Artificial Intelligence
Category: Amazon Textract

Pair Nova 2 Lite with Claude for cost-optimized document processing
In this post, we show how pairing Amazon Nova 2 Lite with Anthropic’s Claude Sonnet 4.6 delivers an efficient solution for digitizing scanned documents at scale. We built a two-model pipeline on Amazon Bedrock for digitizing scanned yearbook pages. Amazon Nova 2 Lite handles native multimodal extraction in a single call: detecting photos, extracting visible names with coordinates, and returning page-level metadata. Claude Sonnet 4.6 then performs spatial reasoning to match names to faces based on page layout.

Huntington Bank: Redacting sensitive data from 400M+ documents with AWS
In this post, we walk through how Huntington built a scalable AWS solution to detect and redact Personally Identifiable Information (PII) and Payment Card Industry (PCI) data from over 400 million documents, reducing processing time from years to just a few months while achieving 95%+ redaction accuracy.

Sun Finance automates ID extraction and fraud detection with generative AI on AWS
In this post, we show how Sun Finance used Amazon Bedrock, Amazon Textract, and Amazon Rekognition to build an AI-powered identity verification (IDV) pipeline. The solution improved extraction accuracy from 79.7% to 90.8%, cut per-document costs by 91%, and reduced processing time from up to 20 hours to under 5 seconds. You’ll learn how combining specialized OCR with large language model (LLM) structuring outperformed using either tool alone. You’ll also learn how to architect a serverless fraud detection system using vector similarity search.

Rocket Close transforms mortgage document processing with Amazon Bedrock and Amazon Textract
Through a strategic partnership with the AWS Generative AI Innovation Center (GenAIIC), Rocket Close developed an intelligent document processing solution that has significantly reduced processing time, making the process 15 times faster. The solution, which uses Amazon Textract for OCR processing and Amazon Bedrock for foundation models (FMs), achieves a strong 90% overall accuracy in document segmentation, classification, and field extraction.

How Ricoh built a scalable intelligent document processing solution on AWS
This post explores how Ricoh built a standardized, multi-tenant solution for automated document classification and extraction using the AWS GenAI IDP Accelerator as a foundation, transforming their document processing from a custom-engineering bottleneck into a scalable, repeatable service.

