Amazon Web Services ブログ
Amazon SageMaker の因数分解機械アルゴリズムを拡張し、レコメンデーション上位 x 件を予測しています。
Amazon SageMaker により、機械学習ワークロードで複雑なビジネス上の問題に対応するために必要な柔軟性が向上します。組み込みアルゴリズムを使用すると、すぐに開始できます。 このブログ記事では、組み込みの因数分解機アルゴリズムを拡張してレコメンデーション上位 x 件を予測する方法について、概説します。
この手法は、ユーザーに対し一定数のレコメンデーションをバッチ処理で生成する場合に最適です。例えば、この手法を使用して、ユーザーと製品購入に関する大量の情報から、あるユーザーが購入しそうな上位 20 製品を生成することができます。その後、将来的にダッシュボードへの表示やパーソナライズメールマーケティングなどで利用するため、このレコメンデーションをデータベースに保存できます。AWS Batch または AWS Step Functions を使用して、このブログで概説する手順を自動化し、定期的な再トレーニングや予測を行うこともできます。
因数分解機は、汎用教師あり学習アルゴリズムで、分類と回帰の両方のタスクに使用できます。このアルゴリズムは、レコメンデーションシステムのエンジンとして設計されました。このアルゴリズムでは、二次係数を低ランク構造に制限しながら、特徴について二次関数を学習することで協調フィルタリング手法を拡張します。この制限は、過学習を避け、また非常にスケーラブルであるため、大きな疎データによく適してします。これにより、入力特徴が何百万である一般的なレコメンデーションの問題に対するパラメーターが、何兆とあるのではなく、何百万となるようにします。
因数分解機のモデル方程式は、つぎのように定義されます。
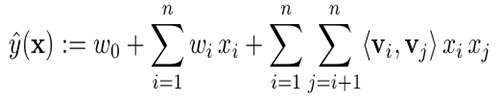
次のようなモデルパラメータが推定されます。
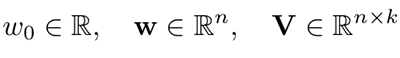
ここでは、n は入力サイズ、k は潜在空間のサイズです。これらの推定されるモデルパラメータを使用して、モデルを拡張します。
モデルの拡張
Amazon SageMaker の因数分解機アルゴリズムを使うことにより、ユーザーと項目のようなペアについて、これらが合致する程度に基づき、そのペアのスコアを予測できます。レコメンデーションモデルの適用時、ユーザーを入力すると、そのユーザーの好みに合致する上位 x 件の項目リストを返すようにしたい場合がよくあります。アイテム数が多くなければ、可能性のあるアイテムすべてに対しユーザーと項目のモデルをクエリすることができます。ただし、この手法では項目数が多くなるとうまくスケールできません。このシナリオでは、Amazon SageMaker k 近傍法 (k-NN) アルゴリズムを使用して、上位 x 件の予測タスクを高速化できます。
以下の図は、このブログ記事で扱う手順のおおまかな概要を示しています。これには、因数分解機モデルの構築、モデルデータの再パッケージ化、k-NN モデルのフィッティング、および上位 x 件予測の作成が含まれます。

先に進めるため、手引きとなる Jupyter ノートブック をダウンロードすることもできます。以下の各セクションは、このノートブックのセクションと対応していますので、読みながら各ステップのコードを実行できます。
ステップ 1: 因数分解機モデルの構築
手引きとなる Jupyter ノートブックのパート 1 で、因数分解機モデルの構築手順を確認します。因数分解機モデルの構築に関する詳細は、因数分解機アルゴリズムのドキュメントを参照してください。
ステップ 2: モデルデータの再パッケージ化
Amazon SageMaker 因数分解機アルゴリズムでは、Apache MXNet 深層学習フレームワークを活用します。このセクションでは、MXNet を使用してモデルデータを再パッケージ化する方法を扱います。
因数分解機モデルの抽出
まず、因数分解モデルをダウンロードしてから、解凍し、MXNet オブジェクトを作成します。MXNet オブジェクトの主要目的は、モデルデータの抽出です。
モデルデータの抽出
因数分解機モデルには、ベクトルのリスト xu + xi を入力します。これは、映画のユーザー評価など、ラベルで結びつけられたユーザー u と項目 i を表します。結果として生じる入力行列には、ユーザー、項目、ならびに追加する必要があるその他の特徴についての、ホットエンコードされた疎な値が含まれます。
因数分解機モデルの出力は、3 つの n 次元配列で構成されます。
- V – (N x k) 行列であり、ここでは
