Amazon Web Services ブログ
EMR – Sqoop を使用して RDBMS またはオンプレミスデータを EMR Hive、S3、および Amazon Redshift に移行する
このブログ記事では、AWS のお客様が Apache Sqoop ツールの使用によって利益を得る方法について説明します。このツールは、データをリレーショナルデータベース管理システム (RDBMS) から AWS の EMR Hadoop Distributed File System (HDFS) にインポートし、データを Hadoop で変換して、それをデータウェアハウス (例: Hive または Amazon Redshift) にエクスポートするために設計されています。
Sqoop ツールのデモを行うために、この記事では以下の 3 つのシナリオにおいて、Amazon RDS for MySQL をソースとして使用し、データをインポートします。
- シナリオ 1 — AWS EMR (HDFS -> Hive および HDFS)
- シナリオ 2 — Amazon S3 (EMFRS)、次に EMR-Hive
- シナリオ 3 — S3 (EMFRS)、次に Redshift

これらのシナリオは、お客様がデータ転送を同時に開始するために役立つことから、転送をより迅速に実行することができ、従来の ETL ツールよりもコスト効率性に優れています。スクリプトを作成したら、お客様は様々な RDBMS データソースを EMR-Hadoop に転送するためにそのスクリプトを再利用できます。これらのデータソースの例は、PostgreSQL、SQL Server、Oracle、および MariaDB です。
オンプレミス RDBMS にも同じ手順をシミュレートすることができます。これには、正しい JDBC ドライバーがインストールされていることと、企業データセンターと AWS クラウド環境の間にネットワーク接続がセットアップされていることが必要です。このシナリオでは、データのロード量とネットワーク制約に基づいて、AWS Direct Connect または AWS Snowball の手法を使用することを検討してください。
前提条件
この記事の手順を完了するには、以下のタスクを実行する必要があります。
ステップ 1 — RDS インスタンスを起動する
AWS マネジメントコンソール または AWS CLI コマンドを使用することによって、希望する容量を持つ MySQL インスタンスを起動します。以下の例では、デフォルト設定で T2.Medium クラスを使用しています。

正しいサービスを呼び出すために、エンドポイントをコピーして、以下の JDBC 接続文字列を表示されているとおりに使用してください。この例では、米国東部 (バージニア北部) の us-east-1 AWS リージョンを使用しています。
ステップ 2 — 接続をテストして、RDS – MySQL にサンプルデータをロードする
最初に、このロケーションからのオープンソースデータサンプルを使用しました。https://bulkdata.uspto.gov/data/trademark/casefile/economics/2016/
その後、以下の 2 つのテーブルをロードしました。
- イベントデータ: https://bulkdata.uspto.gov/data/trademark/casefile/economics/2016/event.csv.zip
- 米国商標区分データ: https://bulkdata.uspto.gov/data/trademark/casefile/economics/2016/us_class.csv.zip
次に、MySQL Workbench ツールを使ってサンプルテーブルをロードして、インポート/エクスポートウィザードを使ってデータをロードしました。 これは、データを自動的にロードし、テーブル構造を作成します。
ダウンロード手順:
以下の手順は、MySQL データベースエンジンをダウンロードして、上記のデータソースをテーブルにロードするために役立ちます。https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/CHAP_GettingStarted.CreatingConnecting.MySQL.html#CHAP_GettingStarted.Connecting.MySQL
今回は、Mac で以下の手順を使用しました。
| ステップ A: Homebrew のインストール | ステップ B: MySQL のインストール |
| Homebrew はオープンソースのソフトウェアパッケージ管理システムです。このブログ記事を書いた時点では、Homebrew のメインリポジトリに MySQL バージョン 5.7.15 がデフォルトフォーミュラとして置かれていました。 | 次のコマンドを入力します: $ brew info MySQL |
| Homebrew をインストールするには、ターミナルを開いてから以下を入力します。 | 期待される出力: MySQL: stable 8.0.11 (bottled) |
| $ /usr/bin/ruby -e “$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)” | 次を入力して MySQL をインストールします: $ brew install MySQL |
| Homebrew は次に、インストールプロセスの一環として Xcode 8.0 向けのコマンドラインツールをダウンロードしてインストールします。 |
最後に、ダウンロードが完了したら、接続パラメーター用に接続文字列、ポート、SID を入力します。メインコンソールで、MySQL Connections の (+) マークをクリックして新しい接続のウィンドウを開き、[Connection Name]、[Hostname] (RDS エンドポイント)、[Port]、[Username]、および [Password] の接続パラメーターを入力します。

