- Machine learning
- Amazon SageMaker AI
- Amazon SageMaker AI MLOps
Amazon SageMaker per MLOps
Fornisci modelli di ML in produzione ad alte prestazioni rapidamente e su larga scala
Perché scegliere Amazon SageMaker MLOps
Come funziona
Vantaggi di SageMaker MLOps
-
Crea flussi di lavoro di addestramento ripetibili per accelerare lo sviluppo dei modelli
-
Cataloga gli artefatti di ML a livello centrale per la riproducibilità e la governance del modello
-
Integra i flussi di lavoro di ML con le pipeline CI/CD per tempi di produzione più rapidi
-
Monitora continuamente i dati e i modelli in produzione per mantenere la qualità
Accelera lo sviluppo dei modelli
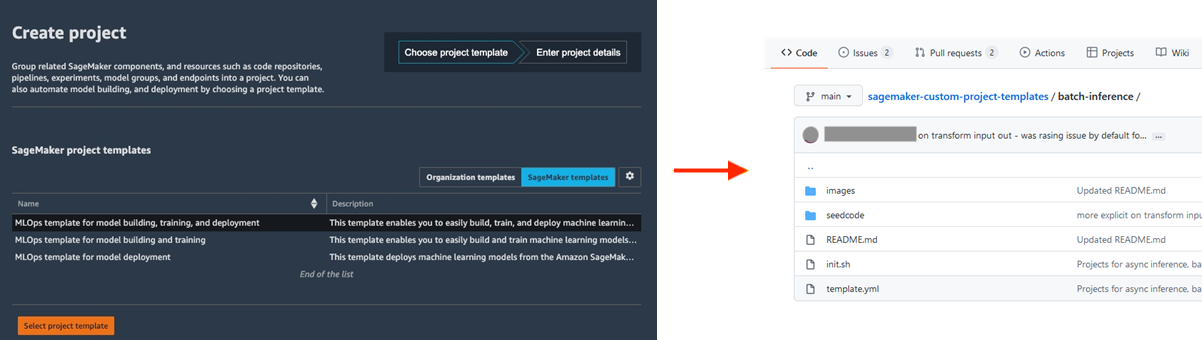
Provisioning di ambienti di data science standardizzati
La standardizzazione degli ambienti di sviluppo del ML aumenta la produttività dei data scientist e, in definitiva, la velocità di innovazione, semplificando il lancio di nuovi progetti, la rotazione dei data scientist tra i progetti e l'implementazione delle best practice di ML. Amazon SageMaker Projects offre modelli per effettuare rapidamente il provisioning di ambienti per data scientist standardizzati con strumenti e librerie testati e aggiornati, repository di controllo del codice sorgente, codice boilerplate e pipeline CI/CD.
Collabora utilizzando MLflow durante la fase di sperimentazione di machine learning
La creazione di modelli ML è un processo iterativo che prevede il training di centinaia di modelli per trovare l'algoritmo, l'architettura e i parametri migliori per una precisione ottimale del modello. MLFlow consente di tenere traccia degli input e degli output di queste iterazioni di training, migliorando la ripetibilità delle prove e promuovendo la collaborazione tra i data scientist. Con funzionalità MLFlow completamente gestite, puoi creare server di tracciamento MLFlow per ogni team, facilitando una collaborazione efficiente durante la sperimentazione ML.
Amazon SageMaker con MLFlow gestisce il ciclo di vita del machine learning end-to-end, semplificando il training efficiente dei modelli, il monitoraggio degli esperimenti e la riproducibilità in diversi framework e ambienti. Offre un'unica interfaccia in cui è possibile visualizzare i job di addestramento in corso, condividere esperimenti con i colleghi e implementare modelli direttamente da un esperimento.
