Amazon Web Services ブログ
AWS Batch および Amazon SageMaker を使用したマルチリージョンサーバーレス分散型トレーニング
AWS でグローバル展開を築き、スケールにアクセスすることは、数多くのベストプラクティスの 1 つです。そのような規模とデータの効率的な利用 (パフォーマンスとコストの両方) を実現するアーキテクチャを作成することで、重要なアクセスが規模であることを確認できます。たとえば、自動運転車両 (AV) の開発では、データは運転キャンペーンにローカルで地理的に獲得されます。機械学習 (ML) から生成データと同じ AWS リージョンでの計算パイプライン実行することに至るまで、関連性があり、より効率的です。
さらに工夫するために、たとえば、組織が米国のサンフランシスコで運転キャンペーンの 4K ビデオデータを獲得したとします。並行して、あなたの同僚がドイツのスタっとガードの運転キャンペーンを取得したとします。両方のビデオキャンペーンにより、1 日当たり数テラバイトのデータを得ることができます。理想的には、そのデータをあなたの生成場所に近いリージョンに転送します。(この場合は、us-west-1とeu-central-1)です。ワークフローがこのデータにラベルを付けると、それぞれのリージョンにローカルの分散型トレーニングを実行することで、コストとパフォーマンスの観点から理に適う一方で、両方のデータセットをトレーニングするために使用されるハイパーパラメーターの一貫性が維持されます。
AWS の分散型トレーニングを開始するには、Amazon SageMaker を使用します。これは、分散型トレーニング (たとえば、Horovod で最適化された TensorFlow) で必要な差別化されないヘビーリフティングの大部分をプロビジョニングします。さらに、1 秒当たりの課金により、効率的なコスト管理をもたらします。これらの利点により、完全管理型のアーキテクチャにおけるモデル開発とデプロイに労力をかけなくても済むようになります。
Amazon SageMaker は管理型 ML サービスのエコシステムであり、地上検証によるラベリング、モデルトレーニング、ハイパーパラメーターの最適化、デプロイを支援します。これらのサービスは、Jupyter notebooks、AWS CLI、または Amazon SageMaker Python SDK を使用してアクセスできます。SDK では特に、ML ワークロードを初期化し、分散させるために少しのコード変更が必要です。

上記のアーキテクチャでは、S3 バケットはトレーニング入力ファイルのソースとしての役割を果たします。SageMaker Python SDK は、必要な計算リソースと Docker イメージをインスタンス化して、S3 からデータをソーシングするモデルトレーニングを実行します。出力モデルアーティファクトは、出力 S3 バケットに保存されます。
Amazon SageMaker Python SDK は、インフラストラクチャデプロイを抽象化し、完全に API 指向であるため、スケーラブルな方法で sdk 経由でトレーニングジョブのリクエストを調整できます。
前の AV シナリオでは、たとえば、アップロードされたデータセットから入力トレーニングデータをトリガーすることができます。これは、リレーショナル方式で追跡しました。これを AWS Batch と組み合わせることができます。これは、実行時に関連するハイパーパラメーターを渡すスケーラブルな方法でこれらの分散型トレーニングジョブを送信できるジョブ配列メカニズムを提供します。以下のサンプルアーキテクチャを考えてみましょう。
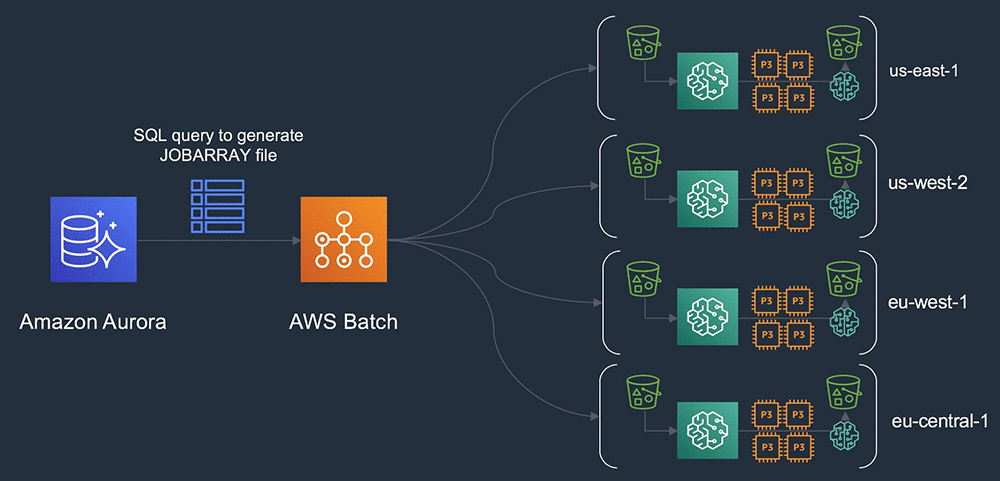
上記のアーキテクチャでは、グローバルに AV キャンペーンメタデータを追跡するために使用されるリレーショナルデータベースが使用されます。AWS Batch の JOBARRAY 入力ファイルを入力する SQL クエリを生成できます。その後、AWS Batch は複数の AWS リージョンにわたってグローバルに実行されるクラスタのグリッドのインスタンス化を調整します。
ローカルで生成された Amazon S3 のデータに基づいて、グローバルにデプロイされたクラスターのグリッドを立てています。中央データベースからメタデータをクエリすることで、4 つのリージョンすべてにわたる容量にアクセスして、トレーニング入力を整理します。いくつかの追加リレーショナル結合を含めて、それにオンデマンドまたはリージョンごとのスポット料金と予約用容量に基づいて推移的なコピーのデータを選択させます。
Amazon SageMaker のデプロイ
この記事の例では、Imagenet2012/Resnet50 モデルをリージョン全体でレプリケートされた Imagenet2012 TF レコードで実行します。このアドバンスワークフローの場合、2 個の Docker イメージを準備する必要があります。1 つのイメージは Amazon SageMaker SDK を呼び出してジョブ送信の準備をするためのもので、2 番目のイメージは Horovod-enabled TensorFlow 1.13 環境を実行するためのものです。
