Artificial Intelligence
Category: Serverless

Build a serverless image editing agent with Amazon Bedrock AgentCore harness
This post walks through building a serverless image editor where users upload a photo, describe an edit in plain English, and receive the result in seconds. The agent runs on AgentCore harness without custom orchestration code. We deploy the full solution, including authentication, encrypted storage, three image editing tools, and a React frontend, with a single deployment command. The infrastructure is defined using AWS Cloud Development Kit (AWS CDK).

Accelerate agentic application development with a full-stack starter template for Amazon Bedrock AgentCore
In this post, you will learn how to deploy Fullstack AgentCore Solution Template (FAST) to your Amazon Web Services (AWS) account, understand its architecture, and see how to extend it for your requirements. You will learn how to build your own agent while FAST handles authentication, infrastructure as code (IaC), deployment pipelines, and service integration.

Migrate MLflow tracking servers to Amazon SageMaker AI with serverless MLflow
This post shows you how to migrate your self-managed MLflow tracking server to a MLflow App – a serverless tracking server on SageMaker AI that automatically scales resources based on demand while removing server patching and storage management tasks at no cost. Learn how to use the MLflow Export Import tool to transfer your experiments, runs, models, and other MLflow resources, including instructions to validate your migration’s success.

Voice AI-powered drive-thru ordering with Amazon Nova Sonic and dynamic menu displays
In this post, we’ll demonstrate how to implement a Quick Service Restaurants (QSRs) drive-thru solution using Amazon Nova Sonic and AWS services. We’ll walk through building an intelligent system that combines voice AI with interactive menu displays, providing technical insights and implementation guidance to help restaurants modernize their drive-thru operations.
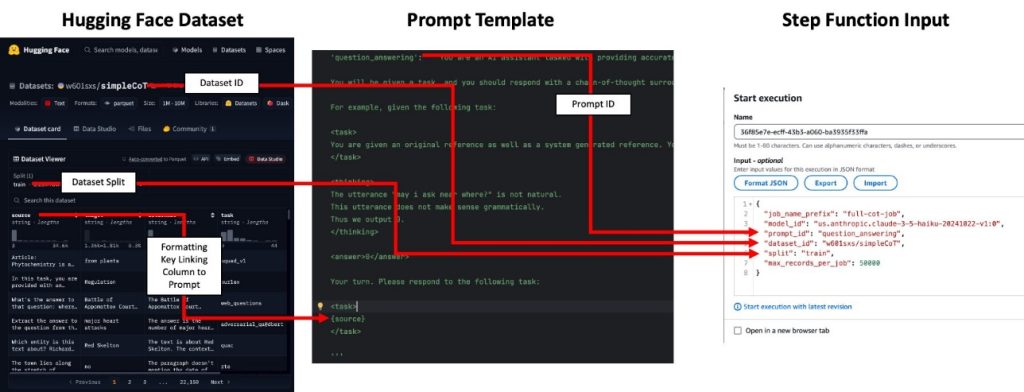
Build a serverless Amazon Bedrock batch job orchestration workflow using AWS Step Functions
In this post, we introduce a flexible and scalable solution that simplifies the batch inference workflow. This solution provides a highly scalable approach to managing your FM batch inference needs, such as generating embeddings for millions of documents or running custom evaluation or completion tasks with large datasets.
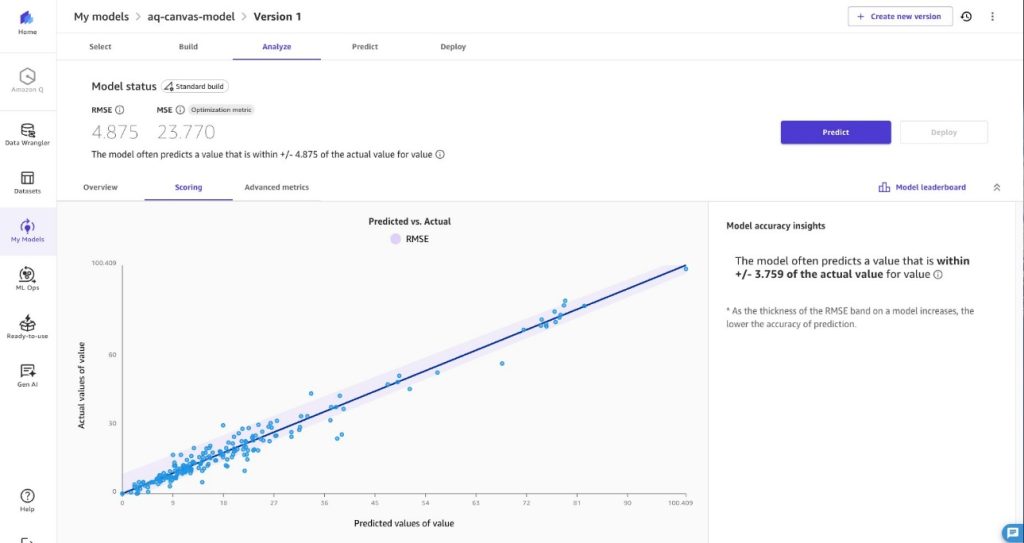
Empowering air quality research with secure, ML-driven predictive analytics
In this post, we provide a data imputation solution using Amazon SageMaker AI, AWS Lambda, and AWS Step Functions. This solution is designed for environmental analysts, public health officials, and business intelligence professionals who need reliable PM2.5 data for trend analysis, reporting, and decision-making. We sourced our sample training dataset from openAFRICA. Our solution predicts PM2.5 values using time-series forecasting.