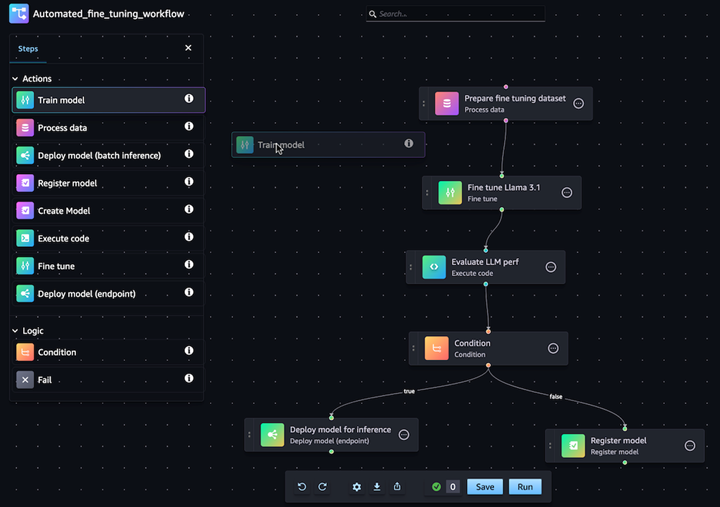
Automatizza i flussi di lavoro di personalizzazione dei modelli di IA generativa
Con Amazon SageMaker Pipelines puoi automatizzare il flusso di lavoro di ML end-to-end di elaborazione dei dati, addestramento dei modelli, fine-tuning, valutazione e implementazione. Costruisci il tuo modello o personalizzane uno di base da SageMaker Jumpstart con pochi clic nell'editor visivo Pipeline. È possibile configurare Pipeline SageMaker per l'esecuzione automatica a intervalli regolari o quando vengono attivati determinati eventi, ad esempio nuovi dati di addestramento in S3.
Implementa e gestisci facilmente i modelli in produzione
Riproduci rapidamente i modelli per la risoluzione dei problemi
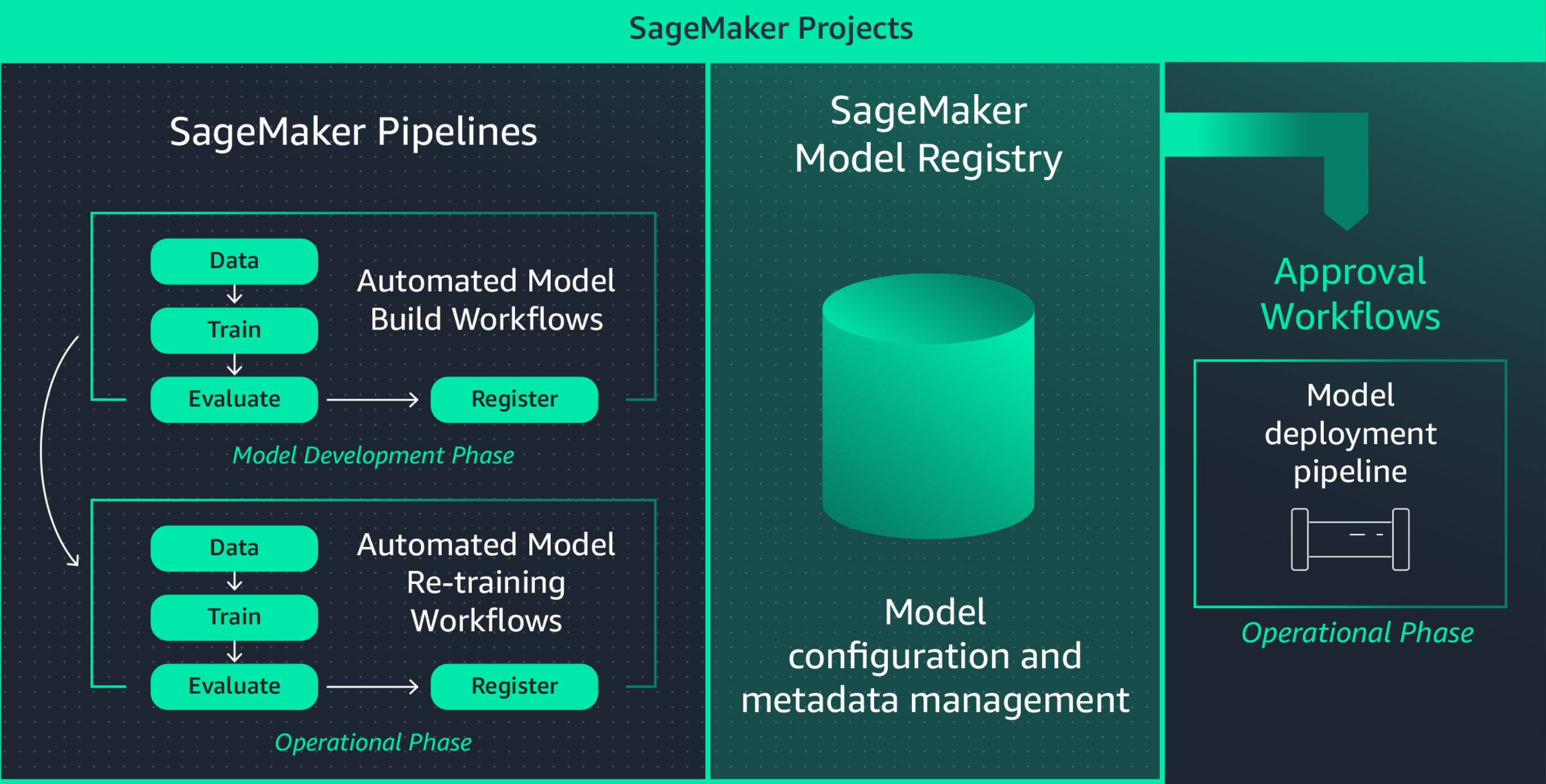
Spesso è necessario riprodurre i modelli in produzione per risolvere i problemi relativi al comportamento del modello e determinarne la causa principale. Amazon SageMaker Pipelines registra ogni fase del tuo flusso di lavoro, creando un audit trail degli artefatti del modello come i dati di addestramento, le impostazioni di configurazione, i parametri del modello e i gradienti di apprendimento. Utilizzando il monitoraggio del lineage, è possibile ricreare modelli per eseguire il debug di potenziali problemi.
