AWS News Blog
Amazon Polly – Announcing Speech Marks and Whispering
Like me, you may have loved going to the library or bookstore to have your favorite book narrated to you. As a child, I loved listening to books narrated by good storytellers who gave life to their stories by changing the inflection of their voice as needed. The book narration coupled with the visual aids the storytellers used to tell the story, drove my love for reading and exploring new books.
In fact, in order for my parents to ensure that my love of reading extended to classic novels, they bought my sister and I, a small projector device with a tape recorder. This device would narrate the story and synchronize the projection of the visuals from the book by using a chime sound to signal when we should advance to the next screen. While I have unfortunately dated myself with that story, it is great for me to look back and consider how far we have come with speech technologies like Text-to-Speech (TTS). Even with all of these advancements, it is still challenging for developers to add synchronized speech/voice to the animations of characters or graphics in their games, videos, and digital books using TTS. Additionally, it is very rare to successfully use a TTS solution to emulate the pitch, tempo, and level of loudness of the speech in lifelike voices.
With this in mind, I am happy to announce Amazon Polly is launching support for Speech Marks and Whispering.

Amazon Polly is a deep learning service that enables you to turn text into lifelike speech. You can select a voice of your choice by taking advantage of the 47 lifelike voices included in the service and its support for 24 languages. Using Polly, you can send the text you want to convert into speech to the Polly API, and it will return an audio stream that you can play or store it in common audio file formats like MP3.
Speech Marks are metadata, which allows developers to synchronize speech with visual experiences. This feature enables scenarios like lip-syncing by synchronizing speech with facial animations or using the highlighting of written words as they are spoken. The speech marks metadata describes the synthesized speech, and by using it alongside the speech audio stream can determine the beginning and ending of sounds, words, sentences, and SSML tags. With the new Speech Marks, developers can now create lip-syncing avatars, visually highlighted read-along experiences, and integrate speech capabilities into the gaming engines like Amazon Lumberyard to give a voice to the characters.
There are four types of speech marks:
- Sentence: Specifies a sentence element in the input text
- Word: Indicates a word element in the input text
- Viseme: Illustrates the position of the face and mouth corresponding to the sound that is spoken
- Speech Synthesis Markup Language (SSML): Describes a <mark> element from the SSML input text.
Whispering is a speech effect similar to pitch, tempo, and loudness, in that it provides developers with yet one more expressive voice feature with which they can now modify the Text-to-Speech output. The whispering feature allows developers to have words from their input text spoken in a whispered voice using <amazon:effect name=”whispered”> SSML element.
Let’s take a quick look at both these new features.
Using Speech Marks
I’ll jump into an example of using speech marks with Amazon Polly in the AWS Console. I’ll go first to the Amazon Polly console and press the Get started button.
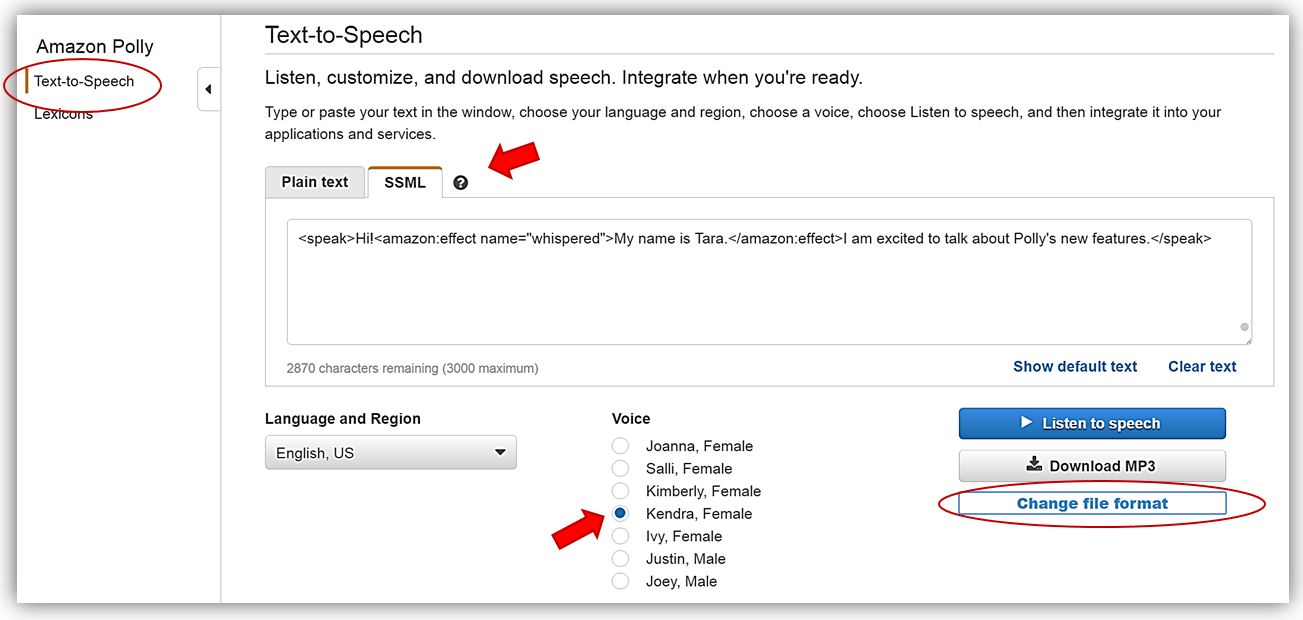
I’m taken to the Text-To-Speech menu option, and I select the SSML tab under the Text-to-Speech section. I will simply add two sentences that I wish to be spoken in the provided text field and then select a Voice.
