Amazon Web Services ブログ
Amazon SageMaker Ground Truth と Databricks MLflow を用いた MLOps 感情分析パイプラインの構築
この記事は、“Build an MLOps sentiment analysis pipeline using Amazon SageMaker Ground Truth and Databricks MLflow” を翻訳したものです。
より深いインサイトを得るために機械学習(ML)を導入する企業が増える中、ラベリングとライフサイクル管理という2つの重要な課題に直面しています。ラベリングとは、データを確認し、ML モデルがそこから学習できるようにラベルを追加して、データのコンテキストを提供することです。ラベルとは、音声ファイルの文字起こし、写真内の車の位置、または MRI 画像内の臓器の箇所などが該当します。データのラベリングは、ML モデルがデータに対してうまく動作するようにするために必要です。ライフサイクル管理は、ML 実験のセットアップと、結果を得るために使用したデータセット、ライブラリ、バージョン、モデルを文書化するプロセスなどに関係するものです。あるチームは、1つのアプローチに落ち着くまでに何百もの実験を行うかもしれません。その実験の要素を記録しておかないと、過去のアプローチに立ち戻って再現するのは難しいでしょう。
多くの ML のサンプルやチュートリアルは、目標値(ラベル)を含むデータセットから始まります。しかし、実世界のデータは必ずしも目標値を持っているとは限りません。例えば、感情分析では、人は通常、レビューが肯定的か否定的か、あるいは混合的か判断することができます。しかし、生のレビューは判断値がついていないテキストの集まりでできています。この問題を解くための教師あり学習モデルを作成するには、高品質のラベル付きデータセットが必須となります。Amazon SageMaker Ground Truth は、ML 用の高精度な学習データセットを簡単に構築できる、フルマネージドのデータラベリングサービスです。
AWS 上のデータおよび分析プラットフォームとして Databricks を使用して抽出、変換、ロード(ETL)タスクを実行している組織の場合、最終目標は教師あり学習モデルのトレーニングであることが多いようです。この記事では、Databricks がどのように Ground Truth や Amazon SageMaker と統合して、データのラベリングやモデルの配布を行うかを紹介します。