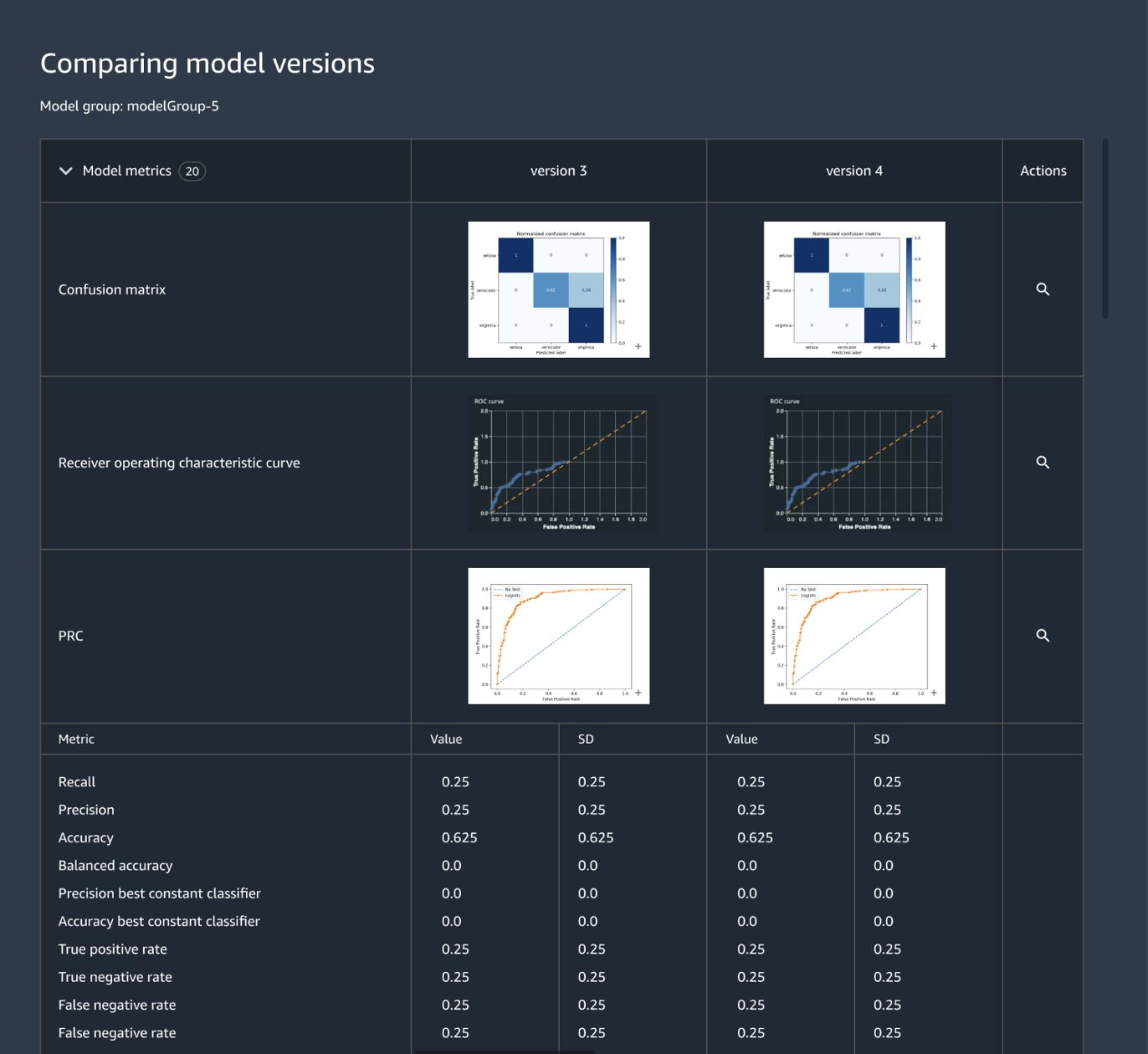
Traccia e gestisci le versioni dei modelli a livello centralizzato
La creazione di un'applicazione ML implica lo sviluppo di modelli, pipeline di dati, pipeline di addestramento e test di convalida. Amazon SageMaker Model Registry consente di monitorare le versioni dei modelli, i relativi metadati (come il raggruppamento dei casi d'uso) e le baseline dei parametri delle prestazioni dei modelli in un repository centrale da cui poter facilmente scegliere il modello più adatto da implementare in base ai requisiti aziendali. Inoltre, SageMaker Model Registry registra automaticamente i flussi di lavoro di approvazione per la verifica e la conformità.
