Artificial Intelligence
Category: Amazon SageMaker Ground Truth
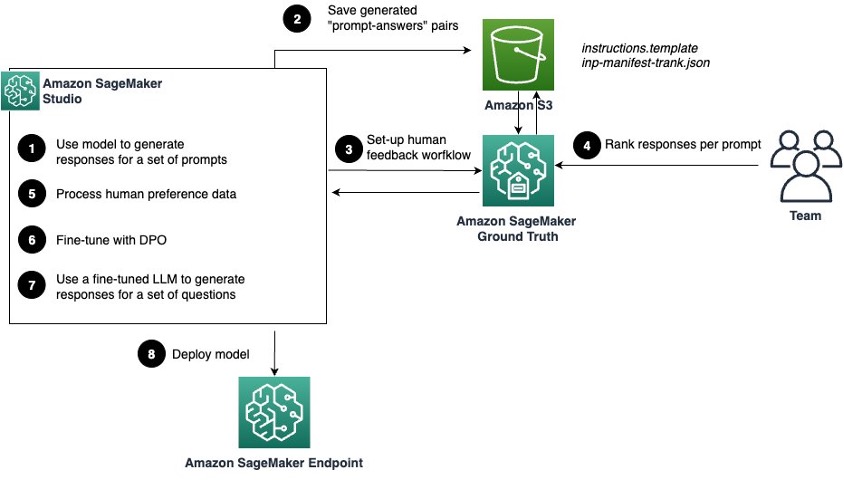
Align Meta Llama 3 to human preferences with DPO, Amazon SageMaker Studio, and Amazon SageMaker Ground Truth
In this post, we show you how to enhance the performance of Meta Llama 3 8B Instruct by fine-tuning it using direct preference optimization (DPO) on data collected with SageMaker Ground Truth.

Use LangChain with PySpark to process documents at massive scale with Amazon SageMaker Studio and Amazon EMR Serverless
In this post, we explore how to build a scalable and efficient Retrieval Augmented Generation (RAG) system using the new EMR Serverless integration, Spark’s distributed processing, and an Amazon OpenSearch Service vector database powered by the LangChain orchestration framework. This solution enables you to process massive volumes of textual data, generate relevant embeddings, and store them in a powerful vector database for seamless retrieval and generation.

Use IP-restricted presigned URLs to enhance security in Amazon SageMaker Ground Truth
While presigned URLs offer a convenient way to grant temporary access to S3 objects, sharing these URLs with people outside of the workteam can lead to unintended access of those objects. To mitigate this risk and enhance the security of SageMaker Ground Truth labeling tasks, we have introduced a new feature that adds an additional layer of security by restricting access to the presigned URLs to the worker’s IP address or virtual private cloud (VPC) endpoint from which they access the labeling task. In this blog post, we show you how to enable this feature, allowing you to enhance your data security as needed, and outline the success criteria for this feature, including the scenarios where it will be most beneficial.

How Krikey AI harnessed the power of Amazon SageMaker Ground Truth to accelerate generative AI development
This post is co-written with Jhanvi Shriram and Ketaki Shriram from Krikey. Krikey AI is revolutionizing the world of 3D animation with their innovative platform that allows anyone to generate high-quality 3D animations using just text or video inputs, without needing any prior animation experience. At the core of Krikey AI’s offering is their powerful […]

Incorporate offline and online human – machine workflows into your generative AI applications on AWS
Recent advances in artificial intelligence have led to the emergence of generative AI that can produce human-like novel content such as images, text, and audio. These models are pre-trained on massive datasets and, to sometimes fine-tuned with smaller sets of more task specific data. An important aspect of developing effective generative AI application is Reinforcement […]

Build an active learning pipeline for automatic annotation of images with AWS services
This blog post is co-written with Caroline Chung from Veoneer. Veoneer is a global automotive electronics company and a world leader in automotive electronic safety systems. They offer best-in-class restraint control systems and have delivered over 1 billion electronic control units and crash sensors to car manufacturers globally. The company continues to build on a […]

Skeleton-based pose annotation labeling using Amazon SageMaker Ground Truth
Pose estimation is a computer vision technique that detects a set of points on objects (such as people or vehicles) within images or videos. Pose estimation has real-world applications in sports, robotics, security, augmented reality, media and entertainment, medical applications, and more. Pose estimation models are trained on images or videos that are annotated with […]

How AWS Prototyping enabled ICL-Group to build computer vision models on Amazon SageMaker
This is a customer post jointly authored by ICL and AWS employees. ICL is a multi-national manufacturing and mining corporation based in Israel that manufactures products based on unique minerals and fulfills humanity’s essential needs, primarily in three markets: agriculture, food, and engineered materials. Their mining sites use industrial equipment that has to be monitored […]

Automate PDF pre-labeling for Amazon Comprehend
Amazon Comprehend is a natural-language processing (NLP) service that provides pre-trained and custom APIs to derive insights from textual data. Amazon Comprehend customers can train custom named entity recognition (NER) models to extract entities of interest, such as location, person name, and date, that are unique to their business. To train a custom model, you […]

Build an end-to-end MLOps pipeline for visual quality inspection at the edge – Part 1
A successful deployment of a machine learning (ML) model in a production environment heavily relies on an end-to-end ML pipeline. Although developing such a pipeline can be challenging, it becomes even more complex when dealing with an edge ML use case. Machine learning at the edge is a concept that brings the capability of running […]