ソリューションの概要
Ground Truth は、ML 用の高精度なトレーニングデータセットを簡単に構築できる、フルマネージドのデータラベリングサービスです。Ground Truth のコンソールを通じて、カスタムまたはビルトインのデータラベリングワークフローを数分で作成することができます。これらのワークフローは、3D 点群、ビデオ、画像、テキストなどさまざまなユースケースに対応しています。さらに、Ground Truth は、ML モデルを使用してデータにラベリングする自動データラベリング機能を提供しています。
ここでは、一般に公開されている Amazon Customer Reviews データセットでモデルを学習させます。大まかには以下のような手順です。
- ラベリングする生データセットを抽出し、Amazon Simple Storage Service (Amazon S3) に配置する。
- SageMaker でラベリングジョブを作成し、ラベリングを実行する。
- サンプルノートブックを使って、Databricks プラットフォーム上でレビューテキストの感情を分類するためのシンプルな scikit-learn 線形学習器モデルを構築し、学習させる。
- MLflow コンポーネントを使用して MLOps を作成、実行し、モデル成果物を保存する。
- MLflow SageMaker ライブラリを使用して SageMaker エンドポイントとしてモデルをデプロイし、リアルタイム推論を実行する。
以下の図は、Ground Truth と MLflow を使用したラベリングと ML の工程を示しています。

SageMaker におけるラベリングジョブの作成
感情分析モデルを構築するため、Amazon Customer Reviews のデータセットからテキスト部分のみを抽出します。抽出したら、テキストを S3 バケットに配置し、SageMaker コンソールから Ground Truth のラベリングジョブを作成します。
