Amazon Web Services ブログ
AWS Lake Formation FindMatches を使用してデータセットの統合および重複の削除を実施
AWS Lake Formation FindMatches は新しい機械学習 (ML、machine learning) 変換で、人間がほとんど、あるいはまったく介入することなく、さまざまなデータセットにわたってレコードを一致させたり、重複レコードを特定および削除したりできます。FindMatches は Lake Formation に含まれている、いくつかの簡単な手順を踏むだけでセキュアなデータレイクを構築できる新しい AWS のサービスです。
FindMatches を使用するのに、コードを書く必要も ML の仕組みを知っている必要もありません。また、データに一意の識別子が含まれている必要はなく、フィールドが完全に一致している必要もありません。
以下に、FindMatches で実現できることを挙げます。
- 顧客の一致: フィールドが完全に一致していない (名前のスペルが異なる、住所が異なる、データが欠損している、データが正確でないなどの理由による) 場合でも、さまざまなデータセットにわたって顧客レコードをリンクおよび統合できます。
- 製品の一致: さまざまなベンダーカタログおよび SKU にわたって製品を一致させることができます。レコードが共通の構造を共有していない場合でも可能です。
- 不正防止: 既知の不正アカウントと比較することで、不正のおそれがあるアカウントを特定できます。
- その他データの一致: 住所、動画、部品リストなどを一致させることができます。通常、人間がデータベースの行を確認してそれらが一致すると判断できる場合、FindMatches が役に立ちます。
この記事では、FindMatches ML 変換を使用して、DBLP と Scholar という各学術刊行物サービスからの 2 つのリストで構成された学術データセットの一致レコードを特定する方法を紹介します。 このデータセットは、“Evaluation of entity resolution approaches on real-world match problems” (Köpcke, H., Thor, A., Rahm, E.) で言及されている DBLP-Scholar Dataset に基づいています。この論文は、Creative Commons Attribution 4.0 International License の下でライセンスを付与されています。
今回、DBLP と Scholar のデータセットを単一ファイルに結合して各レコードのソースを示す列を追加し、FindMatches と互換性のある形式のラベルファイル (“perfect mapping”) を用意しました。
概要
次に示す DBLP と Scholar のサンプルデータで、その構造を確認していきます。DBLP のデータには 2,616 のレコードがあり、次のテーブルのような構造を持っています。

Scholar のデータには 64,263 のレコードがあります。構造は似ていますが、データはこちらの方がより乱雑です。たとえば、エントリがなかったり、値が不正確だったり (タイトルフィールドに住所が載っているなど)、予期しない文字が含まれていたりするのが確認できます。
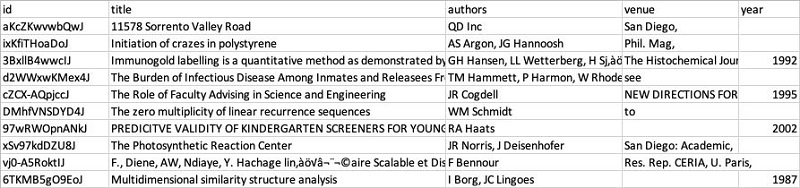
ご覧のとおり、DBLP と Scholar のリストには、似ていて部分的に一致するデータが含まれているものの、共通の識別子を共有してはいません。また、刊行物のタイトル、著者、発表地、発表年は必ずしも一致していません。データの統合は困難で時間がかかるおそれがありますが、FindMatches を使用すれば簡単です。これからその方法を見ていきましょう。
まず、データを FindMatches で使用できる形式に変換します。このツールの対象は単一のテーブルにあるデータです。各レコードの元のデータセットを特定できるよう、2 つのリストを単一テーブルに結合して、“source” 列を追加します。互換性の問題を回避するため、“id” フィールドの “/” 記号をすべて “_” に置換してテーブルを JSON に変換します。そうして使用可能になった入力ファイルは、次の場所から入手可能です。
s3://ml-transforms-public-datasets-us-east-1/dblp-scholar/records/dblp_scholar_records.jsonl
このチュートリアルを “us-east-1” 以外のリージョンで実践している場合、記事内の URL の “us-east-1” をお使いのリージョンに置き換えてください。