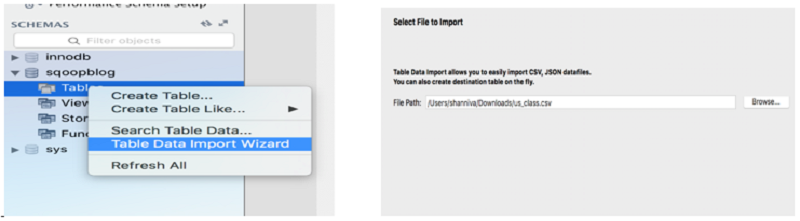

ステップ 3 — EMR クラスターを起動する
EMR コンソールを開き、[詳細オプションに移動する] を選択して、以下のオプションセットでクラスターを起動します。

ステップ 4 — SSH アクセスをテストして、MySQL-connector-java-version-bin.jar を EMR フォルダにインストールする
a.[マスターのセキュリティグループ] でリンクをクリックして、[インバウンドのルールの編集] で PC またはラップトップの IP がマスタークラスターにアクセスできるようにします。

b.以下の場所から、MySQL JDBC ドライバーをローカル PC にダウンロードします。
http://www.mysql.com/downloads/connector/j/5.1.html
c.フォルダを解凍して、利用できる MySQL コネクタの最新バージョンをコピーします。(この例で使用するバージョンは、MySQL-connector-java-5.1.46-bin.jar ファイルです。)
d.ファイルを EMR マスタークラスターの /var/lib/sqoop/ ディレクトリにコピーします。(注意: EMR マスターはマスターノードへのパブリックアクセスを許可しないため、ローカル PC からのマニュアルダウンロードを実行する必要がありました。ダウンロード後、FileZila (クラスプラットフォーム FTP アプリケーション) を使用してファイルをプッシュしました。)
e.ターミナルから、SSH 経由でマスタークラスターにアクセスし、/usr/lib/sqoop ディレクトリに移動してこの JAR ファイルをコピーします。
注意: このドライバーコピーは、bootstrap スクリプトを使ってドライバーファイルを S3 パスにコピーしてから、それをマスターノードに転送することによって自動化できます。スクリプト例は以下のとおりです。
または、一時的なインターネットアクセスを使ってマスターノードにファイルを直接ダウンロードするには、以下のコードをコピーしてください。
マスターノードディレクトリ /usr/lib/sqoop は、以下のようになっているはずです。

- EMR を使った作業を始める前に、アカウント内のリソースにアクセスするために十分な許可を持つ AWS Identity and Access Management (IAM) サービスロールが少なくとも 2 つ必要になります。
- Amazon RDS、および EMR のマスタークラスターとスレーブクラスターは、MySQL RDS インスタンスに接続して、データのインポートとエクスポートを開始するためのアクセス権を持っている必要があります。例えば、ここでは EMR ノード (マスターセキュリティグループとスレーブセキュリティグループ) からの着信接続を許可するために RDS MySQL インスタンスのセキュリティグループを編集します。
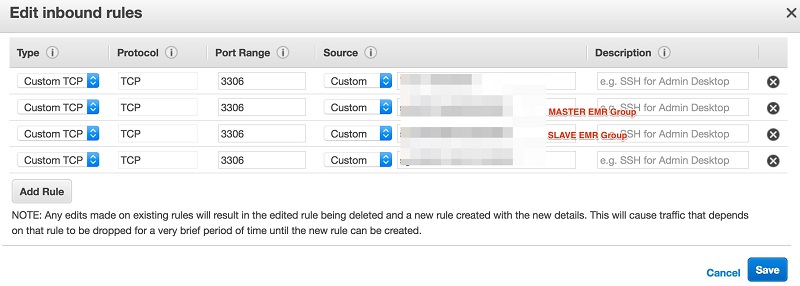
ステップ 5 — EMR から MySQL RDS への接続をテストする
ログインしたら、EMR マスタークラスターで以下のコマンドを実行して接続を検証します。これは、MySQL RDS ログインもチェックし、テーブルのレコード数をチェックするサンプルクエリを実行します。
注意: 前述のサンプルクエリにおけるレコード数は、以下の例で示すように、MySQL テーブルと一致する必要があります。