ラベリングジョブの作成 ページで、必要な項目を入力します。このページのステップの一部として、Ground Truth はジョブで用いるマニフェストファイルを生成することができます。Ground Truth は、入力マニフェストファイルを使用して、ラベリングジョブ内のファイルやオブジェクトの数を特定することで、適切な数のタスクが作成され、人間(または機械)のラベリング作業者に送信されるようにします。このファイルは自動的に S3 バケットに保存されます。次に、タスクカテゴリとタスクの選択を指定します。今回のユースケースでは、タスクカテゴリに テキスト を、タスクの選択に テキスト分類(単一ラベル) を指定します。これは、レビューテキストに、肯定的、否定的、または中立という単一の感情を割り当てることを意味します。
最後に、ラベリング作業者に対して、テキストデータにどのようにラベルを付けるべきかについて、シンプルで簡潔な説明を記述します。この指示はラベリングツールに表示されます。オプションとして作業画面上における表示を確認することもできます。最後に、ジョブを投入し、コンソールで進捗を監視します。
ラベリングジョブの実行中も、出力 タブからラベリングされたデータを確認することができます。各レビューテキストとラベル、そしてそのジョブが人間によって行われたのか機械によって行われたのかを監視することができます。ラベリングジョブの100%を人間が行うこともできますが、機械による自動アノテーションを選択することで、ジョブを高速化し、人件費を削減することができます。
ジョブが完了すると、出力マニフェストとラベル付きデータセットへのリンクがラベリングジョブの概要欄に表示されます。また、Amazon S3 にアクセスし、S3 バケットフォルダからそれぞれをダウンロードすることも可能です。

次のステップでは、Databricks ノートブック、MLflow、Ground Truth でラベリングされたデータセットを使って、scikit-learn モデルを構築します。
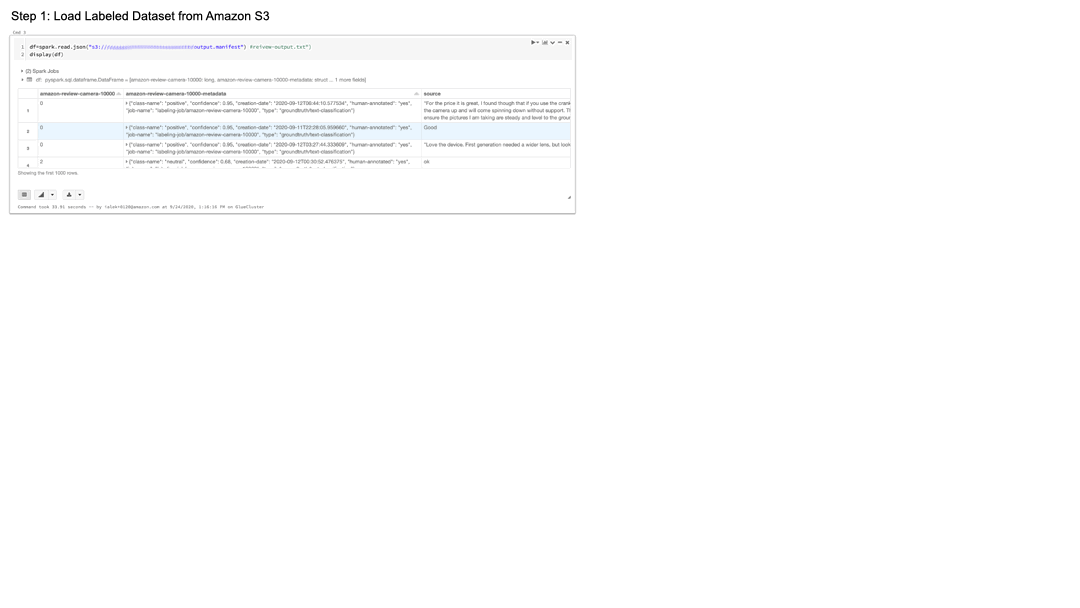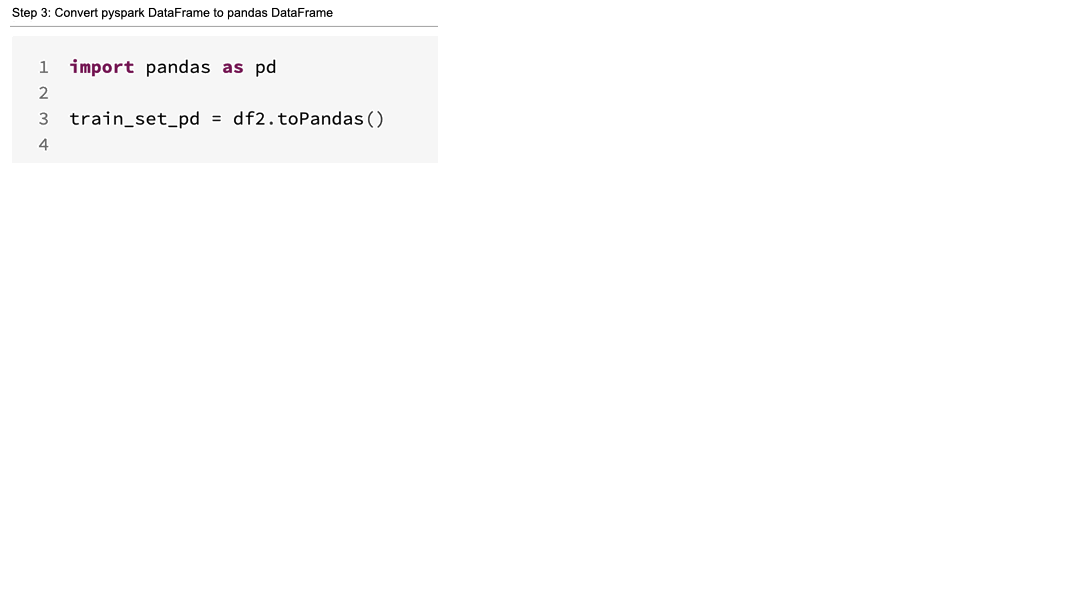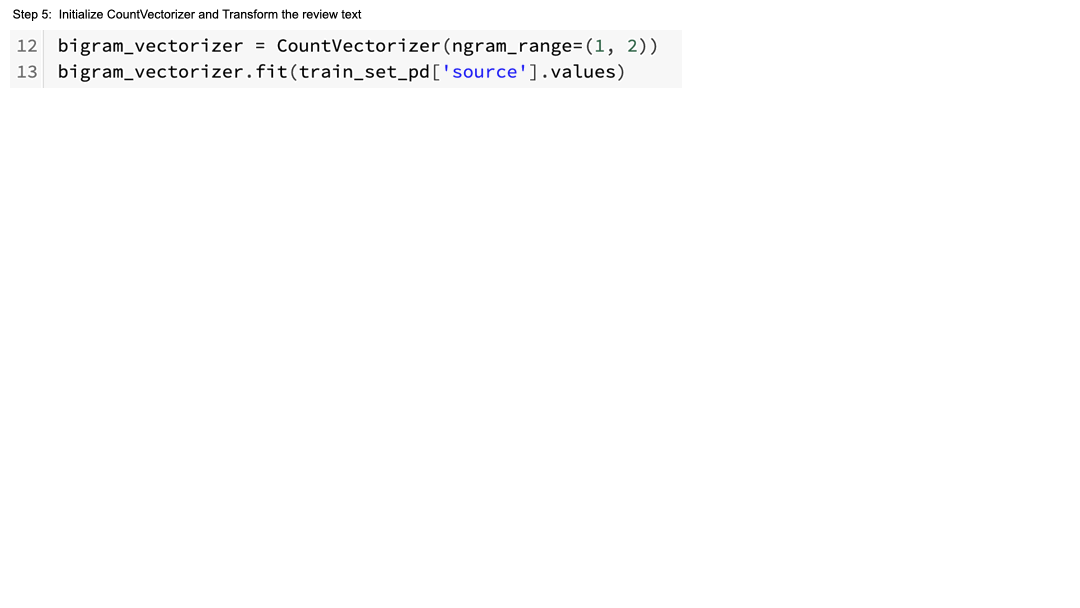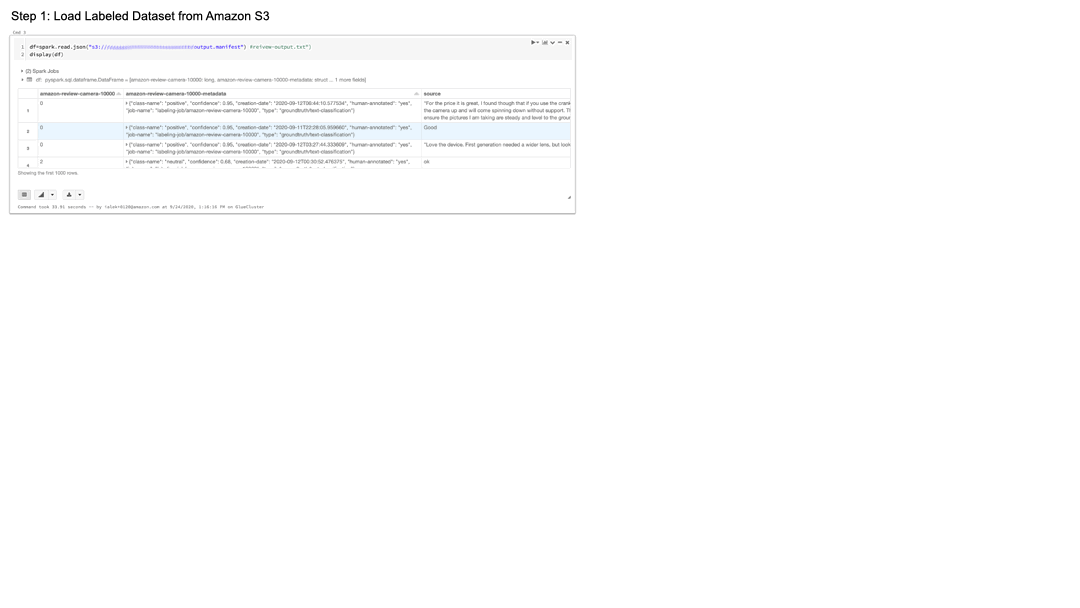
Amazon S3 からラベル付きデータセットをダウンロード
