Amazon Web Services ブログ
Amazon SageMaker に組み込みの物体検出アルゴリズムと AWS DeepLens を使用してエッジで鳥の種を識別する
カスタムの物体検出は、MRI での腫瘍の発見、病気に罹った農作物の特定、鉄道駅ホームの監視など、さまざまな産業やユースケースにとって重要な要素となっています。このブログ記事では、アノテーションが付けられた公開データセットに基づいて鳥を識別します。このタイプのモデルは、さまざまな方法で使用できます。建設プロジェクトの環境調査の自動化で使用したり、バードウォッチングの時に鳥愛好家が使用したりすることができます。また、このモデルを実用的な例として利用し、独自のユースケースの新しいアイデアを生み出すこともできます。
この例では、Amazon SageMaker が提供している組み込みの物体検出アルゴリズムを使用します。Amazon SageMaker は、エンドツーエンドの機械学習 (ML) プラットフォームです。組み込みアルゴリズムを使用することで、開発者は TensorFlow や MXNet などの低レベルの ML フレームワークの使用に関する専門知識を必要とせずに機械学習を加速させることができます。モデルは、Amazon SageMaker の完全に管理されたオンデマンドトレーニングインフラストラクチャでトレーニングします。AWS IoT Greengrass を使用すると、トレーニング済みモデルをクラウドまたはエッジで簡単にホストすることができます。
カスタムの物体検出をエッジで使用する方法を示すために、トレーニング済みモデルを開発者向けの世界初の深層学習対応ビデオカメラである AWS DeepLens にデプロイする方法も示します。AWS DeepLens により、開発者は文字どおり完全にプログラム可能なビデオカメラ、チュートリアル、コード、および深層学習スキルを向上させるよう設計された事前トレーニング済みのモデルを使って深層学習を利用できます。
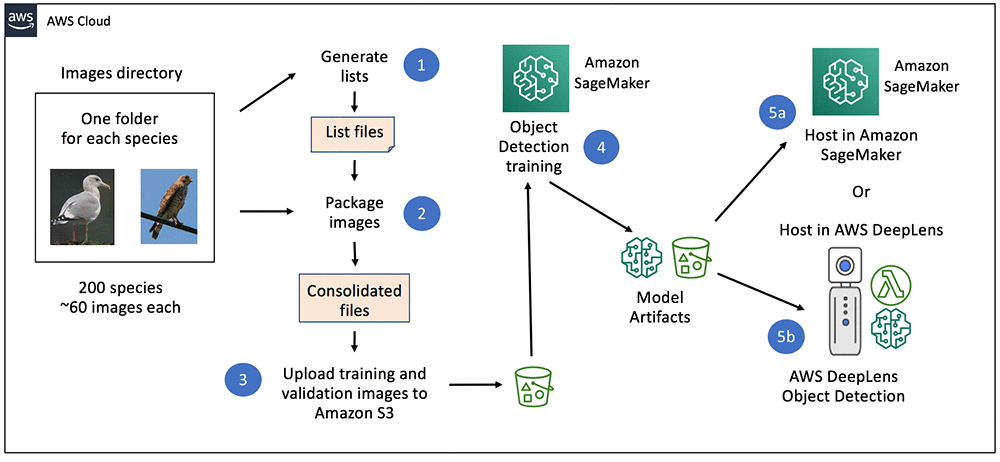
次の図は、鳥の識別ソリューションの構築方法の概要を示しています。
データセットの理解
CUB 200-2011 鳥類データセットには、200 種の鳥の種にわたる 11,788 枚の画像が含まれています。それぞれの種には約 60 枚の画像が付属しており、一般的なサイズは約 350 ピクセル × 500 ピクセルです。鳥の部分のアノテーションとして、バウンディングボックスが提供されています。推奨されるトレーニング/テストの分割は与えられますが、画像サイズデータは与えられていません。

画像データセットの準備
Amazon SageMaker の物体検出アルゴリズムに画像データを提供する最も効率的な方法は、RecordIO 形式を使用することです。MXNet には、データセット用の RecordIO ファイルを作成するための im2rec.py というツールがあります。このツールを使用するには、一連の画像を記述するリストファイルを用意します。
物体検出データセットでは、Amazon SageMaker は、バウンディングボックスを、フル画像に対するボックスのコーナーの比率である xmin、ymin、xmax、ymax で記述する必要があります。CUB データセットのバウンディングボックスは、代わりに x、y、ピクセル単位で表した幅、高さを指定します。次の図を参照して、メタデータの違いを理解してください。
この食い違いに対処するために、各画像のサイズを取得し、絶対バウンディングボックスを変換して画像サイズを基準とした寸法を設定します。次の例で、データセットのボックス寸法は黒色で表示され、RecordIO に必要な寸法は緑色で表示されています。

次の Python コードスニペットは、元のバウンディングボックスの寸法を im2rec で必要な寸法に変換した方法を示しています。完全なコードについては、サンプルの Amazon SageMaker ノートブックを参照してください。
リストファイルを作成すると、次のコマンドを実行することで、im2rec ユーティリティを使用して RecordIO ファイルを作成することができます。
RecordIO ファイルは、作成された後、以下の Python コードを使用して、物体検出アルゴリズムへの入力として Amazon S3 にアップロードされます。