EMR へのデータのインポート – 一括ロード
EMR にデータをインポートするには、以下のクエリを使用して、最初に完全なデータをテキストファイルとしてインポートする必要があります。
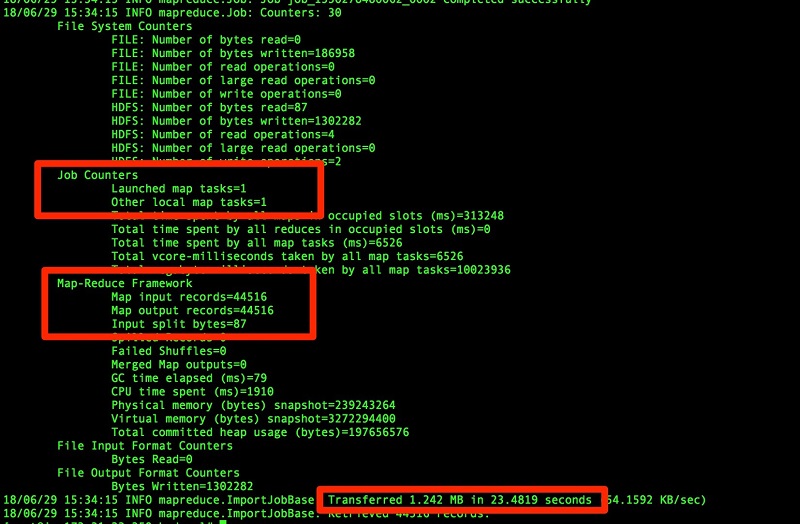
インポートが完了したら、それぞれの hadoop ディレクトリの場所で抽出ファイルを検証します。

前の例に示されているとおり、元のテーブルはパーティション分割されていません。このため、テーブルは 1 つのファイルとして抽出され、Hadoop フォルダにインポートされます。これがより大きなテーブルであった場合は、パフォーマンス問題の原因になっていた可能性があります。
この問題に対応するため、パーティションテーブルを選択し、より高速かつ効率的にエクスポートするためのダイレクトメソッドを使用する場合に、パフォーマンスがどのように向上するかについて説明します。EVENT_DT 列をキーパーティションとしてイベントテーブル EVENTS_PARTITION をアップデートしてから、元のテーブルのデータをこのテーブルにコピーしました。 それに加えて、同時データ転送の効率性を最適化するために、MySQL パーティションの活用を生かすダイレクトメソッドを使用しました。

データをコピーして、統計を実行します。
MySQL Workbench で以下のクエリを実行して、データをコピーし、統計を実行します。

MySQL Workbench でクエリを実行したら、EMR マスターノードで以下の Sqoop コマンドを実行します。
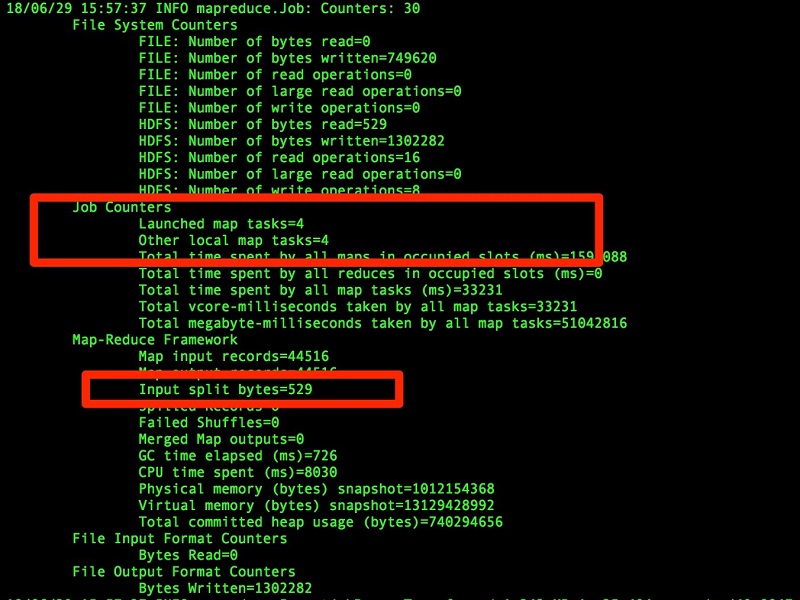 この例は、追加の引数オプション (パーティション分割されたテーブル) による、同じコマンドに対するパフォーマンスの向上を示しています。 また、データファイルが 4 つに分割されていることもわかります。テーブルのパーティション統計に基づいて、MapReduce タスクの数が自動的に 4 つ作成します。
この例は、追加の引数オプション (パーティション分割されたテーブル) による、同じコマンドに対するパフォーマンスの向上を示しています。 また、データファイルが 4 つに分割されていることもわかります。テーブルのパーティション統計に基づいて、MapReduce タスクの数が自動的に 4 つ作成します。