Amazon S3 からラベル付きデータセットをダウンロードすることから始めます。まず、JSON 形式で保存されているマニフェストを、Databricks の Spark DataFrame に読み込みます。感情分析モデルの学習には、Ground Truth ラベリングジョブでアノテーションされたレビューテキストと感情ラベルのみが必要です。select() を用いて、これら2つの特徴量を抽出します。次に、scikit-learn のアルゴリズムが Pandas DataFrame 形式を必要とするため、データセットを PySpark DataFrame から Pandas DataFrame に変換します。
次に、scikit-learn の CountVectorizer を使い、ngram_range の最大値を2に設定することで、レビューテキストをバイグラムベクトルに変換します。 CountVectorizer はテキストをトークン数の行列に変換します。次にTfidfTransformer を用いて、バイグラムベクトルを単語頻度-逆文書頻度(TF-IDF)形式に変換します。
ここでは、バイグラムベクトルを用いた学習と、TF-IDF に変換したバイグラムを用いた学習の精度スコアを比較します。TF-IDF は、ある単語が文書の集まりの中でどの程度文書と関連しているかを評価する統計的尺度です。レビューテキストは比較的短い傾向があるので、TF-IDF が予測モデルの性能にどのような影響を与えるかを観察することができます。
MLflow 実験のセットアップ
MLflow は Databricks 社によって開発され、現在ではオープンソースプロジェクトとして公開されています。MLflow は ML のライフサイクルを管理し、実験の追跡、再現、公開を簡単に行うことができます。
MLflow の実験を設定するために、mlflow.sklearn.autolog() を使用します。これにより、estimator.fit()、estimator.fit_predict()、estimator.fit_transform() が呼ばれるたびにハイパーパラメータ、メトリクス、モデル成果物の自動ロギングを有効にしています。また,mlflow.log_param()、mlflow.log_metric() を呼び出すことで、手動でロギングを行うことも可能です.