How LinqAlpha assesses investment theses using Devil’s Advocate on Amazon Bedrock
LinqAlpha is a Boston-based multi-agent AI system built specifically for institutional investors. The system supports and streamlines agentic workflows across company screening, primer generation, stock price catalyst mapping, and now, pressure-testing investment ideas through a new AI agent called Devil’s Advocate. In this post, we share how LinqAlpha uses Amazon Bedrock to build and scale Devil’s Advocate.
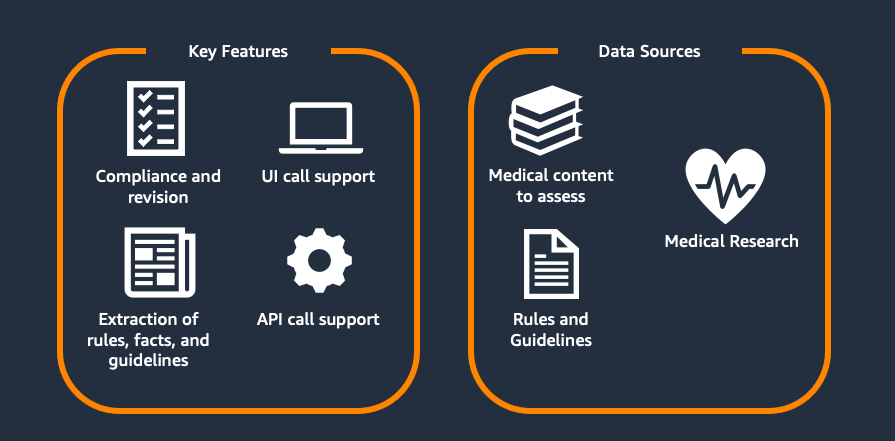
Scaling medical content review at Flo Health using Amazon Bedrock (Part 1)
This two-part series explores Flo Health’s journey with generative AI for medical content verification. Part 1 examines our proof of concept (PoC), including the initial solution, capabilities, and early results. Part 2 covers focusing on scaling challenges and real-world implementation. Each article stands alone while collectively showing how AI transforms medical content management at scale.
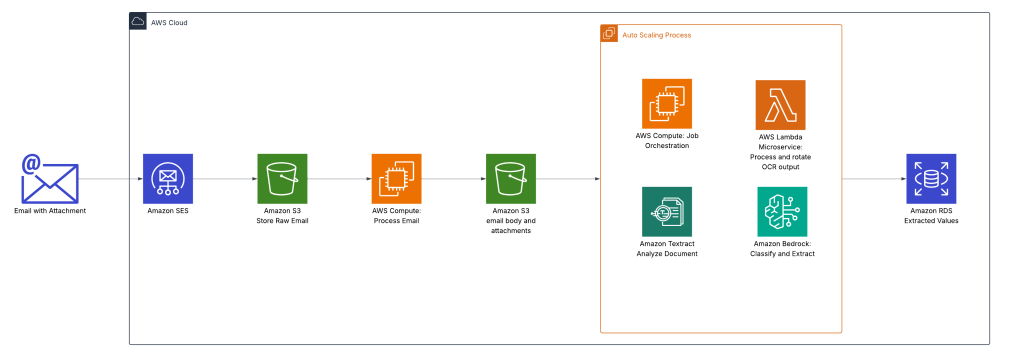
Oldcastle accelerates document processing with Amazon Bedrock
This post explores how Oldcastle partnered with AWS to transform their document processing workflow using Amazon Bedrock with Amazon Textract. We discuss how Oldcastle overcame the limitations of their previous OCR solution to automate the processing of hundreds of thousands of POD documents each month, dramatically improving accuracy while reducing manual effort.
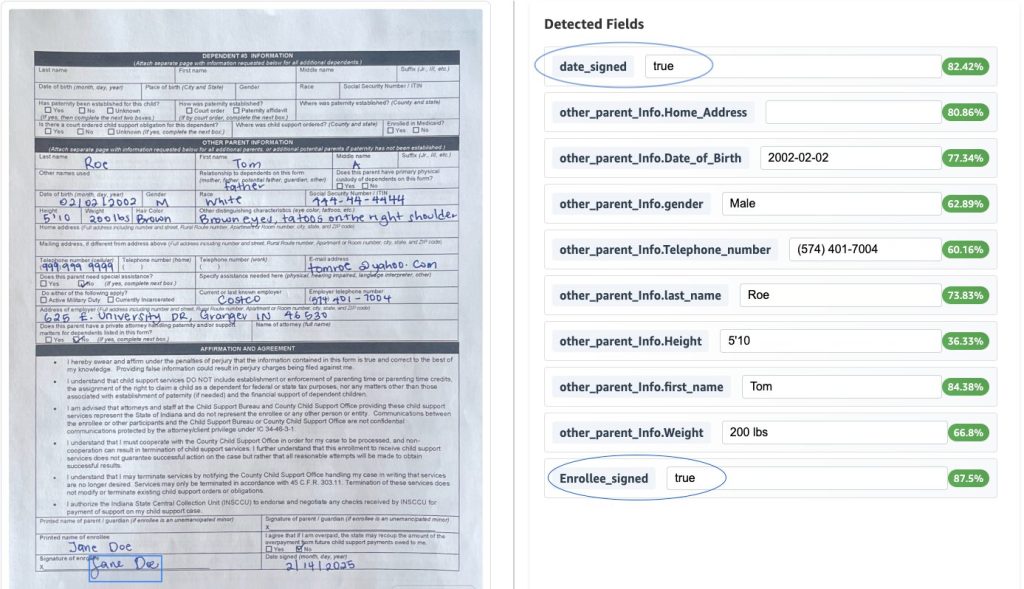
Scalable intelligent document processing using Amazon Bedrock Data Automation
In the blog post Scalable intelligent document processing using Amazon Bedrock, we demonstrated how to build a scalable IDP pipeline using Anthropic foundation models on Amazon Bedrock. Although that approach delivered robust performance, the introduction of Amazon Bedrock Data Automation brings a new level of efficiency and flexibility to IDP solutions. This post explores how Amazon Bedrock Data Automation enhances document processing capabilities and streamlines the automation journey.

How Gardenia Technologies helps customers create ESG disclosure reports 75% faster using agentic generative AI on Amazon Bedrock
Gardenia Technologies, a data analytics company, partnered with the AWS Prototyping and Cloud Engineering (PACE) team to develop Report GenAI, a fully automated ESG reporting solution powered by the latest generative AI models on Amazon Bedrock. This post dives deep into the technology behind an agentic search solution using tooling with Retrieval Augmented Generation (RAG) and text-to-SQL capabilities to help customers reduce ESG reporting time by up to 75%. We demonstrate how AWS serverless technology, combined with agents in Amazon Bedrock, are used to build scalable and highly flexible agent-based document assistant applications.