Artificial Intelligence
Category: Amazon SageMaker JumpStart

NVIDIA Nemotron 3 Ultra now available on Amazon SageMaker JumpStart
Deploy NVIDIA Nemotron 3 Ultra on Amazon SageMaker JumpStart. Get 5x faster inference and 30% lower cost for agentic AI workloads with this frontier reasoning model.

Fundamental’s Large Tabular Model NEXUS is now available on Amazon SageMaker JumpStart
In this post, we show you how to get started with NEXUS on Amazon SageMaker JumpStart, walk through the deployment process, and demonstrate how to run predictions against your enterprise datasets.

NVIDIA Nemotron 3 Nano Omni model now available on Amazon SageMaker JumpStart
Today, we are excited to announce the day zero availability of NVIDIA Nemotron 3 Nano Omni on Amazon SageMaker JumpStart. In this post, we walk through the model architecture and key capabilities of Nemotron 3 Nano Omni, explore the enterprise use cases it unlocks, and show you how to deploy and run inference using Amazon SageMaker JumpStart.

Use-case based deployments on SageMaker JumpStart
We’re excited to announce the launch of Amazon SageMaker JumpStart optimized deployments. SageMaker JumpStart improved deployments address the need for rich and straightforward deployment customization on SageMaker JumpStart by offering pre-defined deployment configurations, designed for specific use cases. Customers maintain the same level of visibility into the details of their proposed deployments, but now deployments are optimized for their specific use case and performance constraint.

NVIDIA Nemotron 3 Nano 30B MoE model is now available in Amazon SageMaker JumpStart
Today we’re excited to announce that the NVIDIA Nemotron 3 Nano 30B model with 3B active parameters is now generally available in the Amazon SageMaker JumpStart model catalog. You can accelerate innovation and deliver tangible business value with Nemotron 3 Nano on Amazon Web Services (AWS) without having to manage model deployment complexities. You can power your generative AI applications with Nemotron capabilities using the managed deployment capabilities offered by SageMaker JumpStart.

From beginner to champion: A student’s journey through the AWS AI League ASEAN finals
The AWS AI League, launched by Amazon Web Services (AWS), expanded its reach to the Association of Southeast Asian Nations (ASEAN) last year, welcoming student participants from Singapore, Indonesia, Malaysia, Thailand, Vietnam, and the Philippines. In this blog post, you’ll hear directly from the AWS AI League champion, Blix D. Foryasen, as he shares his reflection on the challenges, breakthroughs, and key lessons discovered throughout the competition.
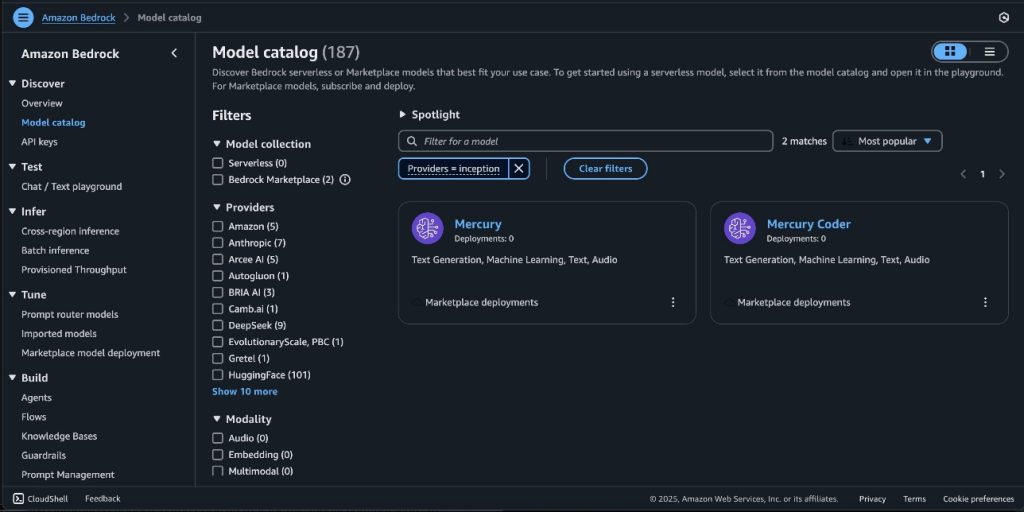
Mercury foundation models from Inception Labs are now available in Amazon Bedrock Marketplace and Amazon SageMaker JumpStart
In this post, we announce that Mercury and Mercury Coder foundation models from Inception Labs are now available through Amazon Bedrock Marketplace and Amazon SageMaker JumpStart. We demonstrate how to deploy these ultra-fast diffusion-based language models that can generate up to 1,100 tokens per second on NVIDIA H100 GPUs, and showcase their capabilities in code generation and tool use scenarios.

GPT OSS models from OpenAI are now available on SageMaker JumpStart
Today, we are excited to announce the availability of Open AI’s new open weight GPT OSS models, gpt-oss-120b and gpt-oss-20b, from OpenAI in Amazon SageMaker JumpStart. With this launch, you can now deploy OpenAI’s newest reasoning models to build, experiment, and responsibly scale your generative AI ideas on AWS. In this post, we demonstrate how to get started with these models on SageMaker JumpStart.

Mistral-Small-3.2-24B-Instruct-2506 is now available on Amazon Bedrock Marketplace and Amazon SageMaker JumpStart
Today, we’re excited to announce that Mistral-Small-3.2-24B-Instruct-2506—a 24-billion-parameter large language model (LLM) from Mistral AI that’s optimized for enhanced instruction following and reduced repetition errors—is available for customers through Amazon SageMaker JumpStart and Amazon Bedrock Marketplace. Amazon Bedrock Marketplace is a capability in Amazon Bedrock that developers can use to discover, test, and use over […]
New capabilities in Amazon SageMaker AI continue to transform how organizations develop AI models
In this post, we share some of the new innovations in SageMaker AI that can accelerate how you build and train AI models. These innovations include new observability capabilities in SageMaker HyperPod, the ability to deploy JumpStart models on HyperPod, remote connections to SageMaker AI from local development environments, and fully managed MLflow 3.0.