Amazon SageMaker の組み込みアルゴリズムを使用した物体検出モデルのトレーニング
Amazon S3 で画像が利用可能になったので、次の手順はモデルをトレーニングすることです。物体検出ハイパーパラメータのドキュメントはこちらから入手できます。この例では、いくつか興味深いハイパーパラメータがあります。
- クラスの数とトレーニングサンプル。
- バッチサイズ、エポック、画像サイズ、事前トレーニング済みモデル、およびベースネットワーク。
Amazon SageMaker の物体検出アルゴリズムでは、モデルを ml.p3.2xlarge などの GPU インスタンスタイプでトレーニングする必要があります。以下は、Estimator を作成し、ハイパーパラメータを設定するための Python コードスニペットです。
データセットをアップロードし、ハイパーパラメータを設定すると、以下の Python コードを使用してトレーニングを開始することができます。
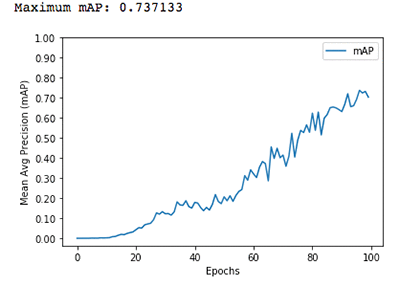
ml.p3.2xlarge インスタンスタイプでの 5 つの種のサブセットの場合、約 11 分で 100 エポックについて 70 パーセント以上の精度を得ることができます。
AWS CLI、ノートブック、または Amazon SageMaker コンソールを使用してトレーニングジョブを作成できます。
Amazon SageMaker エンドポイントを使用してモデルをホストする
モデルのトレーニングが終わったら、Amazon SageMaker でホストします。CPU インスタンスを使用しますが、GPU インスタンスを使用することもできます。Amazon SageMaker ノートブックからのデプロイには、次の 1 行の Python コードが必要です。
モデルをテストする
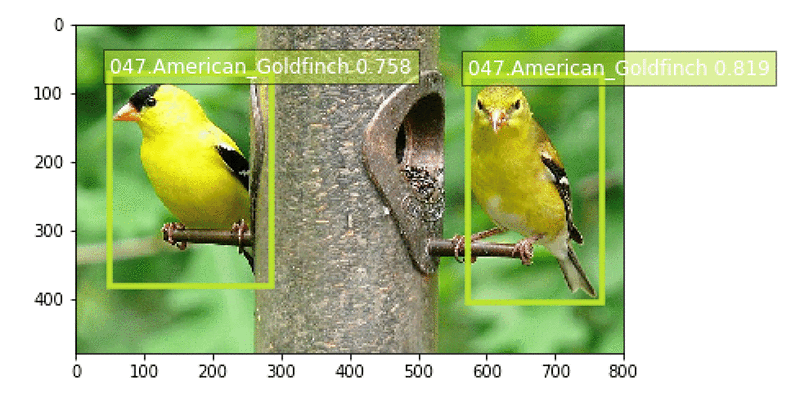
モデルのエンドポイントが使用可能になった後、モデルがまだ表示していない画像を渡して、鳥がどれほどよく検出されているかを確認できます。visualize_detections 関数については、サンプルのノートブックを参照してください。鳥の画像への URL が指定された場合、エンドポイントを起動し、予測された鳥の種とそれらのバウンディングボックスのセットを取得し、結果を視覚化する Python コードは以下のとおりです。
以下は、アオカケスの画像のサンプル結果です。

AWS DeepLens を使用してモデルをエッジで実行する
ユースケースによっては、Amazon SageMaker がホストするエンドポイントで十分な展開メカニズムとなるでしょうが、エッジでリアルタイムの物体検出を必要とするユースケースも数多くあります。鳥類保護区にある電話ベースのアシスタントアプリを想像してみてください。保護区を歩き回って、アプリを鳥に向けると即座にその種についての詳細が得られます (その鳥の鳴き声を聞く、生息地を理解するなど)。今、見た鳥を推測する必要はもうありません。
AWS DeepLens を使用すると、深層学習をエッジで試すことができ、開発者はトレーニングしたモデルを簡単にデプロイし、Python コードを使用して興味深いアプリケーションを思いつくことができます。この例の鳥の識別については、鳥の餌箱を見下ろすキッチンの窓の横に AWS DeepLens デバイスを取り付けることができます。このデバイスは、検出した鳥のトリミング画像を Amazon S3 に送信することができます。あなたの携帯電話へテキストを送って、どんな鳥が訪れたかを知らせることさえできます。
前回のブログ記事では、AWS DeepLens でカスタム画像分類モデルをデプロイする方法について説明しました。カスタムの物体検出モデルには、2 つの違いがあります。
- モデルのアーティファクトは、デプロイする前に変換する必要があります。
- モデルは、ロードする前に最適化されなければなりません。
それでは、これらの違いのそれぞれについてもっと詳しく見てみましょう。
AWS DeepLens にデプロイする前にモデルのアーティファクトを変換する
Amazon SageMaker によって作成されたカスタムの物体検出モデルの場合、モデルを AWS DeepLens にデプロイする場合は追加の手順を実行する必要があります。MXNet は、モデルを変換するためのユーティリティ機能を提供しています。変換を始めるには、まず GitHub リポジトリを複製します。
