Artificial Intelligence
Category: Amazon SageMaker Ground Truth

How Tata Power CoE built a scalable AI-powered solar panel inspection solution with Amazon SageMaker AI and Amazon Bedrock
In this post, we explore how Tata Power CoE and Oneture Technologies use AWS services to automate the inspection process end-to-end.
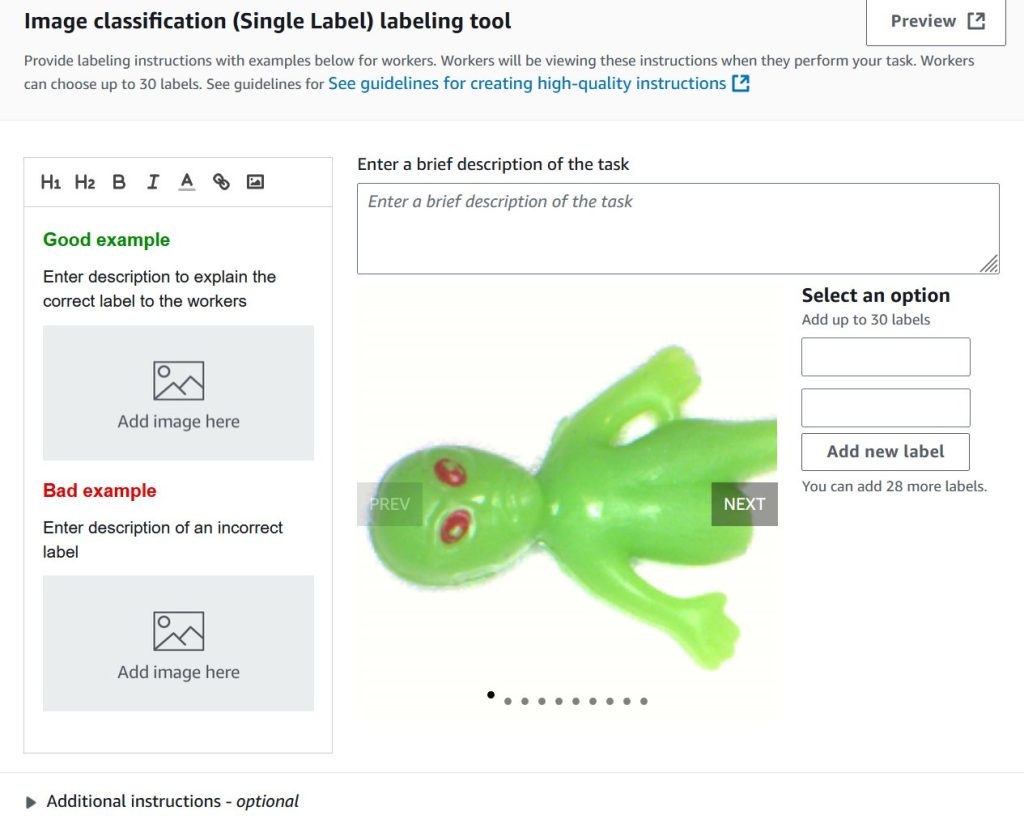
Train custom computer vision defect detection model using Amazon SageMaker
In this post, we demonstrate how to migrate computer vision workloads from Amazon Lookout for Vision to Amazon SageMaker AI by training custom defect detection models using pre-trained models available on AWS Marketplace. We provide step-by-step guidance on labeling datasets with SageMaker Ground Truth, training models with flexible hyperparameter configurations, and deploying them for real-time or batch inference—giving you greater control and flexibility for automated quality inspection use cases.
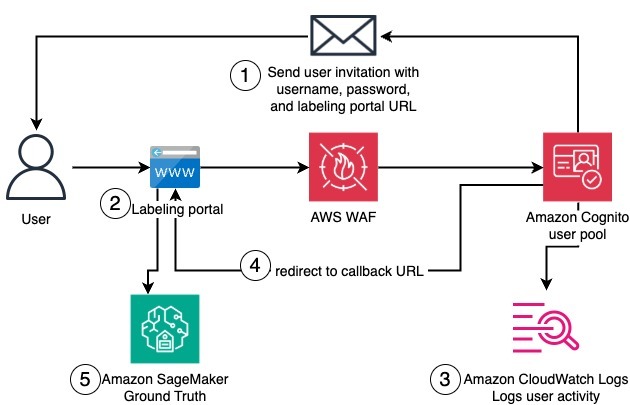
Create a private workforce on Amazon SageMaker Ground Truth with the AWS CDK
In this post, we present a complete solution for programmatically creating private workforces on Amazon SageMaker AI using the AWS Cloud Development Kit (AWS CDK), including the setup of a dedicated, fully configured Amazon Cognito user pool.
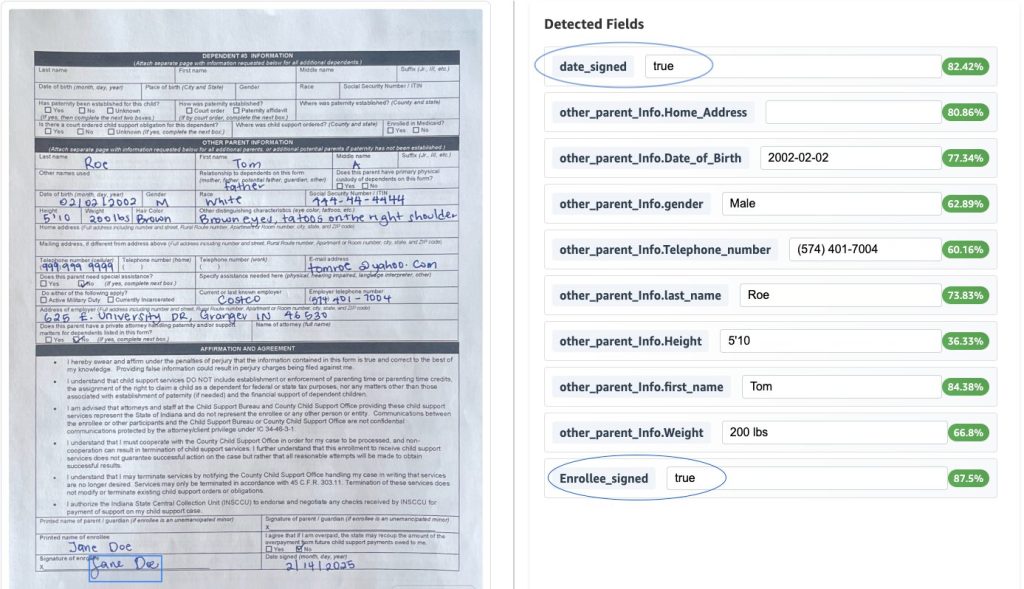
Scalable intelligent document processing using Amazon Bedrock Data Automation
In the blog post Scalable intelligent document processing using Amazon Bedrock, we demonstrated how to build a scalable IDP pipeline using Anthropic foundation models on Amazon Bedrock. Although that approach delivered robust performance, the introduction of Amazon Bedrock Data Automation brings a new level of efficiency and flexibility to IDP solutions. This post explores how Amazon Bedrock Data Automation enhances document processing capabilities and streamlines the automation journey.

