





In questo modulo creerai un'applicazione Amazon Kinesis Data Analytics per aggregare in tempo reale dati di sensori provenienti dalla flotta di unicorni. L'applicazione leggerà dal flusso Amazon Kinesis, calcolerà la distanza totale percorsa e i punti minimi e massimi di integrità e magia per ciascun unicorno attualmente su un Wild Ryde e trasmetterà queste statistiche aggregate su un flusso Amazon Kinesis ogni minuto.
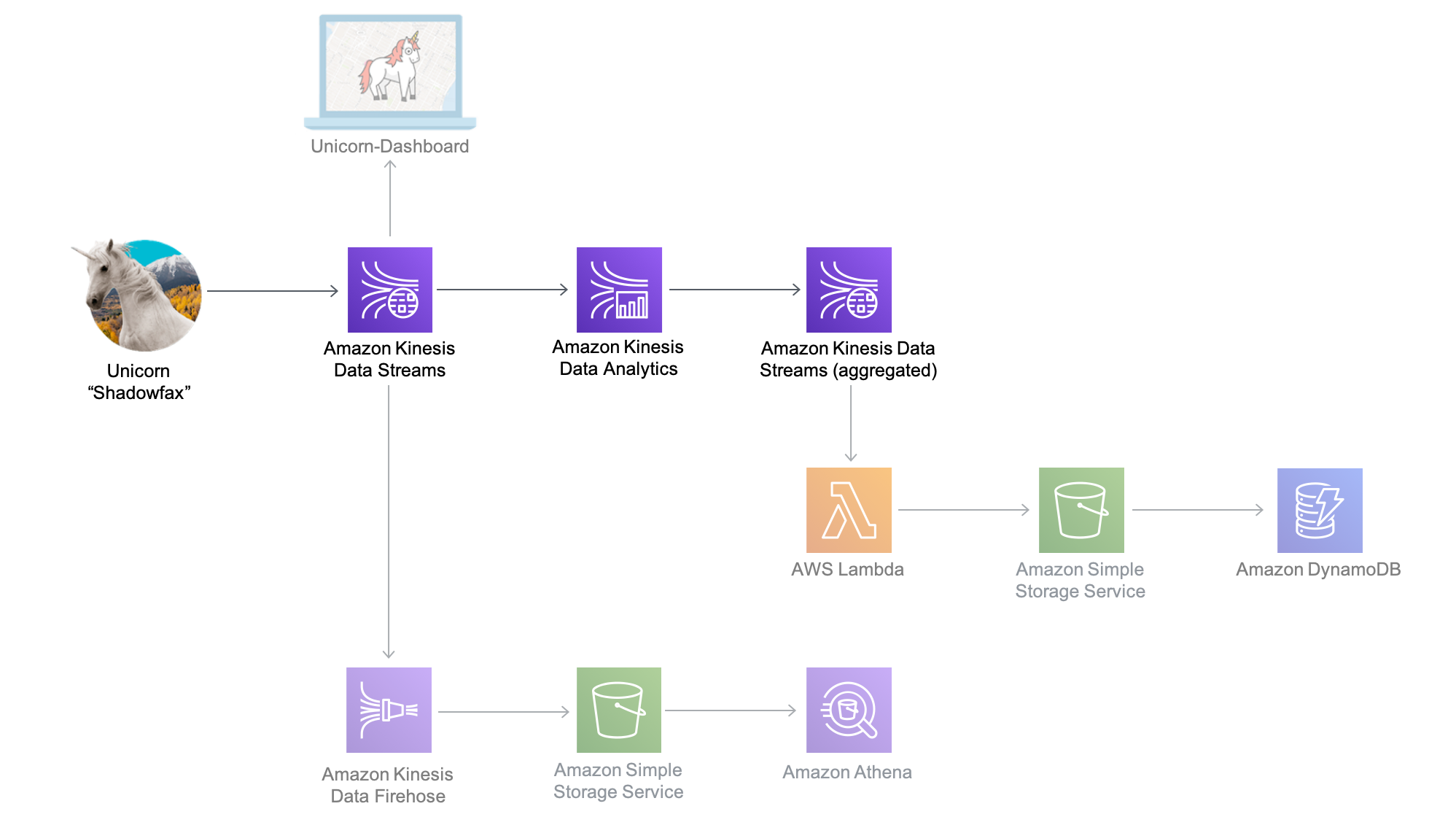
L'architettura di questo modulo prevede un'applicazione Amazon Kinesis Data Analytics, flussi Amazon Kinesis di origine e destinazione e
L'applicazione Amazon Kinesis Data Analytics elabora i dati dal flusso Amazon Kinesis di origine che abbiamo creato nel modulo precedente e li aggrega ogni minuto. Ogni minuto, l'applicazione emetterà dati che includono la distanza totale percorsa nell'ultimo minuto, nonché le letture minime e massime dai punti integrità e magia per ciascun unicorno della flotta. Questi punti dati verranno inviati a un flusso Amazon Kinesis di destinazione per l'elaborazione da parte di altri componenti del sistema.