I’ll verify the sentences are in the form that I wish them to be spoken by clicking the Listen to Speech button. Since I like what I hear, I will proceed with adding the speech marks metadata. In order to use speech marks, I will select the Change file format link.
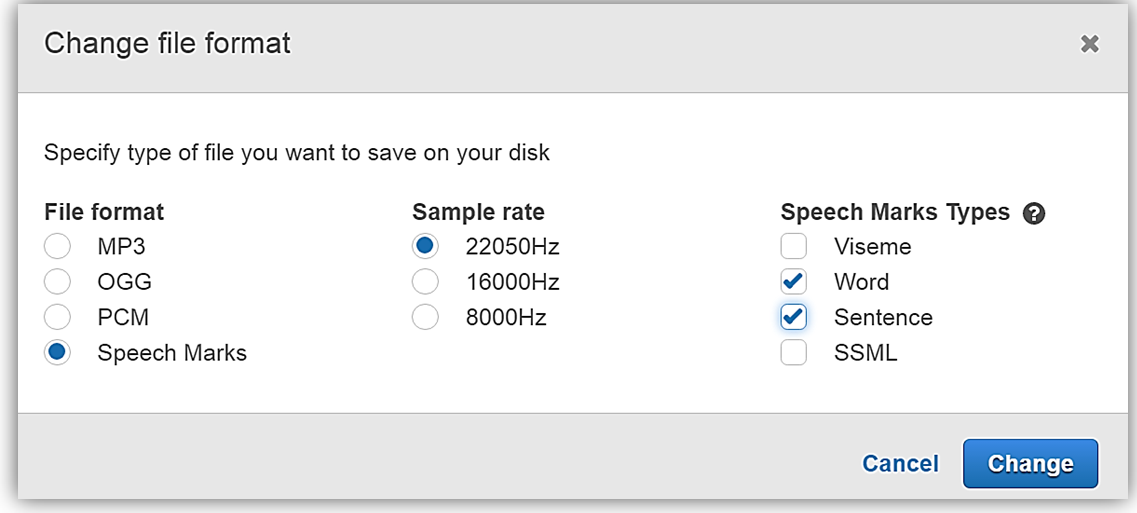
When the Change file format dialog box comes up, I will select the File Format option, Speech Marks, and under the Speech Mark Types section, I will choose: Word and Sentence, by checking the checkboxes beside each speech mark type. Now I will click the Change button.
