label shift focuses on changes in the distribution of the class variable. This type of shifting is essentially the reverse of covariate shift. An intuitive way to think about it might be to consider an unbalanced dataset. If the spam to non-spam ratio of emails in our training set is 50%, but in reality 10% of our emails are non-spam, then the target label distribution has shifted.
Concept shift
Concept shift is different from covariate and label shift in that it’s not related to the data distribution or the class distribution, but instead is related to the relationship between the two variables. For example, email spammers often use a variety of concepts to pass the spam filter models, and the concept of emails used during training may change as time goes by.
Now that we understand the different types of data drift, let’s see how we can use Model Monitor to detect covariate shift in text data.
Solution overview
Unlike tabular data, which is structured and bounded, textual data is complex, high dimensional, and free form. To efficiently detect drift in NLP, we work with embeddings, which are low-dimensional representations of the text. You can obtain embeddings using various language models such as Word2Vec and transformer-based models like BERT. These models project high-dimensional data into low-dimensional spaces while preserving the semantic information of the text. The results are dense and contextually meaningful vectors, which can be used for various downstream tasks, including monitoring for data drift.
In our solution, we use embeddings to detect the covariate shift of English sentences. We utilize Model Monitor to facilitate continuous monitoring for a text classifier that is deployed to a production environment. Our approach consists of the following steps:
- Fine-tune a BERT model using SageMaker.
- Deploy a fine-tuned BERT classifier as a real-time endpoint with data capture enabled.
- Create a baseline dataset that consists of a sample of the sentences used to train the BERT classifier.
- Create a custom SageMaker monitoring job to calculate the cosine similarity between the data captured in production and the baseline dataset.
The following diagram illustrates the solution workflow:
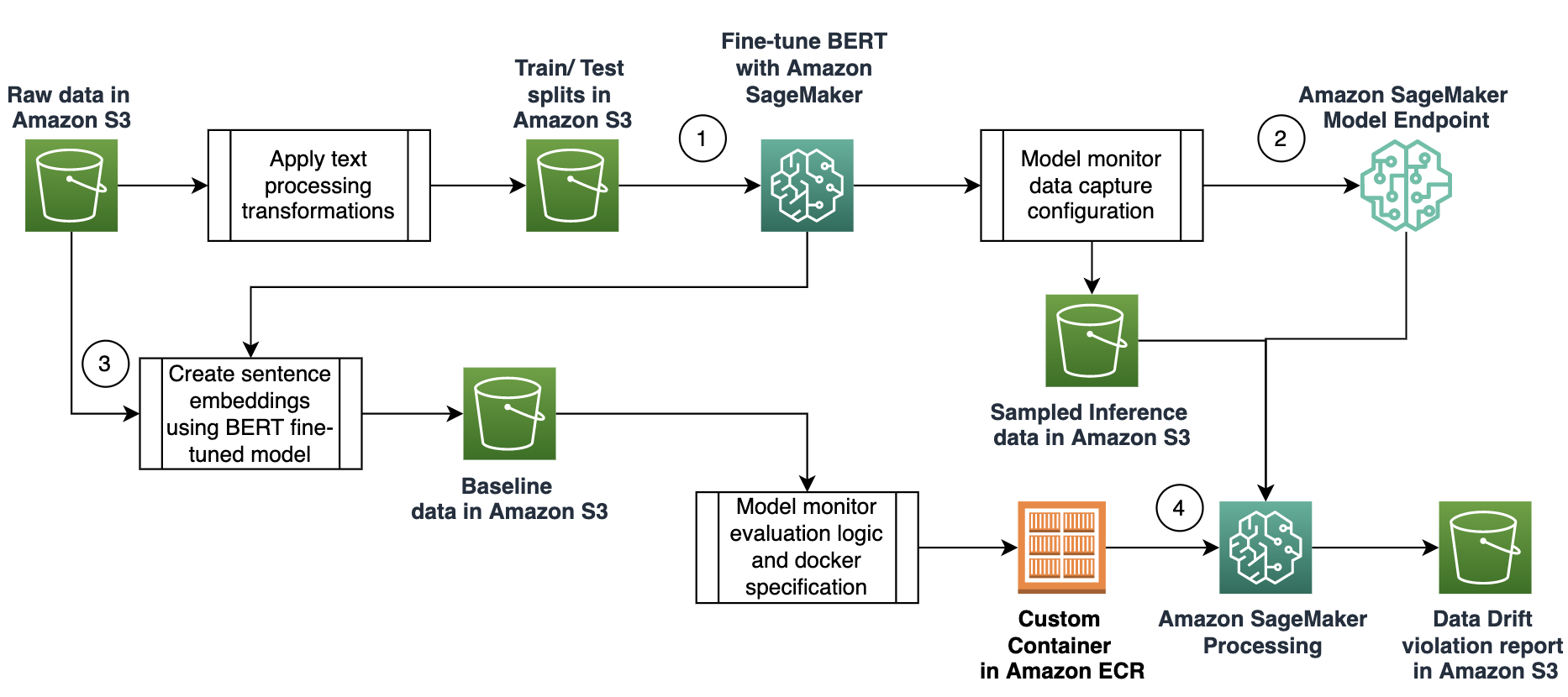
Fine-tune a BERT model
In this post, we use Corpus of Linguistic Acceptability (CoLA), a dataset of 10,657 English sentences labeled as grammatical or ungrammatical from published linguistics literature. We use SageMaker training to fine-tune a BERT model using the CoLa dataset by defining an PyTorch estimator class. For more information on how to use this SDK with PyTorch, see Use PyTorch with the SageMaker Python SDK. Calling the fit() method of the estimator launches the training job:
Deploy the model
After training our model, we host it on a SageMaker endpoint. To make the endpoint load the model and serve predictions, we implement a few methods in train_deploy.py:
