Amazon Web Services ブログ
Apache MXNet リリースに追加された新しい NVIDIA Volta GPU と Sparse Tensor のサポート
Apache MXNet バージョン 0.12 が利用可能になりました。MXNet コミュニティに参加している貢献者の方々との協力により、強化点を追加する新機能の提供を実現することができました。今回のリリースでは、MXNet に 2 つの重要な機能が追加されています。
- NVIDIA Volta GPU のサポートにより、ユーザーはトレーニングやニューラルネットワークモデルの推論に掛かる時間を大幅に削減することができます。
- Sparse Tensor のサポートにより、ユーザーは保存とコンピューティングを効率的にした方法で Sparse マトリックスを使用しモデルをトレーニングすることができます。
NVIDIA Volta GPU サポートのアーキテクチャ
MXNet v0.12 リリースには NVIDIA Volta V100 GPU サポートが追加されています。これにより、ユーザーは畳み込みニューラルネットワークのトレーニングを Pascal GPU に比べて 3.5 倍も速くすることができます。ニューラルネットワークのトレーニングには、数兆にもなる浮動小数点 (FP) 倍数や追加が関係しています。通常、こうした計算には高精度にするため単精度浮動小数点 (FP32) が使われます。けれども、最近の研究結果によると、ユーザーがトレーニングで浮動小数点を半精度 (FP16) にしたデータタイプを使用しても、FP32 データタイプを使用したトレーニングと同じ精度を実現できることが分かっています。
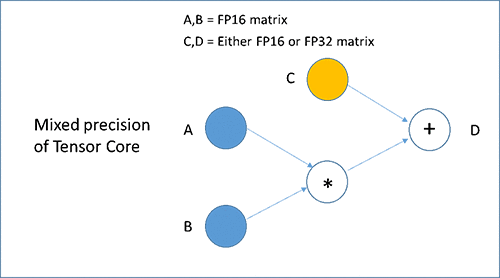
Volta GPU アーキテクチャが Tensor Core を導入しました。各 Tensor Core は 1 時間ごとに 64 fuse-multiply-add ops を実行することができます。これは 1 時間ごとの各コアにおいて CUDA コア FLOPS を 4 倍速にした状態です。Tensor Core は下記で表示したように、それぞれ D = A x B + C を実行します。この場合、A と B は半精度マトリックスで C と D は半精度または単精度マトリックスであるため、様々な精度のトレーニングを実行していることになります。新しい様々な精度のトレーニングにより、ユーザーはネットワークのほぼすべてのレイヤーで FP16 を使用、そして必要な時だけより高い精度のデータタイプを使用することで、精密性を妥協することなく最適なトレーニングパフォーマンスを実現することができます。
MXNet を使用することで、ユーザーは FP16 を利用してモデルをトレーニングし、Volta Tensor Core を活用できます。たとえば、次のコマンドオプションを train_imagenet.py スクリプトでパスすれば、MXNet で FP16 トレーニングを有効にすることができます。
先日、AWS Deep Learning AMI の新しいセットをリリースしました。これは、Amazon EC2 P3 インスタンスファミリーの NVIDIA Volta V100 GPU に最適化した MXNet v0.12 を含む様々なディープラーニングフレームワークを備えた状態でプリインストールされています。AWS Marketplace にてクリック 1 回で開始またはステップバイステップガイドを使用して、最初のノートブックを始めることができます。
Sparse Tensor のサポート
MXNet v0.12 は Sparse Tensor をサポートすることで、大方の要素がゼロである Tensor を効率的に保存しコンピューティングできるようにします。Amazon で過去の購入履歴をもとにお勧めのアイテムが紹介されたり、Netflix で過去に再生または評価した作品をもとに好みに合いそうな映画や番組が勧められたりするシステムには馴染みのある方も多いと思います。このように何百万人ものユーザーを対象にディープラーニングを基盤にした推奨エンジンには、大方の要素がゼロである Sparse マトリックスの乗算や追加が関与しています。こうした操作と同じ様に数兆を超える数のマトリックスを高密度なマトリックス間で実行することは、ストレージやコンピューティングにおいて効率的ではありません。デフォルトの高密度構造において Sparse マトリックスを多数のゼロ要素で保存したり操作すると、結果としてメモリを無駄にしたりゼロにおける不要な処理を行うことになります。
こうした面倒な点に取り組むため、MXNet は MXNet ユーザーが効率的に行う保存とコンピューティングで Sparse マトリックス操作を行ったり、ディープトレーニングモデルをより速くトレーニングできるようにする Sparse Tensor サポートを有効にしています。MXNet v0.12 は主に 2 種類のデータ形式をサポートしています。Compressed Sparse Row (CSR) と Row Sparse (RSP) です。CSR 形式は各行にゼロ以外の要素が少数しかない多数の列でマトリックスを表すように最適化されています。RSP 形式はほとんどの行スライスが完全にゼロとなっている多数の行でマトリックスを表すように最適化されています。たとえば、CSR 形式は推奨エンジンの入力データの特徴ベクトルをエンコードするために使用することができ、RSP 形式はトレーニング中での Sparse グラデーションの更新に使うことができます。このリリースは、マトリックスドットサービスや要素単位の演算子といった頻繁に使用される演算の CPU で Sparse サポートを有効にします。今後のリリースで、その他の演算子に対する Sparse サポートを追加していく予定です。
次のコードスニペットは scipy CSR マトリックスを MXNet CSR 形式に変換し、その Sparse マトリックスベクトルの乗算を 1 のベクトルで実施する方法を表しています。MXNet で新しい Sparse 演算子を使用する場合の詳細についてはチュートリアルをご覧ください。
次のステップ
MXNet の開始は簡単です。変更内容の詳細リストについてはリリースノートをご覧ください。ご不明の点またはご提案があればコメントをお寄せください。
今回のブログの投稿者について
 Sukwon Kim は AWS Deep Learning のシニアプロダクトマネージャーです。 特にオープンソースの Apache MXNet エンジンに注目し、ディープラーニングエンジンを使いやすくする製品を担当しています。余暇にはハイキングや旅行を楽しんでいます。
Sukwon Kim は AWS Deep Learning のシニアプロダクトマネージャーです。 特にオープンソースの Apache MXNet エンジンに注目し、ディープラーニングエンジンを使いやすくする製品を担当しています。余暇にはハイキングや旅行を楽しんでいます。