変換されたデータセットを、SGD(Stochastic Gradient Descent)学習によって線形分類器にフィットします。SGD では、損失の勾配は一度に1サンプルずつ推定され、モデルは勾配に沿って学習率をかけた分だけ更新されます。
先ほど用意した2つのデータセットを train_and_show_scores() 関数に渡し、学習を行います。学習後、モデルを登録し、その成果物を保存する必要があります。その際、mlflow.sklearn.log_model() を使用します。
デプロイする前に、実験結果を見て、2つの実験(バイグラムの実験と、バイグラムと TF-IDF を組み合わせた実験)を選び、比較します。今回のユースケースでは、バイグラムと TF-IDF を組み合わせて学習した2番目のモデルの方が若干性能が良かったので、そのモデルを選んでデプロイしています。モデルの登録が完了したら、モデルのステージを本番に変更し、モデルをデプロイします。この操作は MLflow の UI 上でもできますし、コード上でも transition_model_version_stage() を使って実現することができます。

SageMaker エンドポイントとしてのモデルのデプロイとテスト
学習したモデルをデプロイする前に、SageMaker でモデルをホストするために用いる Docker コンテナを構築する必要があります。これを行うには、シンプルな MLflow コマンドを実行してコンテナをビルドして、AWS アカウント内の Amazon Elastic Container Registry (Amazon ECR) にプッシュします。
こうすると、Amazon ECR のコンソールにイメージの URI が表示されます。イメージ URI を image_url パラメータとして deploy() 関数に渡し、新規デプロイであれば mode パラメータに DEPLOYMENT_MODE_CREATE を指定します。既存のエンドポイントを新しいモデルバージョンで更新する場合は、DEPLOYMENT_MODE_REPLACE を使用します。
SageMaker のエンドポイントをテストするために、エンドポイント名と入力データをパラメータとして使用する関数を作成します。

まとめ
この投稿では、Ground Truth を使って生のデータセットにラベルを付け、そのラベル付きデータを使って scikit-learn で単純な線形分類器を学習する方法を紹介しました。この例では、MLflow を使ってハイパーパラメータとメトリクスを追跡し、本番グレードのモデルを登録し、学習したモデルをエンドポイントとして SageMaker にデプロイしています。データを処理する Databricks とともにこのユースケース全体を自動化すると、新しく追加されたデータにラベルを付けてモデルで処理することができます。このようなパイプラインとモデルを自動化することで、データサイエンスチームは、日々のデータ更新の管理に時間を費やすことなく、新しいユースケースに集中し、より多くのインサイトを発見することができるようになります。
まずは、Amazon SageMaker Ground Truth を使用してデータにラベル付けするをご覧いただき、Databricks on AWS の14日間無料トライアルにご登録ください。Databricks と SageMaker、または AWS Glue や Amazon Redshift といった他のAWSサービスとの統合の詳細については、Databricks on AWS をご覧ください。
さらに、この投稿で使用した以下のリソースもご確認ください。
まずは、こちらのノートブックをお試しください。
著者について

Rumi Olsen は、AWS パートナープログラムのソリューションアーキテクトです。自然言語処理技術のバックグラウンドを持ち、サーバーレスや機械学習ソリューションを専門しています。余暇は娘とパシフィックノースウェストの自然を探索することに費やしています。
 Igor Alekseev はAWSのデータ&アナリティクス専門のパートナーソリューションアーキテクトです。Igorは、戦略的パートナーと共に、複雑な AWS 最適化アーキテクチャーの構築を支援しています。AWS に入社する前は、データ/ソリューションアーキテクトとして、Hadoop エコシステムのデータレイクを含むビッグデータに関する多くのプロジェクトを実施しました。データエンジニアとして、不正検知やオフィスオートメーションへの AI/ML の適用に携わってきました。Igor は、通信、金融、公共安全、製造業、ヘルスケアなど、さまざまな業界のプロジェクトに参加してきました。それ以前は、フルスタックエンジニア/テックリードとして働いていました。
Igor Alekseev はAWSのデータ&アナリティクス専門のパートナーソリューションアーキテクトです。Igorは、戦略的パートナーと共に、複雑な AWS 最適化アーキテクチャーの構築を支援しています。AWS に入社する前は、データ/ソリューションアーキテクトとして、Hadoop エコシステムのデータレイクを含むビッグデータに関する多くのプロジェクトを実施しました。データエンジニアとして、不正検知やオフィスオートメーションへの AI/ML の適用に携わってきました。Igor は、通信、金融、公共安全、製造業、ヘルスケアなど、さまざまな業界のプロジェクトに参加してきました。それ以前は、フルスタックエンジニア/テックリードとして働いていました。
 Naseer Ahmed は Databricks のシニアパートナーソリューションアーキテクトとして、AWS ビジネスをサポートしています。データウェアハウス、ビジネスインテリジェンス、アプリ開発、コンテナ、サーバーレス、AWS 上の機械学習アーキテクチャーを専門としています。Databricks の 2021 SME of the year に選出され、熱心なクリプト愛好家でもあります。
Naseer Ahmed は Databricks のシニアパートナーソリューションアーキテクトとして、AWS ビジネスをサポートしています。データウェアハウス、ビジネスインテリジェンス、アプリ開発、コンテナ、サーバーレス、AWS 上の機械学習アーキテクチャーを専門としています。Databricks の 2021 SME of the year に選出され、熱心なクリプト愛好家でもあります。
翻訳は機械学習パートナーソリューションアーキテクトの本橋が担当しました。本記事は翻訳にあたり、一部記述を追加および修正しています。