- model_fn() – Loads the saved model and returns a model object that can be used for model serving. The SageMaker PyTorch model server loads our model by invoking
model_fn. - input_fn() – Deserializes and prepares the prediction input. In this example, our request body is first serialized to JSON and then sent to the model serving endpoint. Therefore, in
input_fn(), we first deserialize the JSON-formatted request body and return the input as atorch.tensor, as required for BERT. - predict_fn() – Performs the prediction and returns the result.
Enable Model Monitor data capture
We enable Model Monitor data capture to record the input data into the Amazon Simple Storage Service (Amazon S3) bucket to reference it later:
Then we create a real-time SageMaker endpoint with the model created in the previous step:
Inference
We run prediction using the predictor object that we created in the previous step. We set JSON serializer and deserializer, which is used by the inference endpoint:
The real-time endpoint is configured to capture data from the request, and the response and the data gets stored in Amazon S3. You can view the data that’s captured in the previous monitoring schedule.
Create a baseline
We use a fine-tuned BERT model to extract sentence embedding features from the training data. We use these vectors as high-quality feature inputs for comparing cosine distance because BERT produces dynamic word representation with semantic context. Complete the following steps to get sentence embedding:
- Use a BERT tokenizer to get token IDs for each token (
input_id) in the input sentence and mask to indicate which elements in the input sequence are tokens vs. padding elements (attention_mask_id). We use the BERTtokenizer.encode_plusfunction to get these values for each input sentence:
input_ids and attention_mask_ids are passed to the model and fetch the hidden states of the network. The hidden_states has four dimensions in the following order:
- Layer number (BERT has 12 layers)
- Batch number (1 sentence)
- Word token indexes
- Hidden units (768 features)
- Use the last two hidden layers to get a single vector (sentence embedding) by calculating the average of all input tokens in the sentence:
- Convert the sentence embedding as a NumPy array and store it in an Amazon S3 location as a baseline that is used by Model Monitor:
Evaluation script
Model Monitor provides a pre-built container with the ability to analyze the data captured from endpoints for tabular datasets. If you want to bring your own container, Model Monitor provides extension points that you can use. When you create a MonitoringSchedule, Model Monitor ultimately kicks off processing jobs. Therefore, the container needs to be aware of the processing job contract. We need to create an evaluation script that is compatible with container contract inputs and outputs.