FindMatches ML 変換の使用手順に入る前に、その最終的な結果として次の表をお見せしておきます。データセットを一致させると、結果のテーブルには入力テーブルの構造とデータが反映され、match_id 列が追加されます。一致レコードには同じ match_id 値が表示されます。

チュートリアル
このセクションでは、一致プロセス全体を始めから終わりまで詳しく解説していきます。一致プロセスは大まかに次のステップに分けられます。
- AWS Glue データカタログでデータをカタログ化します。
- 自分のデータ用に新しい FindMatches ML 変換を作成します。
- 一致レコードおよび不一致レコードのラベル付け例を示して FindMatches に学習させます。
- 一致品質のメトリクスを確認し、一致品質がまだ十分でなければラベルを追加アップロードします。
- FindMatches 変換を使用する AWS Glue ETL ジョブを作成します。
- 出力を確認します。
AWS Glue クローラを使用してデータをカタログ化する
FindMatches は AWS Glue データカタログで定義されたテーブルで動作します。AWS Glue クローラを使用してデータを検出およびカタログ化します。 クローラを使用して AWS Glue データカタログにテーブルを追加する方法については、クローラの使用方法のドキュメントを参照してください。
FindMatches が一致において使用するのは、数字、文字列、文字列配列の列のみです。日付または構造体など、それ以外のデータタイプの列は無視します。AWS Glue データカタログのテーブルに、レコードの一致を判断するのに重要と思われる、上記以外のデータタイプの列があるかもしれません。 その場合は、元の列の数字バージョンまたは文字列バージョンとなる列を新たに作成してください。
FindMatches ML 変換を作成する
- AWS Glue コンソールを開きます。次のスクリーンショットを参考にしながら、左側のナビゲーションペインの [ジョブ] から [ML Transforms] を選択して、[Add transform] を選択します。

- 次のページで、名前を入力し、AWSGlueServiceRole および AmazonS3FullAccess ポリシーを含む [IAM ロール] を選択または作成して、[次へ] を選択します。詳細については、「AWS Glue 用の IAM ロールを作成する」を参照してください。

- 次のページで、データソースとして dblp_scholar_records_jsonl を選択します。AWS Glue クローラによってデータセットが検出され、テーブルが作成されました。

- 次のページで、プライマリキーとして id を選択します。プライマリキーは一意の識別子である必要があります。これにより、ラベルファイルエントリとデータセットのレコードとの間に明白な関係が確立されます。

- [Tune transform] ページで、[Recall] と [Precision] とのバランス、および [Lower cost] と [Accuracy] とのバランスを調整します。
このスライダーを [Precision] (精度) 寄りに動かすと、変換が “一致” としてレコードを特定する信頼度レベルを高く設定できます。ただし、高信頼度設定を使用すると、アルゴリズム信頼度が低い実際の一致を検出できない場合があります。スライダーを [Recall] (再現率) 寄りに動かすと、一致信頼度のしきい値が緩まってより多くの実際の一致を特定できます。ただし、そうするといくつかの不一致が一致として識別される場合があります。このように、どちらの方向に動かすのにもトレードオフがあります。
ビジネスケースに応じて精度か再現率かを選んでください。たとえば、面接を行う就職希望者を特定する際には、再現率を高く設定します。そうすると一致の可能性が高まり、有望な希望者を誤って不採用にせずに済みます。そして採用決定を下す場合には、精度を高く設定します。そうすると、仕事に適していると強い確信を抱ける場合にのみ、希望者を採用できます。
[Lower Cost] 対[Accuracy] のスライダーは、変換が一致を判断するためにいくつのレコードを比較するかを制御するためのものです。データセットが大規模な場合、各レコードを他のすべてのレコードと比較するのは現実的ではありません。FindMatches は高度なアルゴリズムを使用して、一致の可能性が高いレコードのサブセットを特定し、より精密に比較します。[Accuracy] を高く設定すると、より多くのレコードを比較するために実行時間 (およびそれに伴いコスト) が増大するものの、再現率が高まります。
このチュートリアルでは、今回のデータセットで最良の結果を出すために [Recall] 対[Precision] のスライダーを 0.9 ([Precision] 寄り) に設定します。[Lower Cost] 対[Accuracy] のスライダーは、[Accuracy] 側いっぱいに設定します。必要であれば、あとで変換を選択して [Tune] メニューからこれらの値を調整することができます。