Build a conversational natural language interface for Amazon Athena queries using Amazon Nova
In this post, we explore an innovative solution that uses Amazon Bedrock Agents, powered by Amazon Nova Lite, to create a conversational interface for Athena queries. We use AWS Cost and Usage Reports (AWS CUR) as an example, but this solution can be adapted for other databases you query using Athena. This approach democratizes data access while preserving the powerful analytical capabilities of Athena, so you can interact with your data using natural language.
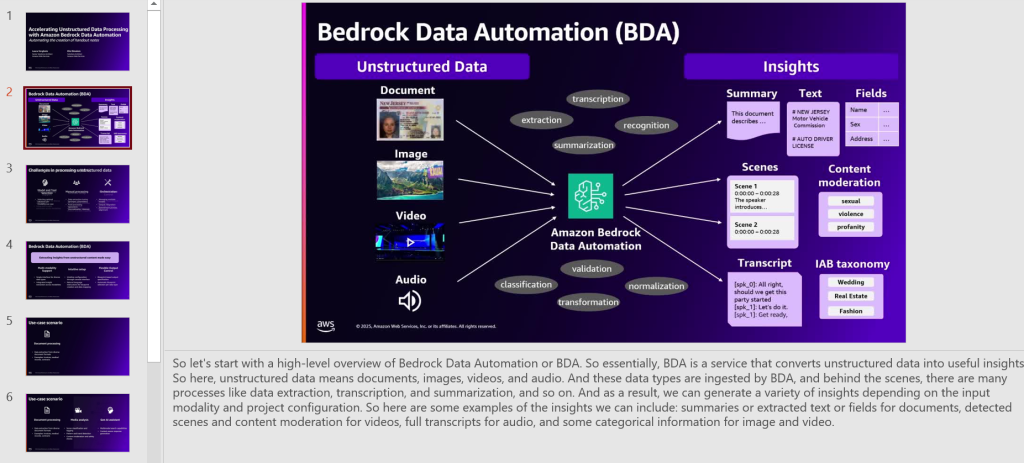
Automate the creation of handout notes using Amazon Bedrock Data Automation
In this post, we show how you can build an automated, serverless solution to transform webinar recordings into comprehensive handouts using Amazon Bedrock Data Automation for video analysis. We walk you through the implementation of Amazon Bedrock Data Automation to transcribe and detect slide changes, as well as the use of Amazon Bedrock foundation models (FMs) for transcription refinement, combined with custom AWS Lambda functions orchestrated by AWS Step Functions.
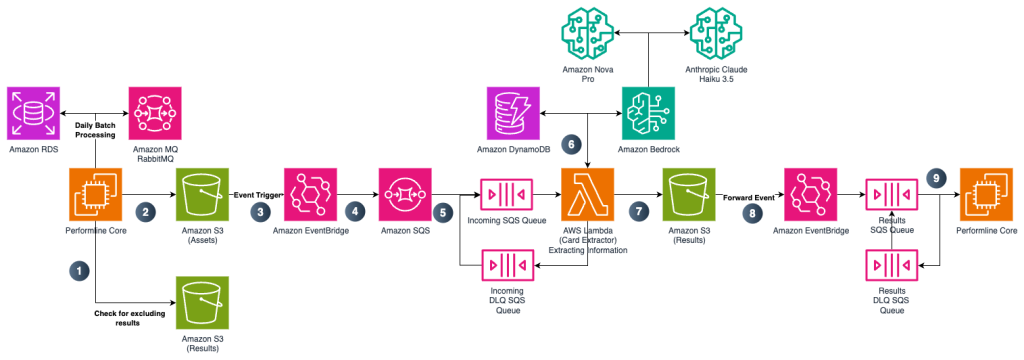
How PerformLine uses prompt engineering on Amazon Bedrock to detect compliance violations
PerformLine operates within the marketing compliance industry, a specialized subset of the broader compliance software market, which includes various compliance solutions like anti-money laundering (AML), know your customer (KYC), and others. In this post, PerformLine and AWS explore how PerformLine used Amazon Bedrock to accelerate compliance processes, generate actionable insights, and provide contextual data—delivering the speed and accuracy essential for large-scale oversight.

Integrate generative AI capabilities into Microsoft Office using Amazon Bedrock
In this blog post, we showcase a powerful solution that seamlessly integrates AWS generative AI capabilities in the form of large language models (LLMs) based on Amazon Bedrock into the Office experience. By harnessing the latest advancements in generative AI, we empower employees to unlock new levels of efficiency and creativity within the tools they already use every day.