Process multi-page documents with human review using Amazon Bedrock Data Automation and Amazon SageMaker AI
In this post, we show how to process multi-page documents with a human review loop using Amazon Bedrock Data Automation and Amazon SageMaker AI.

Use generative AI in Amazon Bedrock for enhanced recommendation generation in equipment maintenance
In the manufacturing world, valuable insights from service reports often remain underutilized in document storage systems. This post explores how Amazon Web Services (AWS) customers can build a solution that automates the digitisation and extraction of crucial information from many reports using generative AI.

Enhance speech synthesis and video generation models with RLHF using audio and video segmentation in Amazon SageMaker
In this post, we show you how to implement an audio and video segmentation solution using SageMaker Ground Truth. We guide you through deploying the necessary infrastructure using AWS CloudFormation, creating an internal labeling workforce, and setting up your first labeling job. By the end of this post, you will have a fully functional audio/video segmentation workflow that you can adapt for various use cases, from training speech synthesis models to improving video generation capabilities.

Accelerate custom labeling workflows in Amazon SageMaker Ground Truth without using AWS Lambda
Amazon SageMaker Ground Truth enables the creation of high-quality, large-scale training datasets, essential for fine-tuning across a wide range of applications, including large language models (LLMs) and generative AI. By integrating human annotators with machine learning, SageMaker Ground Truth significantly reduces the cost and time required for data labeling. Whether it’s annotating images, videos, or […]

Create a data labeling project with Amazon SageMaker Ground Truth Plus
Amazon SageMaker Ground Truth is a powerful data labeling service offered by AWS that provides a comprehensive and scalable platform for labeling various types of data, including text, images, videos, and 3D point clouds, using a diverse workforce of human annotators. In addition to traditional custom-tailored deep learning models, SageMaker Ground Truth also supports generative […]

How Northpower used computer vision with AWS to automate safety inspection risk assessments
In this post, we share how Northpower has worked with their technology partner Sculpt to reduce the effort and carbon required to identify and remediate public safety risks. Specifically, we cover the computer vision and artificial intelligence (AI) techniques used to combine datasets into a list of prioritized tasks for field teams to investigate and mitigate.