最初に、IAM ロールを作成して、Amazon SageMaker サービスとそれに続くサービスを呼び出してトレーニングを実行します。次に、dl-sagemaker.py スクリプトを作成します。これは、Amazon SageMakerトレーニング API へのメイン呼び出しスクリプトです。
Amazon SageMaker Script Mode Docker イメージを構築するための手順については、aws/sagemaker-tensorflow-container の GitHub の TensorFlow framework repo を参照してください。このビルドの後で、このイメージをデータを生成する予定の各リージョンにコミットします。
以下の例では、これを us-east-1 (バージニア北部)、us-west-2 (オレゴン)、eu-west-1 (アイルランド)、および eu-central-1 (フランクフルト) にコミットします。Tensorpack による TensorFlow 1.13 のサポートが Amazon SageMaker Python SDK にある場合、これは任意のステップになります。デプロイを容易にするために、Amazon ECR イメージの名前をリージョン全体で同じに維持します。
Amazon SageMaker SDK (dl-sagemaker.py) を呼び出すメインエントリスクリプトの場合、次のステップを完了してください。
- エントリを置換してください。
- Image_name を作成した Docker イメージの名前に置換します。
以下のコードは、sagemaker_entry.pyのためのものです。トレーニングスクリプトを開始するための内部呼び出しです。
以下のコードは sage_wrapper.sh のためのものです。S3 からアレイ定義をダウンロードし、グローバルな Amazon SageMaker API 呼び出しを開始する AWS Batch の全体的なラッパーです。
最後に、以下のコードが Dockerfile のためのものです。バッチ調整イメージを構築するためのものです。
ビルドされた Docker イメージを Amazon SageMaker Python SDK と同じリージョンの ECR にコミットします。このリージョンから、すべての Amazon SageMaker 分散型 ML cluster-works をグローバルにデプロイします。
AWS Batch を使用すると、コンピューティング環境をインスタンス化するための固有の構成は必要ありません。AWS Batch を使用してAmazon SageMaker API を起動するだけなので、デフォルト設定で十分です。ジョブキューをコンピューティング環境にアタッチし、次を使用してジョブ定義ファイルを作成します。
ジョブ開始時にインポートするには、次のとおり、サンプルの JOBARRAY ファイルを S3 にアップロードします。
Jobs ページで、S3_ARRAY_FILE のパスを変更するジョブを送信します。ジョブアレイは、個別のリージョンでMLトレーニングジョブの送信とモニタリング専用の各ノードで開始します。ジョブが実行されている候補リージョンを選択すると、追加のアルゴリズム、インスタンスメトリック、および詳細なログを表示できます。
このデプロイで注目すべき点の1つは、前の例では、4 つのリージョンで 480 GPU のクラスターのグリッドを開始し、合計 360,000 個のイメージ/秒を組み合わせたことです。このプロセスは、結果が出るまでの時間を短縮し、パラメータースキャニングを最適化します。
まとめ
このアーキテクチャを実装することにより、スケール自在で、パフォーマンスが高く、グローバルな分散型 ML トレーニングプラットフォームを手に入れることができます。AWS Batch スクリプトでは、任意の数のパラメーターをアレイファイルにリフトして、ワークロードを分散させることができます。たとえば、異なる入力トレーニングファイルを使用するだけではなく、異なるハイパーパラメーター、Docker コンテナイメージ、またはさらに異なるアルゴリズムをすべてグローバルスケールでデプロイして使用することができます。
また、バックエンドでも、サーバーレス分散型 ML サービスでこれらのワークロードを実行することもできます。たとえば、Amazon SageMaker コンポーネントを Amazon EKS で置換することが可能です。ML ワークロードをグローバルフットプリントでパワーアップしましょう!
Amazon SageMaker コンソール を開いて、開始します。何かご質問がある場合は、コメントに記入してください。
著者について
 Amr Ragab は、AWS 向け Accelerated Computing のビジネス開発マネージャーであり、お客様が大規模な計算ワークロードを実行できるよう支援することに専念しています。余暇は旅行をしたり、日常の生活にテクノロジーを組み込む方法を見つけることが好きです。
Amr Ragab は、AWS 向け Accelerated Computing のビジネス開発マネージャーであり、お客様が大規模な計算ワークロードを実行できるよう支援することに専念しています。余暇は旅行をしたり、日常の生活にテクノロジーを組み込む方法を見つけることが好きです。