m 10 引数を使ってマップタスクを増やすこともできます。これは、入力分割の数と同じになります。
注意: 上記のサンプルコードにあるように、MapReduce エンジン引数 (-m <<希望する数 #> を増やすことによって、インポートプロセス中により多くのデータ抽出ファイルを分割することもできます。抽出ファイルがパーティション分散と合致するようにしてください。そうしなければ、出力ファイルの順序が正しくなりません。


選択的な列をインポートする必要がある場合は、以下の追加オプションを検討してください。
以下の例では、選択的なフィールドに対して、– COLUMN 引数を追加します。
シナリオ 2 では、テーブルデータファイルを S3 バケットにインポートします。これを行う前に、EMR-EC2 インスタンスグループで S3 バケットに対するセキュリティが追加されていることを確認してください。EMR マスタークラスターで以下のコマンドを実行します。
Hive テーブルとしてのインポート – フルロード
ここで、Sqoop コマンドから直接 Hive テーブルを作成してみましょう。これは、Hive テーブルを動的に作成するためのより効率的な方法で、このテーブルは、追加要件のために後ほど外部テーブルに変更することができます。この方法を使用することによって、お客様は自動化されたアプローチを通じてデータの作成と Hive への変換のための時間を節約できます。
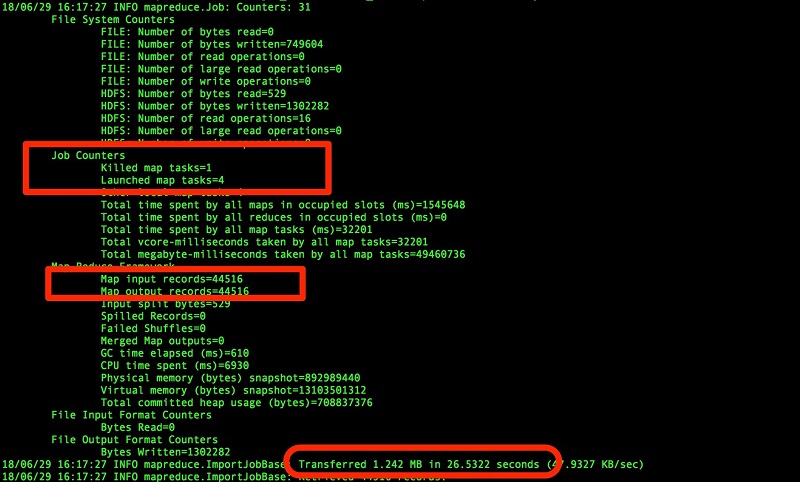
 では、ダイレクトメソッドを試行して、ロードパフォーマンスとインポート時間がどれほど大きく向上するかを確認しましょう。
では、ダイレクトメソッドを試行して、ロードパフォーマンスとインポート時間がどれほど大きく向上するかを確認しましょう。
以下は検討する追加オプションです。
以下の例では、COLUMN 引数を選択的なフィールドに追加してから、Hive テーブルとして EMR にインポートします。
自由形式クエリを実行して、Hive テーブルとして EMR にインポートします。
– シナリオ 2 については、S3 の場所から Hive テーブルを手動で作成してください。 以下の例は、S3 の場所から外部テーブルを作成します。SELECT 文を実行してデータ数をチェックします。
インポートメモ: Sqoop バージョン 1.4.7 を使うと、以下のサンプルコードにあるように、スクリプトを使用して Hive テーブルを直接作成することができます。 この機能は EMR 5.15.0 でサポートされています。
前述のコードサンプルについては、Hive または Hue で検証して、テーブルレコードを確認してください。

