Artificial Intelligence
Category: Expert (400)

Inference meta-monitoring for Amazon SageMaker AI endpoints with Amazon Quick
Learn how to build an inference meta-monitoring system for Amazon SageMaker AI endpoints using Amazon Quick. This governance layer sits above production ML inference pipelines to continuously track prediction and data quality, detect drift, integrate delayed ground truth, and surface automated performance dashboards.

Best practices for applying Amazon Bedrock Guardrails to code generation workflows
In this post, we explain how Amazon Bedrock Guardrails can be configured for code generation workflows with coding assistants to overcome these constraints. With these best practices, you can build an efficient blueprint helping you with effective capacity planning with robust safety coverage.

Building multi-Region visualizations with Highcharts in Amazon Quick
This post shows you how to build multi-Region carrier performance dashboards in Quick Sight using Highcharts custom visualizations to overcome native chart limitations. You will learn how to maintain data sovereignty across AWS Regions while creating unified visualizations through the Quick Sight federated dataset capability. The solution includes production-ready chart configurations and addresses security, compliance, and scalability requirements.

Multi-agent social intelligence with Strands Agents and Amazon Bedrock
This post shows how Thrad.ai deployed a multi-agent system with Strands Agents and Amazon Bedrock AgentCore that automates the pipeline from prospect discovery through personalized email generation. The post compares two orchestration patterns (Swarm and Graph) with head-to-head benchmarks on latency, cost, and email quality. You’ll also learn how the system scores prospects using weighted criteria, intent classification, and temporal decay, plus governance controls for production deployment.

Accelerating software delivery with agentic QA automation using Amazon Nova Act – Part 2
In this post, we extend that foundation to demonstrate how QA Studio addresses batch regression testing and pipeline integration through test suites that organize and parallelize execution, and a command-line interface that brings agentic testing into automated CI/CD pipelines.

Enrich your datasets with business context: Migrating from legacy Topics to semantic datasets in Amazon Quick
In this post, we walk through what Dataset Enrichment is, how it differs from legacy Topics, and provide three migration scenarios with step-by-step guidance so you can move your business context into the dataset layer with confidence.

Data modeling best practices for Amazon Quick Sight multi-dataset relationships
Today, we are excited to announce Multi-Dataset Relationships in Amazon Quick Sight. This new capability lets you define logical relationships between Quick Sight datasets and perform runtime joins at query time. Instead of flattening tables ahead of time, you keep each table as its own Quick Sight dataset and declare how those datasets relate to one another inside a Quick Sight Topic.

Data modeling patterns for Amazon Quick Sight multi-dataset relationships
In this post, we shift from concepts to patterns. For each schema, you’ll find a table structure, use cases, implementation steps, and sample SQL queries. We also cover workarounds for advanced scenarios that require extra modeling steps, and close with a summary of current limitations.

Deploying Multi-Turn RL Infrastructure for Amazon Nova on Amazon SageMaker HyperPod
In this post, you deploy a two-phase infrastructure for multi-turn RL using Amazon Nova Forge on Amazon SageMaker HyperPod. By the end, you have an event-driven pipeline that starts training when you upload data to Amazon Simple Storage Service (Amazon S3). The training job teaches the model to play Wordle, a placeholder for your own RL task.
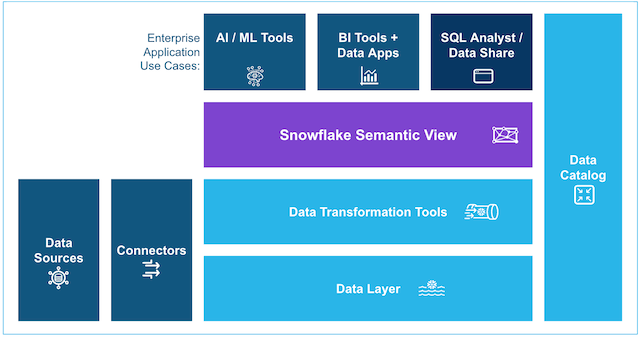
AI-powered BI with Snowflake and Amazon Quick
In this post, you will learn how to build an end-to-end integration between Snowflake semantic views and Amazon Quick. The sample data is user review data for a media company. You start by loading movie review data from Amazon Simple Storage Service (Amazon S3) into Snowflake, define a semantic view in SQL to add business meaning, explore it with natural-language queries through Cortex Analyst, and then generate an Amazon Quick dataset and dashboard. The dataset can be created manually or with a provided automation script. By the end, your BI team or AI team can ask natural-language questions against a governed data layer and trust that every response reflects the same business logic.