Amazon Web Services ブログ
MXNet モデルサーバーを使った PyTorch 推論のデプロイ
トレーニングと推論は、機械学習 (ML) 開発サイクルの重要な要素です。トレーニングの段階で、特定の問題に対処するためのモデルを教えます。このプロセスを通じて、本番稼働で使用する準備ができたバイナリモデルファイルを入手できます。
推論については、TensorFlow Serving や Model Server for Apache MXNet (MMS) など、モデルデプロイ用のフレームワーク固有のいくつかのソリューションから選択することができます。PyTorch は、PyTorch でモデルサービングを実行するためのさまざまな方法を提供します。 このブログ記事では、MMS を使用して PyTorch モデルをサーブする方法を説明します。
MMS はオープンソースのモデルサービングフレームワークであり、大規模な推論のための深層学習モデルをサーブするように設計されています。MMS は、本番稼働での ML モデルのライフサイクルを完全に管理します。MMS は、コントロールプレーンの REST ベースの API と共に、ロギングやメトリクスの生成など、本番ホストのサービスに必要な重要な機能も提供します。
以下のセクションでは、MMS を使用して PyTorch モデルを本番環境にデプロイする方法について説明します。
MMS による PyTorch モデルのサービング
MMS は、ML フレームワークに依存しないように設計されています。言い換えれば、MMS はあらゆるフレームワークのバックエンドエンジンとして機能するのに十分な柔軟性を備えています。この記事では、PyTorch で MMS を使用した、堅牢な本番稼働レベルの推論について説明します。
アーキテクチャ
次の図に示すように、MMS はモデルをモデルアーカイブの形式で使用します。
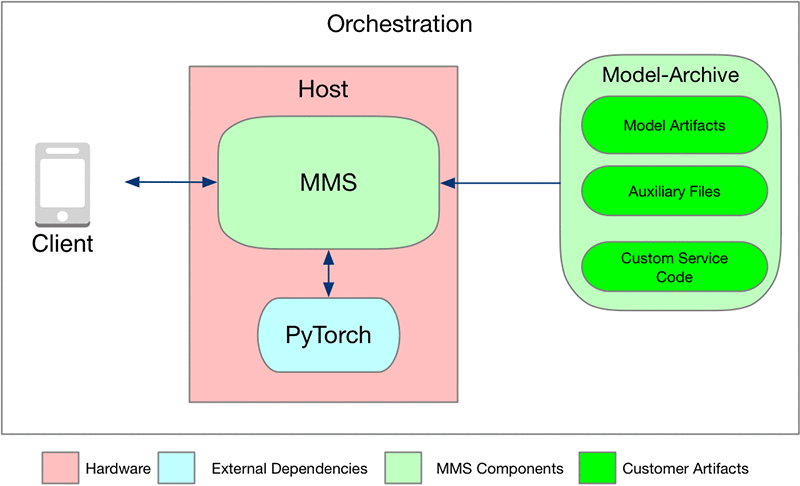
モデルアーカイブは、Amazon S3 バケットに配置することも、MMS が実行されているローカルホストに配置することもできます。モデルアーカイブには、推論を実行するためのすべてのロジックとアーティファクトが含まれています。
また、MMS では、ML フレームワークおよびその他の必要なシステムライブラリを事前にホストにインストールする必要もあります。MMS は ML フレームワークに依存しないため、ML/DL フレームワークやシステムライブラリは付属していません。MMS は、完全に設定可能です。使用可能な設定のリストについては、詳細設定を参照してください。
それでは、モデルアーカイブを詳しく見てみましょう。モデルアーカイブは、以下によって構成されています。
- カスタムサービスコード: このコードは、モデルの初期化、入ってくる未処理データのテンソルへの前処理、入力テンソルの予測出力テンソルへの変換、推論ロジックの出力の人間が読めるメッセージへの変換のメカニズムを定義します。
- モデルアーティファクト: PyTorch は、モデルやチェックポイントを保存するためのユーティリティを提供します。この例では、モデルを model.pth ファイルに保存します。このファイルは、モデル、オプティマイザ、入力、および出力シグネチャを含む、実際にトレーニングされたモデルバイナリです。モデルを保存する方法の詳細については、PyTorch モデルを参照してください。
- 補助ファイル: 推論を実行するために必要な追加のファイルおよび Python モジュールです。
これらのファイルは、MMS に付属の model-archiver というツールを使用してモデルアーカイブにバンドルされます。以下のセクションでは、このモデルアーカイブを作成してモデルサーバーで実行する方法を示します。
推論コード
このセクションでは、カスタムサービスコードの書き方をご覧ください。 この例では、PyTorch 画像分類子を使って densenet161 モデルをトレーニングしました。このリソースは、102 種の花の画像を含んでいます。
前提条件
先に進む前に、以下のリソースが必要です。