Tempo necessario per completare il modulo: 20 minuti
Servizi utilizzati:
• Amazon Kinesis Data Streams
• Amazon Kinesis Data Analytics
-
Fase 1. Creazione di un flusso Amazon Kinesis
Utilizza la console Amazon Kinesis Data Streams per creare un nuovo flusso denominato wildrydes-summary con 1 shard.
a. Andare alla console di gestione AWS, selezionare Services (Servizi) e quindi selezionare Kinesis sotto Analytics.
b. Se compare una schermata introduttiva, selezionare Get started (Inizia subito).
c. Selezionare Create data stream (Crea flusso di dati).
d. Immettere wildrydes-summary nel campo Kinesis stream name (Nome del flusso Kinesis) e 1 nel campo Number of shards (Numero di shard), quindi selezionare Create Kinesis stream (Crea flusso Kinesis).
e. Entro 60 secondi, il flusso Kinesis sarà ACTIVE (ATTIVO) e pronto ad archiviare il flusso di dati in tempo reale.
-
Fase 2. Creazione di un'applicazione Amazon Kinesis Data Analytics
Crea un'applicazione Amazon Kinesis Data Analytics che legge dal flusso wildrydes costruito nel modulo precedente ed emette ogni minuto un oggetto JSON con i seguenti attributi:
Nome Nome unicorno StatusTime ROWTIME fornito da Amazon Kinesis Data Analytics Distanza La somma della distanza percorsa dall'unicorno MinMagicPoints Il punto dati massimo dell'attributoMagicPoints MaxMagicPoints Il punto dati massimo dell'attributoMagicPoints MinHealthPoints Il punto dati minimo dell'attributo HealthPoints MaxHealthPoints Il punto dati massimo dell'attributo HealthPointsa. Passa alla scheda in cui è aperto l'ambiente Cloud9.
b. Avvia il produttore affinché inizi a emettere dati del sensore al flusso.
./producer
La produzione attiva dei dati del sensore durante la creazione dell'applicazione consente ad Amazon Kinesis Data Analytics di rilevare automaticamente lo schema.
c. Andare alla console di gestione AWS, selezionare Services (Servizi) e quindi selezionare Kinesis sotto Analytics.
d. Selezionare Create analytics application (Crea applicazione di analisi).
e. Immettere wildrydes nel campo Application name (Nome applicazione) e quindi selezionare Create application (Crea applicazione).
f. Selezionare Connect streaming data (Connetti flussi di dati).
g. Selezionare wildrydes da Kinesis stream (Flusso Kinesis).
h. Scorrere verso il basso e fare clic su Discover schema (Scopri schema), attendere un momento e assicurarsi che lo schema sia stato correttamente scoperto in modo automatico.