完全なスキーマテーブルを Hive にインポートします。
注意: 最初に Hue または Hive で Hive データベースを作成してから、EMR マスタークラスターで以下のコマンドを実行してください。
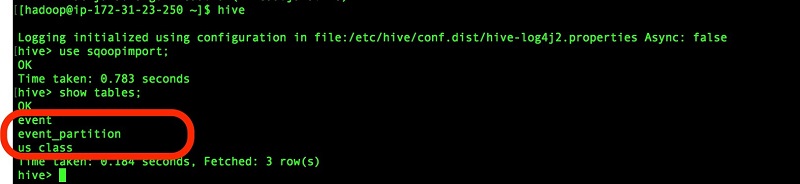
Hive テーブルとしてのインポート – 増分ロード
それでは、イベントデータをキーとするパーティションテーブルのためのサンプル増分データフィードを Hive にロードしてみましょう。増分ベースで以下の Sqoop コマンドを使用します。
EVENT_BASETABLE と呼ばれるテーブルにある初期データに加えて、EVENT_BASETABLE に増分データをロードしました。以下の手順とコマンドで Sqoop による増分更新を行って、Hive にインポートします。
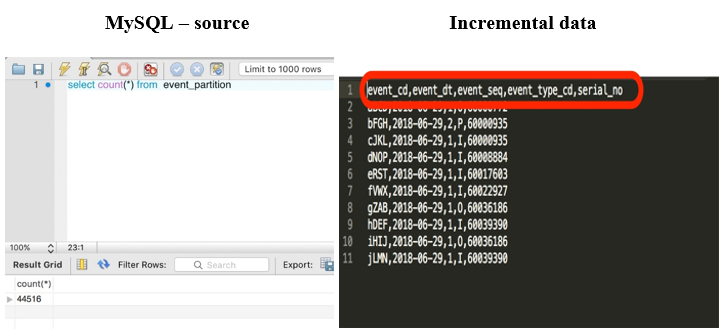
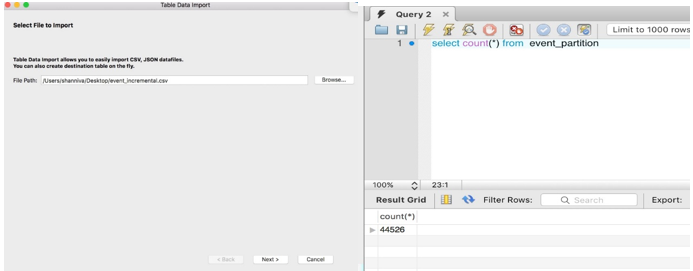

増分抽出が Hadoop ディレクトリにロードされたら、一時的 (または増分) テーブルを Hive に作成して、それらをメインテーブルに挿入できます。
代替手法として、様々なテーブルと条件引数を合わせることによって増分操作を行うための –query 引数を実行して、その後それらをメインテーブルに挿入することもできます。
これらの手順はすべて、フローを自動化するための Sqoop ジョブとして作成されました。
Redshift へのデータのエクスポート
データが S3 データストアである EMR- HDFS にインポートされたところで、Sqoop コマンドを使ってデータをデータウェアハウスレイヤーにエクスポートし直す方法を見ていきましょう。今回は、Redshift クラスターを使用し、例を使ってデモを行います。
SQL クライアントツールまたはアプリケーションが使用する以下の JDBC API をダウンロードします。よくわからない場合は、JDBC 4.2 API ドライバーの最新バージョンをダウンロードします。
このドライバーのクラス名は 1.2.15.1025/RedshiftJDBC41-1.2.15.1025.jar
com.amazon.redshift.jdbc42.Driver です。
この JAR ファイルを EMR マスタークラスターノードにコピーします。SSH 経由でマスタークラスターにアクセスし、/usr/lib/sqoop ディレクトリに移動してこの JAR ファイルをコピーします。
注意: EMR マスターはマスターノードへのパブリックアクセスを許可しないため、ローカル PC からのマニュアルダウンロードを実行する必要がありました。また、FileZila を使用してファイルをプッシュしました。