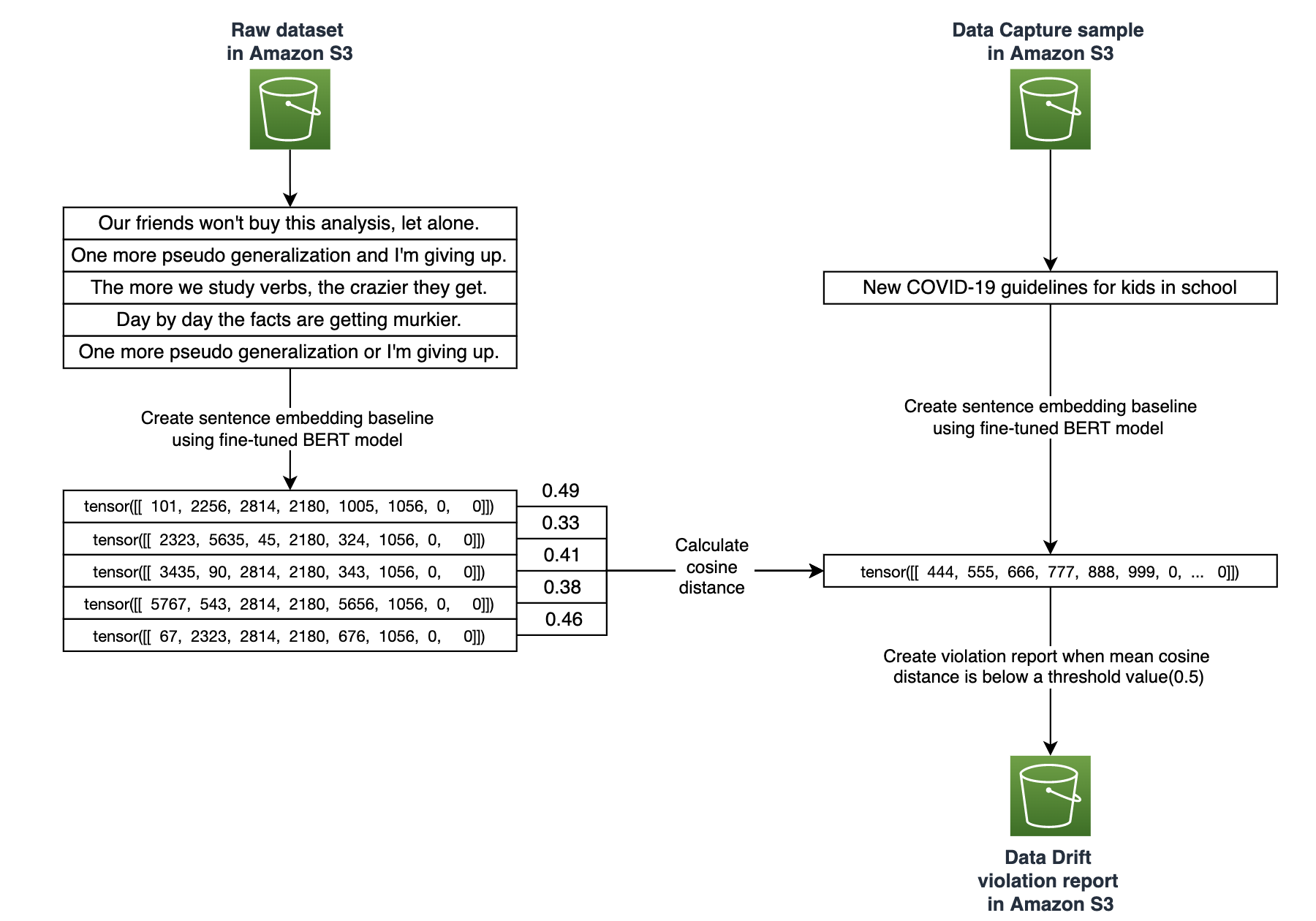
Model Monitor uses evaluation code on all the samples that are captured during the monitoring schedule. For each inference data point, we calculate the sentence embedding using the same logic described earlier. Cosine similarity is used as a distance metric to measure the similarity of an inference data point and sentence embeddings in the baseline. Mathematically, it measures the cosine angle between two sentence embedding vectors. A high the cosine similarity score indicates similar sentence embeddings. A lower cosine similarity score indicates data drift. We calculate an average of all the cosine similarity scores, and if it’s less than the threshold, it gets captured in the violation report. Based on the use case, you can use other distance metrics like manhattan or euclidean to measure similarity of sentence embeddings.