Assicurarsi che lo schema scoperto automaticamente includa:
Colonna Tipo di dati Distanza DOPPIO HealthPoints INTERO Latitudine DOPPIO Longitudine DOPPIO MagicPoints INTERO Nome VARCHAR(16) StatusTime TIMESTAMP i. Selezionare Save and continue (Salva e continua).
j. Selezionare Go to SQL editor (Vai all'editor SQL). Tale operazione aprirà una sessione di query interattiva in cui possiamo creare una query sul flusso Amazon Kinesis in tempo reale.
k. Selezionare Yes (Sì) e avviare l'applicazione. Ci vorranno 30-90 secondi per l'avvio dell'applicazione.
l. Copia e incolla la seguente query SQL nell'editor SQL:
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" ( "Name" VARCHAR(16), "StatusTime" TIMESTAMP, "Distance" SMALLINT, "MinMagicPoints" SMALLINT, "MaxMagicPoints" SMALLINT, "MinHealthPoints" SMALLINT, "MaxHealthPoints" SMALLINT ); CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM "Name", "ROWTIME", SUM("Distance"), MIN("MagicPoints"), MAX("MagicPoints"), MIN("HealthPoints"), MAX("HealthPoints") FROM "SOURCE_SQL_STREAM_001" GROUP BY FLOOR("SOURCE_SQL_STREAM_001"."ROWTIME" TO MINUTE), "Name";
(fai clic per ingrandire l'immagine)
m. Selezionare Save and run SQL (Salva ed esegui SQL). Ogni minuto, vedrai arrivare le righe contenenti i dati aggregati. Aspetta che arrivino le righe.
n. Fare clic sul collegamento Destination (Destinazione).
o. Selezionare Connect to a destination (Connetti a una destinazione).
p. Selezionare wildrydes-summaryda Kinesis stream (flusso Kinesis).
q. Selezionare DESTINATION_SQL_STREAM da In-application stream name (Nome flusso nell'applicazione).
r. Selezionare Save and continue (Salva e continua).

(fai clic per ingrandire l'immagine)
-
Fase 3. Lettura dei messaggi dal flusso
Utilizza il consumatore della riga di comando per visualizzare i messaggi dal flusso Kinesis e vedere i dati aggregati inviati ogni minuto.
a. Passa alla scheda in cui è aperto l'ambiente Cloud9.
b. Esegui il consumatore per iniziare a leggere dati dei sensori dal flusso.
./consumer -stream wildrydes-summary
Il consumatore stampa ogni minuto i messaggi inviati dall'applicazione Kinesis Data Analytics:
{ "Name": "Shadowfax", "StatusTime": "2018-03-18 03:20:00.000", "Distance": 362, "MinMagicPoints": 170, "MaxMagicPoints": 172, "MinHealthPoints": 146, "MaxHealthPoints": 149 } -
Fase 4. Sperimentazione con il produttore
Arresta e avvia il produttore mentre osservi il pannello di controllo e il consumatore. Avvia più produttori con nomi di unicorno diversi.
a. Passa alla scheda in cui è aperto l'ambiente Cloud9.
b. Arresta il produttore premendo Control+C e nota che i messaggi cessano.
c. Avvia di nuovo il produttore e nota che i messaggi riprendono.
d. Premere il pulsante (+) e fare clic su New Terminal (Nuovo terminale) per aprire una nuova scheda di terminale.
e. Avvia un'altra istanza del produttore nella nuova scheda. Fornisci uno specifico nome per l'unicorno e nota i punti dati relativi a
entrambi gli unicorni nell'output del consumatore:./producer -name Bucephalus
f. Verifica di visualizzare più unicorni nell'output:
{ "Name": "Shadowfax", "StatusTime": "2018-03-18 03:20:00.000", "Distance": 362, "MinMagicPoints": 170, "MaxMagicPoints": 172, "MinHealthPoints": 146, "MaxHealthPoints": 149 } { "Name": "Bucephalus", "StatusTime": "2018-03-18 03:20:00.000", "Distance": 1773, "MinMagicPoints": 140, "MaxMagicPoints": 148, "MinHealthPoints": 132, "MaxHealthPoints": 138 } -
Riepilogo e suggerimenti
🔑 Amazon Kinesis Data Analytics permette di eseguire query su flussi di dati o creare intere applicazioni in streaming usando SQL in modo da ottenere informazioni utili e rispondere prontamente alle esigenze dell'azienda e dei clienti.
🔧 In questo modulo, hai creato un'applicazione Kinesis Data Analytics che legge dal flusso Kinesis di dati unicorno ed emette una riga di riepilogo ogni minuto.


Nel modulo successivo, utilizzerai AWS Lambda per elaborare i dati dal flusso Amazon Kinesis