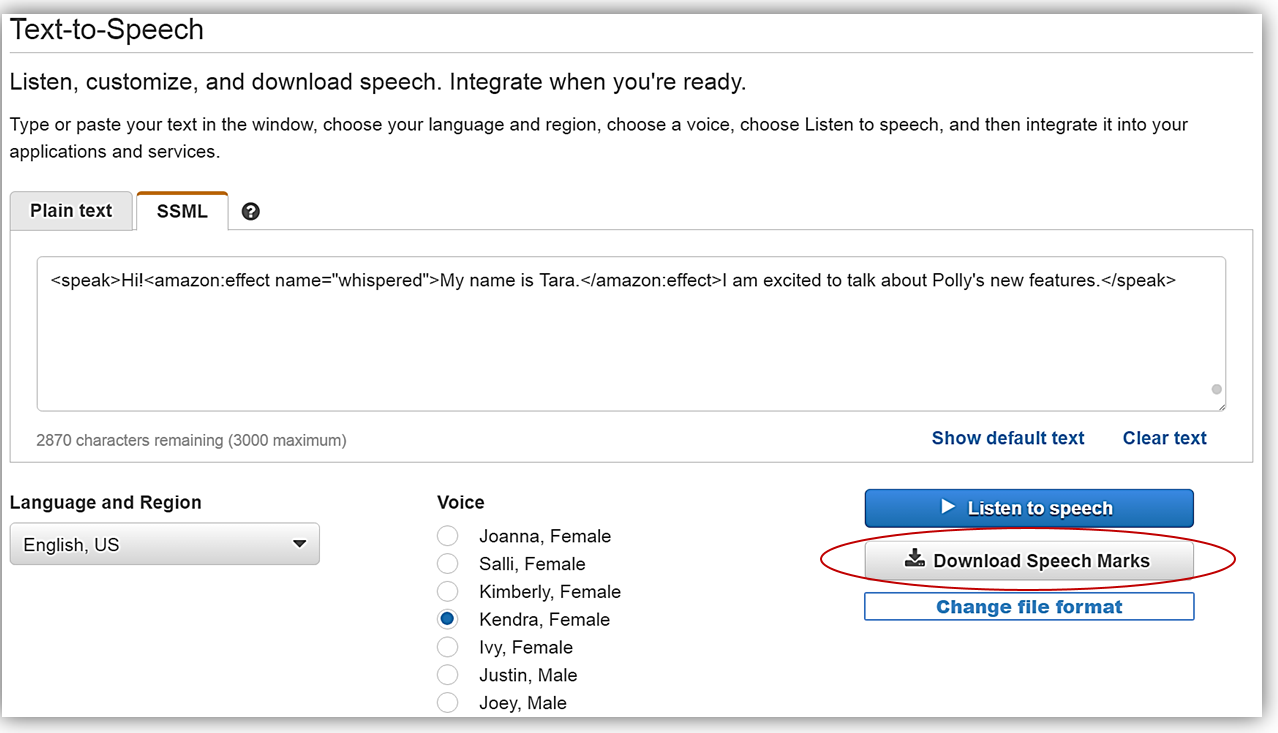
This returns me to the Text-To-Speech section of the console, and I can now click the Download Speech Marks button to see the generated speech marks.
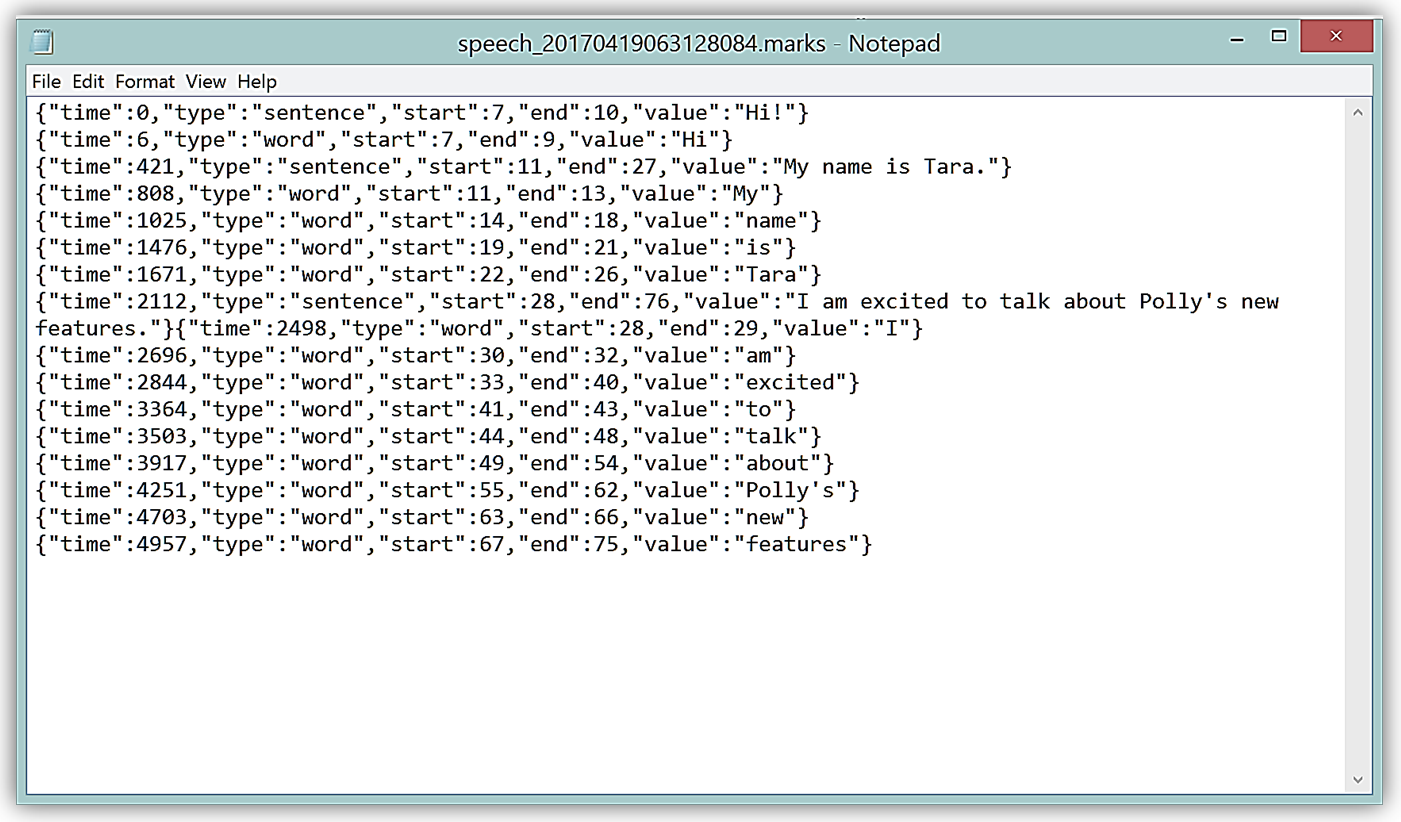
The file downloaded has a .marks extension and contains JSON, and contains information about the start and end of each of my sentences and words. The JSON fields are:
- Time: timestamp in milliseconds from the beginning of the audio stream
- Type: type of speech mark (sentence, word, viseme, or ssml)
- Start: offset in bytes from the start of the object in the input text (not including viseme marks)
- End: offset in bytes of the object’s end in the input text (not including viseme marks)