次の手順は、トレーニングの結果として Amazon S3 に保存されたモデルのアーティファクトのコピーをダウンロードすることです。実際のアーティファクト (パラメータファイル、シンボルファイル、ハイパーパラメータファイル) を抽出し、トレーニングで使用された基本ネットワークおよび画像サイズを反映するようにそれらの名前を変更します。以下は、変換を実行するために使用できる bash スクリプトのコマンドです。
内容を抽出して名前を変更したら、変換ユーティリティを起動します。
これで、元のファイルを削除し、変換したアーティファクトを含む新しい圧縮 tar ファイルを作成することができます。 新しい AWS DeepLens 物体検出モデルをインポートするときに使用できる、新しいモデルのアーティファクトのファイルを Amazon S3 にコピーします。
パッチを適用したモデルの保存先バケットでは、バケット名に「deepplens」という単語が含まれている必要があります。そうでないと、AWS DeepLensコンソールでモデルをインポートするときにエラーが発生します。モデルのアーティファクトにパッチを適用するための完全なスクリプトは、こちらにあります。
AWS DeepLens で AWS Lambda 関数からモデルを最適化する
AWS DeepLens プロジェクトは、トレーニングを受けたモデルと AWS Lambda 関数で構成されています。AWS DeepLens で AWS IoT Greengrass を使用して、推論 Lambda 関数は次の 3 つの重要な機能を実行します。
- ビデオストリームから画像をキャプチャする。
- デプロイされた機械学習モデルに対して、画像を使用して推論を実行する。
- 結果を、AWS IoT と出力ビデオストリームの両方に提供する。
AWS IoT Greengrass を使用すると、AWS Lambda 関数をローカルで実行し、埋め込みソフトウェアの開発の複雑さを軽減できます。推論 Lambda 関数の作成と公開の詳細については、こちらのドキュメントを参照してください。
Amazon SageMaker によって作成されたカスタムの物体検出モデルを使用する場合、AWS DeepLens 推論 Lambda 関数に追加の手順があります。推論関数は、モデルを使用して推論を実行する前に MXNet のモデルオプティマイザを呼び出す必要があります。以下は、モデルを最適化して読み込むための Python コードです。
AWS DeepLens でモデル推論を実行する
AWS Lambda 関数からのモデル推論は、Amazon SageMaker がホストするエンドポイントを使用してモデルを呼び出すための前述した手順と非常によく似ています。以下は、AWS DeepLens ビデオカメラが提供するフレーム内で鳥を見つける Python コードの一部です。
この物体検出モデルによって AWS DeepLens で使用するための完全な推論 Lambda 関数は、ここにあります。
結論
このブログ記事では、Amazon SageMaker の組み込み物体検出アルゴリズムを使用して、一般に利用可能なデータセットに基づいて鳥類を検出するカスタムモデルを作成する方法を説明しました。また、AWS DeepLens を使用して、ホストされている Amazon SageMaker エンドポイントおよびエッジでそのモデルを実行する方法についても説明しました。この例を複製して、独自のユースケースに合わせて拡張することができます。新しい方法でこのコードをどのように適用できるかについて、皆さんのご意見をお聞きしたいです。コメントを追加することで、ぜひフィードバックをお知らせください。
著者について
 Mark Roy は、機械学習を専門とするソリューションアーキテクトであり、顧客やパートナーがコンピュータビジョンソリューションを設計するのを支援することに特に関心を持っています。 余暇には、Mark はバスケットボールのプレー、コーチ、フォローするのが好きです。
Mark Roy は、機械学習を専門とするソリューションアーキテクトであり、顧客やパートナーがコンピュータビジョンソリューションを設計するのを支援することに特に関心を持っています。 余暇には、Mark はバスケットボールのプレー、コーチ、フォローするのが好きです。