The following diagram shows how we use SageMaker Model Monitoring to establish baseline and detect data drift using cosine distance similarity.
The following is the code for calculating the violations; the complete evaluation script is available on GitHub:
Measure data drift using Model Monitor
In this section, we focus on measuring data drift using Model Monitor. Model Monitor pre-built monitors are powered by Deequ, which is a library built on top of Apache Spark for defining unit tests for data, which measure data quality in large datasets. You don’t require coding to utilize these pre-built monitoring capabilities. You also have the flexibility to monitor models by coding to provide custom analysis. You can collect and review all metrics emitted by Model Monitor in Amazon SageMaker Studio, so you can visually analyze your model performance without writing additional code.
In certain scenarios, for instance when the data is non-tabular, the default processing job (powered by Deequ) doesn’t suffice because it only supports tabular datasets. The pre-built monitors may not be sufficient to generate sophisticated metrics to detect drifts, and may necessitate bringing your own metrics. In the next sections, we describe the setup to bring in your metrics by building a custom container.
Build the custom Model Monitor container
We use the evaluation script from the previous section to build a Docker container and push it to Amazon Elastic Container Registry (Amazon ECR):
When the customer Docker container is in Amazon ECR, we can schedule a Model Monitoring job and generate a violations report, as demonstrated in the next sections.
Schedule a model monitoring job
To schedule a model monitoring job, we create an instance of Model Monitor and in the image_uri, we refer to the Docker container that we created in the previous section:
We schedule the monitoring job using the create_monitoring_schedule API. You can schedule the monitoring job on an hourly or daily basis. You configure the job using the destination parameter, as shown in the following code:
To describe and list the monitoring schedule and its runs, you can use the following commands:
Data drift violation report
When the model monitoring job is complete, you can navigate to the destination S3 path to access the violation reports. This report contains all the inputs whose average cosine score (avg_cosine_score) is below the threshold configured as an environment variable THRESHOLD:0.5 in the ModelMonitor instance. This is an indication that the data observed during inference is drifting beyond the established baseline.
The following code shows the generated violation report:
Finally, based on this observation, you can configure your model for retraining. You can also enable Amazon Simple Notification Service (Amazon SNS) notifications to send alerts when violations occur.
Conclusion
Model Monitor enables you to maintain the high quality of your models in production. In this post, we highlighted the challenges with monitoring data drift on unstructured data like text, and provided an intuitive approach to detect data drift using a custom monitoring script. You can find the code associated with the post in the following GitHub repository. Additionally, you can customize the solution to utilize other distance metrics such as maximum mean discrepancy (MMD), a non-parametric distance metric to compute marginal distribution between source and target distribution on the embedded space.
About the Authors
 Vikram Elango is an AI/ML Specialist Solutions Architect at Amazon Web Services, based in Virginia, USA. Vikram helps financial and insurance industry customers with design, thought leadership to build and deploy machine learning applications at scale. He is currently focused on natural language processing, responsible AI, inference optimization and scaling ML across the enterprise. In his spare time, he enjoys traveling, hiking, cooking and camping with his family.
Vikram Elango is an AI/ML Specialist Solutions Architect at Amazon Web Services, based in Virginia, USA. Vikram helps financial and insurance industry customers with design, thought leadership to build and deploy machine learning applications at scale. He is currently focused on natural language processing, responsible AI, inference optimization and scaling ML across the enterprise. In his spare time, he enjoys traveling, hiking, cooking and camping with his family.
 Raghu Ramesha is a ML Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
Raghu Ramesha is a ML Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
 Tony Chen is a Machine Learning Solutions Architect at Amazon Web Services, helping customers design scalable and robust machine learning capabilities in the cloud. As a former data scientist and data engineer, he leverages his experience to help tackle some of the most challenging problems organizations face with operationalizing machine learning.
Tony Chen is a Machine Learning Solutions Architect at Amazon Web Services, helping customers design scalable and robust machine learning capabilities in the cloud. As a former data scientist and data engineer, he leverages his experience to help tackle some of the most challenging problems organizations face with operationalizing machine learning.