Definisci l'infrastruttura di machine learning attraverso il codice
L'orchestrazione dell'infrastruttura tramite file di configurazione dichiarativi, comunemente noti come "infrastructure-as-code", è un approccio comune al provisioning dell'infrastruttura ML e all'implementazione dell'architettura della soluzione esattamente come specificato dalle pipeline CI/CD o dagli strumenti di implementazione. Grazie ad Amazon SageMaker Projects, è possibile scrivere l'infrastructure-as-code utilizzando file di modelli predefiniti.
Automatizza i flussi di lavoro di integrazione e distribuzione (CI/CD)
I flussi di lavoro di sviluppo ML devono combinarsi ai flussi di lavoro di integrazione e implementazione in modo da fornire rapidamente nuovi modelli per le applicazioni di produzione. Amazon SageMaker Projects trasferisce le procedure CI/CD al ML, come il mantenimento della parità tra gli ambienti di sviluppo e di produzione, il controllo del codice sorgente e delle versioni, i test A/B e l'automazione end-to-end. In questo modo, si mette in produzione un modello non appena viene approvato e se ne aumenta l'agilità.
Inoltre, Amazon SageMaker offre protezioni integrate che garantiscono di mantenere la disponibilità degli endpoint e ridurre al minimo il rischio di implementazione. SageMaker si occupa della configurazione e dell'orchestrazione delle best practice di implementazione, come le implementazioni blu/verde, per aumentare al massimo la disponibilità e le integra con i meccanismi di aggiornamento degli endpoint, come i meccanismi di rollback automatico, per identificare automaticamente i problemi in anticipo e intraprendere azioni correttive prima che influiscano in modo significativo sulla produzione.
Riaddestra continuamente i modelli per mantenere la qualità delle previsioni
Quando un modello giunge in produzione, è necessario monitorarne le prestazioni configurando gli avvisi, così che un data scientist possa risolvere tempestivamente l’eventuale problema e attivare la procedura di ri-addestramento. Amazon SageMaker Model Monitor ti aiuta a mantenere la qualità rilevando la deriva del modello e la deriva del concetto in tempo reale e inviandoti avvisi in modo da poter agire immediatamente. SageMaker Model Monitor monitora costantemente le caratteristiche delle prestazioni del modello come l'accuratezza, che misura il numero di previsioni corrette rispetto al numero totale di previsioni, in modo da poter affrontare le anomalie. SageMaker Model Monitor è integrato con SageMaker Clarify per migliorare la visibilità su potenziali distorsioni.
Ottimizza l'implementazione dei modelli per prestazioni e costi
Amazon SageMaker semplifica la distribuzione di modelli ML per l'inferenza a prestazioni elevate e a basso costo per qualsiasi caso d'uso. Offre un'ampia selezione di infrastrutture di machine learning e opzioni di implementazione dei modelli per soddisfare tutte le esigenze di inferenza di machine learning.

Risorse per SageMaker MLOps
Novità
Avvia gli esperimenti di Amazon SageMaker Autopilot da Amazon SageMaker Pipelines per automatizzare facilmente i flussi di lavoro MLOps
30/11/2022
Ora Amazon SageMaker Pipelines supporta i test dei flussi di lavoro di machine learning nell'ambiente locale
17/08/2022
Ora Amazon SageMaker Pipelines supporta la condivisione di entità di pipeline tra account
09/08/2022
L'Orchestratore di carichi di lavoro MLOps aggiunge il supporto per la spiegabilità del modello e il monitoraggio delle distorsioni del modello di Amazon SageMaker
02/02/2022