EMR マスタークラスターにログインし、この Sqoop コマンドを実行して S3 データファイルを Redshift クラスターにコピーします。
Redshift クラスターを起動します。この例では、ds2.xLarge (ストレージノード) を使用します。

Redshift が起動し、接続を許可するためにセキュリティグループが EMR クラスターに関連付けられたら、EMR マスターノードで Sqoop コマンドを実行します。これによって、データがテーブルとして S3 の場所 (先ほどコード 6 のコマンドにあった場所) から Redshift クラスターにエクスポートされます。
ここでは、以下の例にあるように、Redshift にテーブル構造を作成しました。
テーブルが作成されたら、以下のコマンドを実行してデータを Redshift テーブルにインポートします。
このコマンドは、データレコードをテーブルに挿入します。
詳細については、「Amazon EMR からデータをロードする」を参照してください。
RDBMS にデータを再度コピーする方法に関する詳細については、Use Sqoop to Transfer Data from Amazon EMR to Amazon RDS を参照してください。
まとめ
以上で、Apache Sqoop を EMR で使用して、RDBMS から EMR クラスターにデータを転送する方法を学びました。Sqoop を使って EMR クラスターを作成し、Hive でサンプルデータセットを処理して、MySQL-RDS でサンプルテーブルを構築してから、Sqoop を使ってデータを EMR にインポートしました。また、Redshift クラスターも作成し、Sqoop を使ってデータを S3 からエクスポートしました。
Sqoop が並行してデータ転送を実行でき、それによって実行がより迅速でコスト効率性のよいものになることを立証しました。ソースからターゲットレイヤーへの ETL データ処理の簡素化も行いました。
Sqoop の利点は以下のとおりです。
- EMR への高速で並行的なデータ転送 — 外部ツールへの依存性を排除することによって、インポートプロセスを実行するために EMR コンピューティングインスタンスを活用。
- MySQL に直接実行する高速クエリ、および EMR Hadoop と S3 へのプルパフォーマンスを使用するインポートプロセス。
- 再設計なしでのオンプレミス RDBMS データの移行に対して高まるニーズをシンプル化する、維持されているソースシステム (テーブルにプライマリーキーがあることを条件とする) からのシーケンシャルデータセットのインポート。
Sqoop の弱点は以下のとおりです。
- 開発者/運営チームコミュニティによる自動化。これには、Sqoop 向けの Airflow サポート、またはその他ツールを使用するワークフロー/ジョブメソッドを通じた自動化が必要です。
- プライマリーキーがなく、レガシーテーブル依存関係を維持するテーブルについては、増分的なデータのインポートが難しい。Sqoop の一括転送で 1 回限りの移行を実行し、ソース取り込みメカニズムを再設計することが推奨されます。
- インポート/エクスポートが JDBC 接続に従って行われ、ODBC または API コールなどの他のメソッドをサポートしない。
ご質問またはご提案については、以下でコメントを残してください。
その他の参考資料
この記事が役に立つと思われる場合は、Use Sqoop to transfer data from Amazon EMR to Amazon RDS とand Seven tips for using S3DistCp on AMazon EMR to move data efficiently between HDFS and Amazon S3 も併せてお読みください。
今回のブログ投稿者について
 Nivas Shankar はアマゾン ウェブ サービスのシニアビッグデータコンサルタントです。 AWS プラットフォームでのビッグデータアプリケーションの構築において、企業顧客を援助し、密接に連携しています。物理学の修士号を取得している Nivas は、理論物理学概念に情熱を持っています。Nivas の楽しみは、妻と 2 人の可愛い子供たちと時間を過ごすことで、時間があるときは、子供たちをテニスとフットボールの練習に連れて行っています。
Nivas Shankar はアマゾン ウェブ サービスのシニアビッグデータコンサルタントです。 AWS プラットフォームでのビッグデータアプリケーションの構築において、企業顧客を援助し、密接に連携しています。物理学の修士号を取得している Nivas は、理論物理学概念に情熱を持っています。Nivas の楽しみは、妻と 2 人の可愛い子供たちと時間を過ごすことで、時間があるときは、子供たちをテニスとフットボールの練習に連れて行っています。