- Value – data that varies based on the type of speech mark, i.e. sentence speech mark contains the entire sentence in the text
Using Whispering
As I noted previously, using the Whispering feature allows me to have my input text be spoken in a whispered voice using the SSML amazon:effect element with a name attribute value of whispered. I’ll use my example above and insert SSML elements to have some of my text spoken using a using a whispered voice.
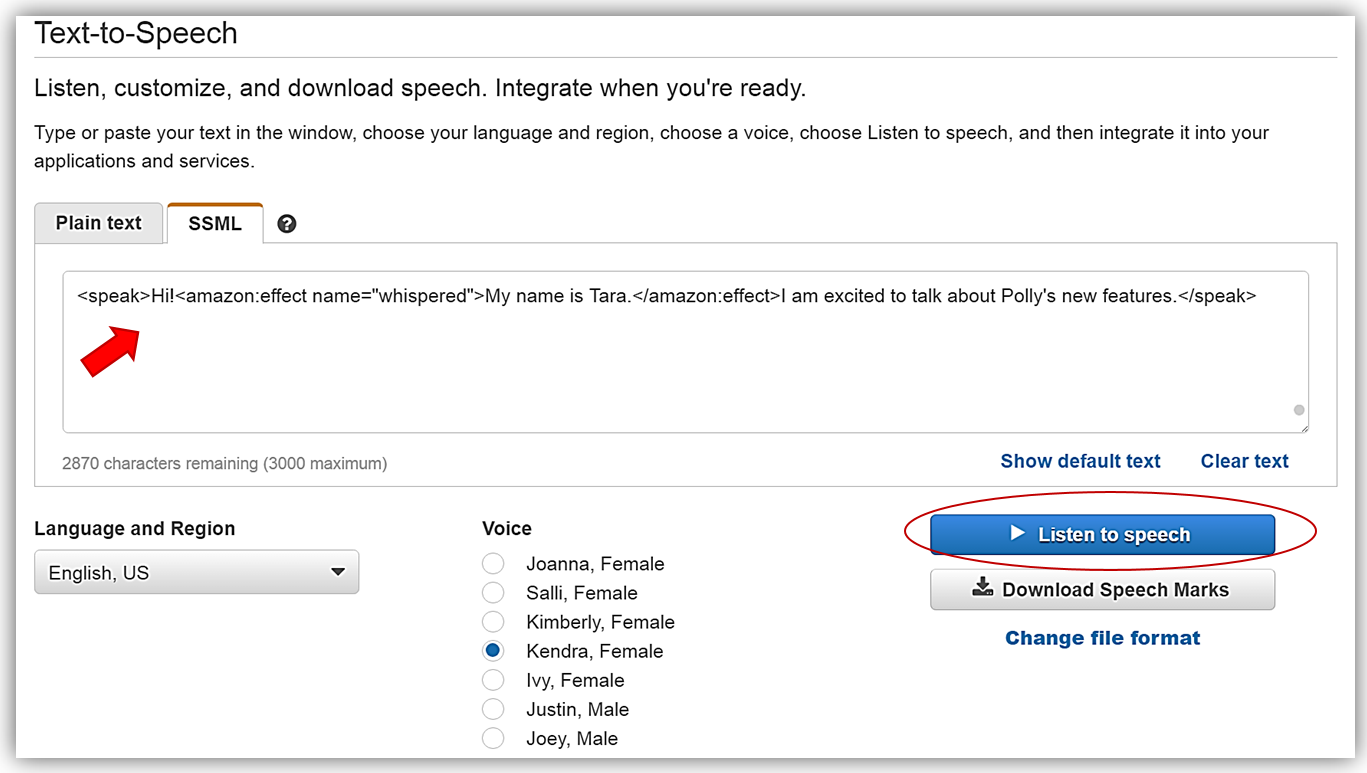
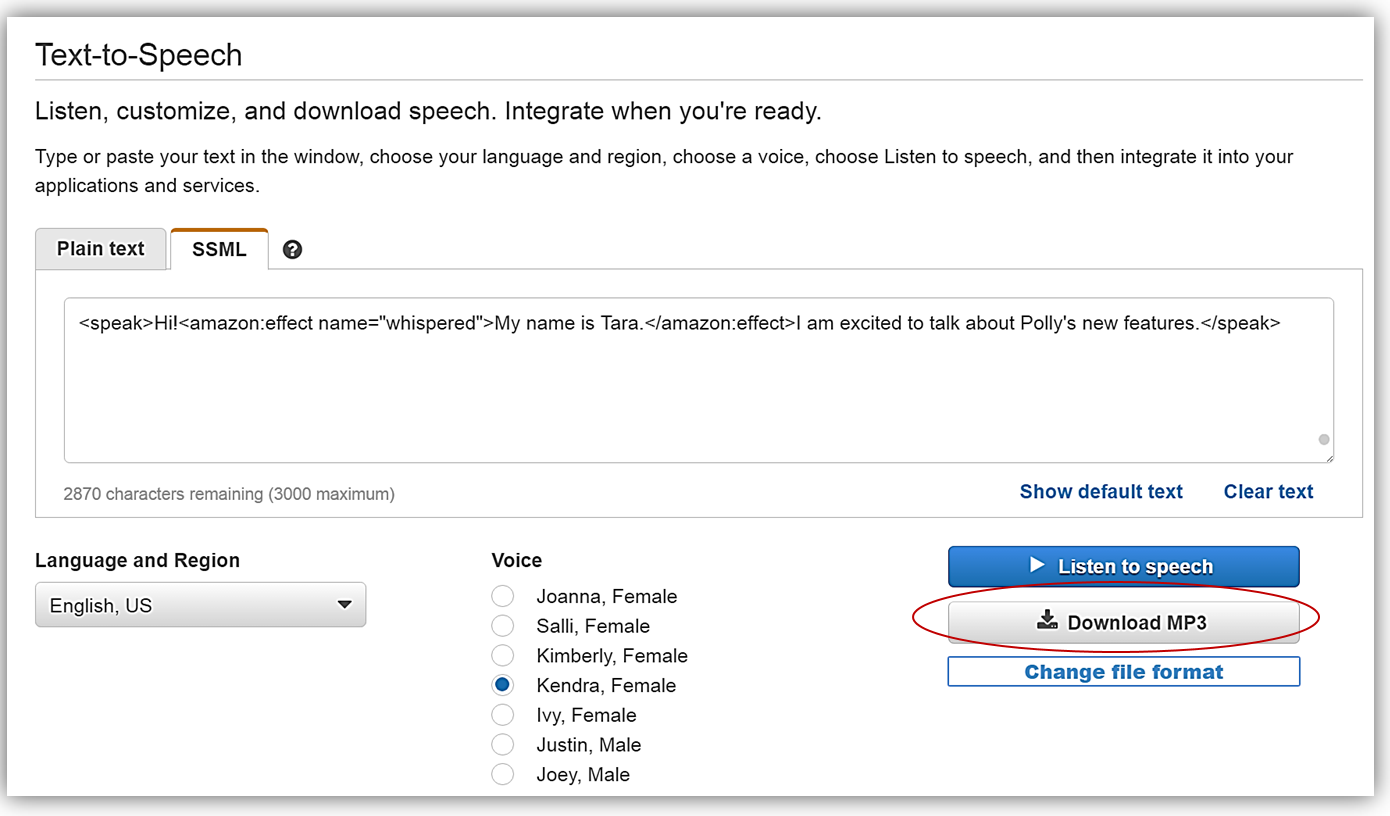
I’ll return to the Amazon Polly console and in the text box change my current text to use the new whispered