- モデルサーバーパッケージ: MMS は、現在 Python パッケージとして配布されており、DockerHub でホストされている事前作成済みのコンテナもあります。この記事では、Python パッケージを使って PyTorch モデルをホストしています。次のコマンドを実行することで、MMS を簡単にホストにインストールすることができます。
- モデルアーカイバ: このツールは、mxnet-model-server パッケージのインストールに付属しています。次のコマンドを実行して、これをインストールすることもできます。
推論コードの作成
MMS は、最小限のコーディングでフォローおよび拡張が可能な有用な推論テンプレートを提供します。ここでは、初期化、前処理、推論のためにテンプレートメソッドを拡張します。この拡張には、モデルの初期化、テンソルへの入力データ変換、モデルへの順方向パスがそれぞれ含まれます。 詳細については、MMS リポジトリのサンプルモデルテンプレートを参照してください。以下は、初期化、前処理、推論のためのコードの例です。
preprocess 関数では、画像を変換する必要があります。
次に、inference 関数ではテンソルを取り、モデルへのフォワードパスを行います。また、花の種類の上位 5 つの可能性も入手できます。
カスタムサービスコードの詳細については、MMS GitHub リポジトリにある PyTorch densenet の例の densenet_service.py を参照してください。
モデルアーカイブの作成
これで推論コードとトレーニング済みモデルが完成したので、MMS model-archiver を使用してそれらをモデルアーカイブにパッケージ化できます。 すべてのコード部分とアーティファクトは、/tmp/model-store に集められています。
このモデルのモデルアーカイブを作成し、S3 バケットで公開しました。そのファイルをダウンロードして、推論に使用することができます。
モデルをテストする
これで、トレーニング済みモデルと推論コードをモデルアーカイブにパッケージ化したので、このアーティファクトを MMS と一緒に使用して推論を行うことができます。このアーティファクトは既に作成されており、S3 バケットにあります。以下の例で、これを使用します。
このバイナリは、densenet161_pytorch.mar モデルをホストする densenet というエンドポイントを作成します。これでサーバーはリクエストを処理する準備が整いました。
ここで、花の画像をダウンロードし、MMS に送信して、花の品種を識別する推論結果を取得します。

そして、推論を実行します。
結論
この記事では、MMS 推論サーバーで PyTorch によってトレーニングしたモデルをホストする方法を説明しました。GPU ホストで推論サーバーをホストするには、モデルを GPU にスケジュールするように MMS を設定します。詳細については、awslabs/mxnet-model-server に進んでください。
著者について
 Gautam Kumar は、AWS AI Deep Learning のソフトウェアエンジニアです。彼は、AWS Deep Learning Containers と AWS Deep Learning AMI を開発しました。彼は、AI のためのツールやシステムを構築することに熱意を持っています。余暇には、自転車に乗ることや読書を楽しんでいます。
Gautam Kumar は、AWS AI Deep Learning のソフトウェアエンジニアです。彼は、AWS Deep Learning Containers と AWS Deep Learning AMI を開発しました。彼は、AI のためのツールやシステムを構築することに熱意を持っています。余暇には、自転車に乗ることや読書を楽しんでいます。
 Vamshidhar Dantu は、AWS Deep Learning のソフトウェア開発者です。 スケーラブルかつデプロイの容易な深層学習システムの構築に注力しています。余暇には、家族との時間やバドミントンを楽しんでいます。
Vamshidhar Dantu は、AWS Deep Learning のソフトウェア開発者です。 スケーラブルかつデプロイの容易な深層学習システムの構築に注力しています。余暇には、家族との時間やバドミントンを楽しんでいます。