- k は潜在空間のディメンション
- N はユーザーと項目の総数
- w – N 次元ベクトル
- b – 単一の数字: バイアス項
下記のステップを完了して、MXNet オブジェクトの出力するモデルを抽出します。
k-NN モデルを構築するためのデータの準備
因数分解機モデルから抽出したモデルデータを再パッケージ化して、k-NN モデルを構築できるようになりました。このプロセスでは、次の 2 つのデータセットを作成します。
- 項目潜在行列 – k-NN モデルの構築用
- ユーザー潜在行列 – 推論用
ステップ 3: k-NN モデルの適合
Amazon SageMaker で k-NN モデルを使用できるように、k-NN モデルの入力データの Amazon S3 へのアップロード、k-NN モデルの作成、保存が可能になりました。また、このモデルは、以降のステップで説明するとおり、バッチ変換を呼び出すのに役に立ちます。
k-NN モデルはデフォルトの index_type (faiss.Flat) を使用します。 このモデルは正確ですが、大量のデータセットの場合は遅くなる可能性があります。そのような場合には、異なる index_type パラメータを近似のより速い応答に使用してもかまいません。インデックスタイプの詳細については、k-NN documentation またはこの Amazon Sagemaker Examples notebook のどらかを参照してください。
ステップ 4: すべてのユーザーに対してレコメンデーション上位 x 件の予測
Amazon SageMaker のバッチ変換機能により、大規模なバッチ予測が可能です。この例として、ユーザー推定の入力データを Amazon S3 にアップロードすることから始めます。それから、バッチ変換をトリガーします。
出力されたファイルにはすべてのユーザーに対する予測が記載されています。出力ファイルの各行の項目は JSON 行で、特定ユーザーの ID と距離が記載されています。
以下はユーザーの出力例です。推奨映画の ID をさらに活用するためにデータベースに保存できます。
複数の機能とカテゴリのシナリオ
このブログのフレームワークは、ユーザーと項目 ID を使用したシナリオに適用されます。ただし、データには、ユーザーや項目の機能など、追加の情報が含まれる可能性があります。たとえば、ユーザーの年齢、郵便番号、性別が分かっているかもしれません。項目については、カテゴリ、映画ジャンル、テキストの説明にある重要なキーワードが分かっているかもしれません。これらの複数の機能とカテゴリシナリオでは、以下を使用して、ユーザーと項目ベクターを抽出します。
- ユーザーとユーザー機能を使用して xi をエンコード:
ai =concat(VT · xi , wT · xi) - 項目と項目機能を使用して xu をエンコード:
au =concat(VT · xu, 1)
それから、ai を使用して、推定するために k-NN モデルと au を構築します。
結論
Amazon SageMaker は開発者とデータサイエンティストに機械学習モデルを迅速に構築、トレーニング、デプロイするための柔軟性を与えます。上記のフレームワークを使用することで、バッチ方式でユーザーに対してレコメンデーション上位 x 件を予測するための推奨システムを構築でき、データベースに出力をキャッシュできます。場合によっては、予測に対してさらにフィルタリングをする必要があるかもしれません。つまり、ユーザー応答に基づいていくつかの予測を随時フィルターをし、取り除く必要がある場合があります。このフレームワークは柔軟性が十分高いので、そのようなユースケースに合わせて修正もできます。
著者について
 Zohar Karnin は Amazon AI の主任科学者です。彼の対象とする研究分野は、大規模なオンライン機械学習アルゴリズムです。彼は Amazon SageMaker 用に無制限に拡張可能な機械学習アルゴリズムを開発しています。
Zohar Karnin は Amazon AI の主任科学者です。彼の対象とする研究分野は、大規模なオンライン機械学習アルゴリズムです。彼は Amazon SageMaker 用に無制限に拡張可能な機械学習アルゴリズムを開発しています。
 Rama Thamman はシニアソリューションアーキテクトで、戦略的アカウントチームの一員です。彼は顧客と協業して、スケーラブルなクラウドと AWS ついての機械学習ソリューションを構築しています。
Rama Thamman はシニアソリューションアーキテクトで、戦略的アカウントチームの一員です。彼は顧客と協業して、スケーラブルなクラウドと AWS ついての機械学習ソリューションを構築しています。