voice feature for the sentence, “My name is Tara”. To accomplish this I will use the following SSML element: <amazon:effect name=”whispered”>. Therefore, the final sentence with SSML marks I entered into the text box looks as follows:
<speak>Hi!<amazon:effect name="whispered">My name is Tara.</amazon:effect>I am excited to talk about Polly's new features.</speak>
When I click the Listen to speech button, I will hear that the sentence, “My name is Tara” is indeed spoken in a whispered voice.
I want to download my speech output, so I will click the Change file format link. When the Change file format dialog box comes up, I will select the MP3 option under File format section then click the Change button.
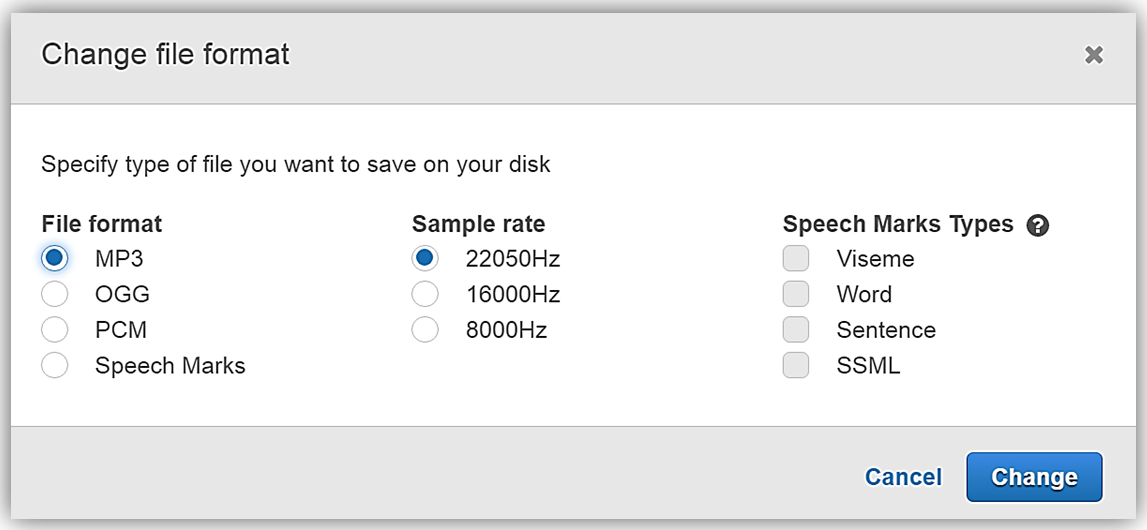
Now I have the option to download my file by clicking the Download MP3 button.
You can hear my speech output using the new whispered voice by clicking here.
Summary
The Speech Marks and Whispering features are available in Amazon Polly starting today. To learn more about these and other features visit the Amazon Polly developer guide found here: http://docs.aws.amazon.com/polly/latest/dg
For more information about Amazon Polly, visit the Amazon Polly product page or get started by converting your text to speech in the Amazon Polly console.
You should give your text the gift of voice with Amazon Polly today.
– Tara