選択した設定を確認したら [完了] を選択し、変換を作成します。
ラベル付けしたデータを使用して FindMatches に学習させる
変換の作成が完了したので、一致レコードと不一致レコードを識別できるよう、変換に教えます (または ML エキスパートの表現を借りて、変換を “トレーニング” します)。この作業は、ラベル付けしたデータ、つまり一致および不一致の入力レコードのサンプルを指定して行います。
このチュートリアルでは、ラベル付けしたデータファイルとして次のファイルを使用します。
s3://ml-transforms-public-datasets-us-east-1/dblp-scholar/labels/dblp_scholar_labels_350.csv
us-east-1 以外のリージョンで FindMatches を使用している場合、ファイル URL の us-east-1 をお使いのリージョンに置き換えてください。
このファイルはすぐに使用可能な状態です。しかし、独自の一致プロジェクトでデータの準備およびラベル付けを行えるよう、ファイルの構造について少し詳しく解説しておきます。
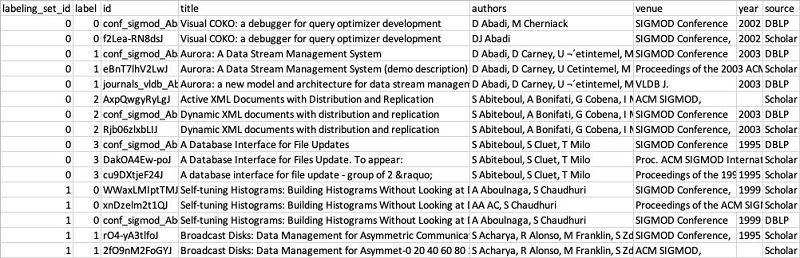
ご覧のとおり、ラベル付けファイルは入力データと同じスキーマを有していますが、labeling_set_id と label の 2 列が追加されています。
トレーニングデータセットは全体的に複数のラベル付けセットに分割されます。各ラベル付けセットには labeling_set_id 値が表示されます。このように識別されることでラベル付けプロセスが簡素化され、ファイル全体をスキャンする場合よりも、同一ラベル付けセット内におけるレコードの一致関係に集中することができます。
あるラベル付けセット内で複数のレコードに同じラベル値を指定すると、それらのレコードを一致と見なすよう FindMatches に教えることになります。また、同一ラベル付けセット内で複数のレコードが異なるラベルを付けられている場合、FindMatches はそれらのレコードを一致と見なさないよう学習します。FindMatches は同一ラベル付けセット内のレコード間でのみレコードの関係を評価します。複数のラベル付けセットをまたいでの評価はしません。
例を示します。上記のテーブルには、0 と 1 という 2 つのラベル付けセットがあります。ラベル付けセット 0 にある最初の 2 つのレコード (タイトル が “Visual COKO . . .” で始まる) にはラベル 0 が、次の 3 つのレコード (タイトルが “Aurora . . .” で始まる) にはラベル 1 が表示されています。FindMatches は、“Visual COKO” レコードは互いに一致し、3 つの “Aurora” レコードは互いに一致すると学習します。FindMatches は 2 つの Visual COKO レコードが 3 つの “Aurora” レコードと一致しないことも学習します。しかし変換は、これらのレコードに関して、ラベル付けセット 1 のレコードと関連することは何も学習しません。たとえば、Visual COKO レコードがラベル付けセット 1 にある最初の 3 つのレコード (タイトルが “Self-tuning Histograms . . .” で始まる) と一致するか否かを、FindMatches は評価しようとはしません。ラベル付け作業者は、この制限により、一度に 1 つのセットでラベル付けを行うことに集中できます。
まったく一致しないレコードがあった場合、そのレコードはラベル付けセット内で一意のラベル値を持ちます。
データを表現するのにラベル付けセットのサイズを変えるのが最良である場合は、そうしてもかまいません。しかし、各ラベル付けセットは、2 つ以上かつ通常で約 30 以下のレコードで構成されている必要があることに注意してください。各ラベル付けセットのサイズは 10 ほどにするのがよいでしょう。
最後に、一致プロジェクトの開始時にラベル付けしたデータがなくても、ラベル付けしたデータファイルを一から作成する必要はありません。このチュートリアルでは、[Teach] ページの [Generate labeling file] 機能を使用します。この機能では、内部ヒューリスティクスを使用してラベル付けするレコードを選択します。
それらのヒューリスティクスにより、一致、不一致、一致と不一致の境界にあるレコードペアのサンプルを含むラベル付けセットを含むよう設計された、ラベル付けファイルが生成されます。自身でラベル付けファイルを生成する場合も同様に、最良の結果を得られるよう、一致レコードおよび不一致レコード両方を表すセットを含めます。また、判断の難しいサンプルも含めてみてください。
妥当な一致品質を達成するには、数百のレコードをラベル付けする計画を立てます。高い一致品質を達成するには、数千のレコードをラベル付けする計画を立てます。
ラベルをアップロードして一致品質を確認する
ラベル付けしたデータセットを作成したら、FindMatches にその場所を教えます。
- AWS Glue コンソールで、先のステップで作成した変換を選択します。
- [アクション]、[Teach transform] の順に選択します。

- 次のページで、[I have labels] を選択し、[Upload labeling file from S3] を選択してから、[次へ] を選択します。

- 次のページの [S3 path where the label file is stored] で、ラベルファイルのパス s3://ml-transforms-public-datasets-us-east-1/dblp-scholar/labels/dblp_scholar_labels_350.csv を選択します。us-east-1 以外のリージョンで FindMatches を使用している場合、ファイル URL の us-east-1 をお使いのリージョンに置き換えてください。
- このチュートリアルでは、ラベルのセットを 1 つだけ使用するため、[Overwrite my existing labels] を選択します。繰り返しラベルを追加する場合、もう一方のオプションを選択します。
 [Upload] を選択します。ラベルがアップロードされたら、変換は使用準備完了です。必ずしも必要なわけではありませんが、一致レコードおよび不一致レコードのメトリクスを確認して、変換の一致品質をチェックしてください。
[Upload] を選択します。ラベルがアップロードされたら、変換は使用準備完了です。必ずしも必要なわけではありませんが、一致レコードおよび不一致レコードのメトリクスを確認して、変換の一致品質をチェックしてください。
- 次のページで、メトリクスにアクセスするため、[Estimate transform quality] を選択します。この変換品質推定機能は、ラベルの 70% を使用して学習します。トレーニングが完了すると、品質推定機能は残りの 30% に対する一致レコードの特定を行い、変換の学習度合いをテストします。最後に、変換はアルゴリズムによって予測された一致および不一致と実際のラベルを比較して、品質メトリクスを生成します。このプロセスには数分かかる場合があります。
結果は次のスクリーンショットのようになります。このテストでは品質の推定にデータのほんの小さなサブセットしか使用しないため、これらのメトリクスは概算として考えてください。メトリクスに満足したら、レコード一致ジョブの作成と実行に進みます。満足できなければ、一致品質向上のため、ラベル付けしたレコードを追加アップロードします。

レコード一致ジョブを作成および実行する
FindMatches 変換を作成し、変換がデータ内の一致レコードを特定できるほど学習したことを検証できたら、データセット全体で一致を特定する準備は完了です。
- AWS Glue コンソール を開き、左側のナビゲーションペインで [ジョブ] を選択し、[ジョブの追加] を選択します。

- [ジョブプロパティ] で、ジョブ名を入力し、IAM ロールを選択します。IAM ロール には、レコードとラベルファイルを保存する Amazon S3 の場所にアクセスするためのアクセス許可がなければなりません。詳細については、「AWS Glue 用の IAM ロールを作成する」を参照してください。

- [セキュリティ設定、スクリプトライブラリおよびジョブパラメータ] の [Worker type] で、全 FindMatches ジョブ向けに [2X] を選択します。

- 次のページで、一致レコードを検出するテーブルを選択します。

- 次のページで、変換タイプとして [Find matching records] を選択します。重複と特定されたレコードを確認する場合は、[Remove duplicate records] を選択しないでください。[次へ] を選択します。

- 次に、作成した変換を選択し、[次へ] を選択します。

- 次のページで、[データターゲットでテーブルを作成する] を選択します。[データストア] で、[Amazon S3] を選択します。[形式] で、[CSV] を選択します。[ターゲットパス] で、ジョブの出力のパスを選択します。[ジョブを保存してスクリプトを編集する] を選択します。
 スクリプトがそのまま使用できる状態でジョブに生成されます。または、スクリプトをさらにカスタマイズして独自の ETL ニーズに合わせることもできます。ジョブの設定が完了しました。
スクリプトがそのまま使用できる状態でジョブに生成されます。または、スクリプトをさらにカスタマイズして独自の ETL ニーズに合わせることもできます。ジョブの設定が完了しました。
- [ジョブの実行] を選択し、このデータセット内で一致の特定を開始します。今のところは、ジョブパラメータをデフォルト設定のままにしておき、ジョブを開始したらこのページを閉じます。

このサンプルデータセット用のジョブは完了までに約 10 分以上かかります。実行が正常に完了したら、FindMatches には Succeeded という実行ステータスが表示されます。
FindMatches は、ジョブの作成中に指定したターゲットパスにマルチパート .csv ファイルとして出力データを保存します。出力を確認するには、ローカルに出力ファイルをコピーして、単一の .csv ファイルにマージします。ファイルのマージには利用可能なあらゆる方法を使用できます。
たとえば、macOS 環境および Linux 環境では、次のコマンドを使用できます。
出力を確認する
出力 .csv ファイルを開いて、match_id 列でソートします。前述のとおり、出力は入力テーブルと同じ構造とデータを有していますが、match_id 列が追加されています。一致と特定されたレコードは同じ match_id 値を有しています。

FindMatches はレコード内で多くの一致を正確に特定しているはずです。詳しくチェックすると、いくつか正確でない一致があることに気づくでしょう。一致の定義は各ユースケースにより異なります。次のテーブルでは、著者と発表年が異なるために、“Guest Editor’s Introduction” エントリが一致とみなされない場合があります。

一般的に、結果はより多くのデータをラベル付けすることで改善します。このチュートリアルでは、ラベル付けしたレコードを 352 個しか使用していません。その内、基盤となる ML モデルのトレーニングに使用されたのはほんの 70% で、一致品質メトリクスの検証用データとして利用されたのは 30% です。一致品質は、ラベル付けしたレコード数を数千規模に増やすことで大幅に向上するはずです。
しかし、より多くのデータをラベル付けし、スライダーを微調整し、一致品質を向上させても、[Precision] と [Recall] 両方の基準で 100% に達することは決してないでしょう。出力には常に一定の割合で偽陽性および偽陰性の一致が発生します。”偽陽性” とは、一致でない場合に変換が一致としてラベル付けしたレコードペアのことです。”偽陰性” とは、変換が一致としてラベル付けし損ねた、実際には一致しているレコードペアのことです。レコード一致ジョブに続くダウンストリームワークフローを設計する際には、このことを考慮してください。
まとめ
この記事では、Lake Formation FindMatches ML 変換を使用して、別々の 2 つのデータセット内の一致レコードを検出する方法を紹介しました。この方法を用いると、2 つのデータセットのレコードが共通の識別子を共有していない場合でも一致を検出することができます。フィールドが完全に一致しない、または属性がないか破損している場合に、この方法がデータセットの列間の一致を検出するのにどのように役立つかがわかったことでしょう。
是非このノウハウを今後に活かしましょう。 AWS コンソールから Lake Formation で構築を開始し、お持ちのデータに FindMatches を試して、AWS に経過をお知らせください。 質問やフィードバックがおありですか? lakeformation-feedback@amazon.com 宛てに E メールを送信してください。
著者について
 Sergei Dobroshinsky は、アマゾン ウェブ サービスの Amazon AI 部門でシニアテクニカルプログラムマネージャーを務めています。
Sergei Dobroshinsky は、アマゾン ウェブ サービスの Amazon AI 部門でシニアテクニカルプログラムマネージャーを務めています。
 Tim Jones は、アマゾン ウェブ サービスの Amazon AI 部門でソフトウェア開発マネージャーを務めています。
Tim Jones は、アマゾン ウェブ サービスの Amazon AI 部門でソフトウェア開発マネージャーを務めています。